- The paper proposes a novel GAN framework for few-shot 3D multi-modal segmentation, achieving near full-supervision accuracy using as few as one or two labeled samples.
- It adapts a 3D U-Net discriminator with weight normalization and average pooling to stabilize adversarial training and effectively integrate unlabeled data.
- Feature Matching in the generator significantly improved segmentation performance, as evidenced by enhanced DSC on the iSEG-2017 and MRBrains 2013 datasets.
Few-shot 3D Multi-modal Medical Image Segmentation using Generative Adversarial Learning
Introduction
The paper "Few-shot 3D Multi-modal Medical Image Segmentation using Generative Adversarial Learning" addresses the challenge of segmenting 3D multi-modal medical images when labeled data is extremely scarce. Through the application of Generative Adversarial Networks (GANs), the authors propose a method that exploits the benefits of both labeled and unlabeled data to improve segmentation accuracy significantly. This approach is groundbreaking in the field as it extends prior adversarial learning methods, traditionally used for 2D single-modality images, to the more complex 3D volume and multi-modal context.
Methodology
The proposed method utilizes a GAN architecture where the generator creates fake examples and a discriminator network distinguishes between fake and real data. This approach entails training three networks simultaneously: the generator, the discriminator, and an encoder that maps generated images back to noise vectors (Figure 1). The discriminator's role includes handling an adapted cross-entropy loss where K+1 class prediction is adjusted to enforce generated images as a separate fake class.
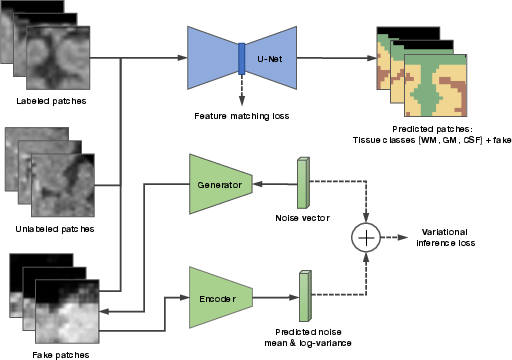
Figure 1: Schematic explaining the working of our model. The model contains three networks which are trained simultaneously.
Generative Adversarial Networks (GANs) Adaptation
The adaptation involves structuring the problem so that the discriminator learns to distinguish not only among K classes but also to identify a "fake" class, rendered by the GAN-generated images. This unique extension serves a dual purpose: it regularizes the segmentation network, preventing it from overfitting on limited labeled examples, and it exploits unlabeled data by thrusting it through an adversarial training setup.
Implementation and Training Details
In implementing this methodology, a 3D U-Net discriminator undergoes modification, notably replacing batch-normalization with weight-normalization, deploying leaky ReLUs, and substituting max pooling with average pooling to stabilize GAN training. Both labeled and unlabeled data are engaged during training, alongside the GAN-generated 'fake' outputs. Feature Matching (FM) was selected as the generator strategy due to its effectiveness over the standard adversarial loss in maintaining generator-discriminator stability.
To solidify these theoretical foundations into practice, the model was tested on the iSEG-2017 and MRBrains 2013 datasets. The approach showed substantial DSC improvements over traditional 3D U-Net models, particularly when very few labeled samples were available (Figure 2, Figure 3).
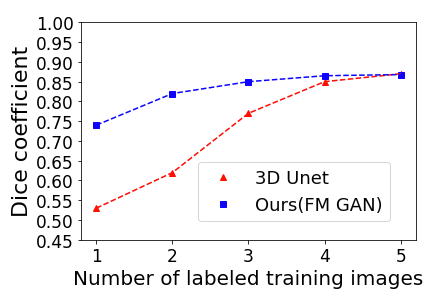
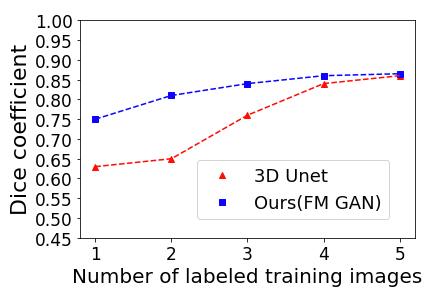
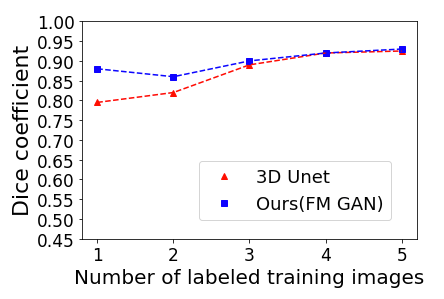
Figure 2: DSC of U-Net and our FM GAN model when training with an increasing number of labeled examples from the iSEG-2017 dataset. Performance is measured on 4 test examples, and a single validation example is used during training. For our GAN-based model, the 13 unlabeled examples of the dataset are also employed during training.
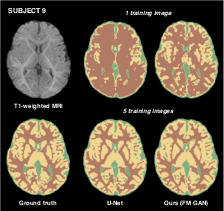
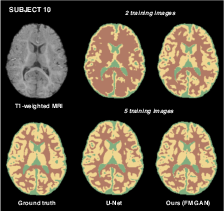
Figure 3: Visual comparison of the segmentation by each model, for two test subjects of the iSEG-2017 dataset, when training with different numbers of labeled examples.
Results and Comparisons
The technique demonstrated notable improvements in segmentation accuracy for subjects in both datasets, achieving close to full-supervision performance with the use of only 1 or 2 labeled training samples (Table 1). The feature matching approach in the generator yielded the most accurate segmentations when compared to other adversarial training strategies such as complementary generator models or standard GAN setups (Table 2).
Conclusion
This research presents a sophisticated framework for reducing the dependency on large annotated datasets in medical image segmentation. The strength of leveraging few-shot learning paired with unsupervised data through GANs offers significant advancements in scenarios where data acquisition is prohibitive. Future work could build upon this foundation by exploring extensions of this approach to other 3D segmentation tasks or integrating more diverse multi-modal datasets.
The benefits demonstrated by this framework underscore its versatility and efficacy in real-world medical imaging tasks, marking an advancement in the application of GANs for robust few-shot learning models.

