- The paper demonstrates that random seed selection critically affects LSTM performance in sequence tagging, recommending the reporting of score distributions over single scores.
- Methodologically, the study evaluates 50,000 LSTM configurations across five tasks, revealing that CRF classifiers and variational dropout techniques improve model stability.
- Results indicate that using optimizers like Nadam reduces performance variance, underscoring the importance of statistical rigor in neural network evaluation.
Introduction
The paper "Reporting Score Distributions Makes a Difference: Performance Study of LSTM-networks for Sequence Tagging" (1707.09861) investigates the implications of non-deterministic behavior in neural networks, particularly LSTM architectures, for sequence tagging tasks. The primary observation is that the performance of these models is heavily dependent on the random seed value used during training. This variance can lead to significant differences in perceived performance, challenging the validity of comparisons based on single performance scores. The authors propose reporting score distributions instead of single scores to provide a more accurate comparison.
Impact of Randomness in Neural Network Evaluation
The paper illustrates that different initializations in neural networks can lead to divergent performances due to the non-convex nature of the error function. This dependence on random initialization is emphasized using two state-of-the-art Named Entity Recognition (NER) systems developed by Ma and Hovy (2016) and Lample et al. (2016). Both systems were re-evaluated multiple times with different seed values, showing that the previously reported conclusions about their comparative performance may be misleading.
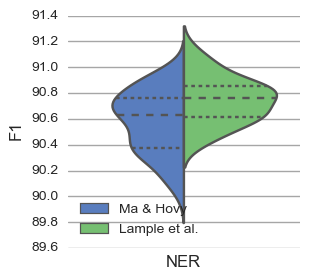
Figure 1: Distribution of scores for re-running the system by Ma and Hovy (left) and Lample et al.\ (right) multiple times with different seed values. Dashed lines indicate quartiles.
Methodology
The study evaluated 50,000 LSTM configurations across five sequence tagging tasks: Part-of-Speech tagging, Chunking, NER, Entity Recognition, and Event Detection. Various architectures and hyperparameters were tested, including different word embeddings, character representations, optimizers, and regularization strategies. The evaluation focused on determining not only superior performance but also stability across configurations.
A key takeaway is that comparing score distributions can more reliably inform researchers about the capabilities of algorithms, as opposed to relying on single best-case scores.
Results
The paper presents several critical insights regarding the architecture and training of LSTM networks:
- Character Representation: Both CNN and LSTM-based character embeddings showed improvements over not using character representations, though there was no statistically significant difference between the two approaches.
- Classifier Choice: CRF classifiers generally outperformed Softmax classifiers, particularly when used in conjunction with deeper LSTM networks.
- Optimizers: Nadam, an Adam variant, exhibited superior performance in terms of both convergence speed and stability, significantly reducing the standard deviation of results compared to other optimizers like SGD or Adagrad.
- Dropout Types: Variational dropout, which applies consistent dropout masks across time steps, yielded the best results in reducing overfitting and improving model robustness.
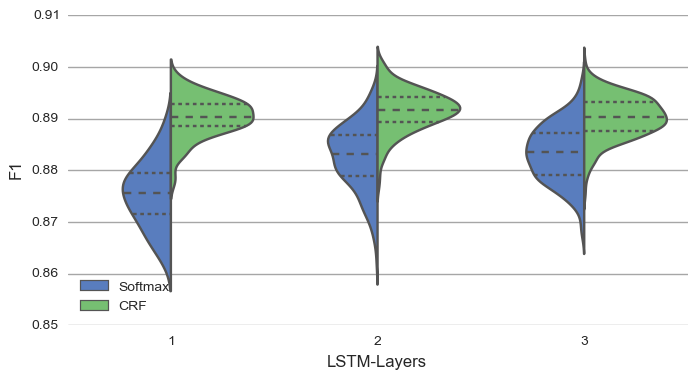
Figure 2: Difference between Softmax and CRF classifier for different number of BiLSTM-layers for the CoNLL 2003 NER dataset.
Implications and Future Work
The findings have wide implications for the development and evaluation of neural networks in NLP. By encouraging the use of score distributions, the paper addresses the reproducibility challenge in deep learning research. Recognizing the role of randomness can better guide the selection and tuning of hyperparameters, reducing the likelihood of dismissing potentially effective models due to a poor initial random seed.
The paper suggests future work could explore methods for minimizing the impact of random seed variability, potentially by investigating specific training techniques or model architectures that inherently exhibit less sensitivity to random initialization.
Conclusion
The paper argues persuasively for a shift in evaluation practice from reporting single scores to using distributions in assessing neural networks. This shift has the potential to refine our understanding of model performance and guide more reliable comparison and selection of machine learning approaches. The research underscores the complexity of deep learning model evaluation and the necessity of robust statistical methods to ensure comparative fairness and accuracy.