- The paper presents a novel architecture that replaces convolutional blocks with 3D shifted window transformers, enhancing spatiotemporal traffic prediction accuracy.
- It leverages a hierarchical U-Net design with feature mixing and patch embedding to effectively capture complex spatial and temporal dynamics.
- Experimental results on the Traffic4Cast2021 challenge demonstrate a reduced MSE of 49.7208, outperforming baseline models like GCN and UNet.
Introduction
The paper introduces SwinUNet3D, a novel architecture for traffic prediction that uses a 3D variant of Swin Transformers within a U-Net configuration. The primary innovation lies in replacing convolutional blocks with 3D shifted window transformers in both the encoder and decoder branches, facilitating spatiotemporal traffic data prediction. This approach aims to enhance prediction accuracy without the extensive computational demand seen in conventional techniques.
Architecture
The SwinUNet3D architecture consists of an encoder-decoder structure typical of U-Net arrangements. However, it diverges by implementing Swin Transformer's shifted window strategy, enabling localized attention mechanisms while promoting efficient information interchange. The encoder compresses spatiotemporal inputs by staggering four transformer blocks, each introduced via a feature mixing layer. Conversely, the decoder performs spatial upsampling using patch expanding layers. This arrangement maximizes the model's capability to capture and predict traffic patterns at varying hierarchical levels.
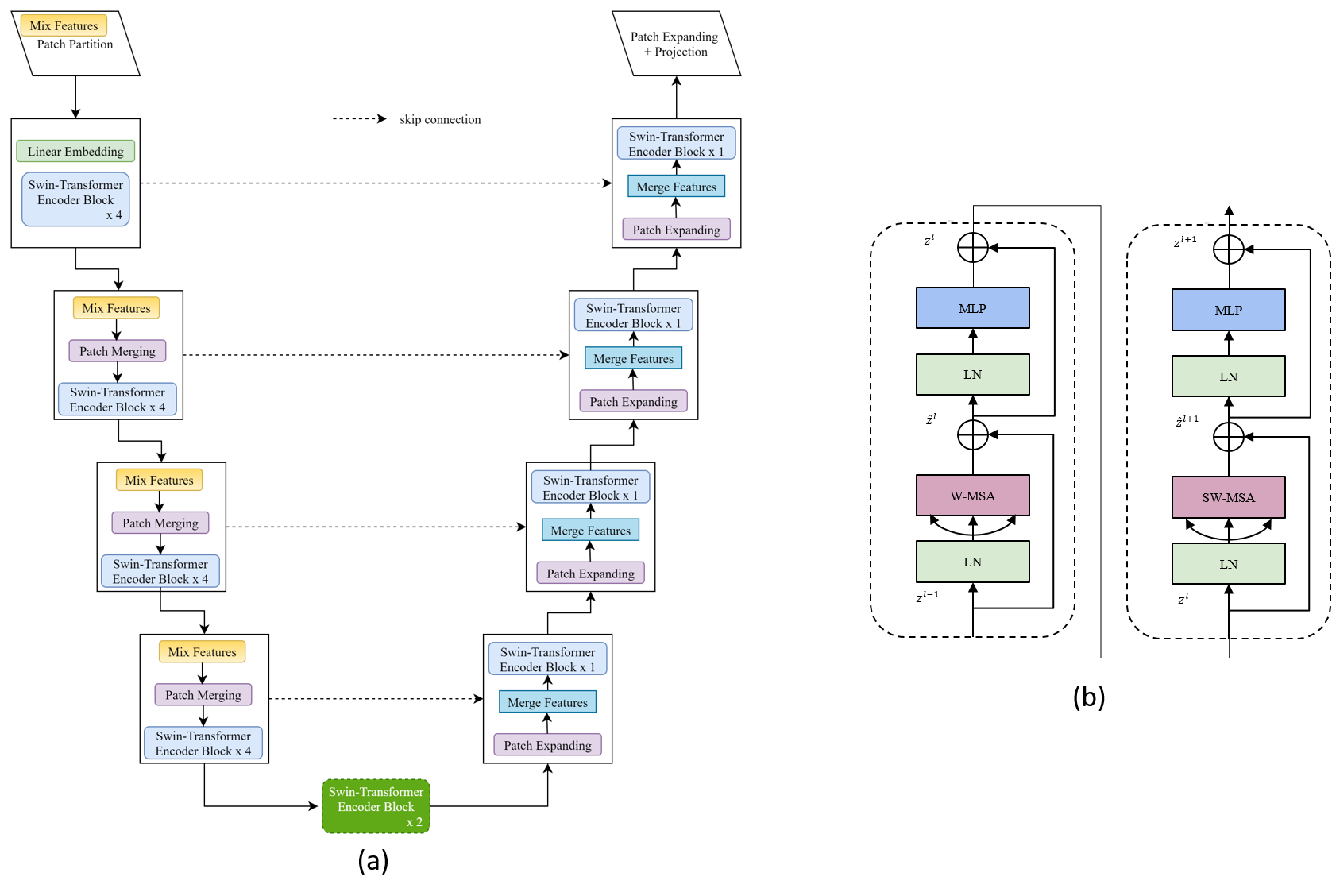
Figure 1: Details of the proposed Spatiotemporal Swin-UNet3D architecture. The network includes encoder and decoder blocks, utilizing Swin-Transformers with feature processing units.
Feature Mixing and Patch Partitioning
The feature mixing layer proves crucial for improving the implicit interrelationship of features, enhancing model performance by reshaping features and applying a fully connected transformation. Features entering the transformer blocks undergo partitioning through strided convolutions, resulting in 3D patch embeddings essential for subsequent transformer operations.
Attention Mechanism
Swin Transformers utilize Multi-Head Self Attention (MSA) within shifted windows to manage the computational overhead typical to traditional attention mechanisms. The transformer blocks interleave windowed and shifted window attention, boosting learning efficiency and maintaining high performance for spatiotemporal inputs. This setup is augmented by lightweight MLP layers without the necessity of larger hidden dimensions, reducing parameter load while preserving accuracy.
Experimental Results
The SwinUNet3D model was tested under the Traffic4Cast2021 challenge framework, which includes datasets representing dynamic traffic states across multiple global cities. The model achieved an MSE of 49.7208, outperforming baseline models like GCN and UNet. Its performance demonstrates the architecture's efficacy in handling complex spatial data, attributed to its improved spatial attention mechanism and feature processing strategy.
Practical Implications and Future Work
SwinUNet3D showcases its utility in short-term traffic forecasting, providing a significant edge in prediction accuracy over previous models without pre-training on extensive datasets. Future research includes exploring alternative attention mechanisms, incorporating hypercomplex network token mixing, and refining multi-task training approaches. The model's adaptability to other spatiotemporal prediction tasks also warrants exploration.
Conclusion
SwinUNet3D contributes a promising template for spatiotemporal forecasting within urban traffic management, leveraging the strengths of Swin Transformers in image processing while tailoring them to dynamic prediction tasks. The structure's modularity and performance signify potential advancements in real-time traffic systems and similar applications requiring refined spatial-temporal data processing.