- The paper introduces an AdaRNN framework that combats temporal covariate shift by adaptively segmenting and matching time series distributions.
- It employs Temporal Distribution Characterization and Temporal Distribution Matching modules to optimize period segmentation and dynamic weighting for improved predictions.
- Experiments show up to a 9.0% increase in regression accuracy and a 2.6% boost in classification accuracy, demonstrating efficacy across RNN and Transformer models.
AdaRNN: Adaptive Learning and Forecasting of Time Series
Introduction
The paper "AdaRNN: Adaptive Learning and Forecasting for Time Series" (2108.04443) tackles the significant challenge of time series forecasting under the conditions of Temporal Covariate Shift (TCS). The TCS problem arises when the statistical properties of a time series change over time, leading to non-stationarity, which complicates accurate prediction. AdaRNN is introduced as a framework designed to address this problem by sequentially employing two modules: Temporal Distribution Characterization (TDC) and Temporal Distribution Matching (TDM).
Temporal Covariate Shift and Time Series Modeling
Temporal Covariate Shift is a refinement of the covariate shift concept, specifically tailored for time series data. It acknowledges that while the data distribution may change across different time periods, the conditional distributions remain consistent. The AdaRNN framework handles this by characterizing distinct periods in the time series where distributions are markedly different (TDC), then learning to adaptively match these distributions (TDM).
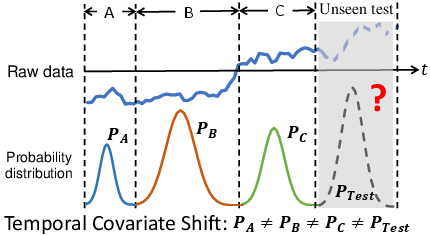
Figure 1: The temporal covariate shift problem in non-stationary time series. The raw time series data (x) is multivariate in reality. At time intervals A, B, C, and the unseen test data, the distributions are different: PA(x)=PB(x)=PC(x)=PTest(x).
The AdaRNN Framework
The framework consists of two innovative components:
- Temporal Distribution Characterization (TDC): TDC is designed to optimally split a time series into multiple periods with maximal diversity in their distribution according to the principle of maximum entropy. This involves an optimization problem which is often solved using dynamic programming or a computationally efficient greedy algorithm.
- Temporal Distribution Matching (TDM): After period segmentation through TDC, TDM is tasked with aligning these distributions to train a highly adaptable RNN model. This is critical for achieving effective future predictions under varying conditions. The module employs an adaptive weighting scheme for temporal states, allowing it to capture relevant distributional characteristics across different periods dynamically.
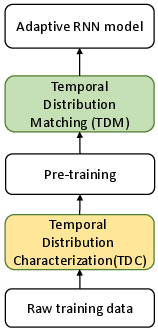
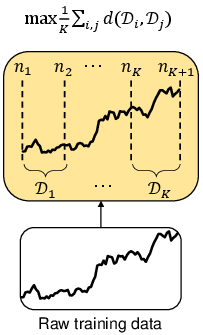
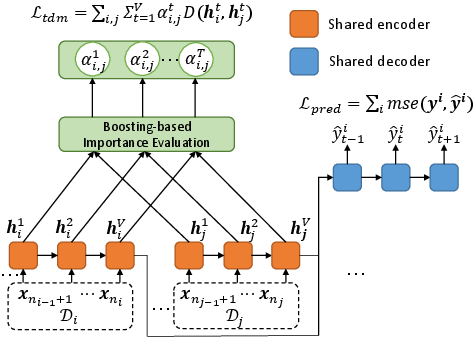
Figure 2: The framework of AdaRNN.
AdaRNN's efficacy is demonstrated through a series of experiments on diverse datasets, including human activity recognition, air quality prediction, and stock price forecasting. The framework showed a marked improvement over existing state-of-the-art methods, achieving up to a 9.0% increase in regression accuracy and a 2.6% enhancement in classification accuracy.
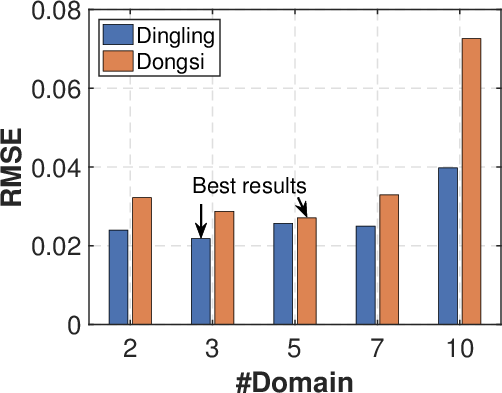
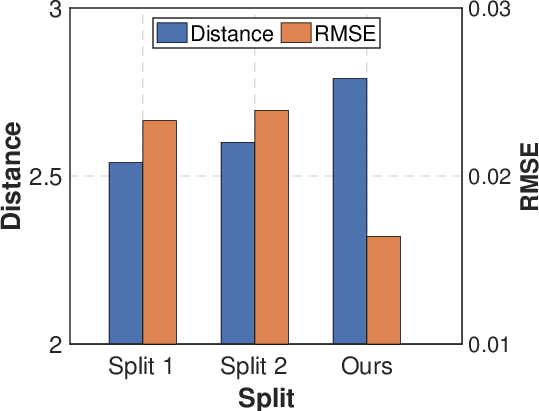
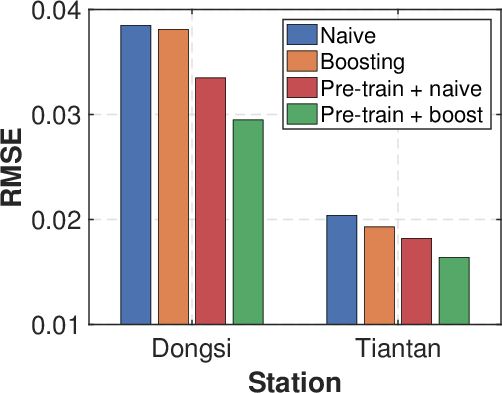
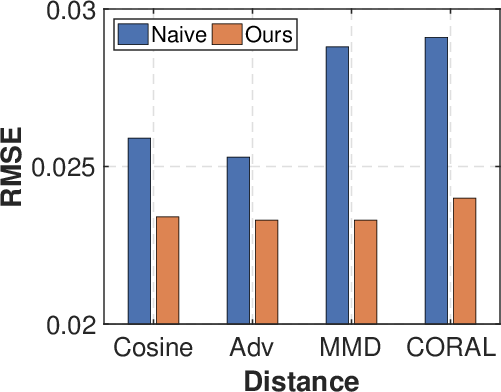
Figure 3: Ablation study. (a) Analysis of K for temporal distribution characterization. (b) Different domain split strategies. (c) Comparison of w. or w./o. adaptive weights in distribution matching. (d) Effectiveness of temporal distribution matching.
Beyond RNNs, AdaRNN's capabilities are extended to the Transformer architecture, showcasing its flexibility and robust performance across different neural architectures. This adaptability highlights the potential for AdaRNN to improve various prediction tasks where non-stationarity is a core issue.
Conclusion
AdaRNN provides a compelling solution for time series forecasting by efficiently addressing the complexities introduced by Temporal Covariate Shift. Its novel approach to temporal distribution characterization and matching serves as a powerful tool for enhancing model generalization across unexpected shifts in data distribution. Future work could focus on integrating TDC and TDM into an end-to-end system, further improving model efficiency and scalability.