- The paper introduces a novel model-agnostic framework that uses iterative co-training between 2D and 3D models to improve segmentation performance in low-label regimes.
- It employs learning rate guided sampling to dynamically balance labeled and unlabeled data, achieving state-of-the-art Dice and Jaccard scores on LA and Pancreas datasets.
- The framework's versatile design supports various architectures and paves the way for future multi-modal and cross-domain medical imaging applications.
Semi-Supervised 3D Medical Segmentation Leveraging 2D Natural Image Pretraining
Introduction
The paper introduces a model-agnostic framework, denoted as \proposed, for semi-supervised 3D medical image segmentation that distills knowledge from vision models pretrained on 2D natural images. The approach is motivated by the observation that 2D models pretrained on large-scale natural image datasets (e.g., ADE20K, ImageNet) exhibit strong transferability to medical segmentation tasks, especially in low-data regimes. The framework is designed to address the scarcity of labeled 3D medical data by leveraging abundant unlabeled data and the rich representations learned by 2D models.
Methodology
Framework Overview
\proposed consists of two main components: a 2D segmentation model pretrained on natural images and a randomly initialized 3D segmentation model. The core innovation is an iterative co-training strategy where both models are trained using pseudo-masks generated by each other. This process is further enhanced by a learning rate guided sampling (LRG-sampling) mechanism that adaptively balances the proportion of labeled and unlabeled data in each training batch according to the models' prediction stability.
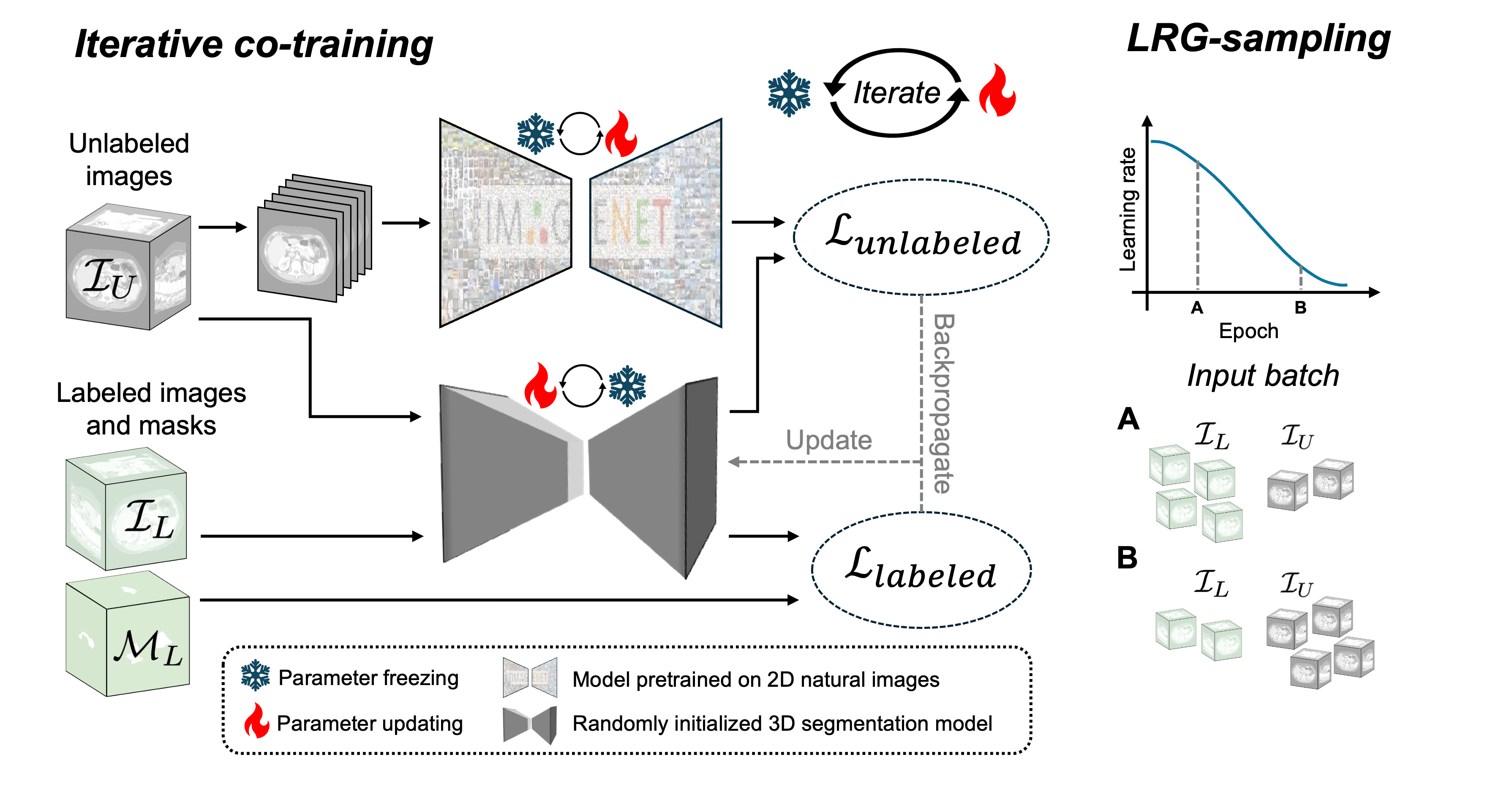
Figure 1: Pipeline of the proposed \proposed framework, illustrating iterative co-training and adaptive batch composition via LRG-sampling.
Fine-Tuning and Co-Training
- 2D Model Fine-Tuning: The 2D model is fine-tuned on labeled 3D medical images by extracting 2D slices along the depth dimension. Fine-tuning strategies include updating all weights, decoder-only fine-tuning, and LoRA-based adaptation.
- 3D Model Training: The 3D model is trained from scratch on the same labeled data.
- Iterative Co-Training: Training alternates between odd and even epochs. In odd epochs, the 2D model generates pseudo-masks for unlabeled data, which supervise the 3D model. In even epochs, the 3D model generates pseudo-masks for the 2D model. The loss function combines labeled and unlabeled losses, weighted by the batch composition.
Learning Rate Guided Sampling
LRG-sampling dynamically adjusts the ratio of labeled to unlabeled samples in each batch based on the current learning rate. Early in training, when predictions are unstable, batches contain more labeled data. As training progresses and predictions stabilize, the proportion of unlabeled data increases, maximizing the utility of pseudo-labels while minimizing the risk of propagating errors.
Loss Functions
- Labeled Loss: Combination of cross-entropy and soft Dice loss.
- Unlabeled Loss: Combination of KL-divergence and Dice loss between predictions and pseudo-masks.
- Co-Training Loss: Weighted sum of labeled and unlabeled losses, with weights determined by LRG-sampling.
Experimental Results
Datasets and Implementation
Experiments were conducted on the LA (left atrial cavity) MRI dataset and the Pancreas-CT dataset. The 2D model used was SegFormer-B2 pretrained on ADE20K and ImageNet-1K, while the 3D model was a randomly initialized 3D UNet. Training involved extensive data augmentation and a cosine learning rate schedule.
\proposed achieved state-of-the-art results across all tested settings, outperforming 13 existing semi-supervised segmentation methods. Notably, the framework demonstrated robust performance in extremely low-label regimes (4, 6, 8 labeled images), which is critical for practical clinical deployment.
- LA Dataset (8 labels): Dice score of 91.56%, Jaccard of 84.47%, HD95 of 4.59 voxels, ASD of 1.40 voxels.
- Pancreas-CT (6 labels): Dice score of 81.67%, Jaccard of 69.53%, HD95 of 6.56 voxels, ASD of 1.67 voxels.
Qualitative Analysis
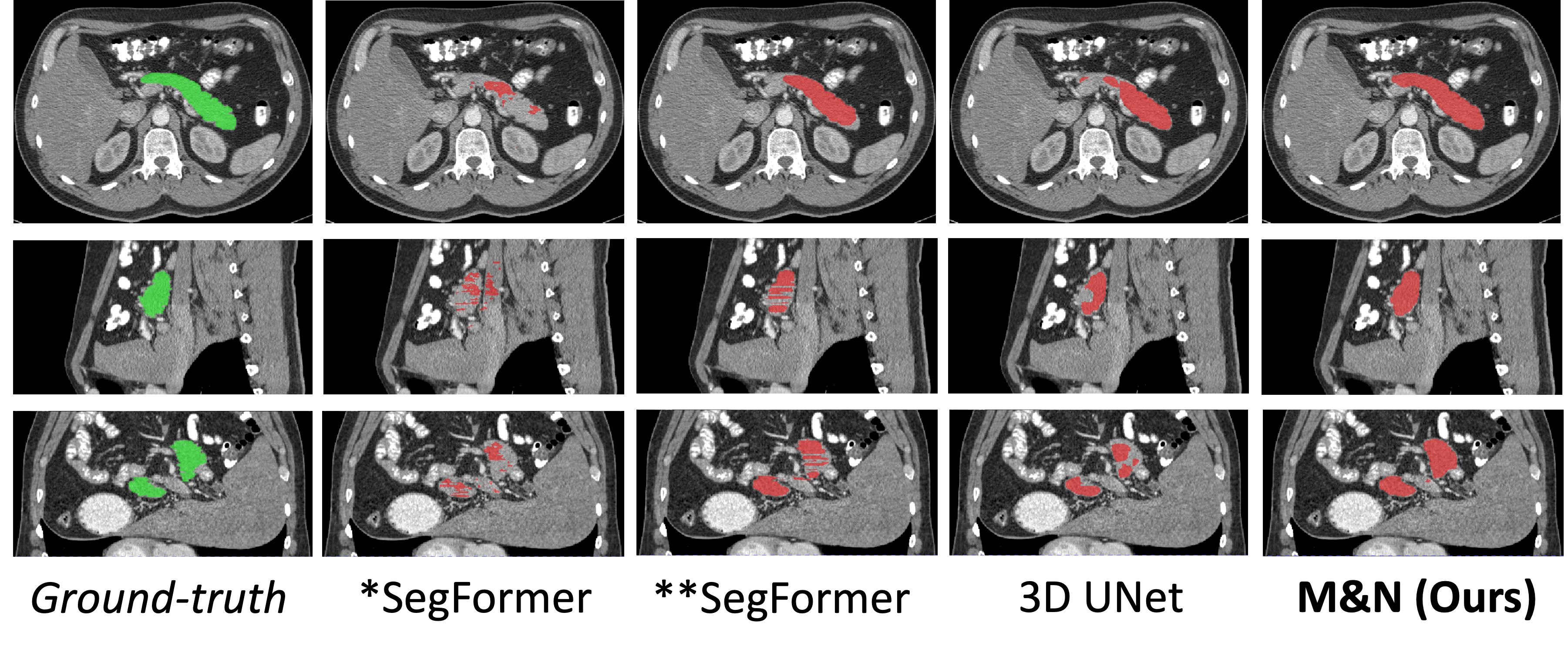
Figure 2: Qualitative segmentation results on the Pancreas-CT dataset, comparing \proposed with baseline and prior methods.
Visual inspection confirms that \proposed produces more accurate and anatomically plausible segmentations, especially in challenging cases with limited labeled data.
Ablation Studies
Ablation experiments validated the model-agnostic nature of \proposed, showing strong performance with alternative architectures (e.g., ResUNet, SwinUNETR) and fine-tuning strategies. The iterative co-training and LRG-sampling components were shown to be critical for optimal performance; removing either led to significant drops in accuracy.
Implementation Considerations
- Computational Requirements: Training involves two models and iterative pseudo-label generation, requiring substantial GPU memory and compute, especially for large 3D volumes.
- Scalability: The framework is compatible with any 2D/3D architecture, facilitating future integration with more advanced models.
- Deployment: Inference is performed via patch-based sampling with overlap and averaging, ensuring full volume coverage and robust predictions.
- Limitations: The reliance on pseudo-masks introduces potential error propagation; LRG-sampling mitigates but does not eliminate this risk.
Implications and Future Directions
The results demonstrate that knowledge distilled from 2D natural image pretraining can substantially improve 3D medical segmentation in data-scarce scenarios. The model-agnostic design ensures adaptability to future advances in vision architectures. The framework's success suggests broader applicability to other medical imaging tasks, such as registration and detection, and highlights the value of cross-domain transfer learning.
Potential future developments include:
Conclusion
\proposed establishes a robust, flexible paradigm for semi-supervised 3D medical segmentation by leveraging 2D natural image pretraining and iterative co-training. The framework achieves superior performance in low-label regimes, is agnostic to model architecture, and is well-positioned for future integration with emerging vision models and medical imaging tasks.