- The paper presents a hybrid EEG-Transformer model that integrates convolutional features with self-attention to decode imagined and overt speech EEG signals.
- It shows an average accuracy of 49.5% for overt speech and 35.07% for imagined speech, demonstrating significant improvements over traditional methods.
- The study highlights the potential for lightweight, portable BCI systems by efficiently processing limited-channel EEG signals using Transformer architecture.
The paper "EEG-Transformer: Self-attention from Transformer Architecture for Decoding EEG of Imagined Speech" (2112.09239) presents an innovative application of Transformer architectures in the context of EEG signal decoding for imagined and overt speech tasks. Leveraging the self-attention mechanism, the authors aim to enhance classification accuracy while reducing model complexity, showcasing the viability of attention-based models for brain-computer interface (BCI) applications.
The advent of deep learning has transformed traditional approaches to decoding electroencephalography (EEG) signals, particularly in brain-computer interfaces (BCIs) tasked with recognizing cognitive states or intentions. This paper explores the potential of Transformer architectures, specifically applying self-attention modules to the temporal-spectral-spatial data derived from EEG. Unlike recurrent neural networks (RNNs), Transformers facilitate parallel processing, addressing limitations in computation speed and enabling robust, interpretable models for EEG signal analysis.
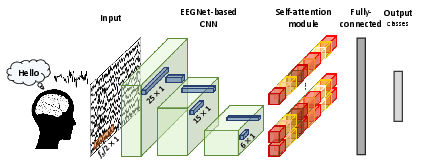
Figure 1: Total frameworks in this study. We split an image into fixed-size patches, linearly embed each of them, add position embeddings, and feed the resulting sequence of vectors to a standard Transformer encoder.
Data and Preprocessing
The research involved nine participants, with EEG data collected during tasks of imagined and overt speech involving 12 distinct words and a resting state. The preprocessing pipeline included down-sampling EEG signals, applying a high-gamma band Butterworth filter, and executing baseline correction. Channels around the Broca and Wernicke areas were specifically targeted, and independent component analysis mitigated artifacts from electromyography (EMG) and ocular signals.
Architecture Overview
The EEG-Transformer framework integrates convolutional layers for extracting features and incorporates self-attention mechanisms to exploit long-range dependencies within the EEG data. This hybrid model architecture not only compresses model size but also enhances classification accuracy through multi-head attention, which resolves EEG representations into distinct subspaces.
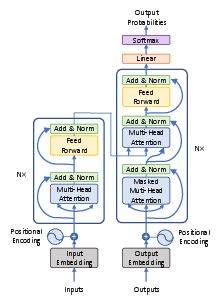
Figure 2: Transformer architecture. Self-attention and feed-forward networks with subsystem integrations, optimizing long-term dependency path lengths.
The Transformer-based model exhibited noteworthy performance, with overt speech reaching an average accuracy of 49.5% across 13 classes, while imagined speech scored 35.07%. Although overt speech naturally encompasses richer features due to associative EMG activities, the marginal performance gap indicates the potential of imagined speech decoding. Statistically significant improvement was noted with the self-attention module, highlighting its effectiveness in focusing computational resources on relevant EEG features.
Discussion on Practical Implications
This research underscores the feasibility of employing Transformers in EEG-based imagined speech decoding, with critical implications for real-world BCIs. Notably, the ability to achieve high performance with limited channels, such as ear-EEG configurations, proposes a robust, practical communication system applicable to portable BCI technologies. Future work may explore optimizing architectural parameters and expanding datasets to refine the accuracy and generalization capabilities of Transformer models in neural signal processing.
Conclusion
The study successfully applies self-attention from Transformer models to EEG decoding tasks, demonstrating significant advancements in classification performance for imagined speech. These findings provide a compelling case for integrating self-attention mechanisms into practical BCI frameworks, promoting the development of more responsive and accurate neuro-interfacing systems. Future research directions could involve investigating other Transformer-derived mechanisms, such as Vision Transformers, to further augment the efficiency and versatility of EEG decoding strategies in varied BCI applications.