- The paper introduces the shifted window mechanism in a hierarchical vision Transformer for efficient feature representation and linear complexity.
- It achieves superior performance with notable gains on ImageNet classification, COCO object detection, and ADE20K segmentation benchmarks.
- The architecture scales across variants, proving effective for high-resolution tasks and setting a new paradigm in vision modeling.
The paper presents the Swin Transformer, a novel vision Transformer architecture designed to offer a high-performance backbone for a range of computer vision tasks. Utilizing a hierarchical design with a unique shifted window mechanism, the Swin Transformer achieves notable efficiency and accuracy improvements over competing models in tasks such as image classification, object detection, and semantic segmentation.
Hierarchical Feature Representation
The Swin Transformer constructs hierarchical feature maps by starting with small-sized image patches that are progressively merged into larger patches as the network depth increases. This approach contrasts with previous vision Transformers, which typically maintain a fixed-scale feature map across network stages and interact globally with each pixel. The hierarchical strategy, combined with the shifted window approach, leads to linear computational complexity with respect to image size, making the Swin Transformer efficient in handling high-resolution images.
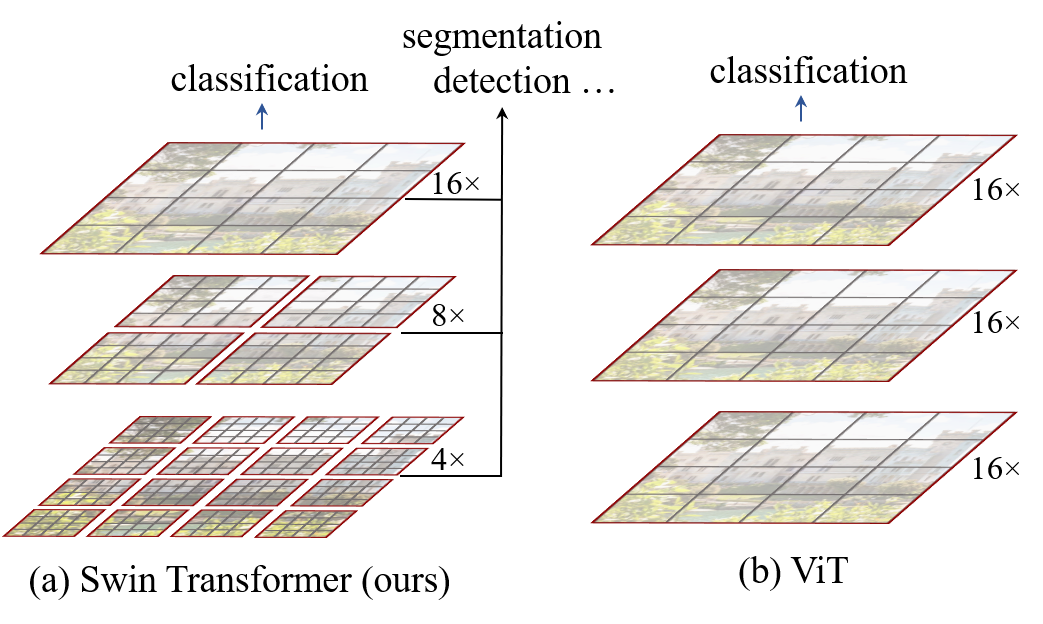
Figure 1: The proposed Swin Transformer architecture builds hierarchical feature maps via a shifted window approach, optimizing computational efficiency.
Shifted Window Mechanism
A core innovation in the Swin Transformer is its shifted window self-attention. Successive Transformer blocks use shifted window partitioning, which introduces connections between adjacent windows over layers, enhancing the model's representation capabilities without escalating computational demands. This contrasts with the high overhead associated with conventional sliding and global window methods, which suffer from inefficiencies in real-world latency and resource usage.
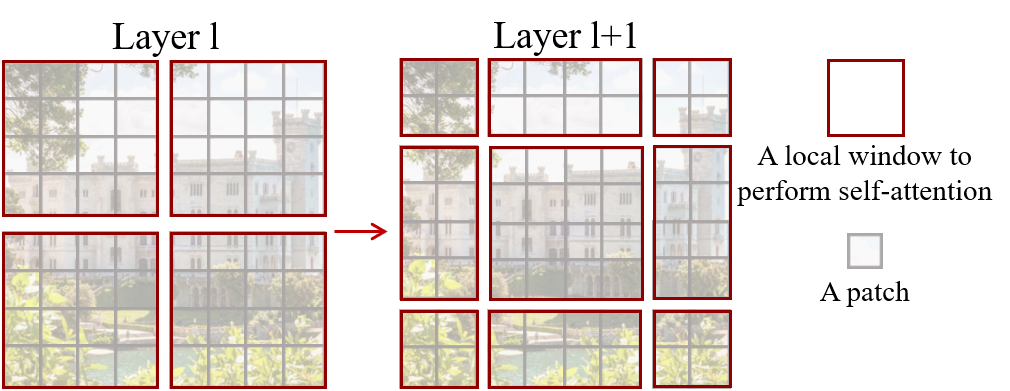
Figure 2: An illustration of the shifted window approach, crucial for efficient self-attention computation in the Swin Transformer architecture.
Architectural Details
The Swin Transformer is built using a series of Swin Transformer blocks that replace the conventional multi-head self-attention found in standard Transformers with shifted window-based approaches. Four primary variants of the Swin Transformer are introduced (Swin-T, Swin-S, Swin-B, and Swin-L), differing in computational complexity and parameter count to cater to various application requirements.
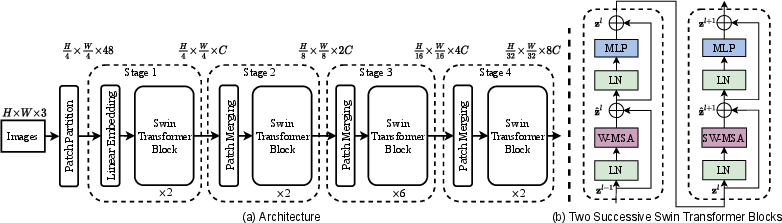
Figure 3: The architecture of a Swin Transformer, highlighting Swin Transformer blocks and hierarchical feature map generation.
The Swin Transformer demonstrates state-of-the-art performance across a variety of tasks:
- Image Classification (ImageNet-1K): Achieves 87.3% top-1 accuracy, surpassing other models like the Vision Transformer (ViT) by notable margins.
- Object Detection (COCO): Attains a box AP of 58.7 and a mask AP of 51.1, which are significantly higher than previous benchmarks.
- Semantic Segmentation (ADE20K): Reaches a mean Intersection over Union (mIoU) of 53.5, outperforming existing approaches by 3.2 mIoU.
These results indicate the model's robust ability to act as a general-purpose backbone across diverse visual tasks. By outperforming conventional backbones such as ResNet and ViT, the Swin Transformer emerges as a leading alternative, especially in applications requiring high-resolution and dense predictions.
Conclusion
The Swin Transformer stands as a significant advancement in vision-based transformer architectures, offering a blend of efficiency and performance not previously achieved by existing models. The hierarchical representation combined with the shifted window self-attention serves as a paradigm shift, setting a new standard for future developments in unified visual and linguistic modeling frameworks. Its strong performance on fundamental vision tasks signals its potential utility in broader contexts, encouraging the exploration of joint vision-language signal processing.