- The paper proposes a standardized preprocessing method that prevents data leakage and reduces biases in predictive process monitoring datasets.
- It demonstrates that strict temporal splitting and debiasing techniques lead to significant improvements in model predictive accuracy.
- The study emphasizes the need for publicly available, unbiased benchmark datasets to ensure fair comparisons in process mining research.
Creating Unbiased Public Benchmark Datasets with Data Leakage Prevention for Predictive Process Monitoring
The paper focuses on improving the methodology for constructing benchmark datasets in the field of predictive process monitoring (PPM). It identifies critical issues in existing datasets, such as data leakage and biases, which hinder scientific progress and reproducibility. The authors propose a principled approach to dataset preprocessing to standardize and improve the validity of comparisons among various predictive models.
Introduction to Predictive Process Monitoring
Predictive process monitoring is a sub-field of process mining that utilizes event logs to predict future events, outcomes, and remaining execution times of processes. Despite the rise in interest and research in this area, there are substantial inconsistencies in the preprocessing of datasets. These inconsistencies arise due to different dataset selection and splitting methods, often exacerbated by undocumented domain knowledge, leading to challenges in reproducibility and fair comparison of models.
Major Obstacles in Fair Benchmarking
Dataset Diversification and Preprocessing Biases
The use of diverse datasets and preprocessing techniques complicates the comparison of predictive models. Additionally, some preprocessing methods introduce biases related to case durations and running processes, especially at the chronological extremes of datasets. These biases lead to skewed model performances and unreliable predictions.
Data Leakage
Data leakage is a significant obstacle in temporal splitting methods currently employed, where training and test datasets are not properly isolated. This affects the predictive performance due to the inadvertent sharing of data between training and testing phases.
Lack of Standardized Benchmarks
The absence of standardized benchmarks in PPM equivalent to those in other AI domains (like MNIST for image processing) impedes progress. The creation of unbiased and publicly accessible benchmark datasets is crucial for advancing the field.
Proposed Method for Benchmark Dataset Construction
Principled Approach
The authors suggest a standard preprocessing method to establish unbiased benchmark datasets. They advocate for the isolation of test sets using strict temporal splitting to prevent data leakage and ensure an unbiased evaluation environment.
Debiasing Techniques
The paper outlines techniques to remove chronological outliers and balance case durations and running cases within datasets. Figure 1 illustrates the presence of remote outliers, while Figure 2 highlights biases at dataset ends.
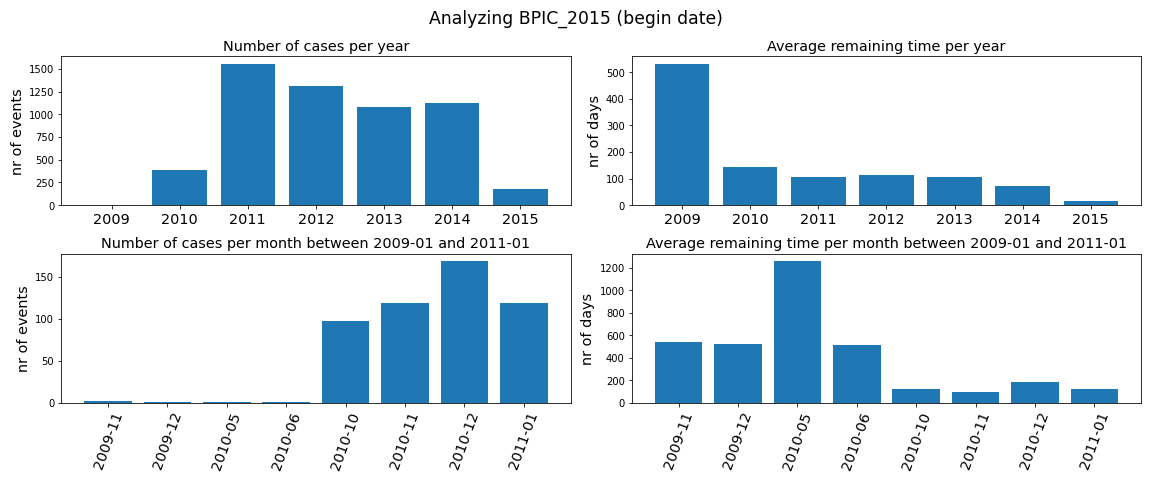
Figure 1: BPIC_2015 contains remote, faulty outliers at the beginning of the dataset.
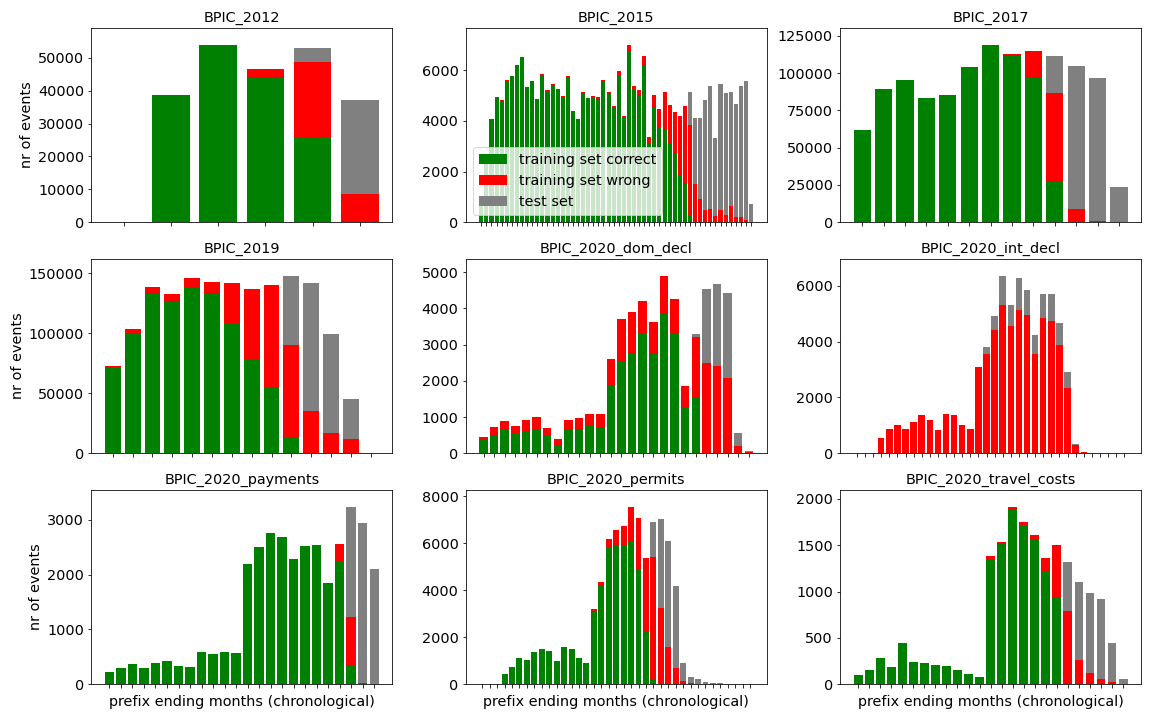
Figure 2: Grey bars represent test set events (20\%). Green bars are events in training set cases ending before the separation time (strict temporal splitting), red ones belong to cases ending after that separation time (regular temporal splitting). As debiasing was not done to retain sufficient samples, the bias at the datasets' ends is clearly visible.
Training and Testing Set Configuration
By implementing a strict temporal splitting strategy, the paper suggests a configuration where training sets consist only of completed cases before a certain separation time, ensuring no overlap with test cases.
The authors evaluated their preprocessing approach using convolutional neural networks (CNNs) to predict remaining times across various datasets. The results indicate that preprocessing choices significantly affect predictive accuracy, as shown in Figure 3.
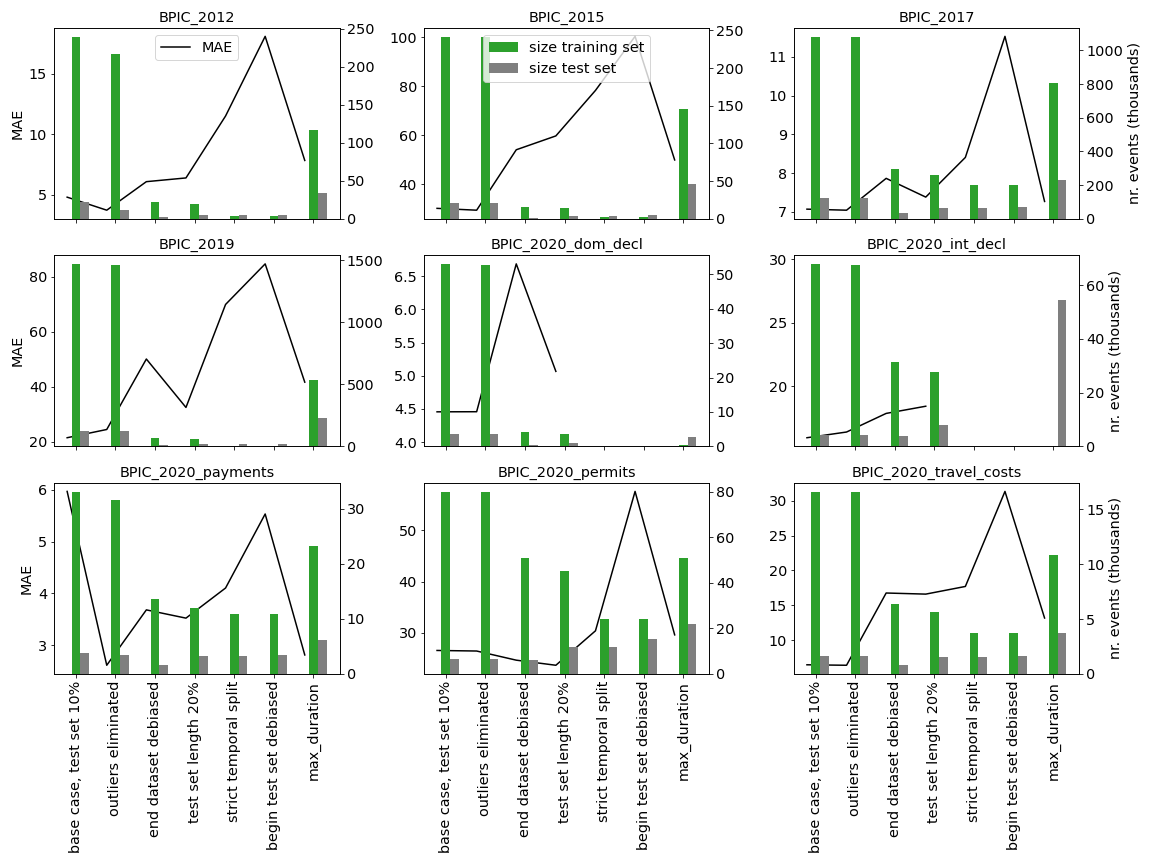
Figure 3: Prediction results (MAE) vary significantly in function of the chosen training and test data sets.
The implementation of proposed preprocessing steps improved model performance by reducing biases and preventing data leakage. Additionally, removing extremely long cases helped maintain dataset integrity and usability.
Conclusion
This paper identifies crucial challenges within predictive process monitoring related to dataset preprocessing and highlights the need for unbiased benchmarks. By offering specific preprocessing recommendations and making datasets publicly available, the authors aim to streamline research efforts, enable fair comparisons, and accelerate progress in PPM. Future work includes applying these methodologies to new datasets and exploring how the proposed benchmarks influence the development of next-generation predictive models.
