- The paper extends XGBoost by integrating weighted cross-entropy and focal loss functions to tackle imbalanced binary classification.
- It presents a Python package that seamlessly integrates with Scikit-learn for parameter tuning and cross-validation.
- Experimental results on UCI and Parkinson's datasets demonstrate improved F1 scores and MCC compared to traditional models.
Imbalance-XGBoost: Leveraging Weighted and Focal Losses for Imbalanced Classification
Introduction
The paper "Imbalance-XGBoost: Leveraging Weighted and Focal Losses for Binary Label-Imbalanced Classification with XGBoost" introduces a Python package that extends XGBoost to handle binary classification tasks with imbalanced labels by incorporating weighted and focal loss functions. Imbalance in data, where certain classes are underrepresented, presents challenges for traditional machine learning models, which often prioritize overall accuracy, leading to suboptimal performance on minority classes. This paper proposes an extension to the standard XGBoost framework to address these challenges effectively using novel loss functions.
Design and Implementation
The Imbalance-XGBoost package is structured in Python, leveraging the existing XGBoost, NumPy, and Scikit-learn libraries. The core component of Imbalance-XGBoost is the integration of two custom loss functions: weighted cross-entropy loss and focal loss. The package's design is minimalistic yet functional, consisting of three main classes. The principal class, imbalance_xgboost, interfaces with users, while the other two classes, Weight_Binary_Cross_Entropy and Focal_Binary_Loss, encapsulate the custom loss functions. The design ensures compatibility with Scikit-learn for parameter tuning, cross-validation, and integration with pipelines.
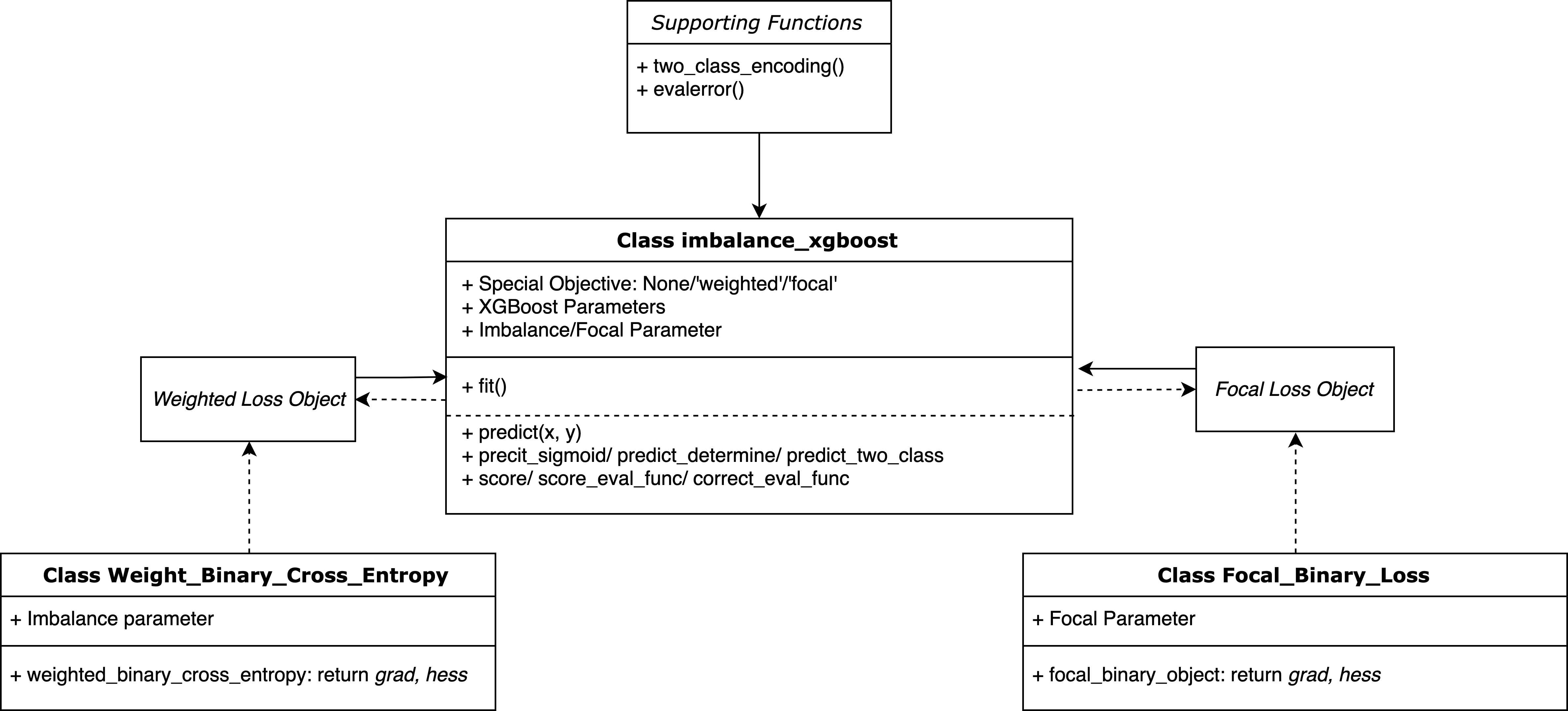
Figure 1: The Overall Structure of the Program.
Loss Functions and Derivatives
Weighted Cross-Entropy Loss
The weighted cross-entropy loss function modifies the traditional cross-entropy by applying a weight to account for class imbalance. This modification involves scaling the loss associated with misclassifying instances of a particular class. Derivatives of this loss function are critical as they guide the optimization process within the gradient boosting framework. Specifically, the first and second-order derivatives help in regularizing the update steps during model training.
Focal Loss
Focal loss, a more recent innovation, adjusts the cross-entropy loss by factoring in the difficulty of classifying individual samples, with a tunable parameter γ. This focus reduces the loss contribution from well-classified instances and shifts the optimization focus towards harder-to-classify examples, making it robust against imbalance. The paper derives both the gradient and Hessian for the focal loss, which are essential for its implementation within XGBoost's boosting context.
Experimental Evaluation
The package's performance was evaluated across several datasets, including the Parkinson's disease dataset and four benchmark datasets from the UCI repository with varying levels of imbalance. The Parkinson's dataset, particularly, demonstrated how traditional algorithms suffer from high accuracy overshadowing low recall, highlighting the inability to correctly predict minority classes.
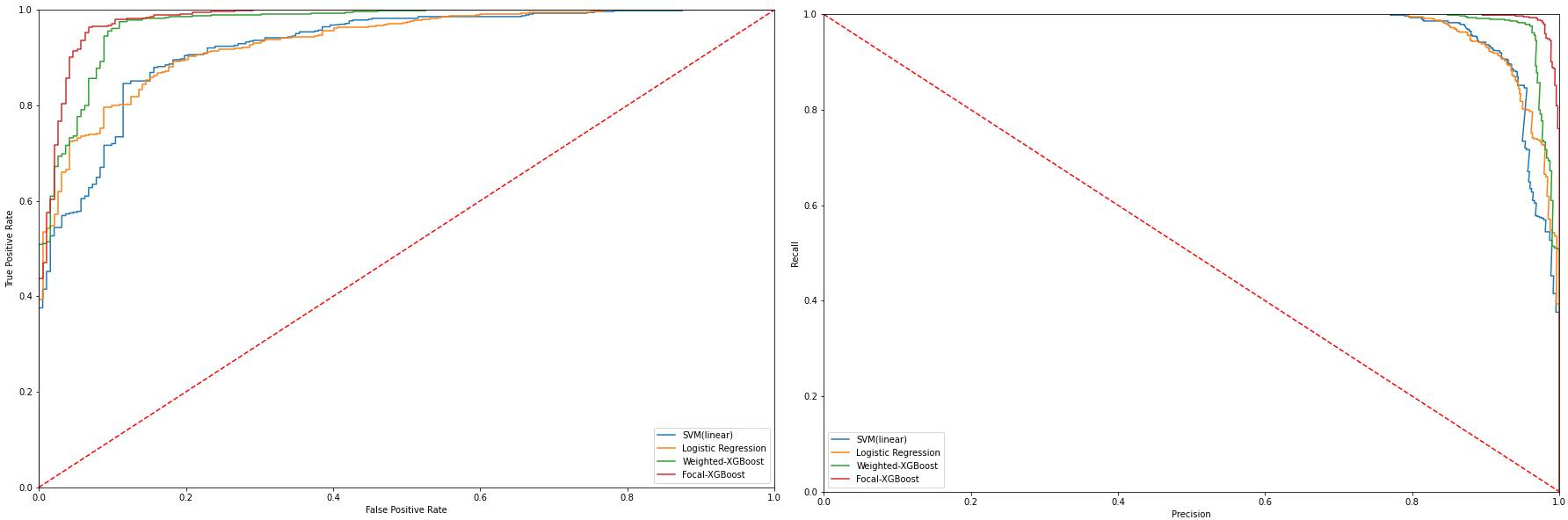
Figure 2: ROC and Precision-Recall Curve of MFCC Feature.
Results showcased that both weighted and focal loss-enhanced XGBoost models consistently outperformed traditional models in terms of F1 scores and Matthews Correlation Coefficients (MCC). Notably, focal loss, due to its robustness and adaptability, often achieved superior results, especially in higher imbalance scenarios. The precision-recall curves and ROC curves further assert Imbalance-XGBoost's enhanced sensitivity and specificity across diverse feature representations.
Conclusion
Imbalance-XGBoost significantly enhances the utility of traditional XGBoost for imbalanced datasets, thus broadening its application spectrum to real-world scenarios where imbalance is prevalent. Through sophisticated loss functions and rigorous evaluations, the package presents a powerful tool for researchers and practitioners dealing with imbalanced classification tasks. Future work could explore extending these principles to multiclass imbalanced scenarios and further optimizing computational efficiency for large-scale datasets.