- The paper introduces Momentum Pseudo-Labeling (MPL) as its main contribution, using a dual-model setup for robust pseudo-label generation in semi-supervised ASR.
- The method employs an online and offline model that iteratively refine pseudo-labels through momentum-based weight updates, improving stability and reducing retraining complexity.
- Experimental results on LibriSpeech and TEDLIUM3 datasets demonstrate that MPL enhances Word Error Rate performance comparable to traditional language model-based approaches.
Momentum Pseudo-Labeling for Semi-Supervised Speech Recognition
Introduction
The paper "Momentum Pseudo-Labeling for Semi-Supervised Speech Recognition" (2106.08922) introduces a novel approach to tackle the challenges in semi-supervised automatic speech recognition (ASR) through Momentum Pseudo-Labeling (MPL). This method leverages both labeled and unlabeled data to improve the end-to-end ASR performance by employing a unique training framework involving online and offline models, reminiscent of the mean teacher methodology. The MPL approach addresses limitations of conventional pseudo-labeling by maintaining a momentum-based moving average for enhanced pseudo-label generation and stability.
Methodological Framework
Pseudo-Labeling in Semi-Supervised Learning
Pseudo-labeling (PL) operates by using a trained base model to generate labels for unlabeled data, thereby creating a dataset of pseudo-labeled instances for further training. The traditional PL methods suffer from instability and inefficiency due to the frequent need for retraining and complex label updating techniques. These limitations become more pronounced under conditions of domain mismatch and large datasets.
Momentum Pseudo-Labeling Approach
MPL innovatively applies a dual-model setup, consisting of online and offline models, wherein the online model learns to predict pseudo-labels generated by the offline model, which itself aggregates a momentum-based moving average of the online model's weights. This setup facilitates a dynamic and iterative refining of pseudo-labels and stabilizes the training process, particularly in varying semi-supervised scenarios. The MPL framework allows continuous improvement of both models as they learn from each other in a single training process without the need for external LLMs or complex decoding schemes.
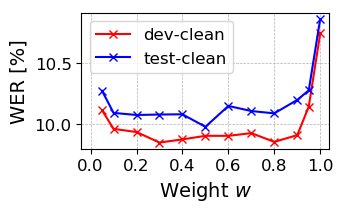
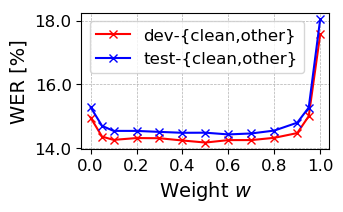
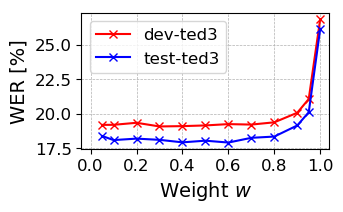
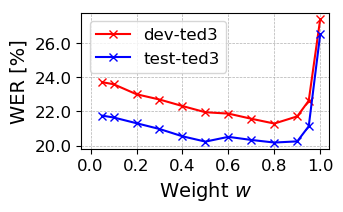
Figure 1: Influence of momentum update weight w on WER.
Experimental Evaluation
Dataset and Experimental Setup
The experiments were conducted using the LibriSpeech and TEDLIUM3 datasets, testing MPL's capability across in-domain and cross-domain semi-supervised scenarios. The results were benchmarked against traditional pseudo-labeling methods and evaluated based on Word Error Rate (WER) and WER Recovery Rate (WRR).
Results and Discussion
MPL consistently outperformed standard pseudo-labeling approaches in improvements over the base model's ASR performance. Notably, MPL without an accompanying LLM achieved results comparable to traditional methods that relied on sophisticated label generation techniques. The method also demonstrated scalability and robustness in the face of domain mismatches and varying amounts of unlabeled data.
Implications and Future Work
The introduction of MPL marks a step forward in semi-supervised ASR systems, providing a refined framework that simplifies label generation and training with improved stability and performance. Its adaptability makes it suitable for diverse ASR applications, expanding its utility in real-world deployment despite data constraints.
Future research directions include integrating filtering mechanisms and exploring the impact of multiple hypothesis generation on the MPL framework to further enhance performance and application robustness.
Conclusion
MPL presents a substantial enhancement to semi-supervised ASR by simplifying the pseudo-labeling process while significantly improving model accuracy and stability. The method's novel use of momentum-based parameter updates facilitates better handling of the inherent variability in pseudo-labels, thereby providing an effective tool for advancing semi-supervised learning in ASR contexts.

