HCFT: Hierarchical Convolutional Fusion Transformer for EEG Decoding
Abstract: Electroencephalography (EEG) decoding requires models that can effectively extract and integrate complex temporal, spectral, and spatial features from multichannel signals. To address this challenge, we propose a lightweight and generalizable decoding framework named Hierarchical Convolutional Fusion Transformer (HCFT), which combines dual-branch convolutional encoders and hierarchical Transformer blocks for multi-scale EEG representation learning. Specifically, the model first captures local temporal and spatiotemporal dynamics through time-domain and time-space convolutional branches, and then aligns these features via a cross-attention mechanism that enables interaction between branches at each stage. Subsequently, a hierarchical Transformer fusion structure is employed to encode global dependencies across all feature stages, while a customized Dynamic Tanh normalization module is introduced to replace traditional Layer Normalization in order to enhance training stability and reduce redundancy. Extensive experiments are conducted on two representative benchmark datasets, BCI Competition IV-2b and CHB-MIT, covering both event-related cross-subject classification and continuous seizure prediction tasks. Results show that HCFT achieves 80.83% average accuracy and a Cohen's kappa of 0.6165 on BCI IV-2b, as well as 99.10% sensitivity, 0.0236 false positives per hour, and 98.82% specificity on CHB-MIT, consistently outperforming over ten state-of-the-art baseline methods. Ablation studies confirm that each core component of the proposed framework contributes significantly to the overall decoding performance, demonstrating HCFT's effectiveness in capturing EEG dynamics and its potential for real-world BCI applications.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper introduces a new computer model called HCFT (Hierarchical Convolutional Fusion Transformer) that reads brain signals (EEG) and tries to understand them. The goal is to make EEG decoding more accurate and reliable for different people and tasks, like recognizing imagined hand movements or predicting seizures.
What questions the paper tries to answer
The researchers wanted to know:
- How can we build a model that understands both short, quick brain signal changes and longer, bigger patterns at the same time?
- Can we combine the strengths of two popular tools—convolutions (good at local details) and Transformers (good at long-range connections)—to decode EEG better?
- Will this model work well across different people and tasks, not just a single subject?
- Can we keep the model small and stable during training, so it’s practical to use?
How the model works (in everyday terms)
Think of EEG signals like many tiny microphones placed on your head, each recording a wavy line over time. HCFT tries to make sense of these waves using a few clever steps:
- Dual-branch “listening”:
- Time branch: Like sliding a small window along each microphone’s recording to catch quick beats and rhythms.
- Space-time branch: Like looking at a grid made from all microphones over time to spot patterns that happen across different places on the head at once.
- Cross-attention (branches compare notes): The time branch acts like a guide, helping the space-time branch focus on moments that really matter—similar to two friends sharing notes and highlighting important parts so they agree on what’s important.
- Hierarchical Transformer (multi-scale understanding): The model processes the signals in stages—starting with fine details and gradually stepping back to see bigger patterns, like zooming out from a close-up to a full map and then combining all views.
- Dynamic Tanh normalization (training stabilizer): A simple, learnable way to keep the values from exploding or shrinking too much during training—think of it like a volume controller that keeps the sound level comfortable, making training smoother. It sometimes replaces a standard tool called LayerNorm.
Together, these parts help the model capture:
- Local rhythms (short moments),
- Patterns across different EEG channels (places on the head),
- And long-range dependencies (things that happen far apart in time).
What the study found and why it matters
The model was tested on two well-known tasks:
- Motor imagery (BCI Competition IV-2b): The task is to tell if someone is imagining moving their left or right hand, using 3 EEG electrodes. The model got about 80.83% average accuracy and a Cohen’s kappa of 0.6165. Kappa is a fairness score that shows how much better the model is than random guessing—even when the classes are imbalanced. HCFT beat more than ten other strong methods and was more consistent across different people.
- Seizure prediction (CHB-MIT dataset): The task is to predict seizures before they happen, using many EEG channels. HCFT reached 99.10% sensitivity (it catches almost all seizures), 98.82% specificity (it usually avoids false alarms), and only 0.0236 false positives per hour (very few “wrong” alerts). This is excellent for practical, real-world use.
The researchers also did “ablation” tests—turning off parts of the model one by one—to see if each piece really helps. Performance dropped when they removed the cross-attention, self-attention, or multi-scale fusion, showing that all parts are important.
Why it matters:
- Better decoding of EEG could help brain-computer interfaces be more reliable for more people.
- Fewer false alarms in seizure prediction can make real healthcare systems safer and less stressful.
- The model is relatively lightweight and designed to be stable, making it more practical to deploy.
What this could mean for the future
If models like HCFT continue to improve, we could see:
- More accurate brain-computer interfaces for communication, rehabilitation, and gaming.
- Earlier and more reliable seizure warnings, giving patients and families more time to prepare.
- Systems that adapt better to new users without lots of re-training.
The paper also notes challenges, like choosing the best settings for different datasets and making sure the model works perfectly across many diverse people. Future work could focus on automatic tuning and using more varied data to make the model even more general and robust.
Knowledge Gaps
Unresolved knowledge gaps, limitations, and open questions
Below is a single, focused list of what remains missing, uncertain, or unexplored in the paper. Each point is phrased to be concrete and actionable for future research.
- Evaluation protocol clarity: The text alternates between a subject-wise 70/30 split and leave-one-out evaluation for CHB-MIT; provide a unified, clearly specified protocol and re-run experiments to eliminate ambiguity.
- Apples-to-apples comparison on CHB-MIT: Baselines use varied patient exclusions and SOP/SPH settings; re-evaluate all methods under the same patient set and identical SOP/SPH to enable fair comparison.
- SOP/SPH sensitivity: Report HCFT performance across multiple seizure occurrence periods (e.g., 30/5, 60/5 minutes) and prediction horizons to assess robustness to clinical design choices.
- Missing metrics for seizure prediction: Provide AUC, time-to-warning (TTW), warning duration (TiW), and alarm latency analyses; detail threshold selection procedures used to compute FPR/h.
- Statistical rigor: Clarify statistical tests used for p-values, apply multiple-comparison corrections, and report confidence intervals and effect sizes (per subject and overall).
- Potential data leakage: Specify whether z-score normalization and any scaler or filter parameters are fit on training only and applied to test; detail how contiguous time windows are split to prevent temporal leakage.
- Generalization beyond two datasets: Evaluate HCFT on diverse EEG tasks (e.g., emotion recognition, P300/SSVEP, sleep staging, cognitive workload) and across datasets with different populations and recording conditions.
- Cross-device, cross-session transfer: Test robustness to changes in hardware, electrode montage, and session-to-session variation; include domain-shift and cross-session generalization experiments.
- Channel variability and missing channels: Assess performance on high-density EEG (64–128 channels), sparse montages, and with random channel dropouts; introduce channel-robust mapping or imputation strategies.
- Noise/artifact robustness: Quantify sensitivity to EOG/EMG artifacts, motion, and powerline noise; evaluate under varied SNRs and artifact removal pipelines and/or augmentations.
- Real-time deployment: Report inference latency, memory footprint, and energy use on edge hardware (e.g., embedded CPU/GPU, mobile SoC); characterize end-to-end decoding delay and throughput.
- DyT normalization analysis: Provide theoretical or empirical characterization of DyT’s stability, gradient dynamics, and capacity vs LayerNorm; reconcile the “no inference overhead” claim with observed increases in parameters/FLOPs and measure actual inference latency.
- Adaptive normalization: Explore mechanisms to automatically select or mix DyT and LayerNorm per layer/task/subject (e.g., gating, meta-learning) rather than manual dataset-specific tuning.
- Cross-attention design choices: Compare temporal→spatiotemporal conditioning to alternatives (spatiotemporal→temporal, bidirectional co-attention, symmetric fusion); quantify effects per stage and task.
- Multi-scale fusion strategy: Benchmark “one-shot” concatenation + MHSA against progressive fusion, gated fusion, attention-based pooling per stage, and hierarchical co-attention to determine the most efficient/accurate integration.
- Temporal kernel size and spectral coverage: The fixed kernel length (15) targets 8–30 Hz; evaluate task-dependent, subject-adaptive kernel sizes, multi-band convolutions, and explicit spectral modeling (e.g., learnable filter banks).
- Long-context modeling for seizure prediction: Current 5-second epoch classification lacks inter-epoch sequence modeling; study temporal aggregation (e.g., Transformers/RNNs across epochs), alarm smoothing rules, and their impact on FPR/h and TTW.
- Class imbalance handling: Detail strategies for preictal/interictal imbalance (e.g., weighted/focal loss, balanced sampling) and analyze sensitivity-specificity trade-offs under different class priors.
- Positional encoding choices: Evaluate sinusoidal, relative positional encodings, or rotary embeddings and their effect on temporal order sensitivity and performance across tasks.
- Downsampling choices: Compare average pooling to strided/learnable pooling or anti-aliasing filters; quantify aliasing effects and spectral fidelity loss across stages.
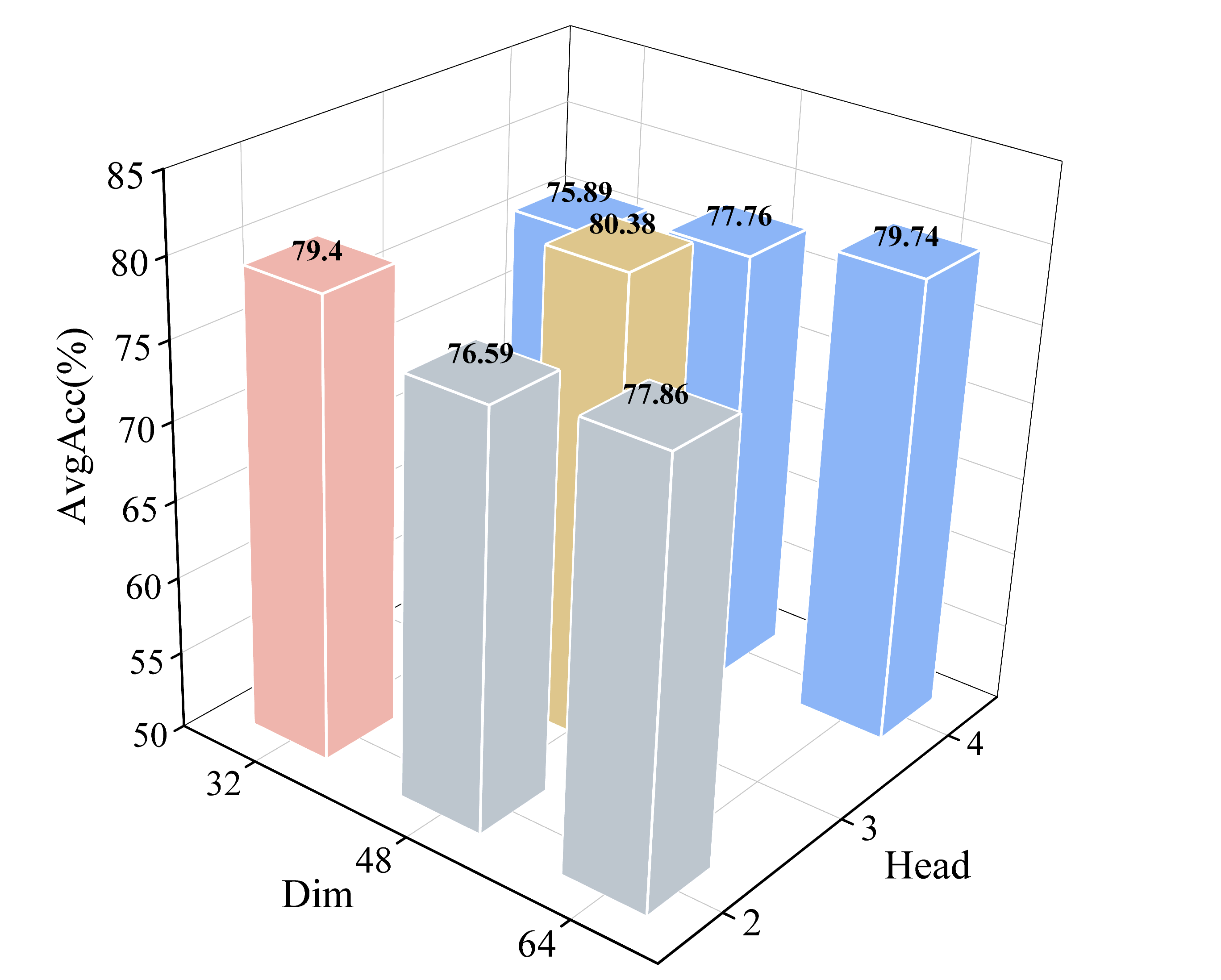
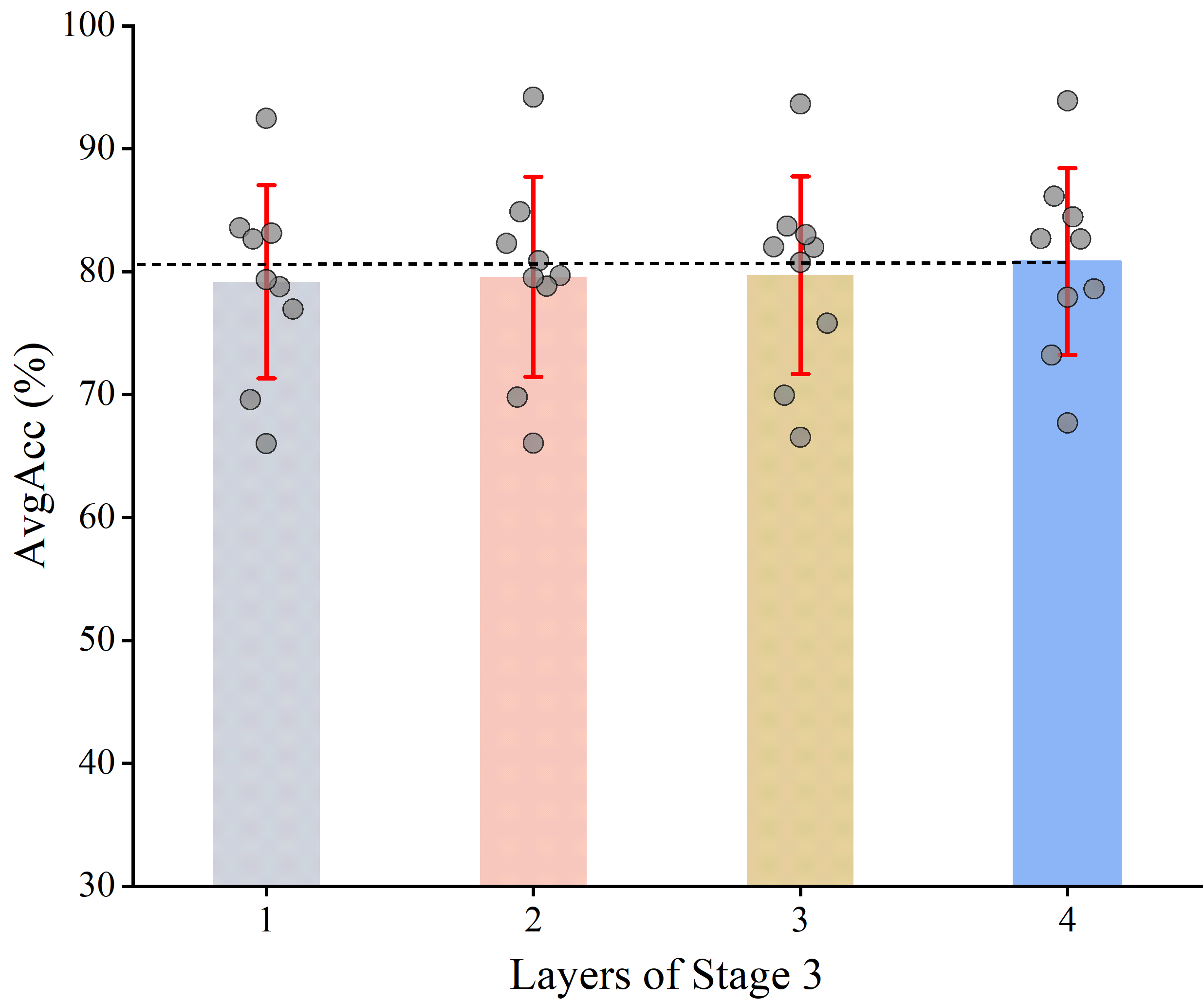
- Scaling behavior: Investigate how performance scales with model depth/width, number of heads, and data size; provide compute–performance scaling laws and guidance for resource-constrained settings.
- Reproducibility and specification: Correct typos and ambiguous equations (tensor shapes, attention projections) and release end-to-end code, seeds, preprocessing scripts, and detailed hyperparameters (including DyT settings).
- Interpretability validation: Move beyond qualitative attention heatmaps to quantitative tests (e.g., perturbation importance, occlusion studies) and validate alignment with neurophysiology (e.g., C3/C4 for MI); assess stability across random seeds.
- Personalization and adaptation: Evaluate few-shot/on-line adaptation for subject-specific performance, address catastrophic forgetting, and quantify gains vs generalized models.
- Domain shift and non-stationarity: Test robustness to long-term drift, medication changes, electrode re-placement; explore unsupervised or continual domain adaptation strategies.
- Clinical safety and workflow: Conduct prospective evaluations with practical alarm management (refractory periods, escalation policies), quantify false alarm burden in realistic monitoring scenarios, and analyze clinical utility.
- Fairness and population diversity: CHB-MIT comprises pediatric scalp recordings; assess HCFT on adult cohorts and varied demographics to evaluate fairness and generalizability.
Glossary
- Ablation studies: Experiments removing components to measure their individual impact on performance. "Ablation studies confirm that each core component of the proposed framework contributes significantly to the overall decoding performance"
- AdamW optimizer: An adaptive optimizer with decoupled weight decay for better generalization. "The model was trained using the AdamW optimizer with an initial learning rate of 0.001 and a weight decay of 0.00125."
- alpha/beta rhythm band (α/β): EEG frequency bands (~8–30 Hz) linked to cognitive/motor processes. "effectively covering the 8â30 Hz rhythm band that is critical for cognitive decoding."
- Area Under the ROC Curve (AUC): A performance metric summarizing the trade-off between true and false positive rates across thresholds. "the Area Under the ROC Curve (AUC)."
- Average pooling: Downsampling by averaging values within a kernel window. "Between stages, temporal resolution is reduced through average pooling,"
- BCI Competition IV-2b: A benchmark EEG dataset for motor imagery classification. "Extensive experiments are conducted on two representative benchmark datasets, BCI Competition IV-2b and CHB-MIT,"
- Bipolar channels: EEG derivations formed by the difference between two adjacent electrodes. "we retain 18 standardized bipolar channels."
- Butterworth band-stop filter: A filter with maximally flat passband used to attenuate specific frequency bands. "Noise artifacts are suppressed using a sixth-order Butterworth band-stop filter targeting powerline harmonics (57â63 Hz and 117â123 Hz)"
- Cohenâs kappa: A statistic measuring agreement beyond chance, robust to class imbalance. "a Cohenâs kappa of 0.6165"
- Conditional cross-attention: An attention mechanism where one feature stream guides another during fusion. "A conditional cross-attention mechanism then uses the temporal features as queries to guide the spatiotemporal branch,"
- Convolutional Fusion Transformer (CFT) Block: The model’s core module combining convolutional encoders with attention-based fusion. "a unified Convolutional Fusion Transformer (CFT) Block, which integrates Multi-Head Self-Attention (MHSA), Multi-Head Cross-Attention (MHCA), and an expanded feed-forward network."
- Cosine annealing scheduler: A learning-rate schedule that decays following a cosine curve over cycles. "A cosine annealing scheduler with a maximum cycle length of 32 epochs was used for learning rate adjustment."
- Cross-entropy loss: A classification loss function measuring the difference between predicted and true distributions. "followed by normalization (LayerNorm or DyT), global average pooling, and a fully connected layer for classification (trained using cross-entropy loss):"
- Cross-subject validation: Evaluation protocol testing generalization to unseen participants. "performing well in cross-subject validation."
- Depthwise separable convolution: A factorized convolution using per-channel spatial filters followed by pointwise mixing. "Depthwise separable convolutions are applied independently across EEG channels to extract localized rhythms,"
- Dynamic Tanh Normalization (DyT): A learnable tanh-based normalization alternative to LayerNorm for stability. "we optionally incorporate a Dynamic Tanh Normalization (DyT) module"
- Embedding dimension: The size of the vector space used to represent tokens/features. "into a unified embedding space with dimension D."
- False Positive Rate per hour (FPR/h): The expected number of false alarms per hour in detection tasks. "the False Positive Rate per hour (FPR/h)"
- Feedforward Network (FFN): The MLP sublayer in Transformer blocks for non-linear feature transformation. "Feedforward Network (FFN)."
- FLOPs: Floating point operations, used to estimate computational cost. "both the model size (#Param) and FLOPs significantly increase."
- GELU: Gaussian Error Linear Unit, a smooth activation function. "Batch normalization, GELU activation, and dropout are applied for regularization and stability."
- Global average pooling (GAP): Operation that averages spatial/temporal features to a single vector. "followed by normalization (LayerNorm or DyT), global average pooling, and a fully connected layer for classification"
- Hierarchical encoder: Multi-stage architecture that progressively abstracts representations across scales. "HCFT adopts a multi-stage hierarchical encoder,"
- High-pass filter: A filter that removes low-frequency components such as baseline drift. "followed by a 1 Hz high-pass filter to eliminate baseline drift."
- Ictal: The period during a seizure event. "with explicit exclusion of ictal activity,"
- Interictal: Periods between seizures without ictal activity. "Interictal samples are drawn from seizure-free periods,"
- LayerNorm: Layer Normalization; normalizes features across channels per sample. "conventional LayerNorm"
- Leave-One-Out Cross-Validation (LOOCV): Validation where one subject/session is held out per fold. "LOOCV: Leave-One-Out Cross-Validation;"
- Leave-one-subject-out (LOSO) protocol: Cross-subject evaluation where each subject is held out in turn for testing. "we adopt a leave-one-subject-out (LOSO) protocol:"
- Learnable positional embeddings: Trainable vectors encoding sequence order for attention models. "HCFT integrates learnable positional embeddings"
- Long-context pooling: A pooling strategy to condense long sequences into compact representations. "A subsequent long-context pooling operation condenses this information into a compact representation,"
- Multi-Head Cross-Attention (MHCA): Attention mechanism using multiple heads to fuse information across modalities/branches. "integrates Multi-Head Self-Attention (MHSA), Multi-Head Cross-Attention (MHCA), and an expanded feed-forward network."
- Multi-Head Self-Attention (MHSA): Parallel attention heads capturing dependencies within a sequence. "integrates Multi-Head Self-Attention (MHSA), Multi-Head Cross-Attention (MHCA), and an expanded feed-forward network."
- Pointwise convolution: 1×1 convolution used for channel mixing and projection. "pointwise convolutions are applied"
- Pre-Norm: Transformer variant applying normalization before attention/FFN sublayers. "A Pre-Norm structure is adopted,"
- Preictal: Time window preceding a seizure used for prediction tasks. "The preictal class is defined as epochs occurring within the 30-minute window preceding a seizure onset."
- Pyramid Vision Transformer (PVT): A hierarchical Transformer backbone with multi-scale token representations. "Inspired by the Pyramid Vision Transformer (PVT)"
- Pyramidal architecture: Design that reduces resolution across stages to enable multi-scale modeling efficiently. "This pyramidal architecture, inspired by designs such as the Swin Transformer, supports efficient multi-scale modeling"
- Sensitivity (Sens): Proportion of actual positives correctly identified (true positive rate). "In seizure detection tasks using the CHB-MIT dataset, we adopt domain-specific metrics: Sensitivity (Sens), Specificity (Spec), the False Positive Rate per hour (FPR/h), and the Area Under the ROC Curve (AUC)."
- Specificity (Spec): Proportion of actual negatives correctly identified (true negative rate). "In seizure detection tasks using the CHB-MIT dataset, we adopt domain-specific metrics: Sensitivity (Sens), Specificity (Spec), the False Positive Rate per hour (FPR/h), and the Area Under the ROC Curve (AUC)."
- State-of-the-art (SOTA): The best-performing methods at the time of writing. "consistently outperforming over ten state-of-the-art baseline methods."
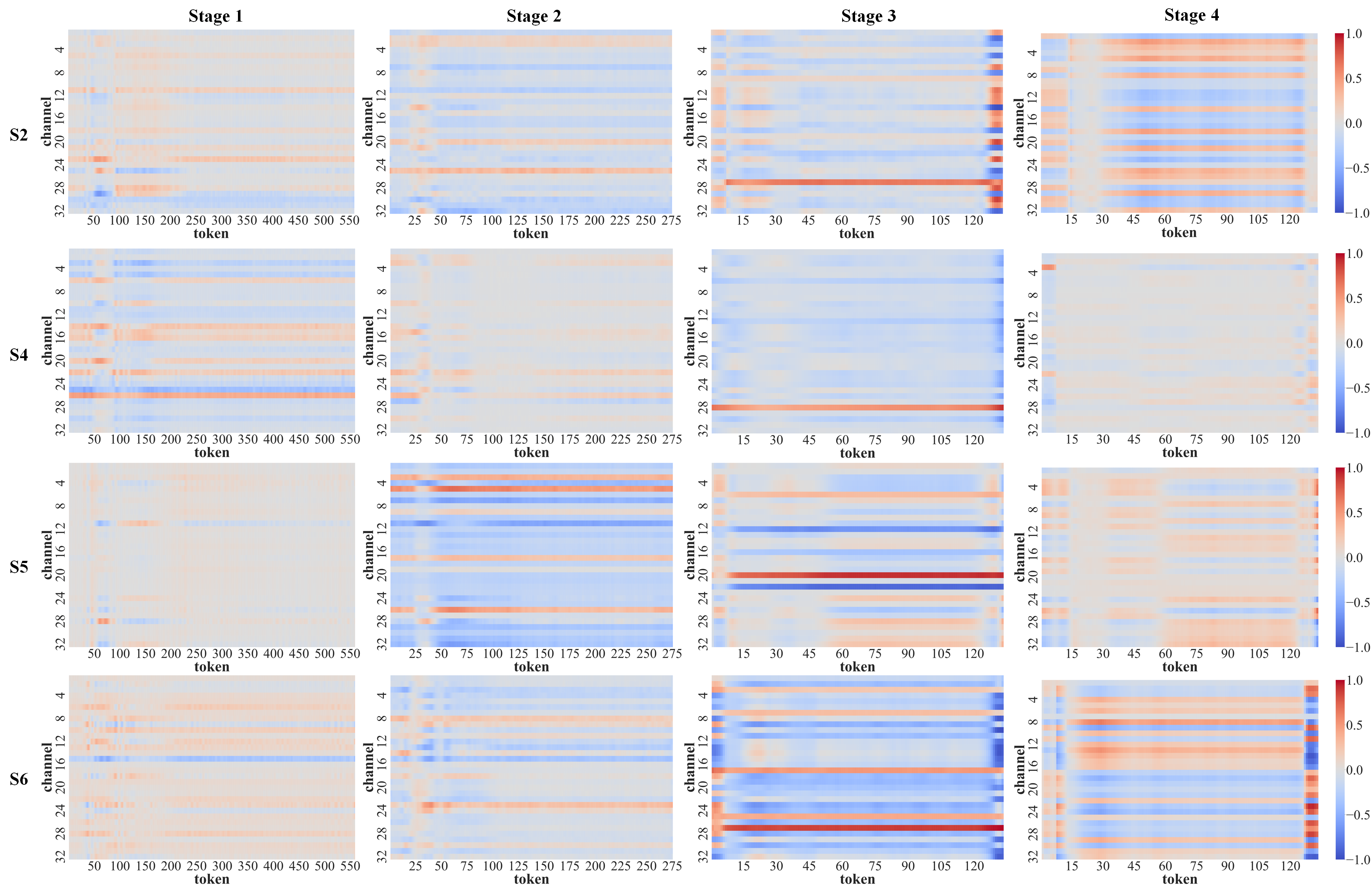
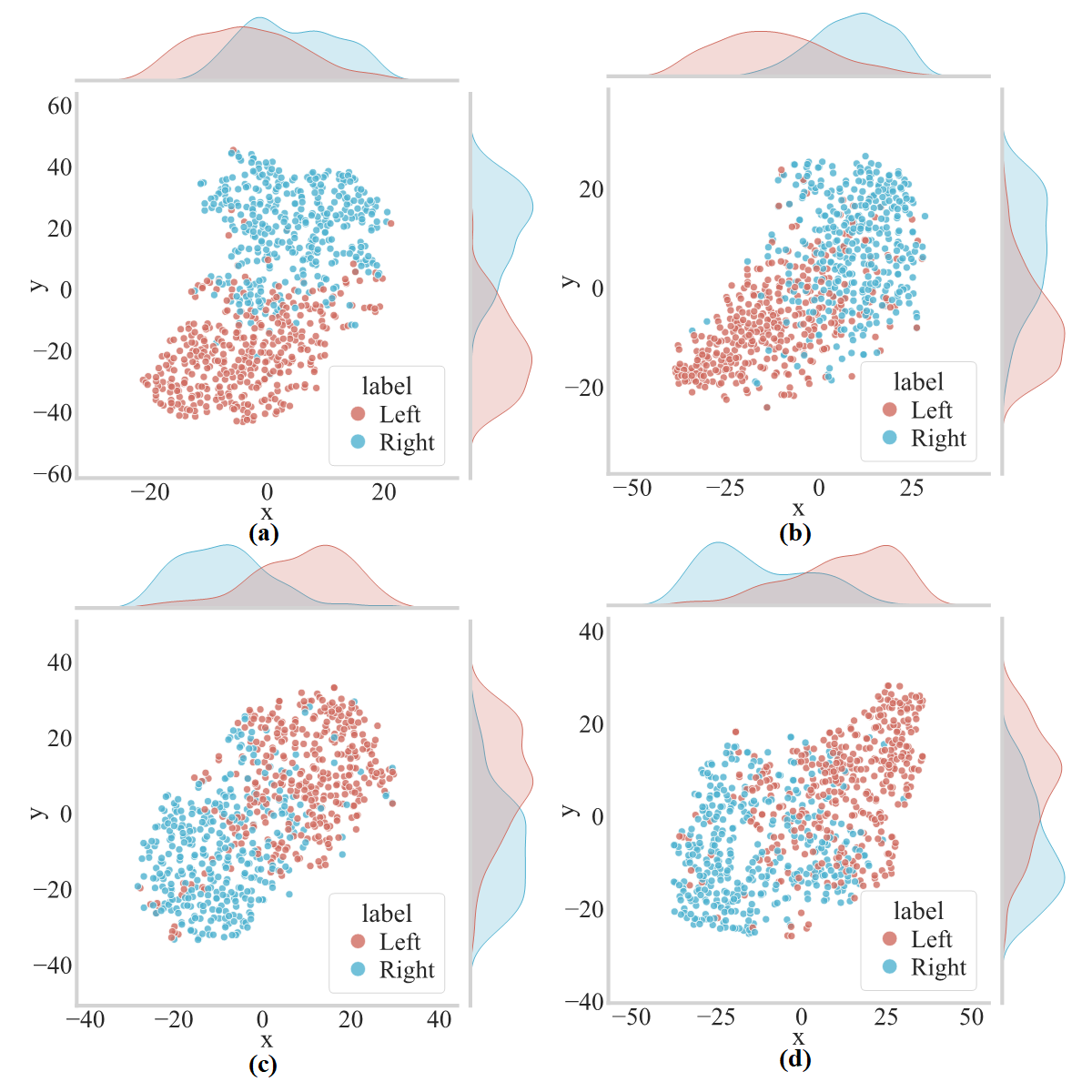
- t-SNE: Nonlinear dimensionality reduction technique for visualization. "the t-SNE visualization revealed two well-separated clusters"
- Token: A vectorized patch/segment used as a unit of processing in Transformer models. "Tokens from different hierarchical stages are concatenated and integrated via self-attention."
- Weight decay: Regularization adding L2 penalty on weights to prevent overfitting. "with an initial learning rate of 0.001 and a weight decay of 0.00125."
- Z-score normalization: Standardization to zero mean and unit variance per feature/channel. "All trials are z-score normalized on a per-channel basis"
Practical Applications
Immediate Applications
The following applications can be deployed now, leveraging HCFT’s demonstrated performance on motor imagery (MI) classification and seizure prediction, its lightweight design, and available implementation details.
- EEG-based seizure early warning and triage in hospital monitoring
- Sector: healthcare
- What it does: Integrates HCFT into bedside or central monitoring systems to flag preictal states with low false positives (≈0.0236/h), aiding clinicians in proactive interventions.
- Tools/workflow: Standard scalp EEG acquisition; preprocessing pipeline (band-stop for powerline noise, high-pass, z-score normalization); on-prem inference server (PyTorch); alerting dashboard integrated with hospital systems.
- Assumptions/dependencies: Regulatory approval; comparable channel montage to CHB-MIT subset; real-time data streaming with low latency; robust artifact handling; clinical SOP/SPH alignment.
- Rapid cross-subject BCI calibration for binary MI commands
- Sector: robotics, accessibility, human–machine interaction
- What it does: Uses HCFT’s cross-subject robustness (≈80.83% average accuracy) to shorten per-user calibration for simple left/right MI control (e.g., switches, wheelchair toggles, simple robot teleoperation).
- Tools/workflow: Pretrained HCFT weights; brief user-specific fine-tuning; integration with BCI frameworks (e.g., LabStreamingLayer/OpenBCI); feedback loop for calibration.
- Assumptions/dependencies: Consistent electrode placement (C3, Cz, C4), minimal motion artifacts; user training effort; safety constraints for device actuation.
- Clinical research baseline for EEG decoding
- Sector: academia, healthcare research
- What it does: Serves as a reproducible baseline for MI and seizure prediction studies under cross-subject protocols (LOSO, subject-wise splits); supports ablations and attention visualizations for interpretability.
- Tools/workflow: PyTorch 2.0 implementation; scripts for DyT vs LayerNorm selection; standardized preprocessing; metrics (accuracy, kappa; sensitivity, specificity, FPR/h).
- Assumptions/dependencies: Access to labeled EEG datasets; GPU/CPU resources; adherence to dataset-specific preprocessing.
- Attention-guided channel quality assurance
- Sector: healthcare, research
- What it does: Uses HCFT’s channel/token attention maps to identify poorly contributing or noisy electrodes, improving technician workflows and data quality.
- Tools/workflow: Attention heatmap viewer; real-time QC indicators during setup; feedback to re-seat electrodes or adjust montage.
- Assumptions/dependencies: Reliable attention interpretability at the channel level; acceptance in clinical workflows; variability across subjects.
- Lightweight edge inference for closed-loop neurofeedback
- Sector: software, wellness/consumer neurotech
- What it does: Deploys HCFT (e.g., D=32, 2 heads) on embedded platforms (Jetson-class, small PCs) to deliver real-time neurofeedback based on MI or seizure risk indicators.
- Tools/workflow: Stream-processing with low-latency preprocessing; on-device inference; simple feedback interface (audio/visual cues).
- Assumptions/dependencies: Adequate compute/power; buffering strategy; model compression/quantization if needed; consumer-grade EEG data quality.
- Automated seizure diary enrichment
- Sector: healthcare software
- What it does: Enhances seizure diaries by auto-tagging preictal periods and suspected events from continuous EEG, improving longitudinal tracking.
- Tools/workflow: Cloud service ingesting EEG streams or uploads; HCFT inference; event API to patient apps/EHR systems; clinician review queue.
- Assumptions/dependencies: Data privacy and consent; interoperability (FHIR/EHR integration); device–app connectivity; false alarm management.
- Teaching and training modules in signal processing and AI
- Sector: education
- What it does: Provides a modern, compact example of dual-branch CNN + Transformer fusion, cross-attention, and hierarchical multi-scale modeling for coursework and labs.
- Tools/workflow: Assignments using public EEG datasets; ablation studies; visualization exercises; reproducible notebooks.
- Assumptions/dependencies: Student access to basic compute; curated datasets; institutional licensing for required software.
- Standardized preprocessing and evaluation workflow adoption
- Sector: academia, healthcare
- What it does: Promotes consistent filtering, segmentation, LOSO splits, and reporting (AUC, sensitivity, FPR/h) across studies and pilots.
- Tools/workflow: Shared pipeline scripts; documentation; evaluation harness.
- Assumptions/dependencies: Agreement on SOP/SPH; compatibility with diverse montages; willingness to adhere to standardized metrics.
Long-Term Applications
These applications require further research, scaling, validation, regulatory clearance, or adaptation to new domains and hardware.
- Ambulatory seizure forecasting with consumer-grade wearables
- Sector: healthcare, consumer neurotech
- What it could do: Deliver continuous, at-home seizure risk prediction using fewer-channel headbands, with smartphone alerts.
- Tools/workflow: BLE-enabled EEG wearables; mobile inference or edge/cloud hybrid; robust artifact suppression; longitudinal personalization.
- Assumptions/dependencies: Generalization to low-channel, noisy devices; battery and compute constraints; regulatory and reimbursement pathways; user adherence.
- Plug-and-play, minimal- or zero-calibration BCIs
- Sector: robotics, accessibility, HMI
- What it could do: Enable immediate use of MI BCIs across users/devices with meta-learning/adaptive layers, minimizing per-user training.
- Tools/workflow: Subject-agnostic pretraining; online adaptation; uncertainty estimation; safety gating for actuators.
- Assumptions/dependencies: Robust cross-hardware generalization; adaptive normalization strategies; safeguards for misclassification.
- Multimodal human state decoding (EEG + additional sensors)
- Sector: transportation safety, ergonomics, affective computing
- What it could do: Use HCFT-style cross-attention to fuse EEG with EOG/EMG/PPG/eye tracking for workload, drowsiness, or stress detection.
- Tools/workflow: Synchronized multimodal acquisition; fusion transformers; domain-specific labels; deployment dashboards.
- Assumptions/dependencies: High-quality multimodal datasets; domain generalization; clear operational thresholds; ethical oversight.
- Closed-loop therapeutic neuromodulation
- Sector: medical devices
- What it could do: Trigger neurostimulation (e.g., VNS/TNS/DBS) based on model detection of preictal dynamics to reduce seizure likelihood.
- Tools/workflow: Low-latency detection; hardware integration with stimulators; safety/efficacy trials; clinician-configurable policies.
- Assumptions/dependencies: Precise timing (SPH, SOP tuning); robust fail-safes; comprehensive regulatory studies; patient-specific adaptation.
- Cognitive monitoring in safety-critical operations
- Sector: industrial operations, aviation, energy grid operations
- What it could do: Monitor operators’ cognitive states to prevent incidents; trigger breaks or assistance when risk increases.
- Tools/workflow: Lightweight headsets; privacy-preserving analytics; incident correlation; policy-compliant alerting.
- Assumptions/dependencies: Acceptability and ethics; robust real-world generalization; legal frameworks; clear cost–benefit evidence.
- Cross-site clinical analytics and decision support
- Sector: healthcare IT
- What it could do: Standardize EEG analytics across hospitals, integrating HCFT outputs into EHRs for decision support and longitudinal population analytics.
- Tools/workflow: Data pipelines; governance; calibration across montages; model monitoring and drift detection.
- Assumptions/dependencies: Interoperability; data sharing agreements; model retraining policies; clinician trust and oversight.
- Benchmarking and standards for EEG decoding
- Sector: academia, policy
- What it could do: Inform guidelines on cross-subject evaluation, SOP/SPH definitions, reporting of FPR/h, and attention-based interpretability.
- Tools/workflow: Consortium datasets; reference implementations; reproducibility audits; policy briefs.
- Assumptions/dependencies: Community consensus; funding for dataset curation; engagement with regulators.
- Energy-efficient hardware acceleration of HCFT
- Sector: semiconductor/embedded systems
- What it could do: Implement hierarchical fusion attention and separable convolutions on FPGAs/ASICs for low-power, real-time decoding in wearables.
- Tools/workflow: Model compression and quantization; hardware-aware training; RTL design; on-chip signal preprocessing.
- Assumptions/dependencies: Sustained accuracy under quantization; cost of custom silicon; device certification.
- Mental health and affective computing applications
- Sector: digital therapeutics, wellness
- What it could do: Adapt HCFT to emotion recognition, stress detection, or attention training (building on transformer successes in affective EEG).
- Tools/workflow: Domain-specific datasets; labeling strategies; personalization; feedback mechanisms in apps or VR.
- Assumptions/dependencies: Transferability beyond MI/seizure tasks; reliable ground truth; regulatory distinctions for wellness vs medical claims.
- Multi-class, fine-grained BCI control for assistive robotics
- Sector: robotics, rehabilitation
- What it could do: Scale HCFT to more MI classes (e.g., hand/arm gestures) for nuanced control of prosthetics/exoskeletons.
- Tools/workflow: Expanded datasets; higher-density EEG; real-time decoders; safety layers; user training curricula.
- Assumptions/dependencies: Sufficient SNR for fine-grained MI; user fatigue management; ergonomic electrode solutions.
In all cases, feasibility depends on data quality (montage consistency, artifact suppression), domain generalization across hardware and populations, careful choice of normalization strategy (DyT vs LayerNorm) per task, latency and power budgets for real-time use, and regulatory, privacy, and ethical constraints for clinical or safety-critical deployments.
Collections
Sign up for free to add this paper to one or more collections.