- The paper introduces a deep RL-based JAiLeR system that bypasses differential equations to achieve sub-centimeter accuracy in joint space control.
- It employs curriculum learning and Proximal Policy Optimization to manage joint constraints and integrate obstacle avoidance in dynamic environments.
- The approach demonstrates robust sim-to-real transfer, simplifying robotic control architectures while enhancing precision and safety in unstructured settings.
Joint Space Control via Deep Reinforcement Learning
Introduction
The paper "Joint Space Control via Deep Reinforcement Learning" introduces a novel approach to robot control which leverages deep reinforcement learning (DRL) to replace traditional control systems that depend heavily on differential equations. Traditional robotic systems predominantly use predefined equations, employing inverse kinematics and dynamics for operational space control. These methods, despite their efficacy, struggle in dynamic and unstructured environments, primarily due to their inability to navigate joint space constraints effectively.
Methodology
Deep Reinforcement Learning Controller
The researchers propose a joint-level controller that omits the need for differential equations and instead relies on a deep neural network trained via model-free reinforcement learning. This neural network maps task space inputs directly to joint space outputs, enabling the robot to achieve tasks traditionally managed by complex mathematical modeling.
The proposed method, Joint Action-space Learned Reacher (JAiLeR), handles redundancy, joint limits, and acceleration/deceleration profiles dynamically. Furthermore, it enhances obstacle avoidance capabilities by integrating additional inputs concerning the robot's proximity to its environment.

Figure 1: Our deep RL-based JAiLeR system is able to learn a policy that enables a robot manipulator to reach any goal position (red sphere) in the workspace with sub-centimeter average error, while avoiding obstacles (silver spheres). The green points on the robot links are used for distance computations for collision avoidance.
Architecture
JAiLeR's architecture comprises a policy network that operates on state inputs such as end-effector error, current joint states, and optional obstacle-related inputs. The network outputs desired joint velocities, optimally utilizing a Proportional-Derivative (PD) control framework for motor commands. The training employs Proximal Policy Optimization (PPO), a model-free DRL algorithm known for its stability and efficiency.
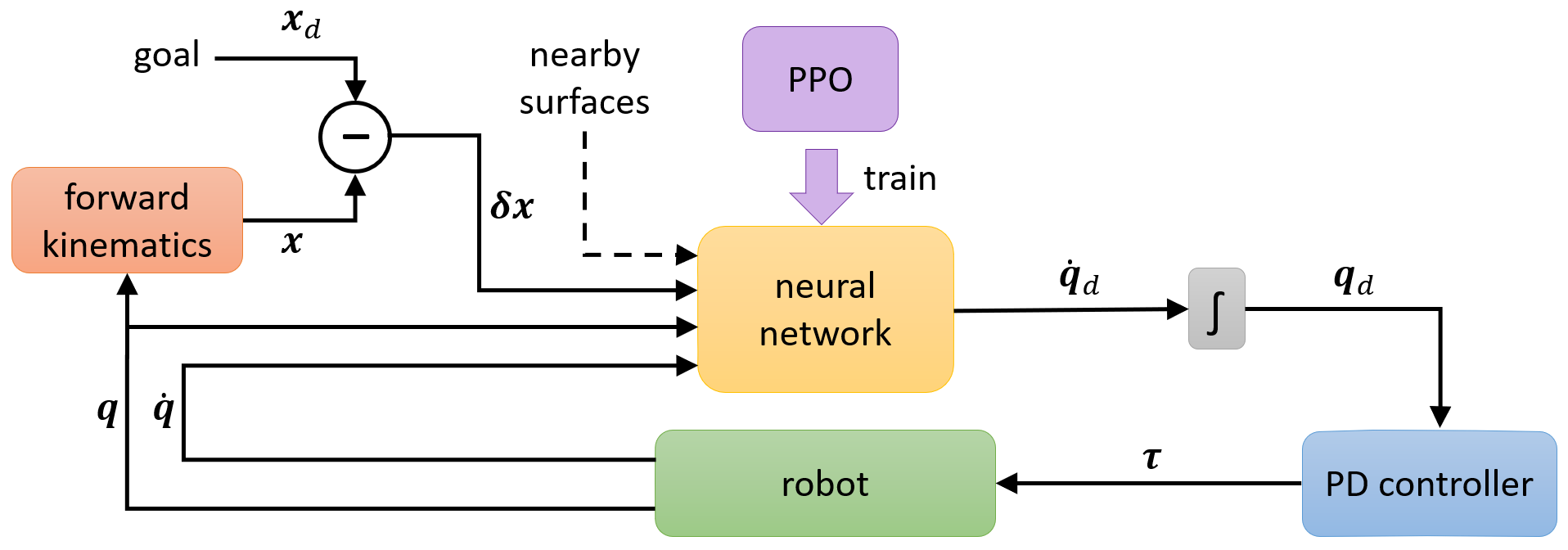
Figure 2: Overview of the proposed JAiLeR approach. The goal is provided externally (at run time) or by curriculum learning (during training). The robot can be either simulated or real.
Curriculum Learning
To improve learning efficacy, the researchers deploy curriculum learning, wherein the workspace is divided into increasingly complex sub-regions. The network iteratively masters these sub-regions, progressively expanding its functional capabilities across a broader workspace. This method significantly enhances the policy's robustness and generalization capabilities.
Experimental Evaluation
Simulation and Real-World Testing
The JAiLeR system was evaluated through extensive simulations and real-world experiments using robotic arms such as the Kinova Jaco and Baxter. Results demonstrated that JAiLeR could reach arbitrary target positions with sub-centimeter accuracy across large workspaces.
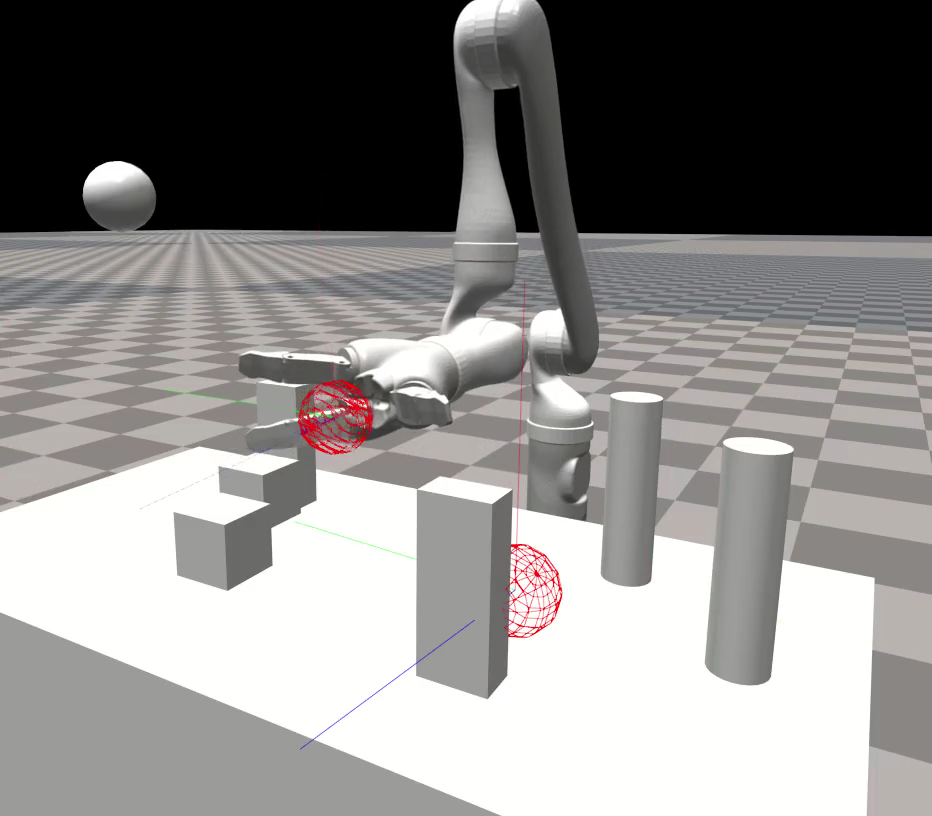
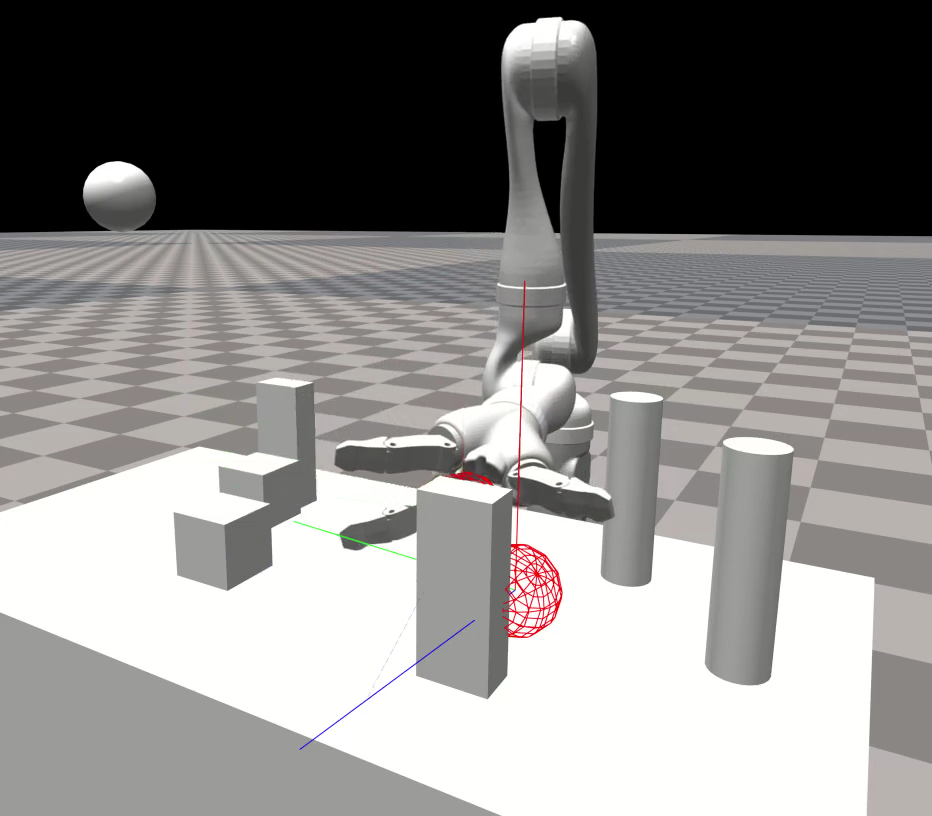
Figure 3: By feeding the network additional inputs (vectors pointing from links to the nearest obstacles), the policy learns to avoid obstacles. This is without scene-specific training, because the policy is trained only on spherical obstacles. The Jaco robot is reaching for a target (large red sphere).
Obstacle Avoidance
Through the augmentation of input vectors representing the closest obstacles, JAiLeR effectively avoids collisions without additional scene-specific training. This feature was particularly emphasized in cluttered environments, showcasing the policy's adaptability and effectiveness.
Sim-to-Real Transfer
The policy was successfully transferred from simulation to physical robotic systems without significant performance degradation—a testament to the robustness of the learned policies and the design’s resilience against the sim-to-real gap.
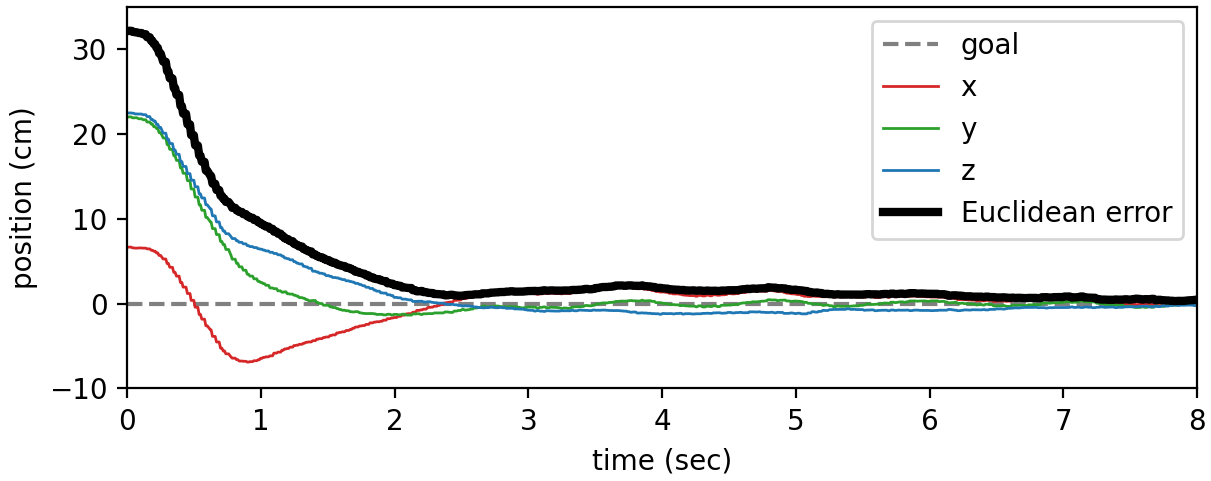
Figure 4: Step response of the real Baxter robot reaching for a goal, showing the speed, accuracy, smoothness, relatively small overshoot, and stability of our learned policy. This policy was not fine-tuned in the real world and comes directly from simulation.
Discussion
The shift from theoretically rigorous control methods to data-driven models like JAiLeR simplifies implementation while maintaining, if not surpassing, the performance of traditional systems. The integration of perception capabilities directly into the control policy represents a significant step forward, simplifying the control architecture of robotic systems. The proposed approach not only handles precise manipulative tasks but also dynamically responds to environmental changes, marking an improvement over traditional methods.
Conclusion
The work presents an effective alternative to classical robotic control methods through the application of deep reinforcement learning. JAiLeR's success in both simulated and real-world environments, its comprehensive handling of redundancy, and its adaptability to unstructured environments signify a substantial advancement in robotic control systems. Future developments aim to integrate real-time perception, enhancing the robot's ability to operate autonomously in dynamic contexts.

