AstroReason-Bench: Evaluating Unified Agentic Planning across Heterogeneous Space Planning Problems
Abstract: Recent advances in agentic LLMs have positioned them as generalist planners capable of reasoning and acting across diverse tasks. However, existing agent benchmarks largely focus on symbolic or weakly grounded environments, leaving their performance in physics-constrained real-world domains underexplored. We introduce AstroReason-Bench, a comprehensive benchmark for evaluating agentic planning in Space Planning Problems (SPP), a family of high-stakes problems with heterogeneous objectives, strict physical constraints, and long-horizon decision-making. AstroReason-Bench integrates multiple scheduling regimes, including ground station communication and agile Earth observation, and provides a unified agent-oriented interaction protocol. Evaluating on a range of state-of-the-art open- and closed-source agentic LLM systems, we find that current agents substantially underperform specialized solvers, highlighting key limitations of generalist planning under realistic constraints. AstroReason-Bench offers a challenging and diagnostic testbed for future agentic research.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces AstroReason-Bench, a new “test world” for smart AI assistants (called agents) that plan and make decisions for satellites. It checks how well these agents can handle real, physics-based space tasks—like when satellites should take pictures of Earth or talk to ground stations—without breaking rules about energy, timing, or movement. The big idea is to see if one general-purpose agent can plan well across many different space problems, instead of using a separate, specialized algorithm for each task.
What questions did the researchers ask?
The paper explores simple, big-picture questions like:
- Can one AI agent plan well across several different space missions with strict physical limits?
- How do these general AI agents compare to specialized, math-heavy tools that people already use for satellite scheduling?
- Which kinds of space tasks are easiest or hardest for agents?
- What does this tell us about how to build better agents for real-world planning?
How did they study it?
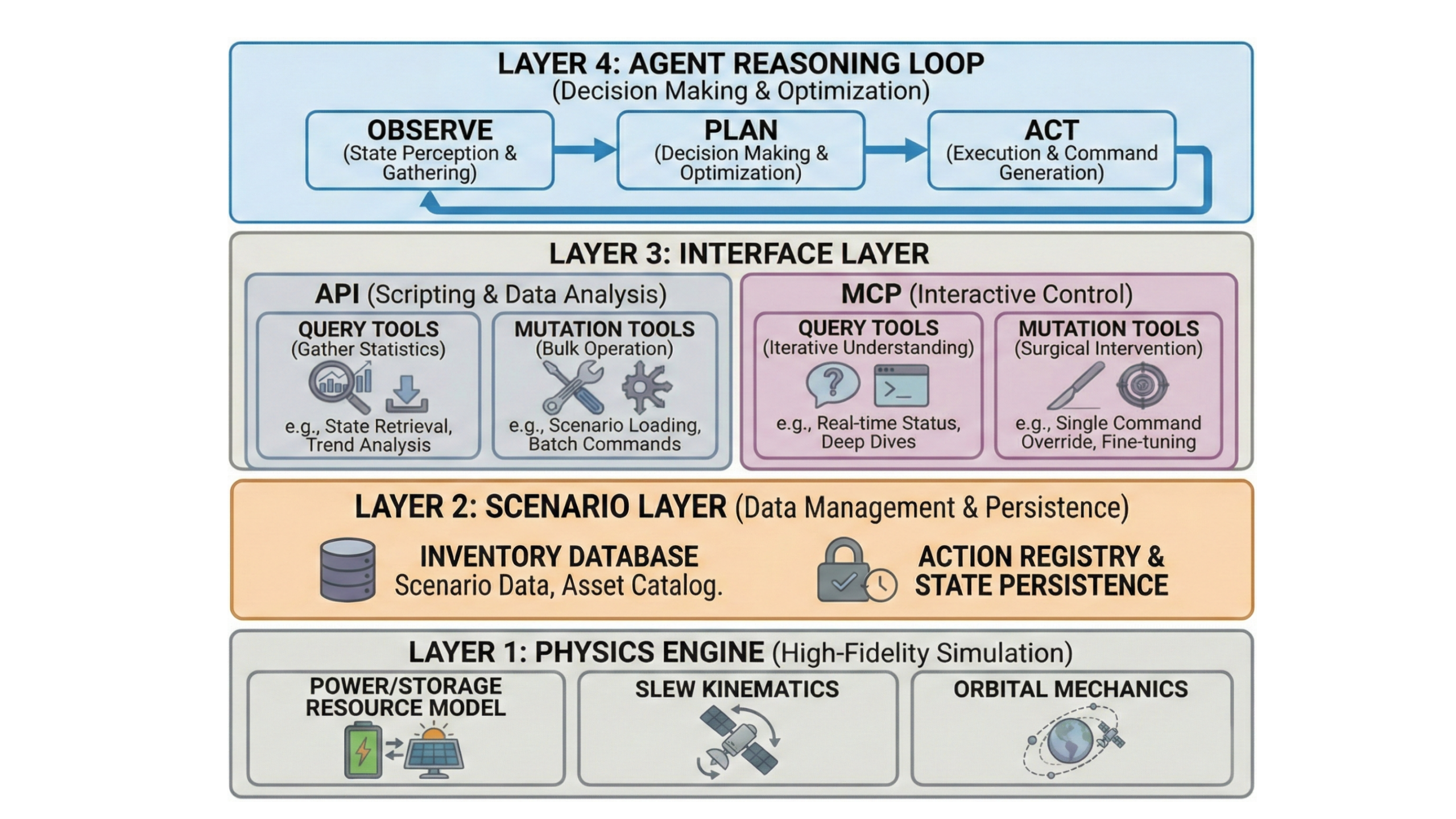
The team built a unified test system and five different challenge tasks that feel realistic and follow the laws of physics. Think of it like a video game:
- The “physics engine” keeps everything accurate (like how satellites move or how long it takes to point cameras).
- The “world manager” keeps track of satellites, ground stations, targets, energy, and storage.
- The “controls” let the agent look around, try actions, and get warnings if it breaks rules.
- The “player” is the AI agent that reads the task and tries to plan the mission.
A unified test world
- Physics rules: They use standard models to predict satellite paths (SGP4), like a rulebook for orbit motion. They also simulate how long it takes to turn a satellite to look at a target (slew time), and how energy and data storage fill up or empty over time (like a battery and a photo gallery).
- Interfaces: Agents can ask for summaries (via MCP tools) and run small Python scripts to do calculations they’re not good at mentally. This helps them explore, test, and adjust their plans.
Here are a few important rules explained in everyday terms:
- Energy limit: Satellites have batteries charged by the Sun. If they take too many actions (like taking lots of pictures) without sunlight, they can run out of power.
- Storage limit: Satellites can store only so much data. If they don’t “downlink” (send data to Earth), their memory fills up and new pictures can’t be saved—just like your phone running out of space.
- Movement limit: Turning to point at a new target takes time. You can’t instantly spin and take a perfect photo—like turning your head slowly to look at different things.
- Communication limit: Radio antennas can aim independently of cameras, so satellites can talk and take pictures at the same time—if they have the hardware for it.
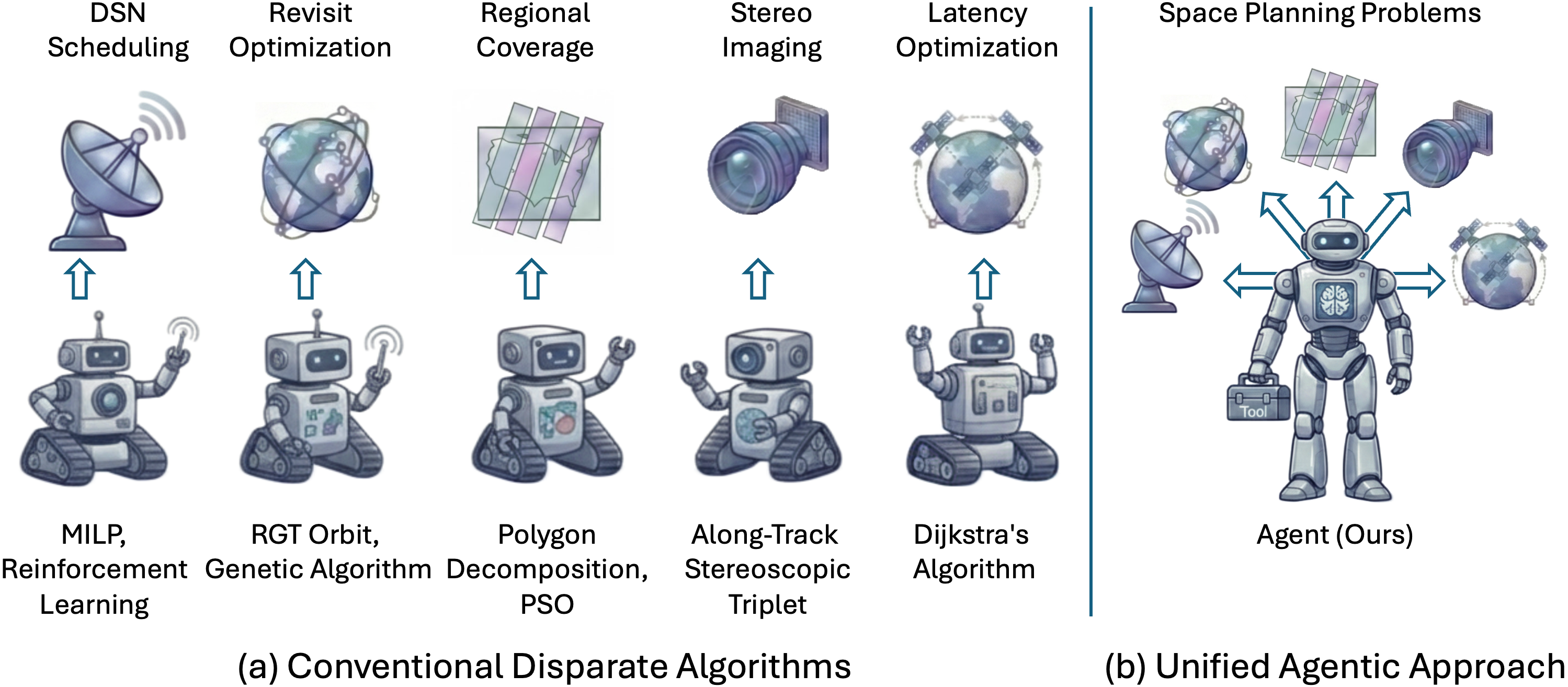
The five challenge tasks
The benchmark includes five realistic planning problems:
- Deep Space Network (DSN) Scheduling: Decide how to share limited antennas among many missions so everyone gets fair time.
- Revisit Optimization: Keep watching certain places often (small gaps between visits), while also meeting fixed photo quotas for other targets.
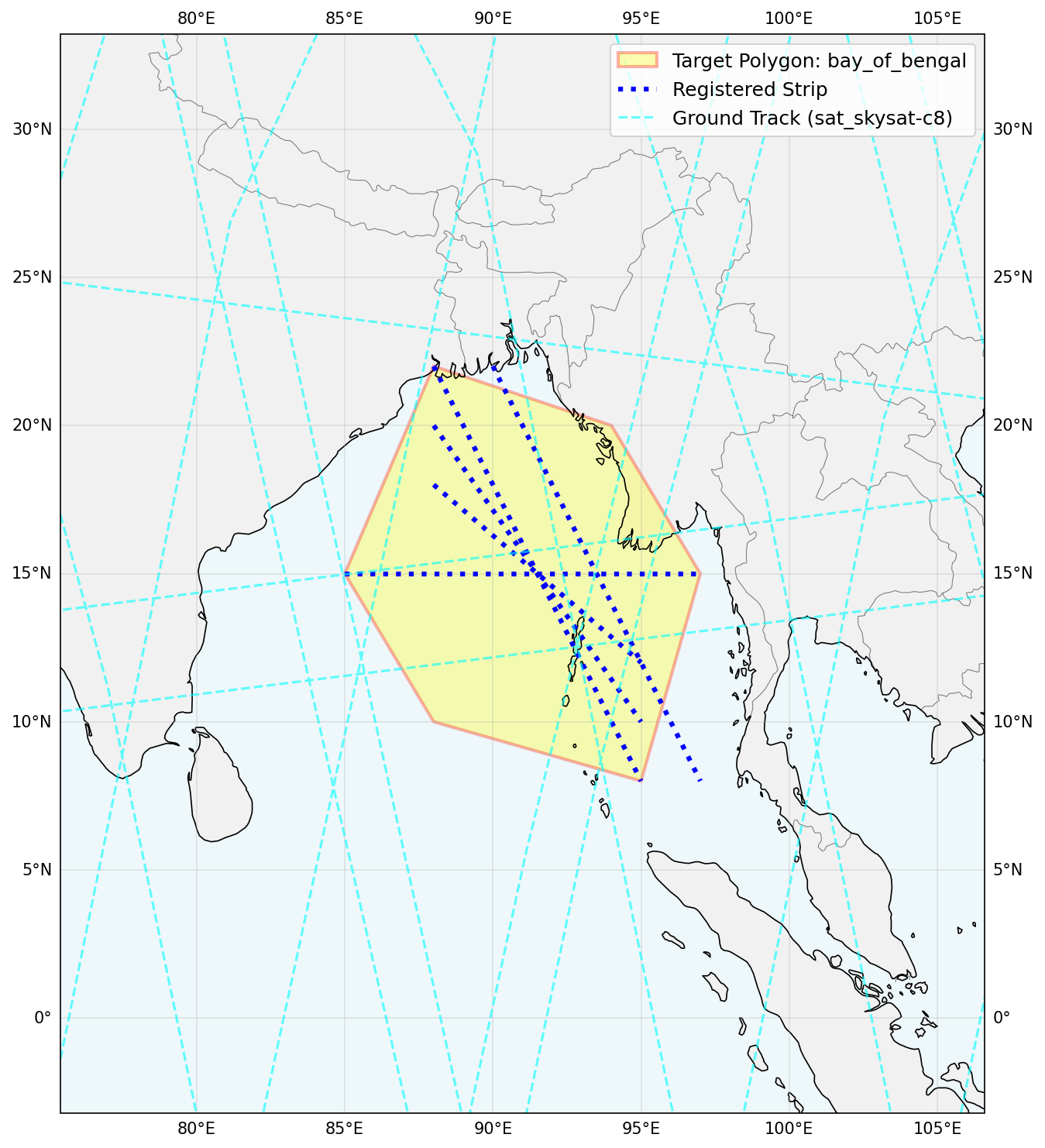
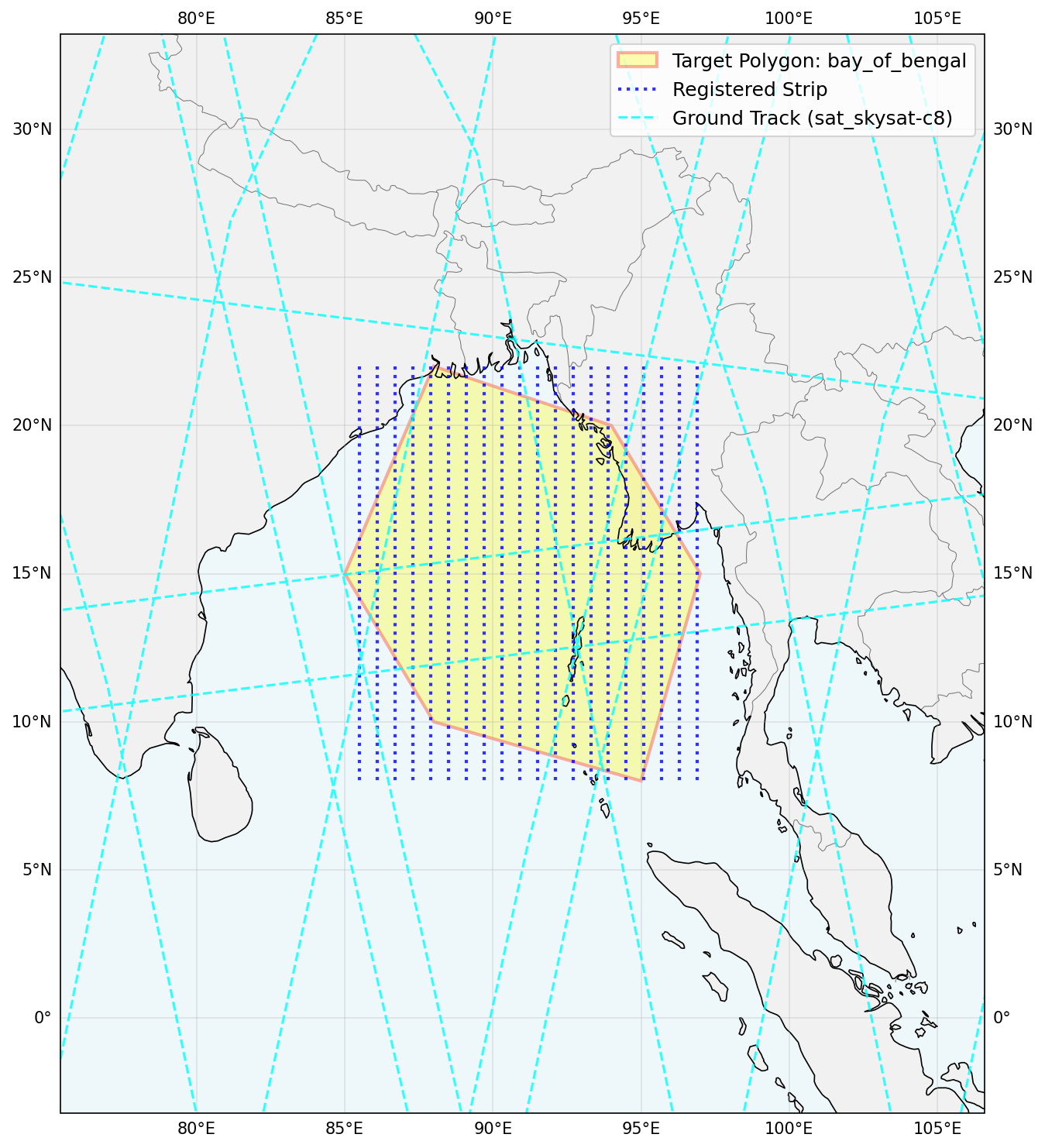
- Regional Coverage: Cover large areas (polygons) with long “strips” of images aligned with the satellite’s path.
- Stereo Imaging: Take two well-timed pictures of the same place with the right angles to build a 3D model—like taking two photos from different positions to see depth.
- Latency Optimization: Build live communication paths between two far-away ground stations using multiple satellites as relays (multi-hop), while also doing some Earth observation without breaking the network.
How agents and solvers were compared
They tested six modern AI agents (like Claude, Gemini, and DeepSeek) and compared them with classic methods:
- Greedy heuristic: A simple rule-of-thumb picker that chooses the best next step without looking far ahead.
- Simulated Annealing (SA): Tries changes randomly and keeps improvements, sometimes accepting worse steps to escape being stuck—like exploring different routes to find a better one.
- MILP (Mixed-Integer Linear Programming): A math-heavy solver that searches carefully through combinations to find near-optimal answers.
- RL (Reinforcement Learning): Learns by practicing many times and improving a policy over episodes.
What did they find, and why is it important?
Overall: Agents did okay, sometimes even better than simple heuristics, but they often lost to specialized solvers—especially when problems needed heavy computation or perfect resource tracking.
Here’s what happened in each task:
- DSN Scheduling: Agents were better than very simple baselines but worse than MILP or RL. They had decent scheduling intuition but didn’t explore many options systematically.
- Revisit Optimization: SA was best. The top agent kept visit gaps fairly small and hit quotas, but weaker agents forgot to schedule enough downlinks and ran out of storage—like taking too many photos without clearing space.
- Regional Coverage: Very hard. Most methods got low coverage because they didn’t align their image strips with the actual satellite ground tracks. It’s like drawing lines in random directions instead of following the road.
- Stereo Imaging: Classic baselines failed completely, but agents achieved modest success by thinking in pairs (“I need two photos that fit these rules”) and staging both together.
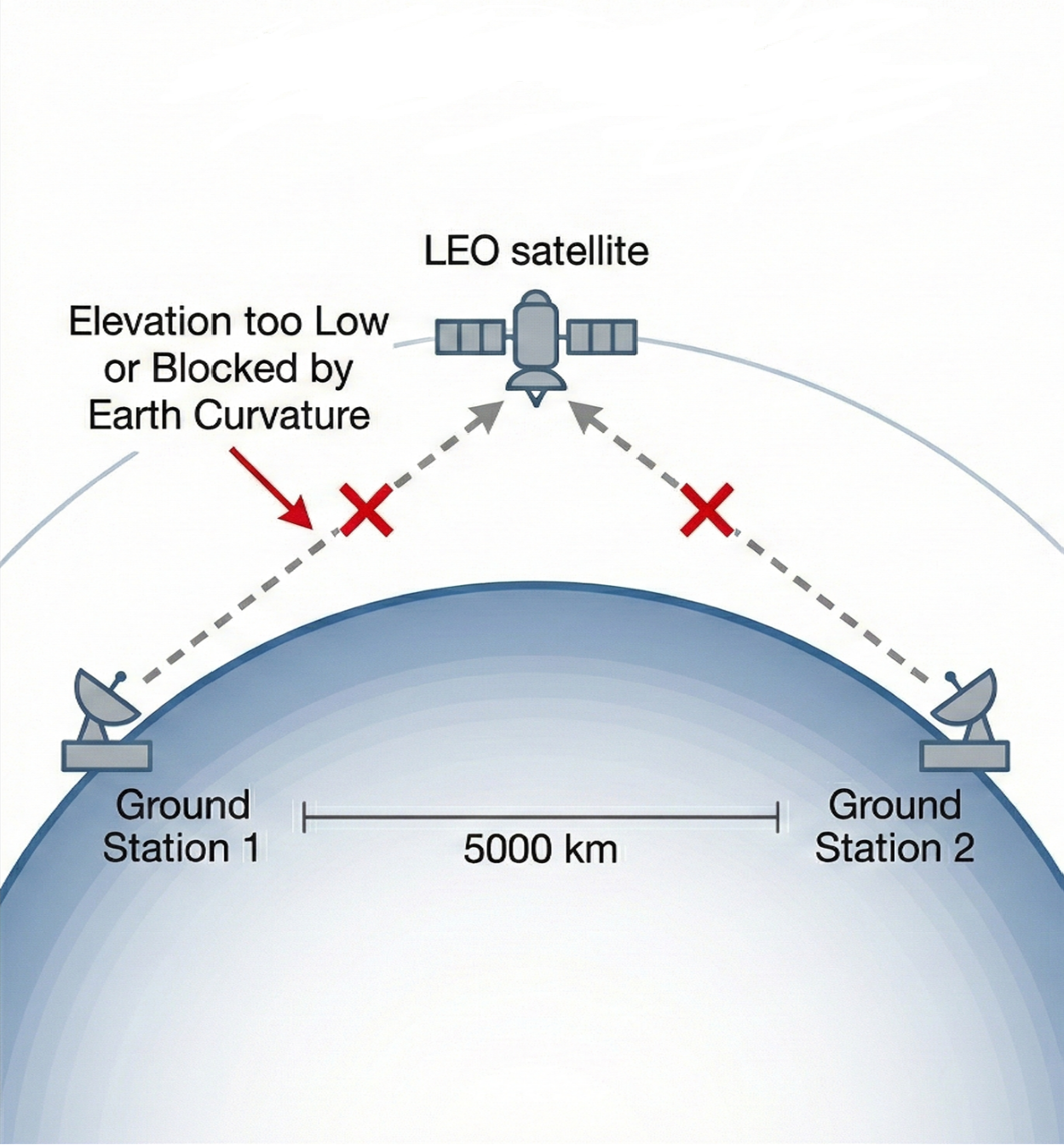
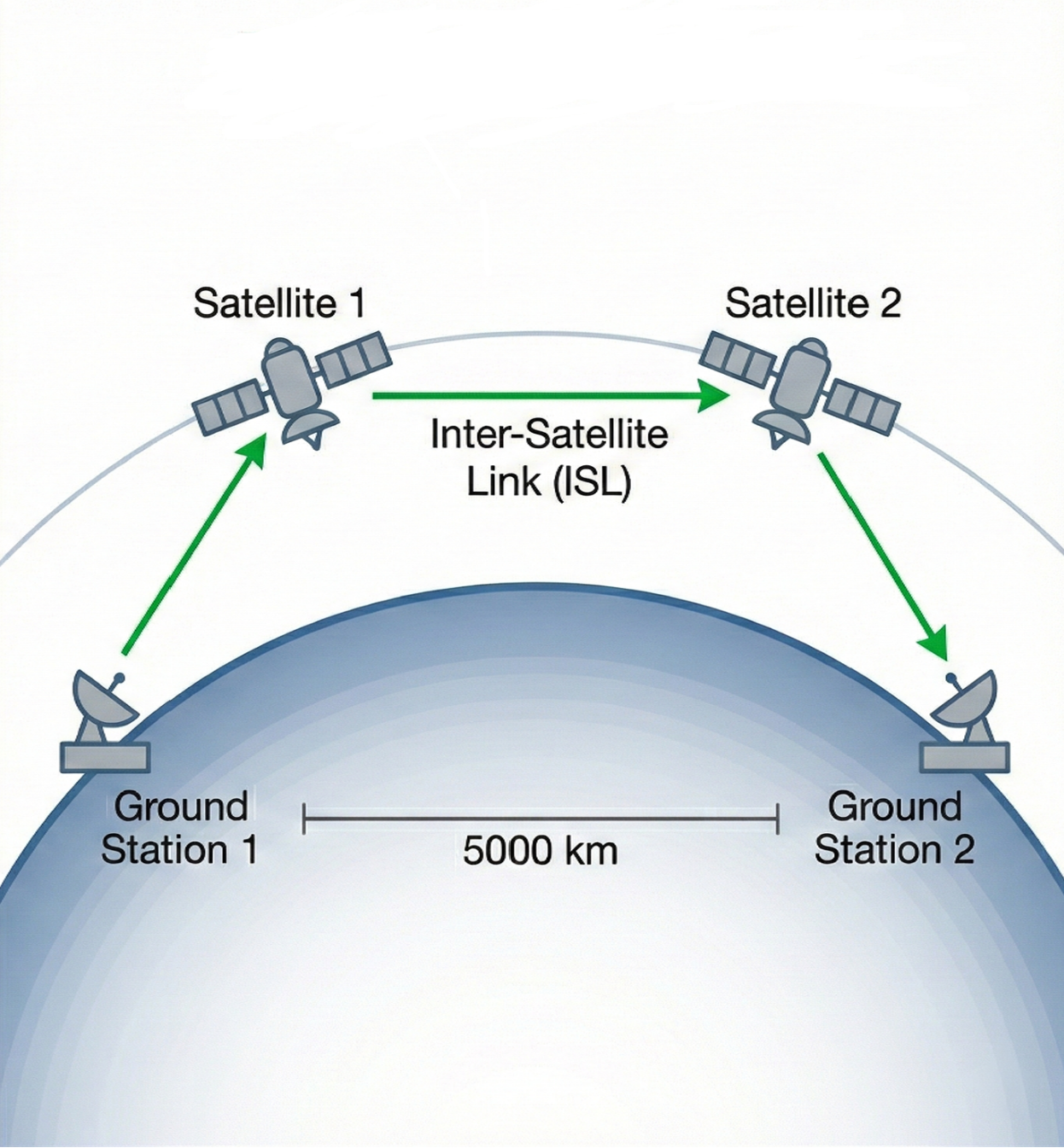
- Latency Optimization: Almost all agents failed by trying to find one satellite that could see both ground stations at the same time—which is usually impossible. Only one agent built a correct multi-hop path with several satellites acting like a relay team.
Why this matters:
- It shows that realistic physics and long-term planning make problems much tougher than text-only puzzles or simple games.
- Agents shine when they need flexible reasoning (like pairing photos or thinking about network paths), but struggle with resource management, geometry, and deep exploration.
- The benchmark exposes exactly where agents need to improve—storage planning, energy management, and spatial understanding.
What could this lead to?
AstroReason-Bench gives researchers a tough, realistic playground to build smarter agents. Potential impacts include:
- Better planning assistants for space missions that can safely balance energy, storage, timing, and movement.
- Unified tools that help one agent handle many types of tasks, instead of switching to a new solver for each problem.
- New training methods that strengthen agents in physics-grounded environments, encourage deeper exploration before acting, and use structured workflows (like “plan mode”) to read relevant research and tools more effectively.
In short, this benchmark helps move AI planning from toy problems to the real world of satellites—where the rules of physics are strict, mistakes are expensive, and smart scheduling can make missions more successful.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list enumerates concrete gaps and unresolved questions in AstroReason-Bench that future work could address to strengthen realism, comparability, and scientific insight:
- Compute-matched evaluation is absent: quantify agent performance when given equivalent computation to specialized solvers, and when agents orchestrate MILP/RL backends under identical budgets.
- Small episode counts and no confidence intervals: expand scenarios per benchmark, report variance/error bars, and perform statistical tests to ensure robust conclusions.
- Agent scaffolding is limited to a ReAct loop: systematically compare plan-then-act, self-correction, tree-of-thought, tool-use gating, and hierarchical controllers on the same tasks.
- No domain-adapted training/fine-tuning: test whether instruction-tuning, tool-use finetuning, or RL from environment feedback enables agents to approach optimizer-level performance.
- Orbit/physics simplifications: evaluate impact of using higher-fidelity propagators and environmental models (e.g., J2+ perturbations beyond SGP4 epoch alignment, atmospheric drag variability, Earth orientation parameters) on scheduling feasibility and agent decisions.
- Attitude-dependent power and thermal effects omitted: incorporate solar panel orientation, eclipse transients, thermal constraints, and battery degradation to test resource-aware planning under realistic spacecraft operations.
- Communication/link budgets and data rates simplified: model SNR/link budgets, rain fade, bandwidth allocation, variable downlink/uplink rates, and queuing to capture realistic contention and throughput constraints.
- Slew/attitude model oversimplified: include reaction wheel saturation, momentum management, star tracker constraints, slew planning across composite maneuvers, and non-constant settling times; quantify impact on feasible windows.
- Concurrency assumptions may be unrealistic: couple observation, ISL, and downlink activities via shared pointing, thermal, and power budgets to reflect platforms where payloads and terminals are not fully independent.
- No weather/illumination/cloud cover: integrate cloud forecasts, sun-angle/BRDF constraints, and scene quality models to stress robust EO planning under uncertainty.
- Stereo imaging assessed only by pair existence: add quality-of-result metrics (e.g., predicted DEM vertical accuracy vs. baseline geometry, incidence angles, metadata error correlation) to link plan quality to product quality.
- Regional coverage lacks canonical decomposition baselines: provide ground-track–aware strip generation methods, oracle/near-optimal references, and difficulty calibration to enable meaningful algorithmic comparisons.
- Missing strong baselines on novel tasks: implement state-of-the-art MILP/CP, heuristic search, and RL for Regional Coverage, Stereo, and Latency to contextualize agent results under compute-matched conditions.
- Latency metric excludes network stack effects: incorporate routing overhead, switching delays, MAC scheduling, congestion/queuing, and jitter; validate
M_latagainst a realistic network simulation. - ISL feasibility constraints under-modeled: enforce per-terminal pointing limits, slew/switching latencies, duty cycles, and bandwidth caps; study their effect on multi-hop route stability and availability.
- Fixed four-day horizon: analyze performance across longer horizons and different TLE epochs, including drift-induced geometry changes and growing propagation errors.
- Dataset sampling biases: quantify how filtering targets by mean constellation inclination affects representativeness and fairness; include polar/high-latitude and edge-of-access scenarios.
- Domain scope omissions: extend to maneuver planning (collision avoidance, station-keeping, fuel budgets), cross-mission trades, and deep-space trajectory design to broaden agentic coverage.
- No online replanning under disturbances: benchmark agents under dynamic events (new task insertions, station outages, weather changes, resource anomalies) to assess resilience and adaptability.
- Single-agent control only: compare centralized vs. multi-agent coordination, communication protocols, and decentralized planning for large constellations.
- Tool-use action bias: design and evaluate curricula, tool-use policies, and automatic “explore-before-commit” checks that drive agents to inspect ground tracks and constraints prior to staging actions.
- RAG effects anecdotal: rigorously study retrieval strategies (corpus curation, citation grounding, planning-phase alignment), measure when literature improves outcomes, and formalize RAG+planning workflows.
- Multi-objective evaluation absent: introduce Pareto analyses and normalized cross-task scoring to capture trade-offs (e.g., availability vs. mapping, gap vs. coverage) and enable aggregate benchmarking.
- Reproducibility and stochasticity: publish seeds, tool-call logs, and standardized evaluation protocols; report per-case distributions to mitigate LLM stochasticity concerns.
- Compute budget sensitivity unexplored: vary CPU/memory/time budgets to understand how resource limits shape agent strategies and success modes.
- Fidelity validation vs. industry tools missing: cross-validate environment outputs with STK/Basilisk and report discrepancies to establish trust in physics and visibility calculations.
- Constellation diversity limited: evaluate across GEO/MEO/HEO and additional real fleets (Starlink, OneWeb, ICEYE), measuring generalization across orbital regimes and architectures.
- Downlink/ground operations simplified: add maintenance windows, staffing/regulatory constraints, antenna handovers, and weather impacts on RF to test realistic ground network scheduling.
Practical Applications
Practical Applications of AstroReason-Bench
Below are real-world applications that flow from the paper’s benchmark, interfaces, findings, and engineering choices. They are grouped by deployment horizon and tagged with relevant sectors. Each item includes indicative tools/products/workflows and key assumptions or dependencies that affect feasibility.
Immediate Applications
- Hybrid schedule-repair copilots for space operations — sector: aerospace, software
- What: Deploy an LLM “repair” layer on top of existing MILP/RL/planner outputs to fix constraint violations, add stereo pairs, or coordinate multi-hop relays where constructive heuristics fail. Findings show agents are comparatively strong at compound-constraint reasoning (e.g., stereo doublets, ISL paths) and weak at exhaustive search—perfect for post-optimization repair.
- Tools/products/workflows: MCP tools + Python API; plug-ins that read/write YAML/JSON scenarios; “repair-and-validate” loops with physics checks; optional RAG+Plan mode for higher-stakes edits.
- Assumptions/dependencies: Existing baseline optimizer in place; reliable constraint validators; human-in-the-loop approval (HIL) for safety; scenario schemas aligned with ops systems.
- Procurement and capability evaluation for agentic planning — sector: government, defense/civil space agencies, integrators
- What: Use AstroReason-Bench as a standardized acceptance test for vendors’ agentic planners (compare U_rms, M_gap, stereo coverage, availability, latency). Supports evidence-driven procurement and risk assessment for autonomy claims.
- Tools/products/workflows: “Benchmark-as-a-Service” harness; reproducible suites with seed locking; leaderboard dashboards for model/agent variants.
- Assumptions/dependencies: Agreement on metrics; compute/time caps for fairness; scenario difficulty tiers reflecting mission realities.
- Operator training simulators for SatOps — sector: aerospace, education
- What: Trainees practice solving DSN, revisit, regional coverage, stereo, and ISAC routing tasks under realistic physics/resource constraints. Instructors can toggle agent aides to demonstrate failure modes and best practices (e.g., downlink budgeting, strip alignment).
- Tools/products/workflows: Classroom-ready Docker images; scripted “Plan Mode” curricula; annotated mission briefs; post-hoc trace visualizations of agent decisions and constraint violations.
- Assumptions/dependencies: Basic orbital mechanics background; visualization layer for ground tracks and swaths; TLE refresh policy for teaching cycles.
- Red-team/blue-team safety testing of autonomous agents — sector: safety, compliance, policy
- What: Stress-test agent behaviors under hard constraints to surface unsafe policies (e.g., energy depletion, storage overflow, infeasible single-hop assumptions). Codify “do-no-harm” constraints and audit logs.
- Tools/products/workflows: Scenario perturbation packs (eclipse-heavy, oversubscription, limited storage); automated violation reporters; policy checkers that block commits if resource invariants are breached.
- Assumptions/dependencies: Formalized constraint policies; governance workflow for waivers; auditability of agent tool calls.
- Research testbed for tool-use, planning, and RAG workflows — sector: academia, AI research
- What: Standard platform to study ReAct vs. Plan-mode vs. self-correction vs. RAG-enhanced planning; measure how tool prompting affects exploration (e.g., forcing ground-track queries before strip placement).
- Tools/products/workflows: MCP tool adapters; ablation scripts; logging of thought/tool traces; RAG “knowledge packs” (DSN literature, stereo geometry primers).
- Assumptions/dependencies: IRB not needed (no human subjects); reproducible seeds; open licensing for benchmark assets.
- Curriculum modules for physics-grounded AI planning — sector: higher education, STEM outreach
- What: Courses/labs on agentic planning with real orbital constraints (SGP4, slew kinematics, resource buffers). Students build heuristics and compare against LLM agents and SA/MILP baselines.
- Tools/products/workflows: Jupyter notebooks; graded assignments; reference solutions; visualization widgets for strip orientation and ISL paths.
- Assumptions/dependencies: Access to basic compute (8 cores, 16 GB OK); didactic datasets; instructor guides on known failure modes.
- Rapid A/B testing of scheduling heuristics and solver hyperparameters — sector: aerospace software, optimization
- What: Use the procedural dataset generator and uniform metrics to evaluate heuristic variants (e.g., downlink prioritization, fairness penalties, azimuth separation scoring) under a common harness.
- Tools/products/workflows: Batch experiment CLI; metric dashboards; seed-controlled scenario sweeps; time/compute-budgeted runs.
- Assumptions/dependencies: Comparable compute budgets; controlled scenario scaling; versioned configs for reproducibility.
- API adapters to legacy mission tools via MCP — sector: software, aerospace
- What: Wrap STK/Basilisk/mission planners behind the MCP/Python interface to enable agent-accessible physics and schedule commit/validate operations—with semantic feedback on violations.
- Tools/products/workflows: Adapter SDK; schema mappers between ops databases and benchmark schema; side-by-side “shadow run” mode in non-production environments.
- Assumptions/dependencies: Vendor licenses; API access; IT/security approvals for sandboxing.
- Educational/enthusiast apps for satellite pass planning and imaging geometry — sector: consumer education, citizen science
- What: Simplified web apps that teach why single-hop links fail across continents, how swath orientation impacts coverage, or how stereo baselines work.
- Tools/products/workflows: Thin UI over the physics engine; pre-baked scenarios; interactive ground-track overlays.
- Assumptions/dependencies: Rate-limited compute; simplified constraints for clarity; public TLE data.
Long-Term Applications
- Mission scheduling copilots with production-grade autonomy — sector: aerospace (EO, DSN, ISAC)
- What: End-to-end agent copilots that co-plan observations, downlinks, ISL routing, and maintenance windows in live ops. Hybridized with MILP/RL backends for global optimization, agents handle constraint negotiation, schedule repair, and dynamic re-planning.
- Tools/products/workflows: Human-on-the-loop approval gates; safety envelopes; real-time telemetry ingestion; continuous validation against physics kernels; offline “what-if” sandboxes.
- Assumptions/dependencies: Certification for safety; robust guardrails; high-fidelity state estimation; organizational change management.
- Onboard/edge planning under tight compute and latency — sector: space systems, embedded AI
- What: Trimmed agentic planners running on satellites for responsive retasking (e.g., disaster imaging, time-critical downlinks), with verified constraint models and limited tool-chains.
- Tools/products/workflows: Model compression; rule-based fallbacks; pre-verified action libraries; on-device constraint checkers.
- Assumptions/dependencies: Flight hardware limits; rad-hard compute; offline verification/validation; uplink constraints for updates.
- Cross-agency/shared-asset scheduling and fairness arbitration — sector: multi-stakeholder governance, policy
- What: Broker agents negotiating DSN use, cross-constellation tasking, and spectrum/time-slot allocations with fairness and SLAs, using standardized metrics (U_rms, availability, latency).
- Tools/products/workflows: Policy-encoded objective weights; cryptographic audit trails; scenario negotiation simulators; compliance dashboards.
- Assumptions/dependencies: Interoperable APIs and data schemas; legal/contractual frameworks; dispute resolution processes.
- Dynamic ISAC network orchestration (multi-hop routing co-optimized with sensing) — sector: telecommunications, Earth observation
- What: Agents that maintain connectivity SLAs while opportunistically fulfilling mapping quotas by exploiting idle time-frequency resources—extending the paper’s Latency-Optimization benchmark into live networks.
- Tools/products/workflows: Real-time link-state monitoring; predictive access windows; multi-objective controllers for availability/latency/coverage; handoff choreography.
- Assumptions/dependencies: Accurate link budgets; crosslink hardware; interference management; resilient autonomy strategies.
- Automated stereo and tri-stereo product pipelines — sector: geospatial intelligence, mapping, climate/disaster response
- What: Agents that plan and validate stereo/tri-stereo acquisitions end-to-end (geometric constraints, timing, radiometry), then trigger downstream 3D reconstruction workflows with quality gates.
- Tools/products/workflows: Stereo window search utilities; parallax/geometry validators; pipeline orchestration to DEM generation and QA.
- Assumptions/dependencies: Reliable weather/cloud forecasts; radiometric consistency models; downstream processing SLAs.
- Digital-twin-based certification of autonomous planners — sector: safety engineering, standards
- What: Formal certification processes that require agent submissions to pass a battery of physics-grounded benchmark scenarios (stress, edge cases, degraded sensors) before exposure to operations.
- Tools/products/workflows: Scenario fuzzing; adversarial case generation; traceability matrices from requirement to metric; continuous compliance testing.
- Assumptions/dependencies: Consensus on standards; independent test authorities; long-run performance stability data.
- Meta-learning and transfer for heterogeneous planning — sector: AI research, aerospace
- What: Train agents that transfer strategies across DSN scheduling, coverage, stereo, and ISAC routing via shared interfaces—closing the “generalist planner” gap shown in the results.
- Tools/products/workflows: Multi-task curricula; tool-use skill libraries; hierarchical policy distillation; simulation-to-ops transfer studies.
- Assumptions/dependencies: Sufficient scenario diversity; stable tool semantics; evaluation at increasing horizon/difficulty.
- Multi-objective business planning and portfolio optimization — sector: EO/telecom operators, finance/strategy
- What: Strategic simulators that quantify revenue/risk trade-offs between revisit frequency, coverage, stereo product mix, and network SLAs—informing constellation design and capacity planning.
- Tools/products/workflows: Scenario samplers linked to demand models; revenue/cost objective functions; sensitivity analyses; “what-if” dashboards for execs.
- Assumptions/dependencies: Validated demand and price curves; integration of weather/market signals; model risk management.
- Emergency response tasking at global scale — sector: public safety, NGOs, government
- What: Rapid re-planning for wildfires, floods, and earthquakes that balances energy/storage, downlink bottlenecks, and stereo needs for damage assessment; ties into multi-agency DSN/ground-station availability.
- Tools/products/workflows: Event-driven triggers; priority queues; dynamic reprioritization policies; CAT (catastrophe) playbooks encoded for agents.
- Assumptions/dependencies: Near-real-time data feeds; inter-agency interoperability; robust override controls and human authority.
- Standardization of agent-oriented interfaces for physics-grounded systems — sector: standards bodies, software ecosystem
- What: MCP-like schemas for “laws-of-physics” layers beyond space (power grids, aviation, maritime), enabling cross-domain agent evaluation and safer deployment.
- Tools/products/workflows: Open schemas; conformance tests; reference adapters; governance forums.
- Assumptions/dependencies: Community adoption; alignment with incumbent tool vendors; security and audit requirements.
Notes on Feasibility and Dependencies (cross-cutting)
- Fidelity: SGP4 + TLE are operationally useful but have limits; high-precision tasks may require higher-fidelity propagators and atmosphere/attitude models.
- Safety: HIL and guardrails are essential; autonomous commit privileges require certification and formal verification of constraint checkers.
- Compute and costs: Real-time and onboard deployments need model compression and deterministic runtimes; benchmark results established on modest compute should be re-baselined for production.
- Data access: Live ephemerides, station availability, and link budgets must be integrated securely; licensing for STK/Basilisk or equivalent tools may constrain adapters.
- Organizational readiness: Integrating agentic planners into mission ops demands change management, operator trust-building, and clear escalation protocols.
Glossary
- Advisory locks: File-system locks that rely on cooperating processes to honor them, used to guard shared state. "State Persistence: a file-backed mechanism guarded by advisory locks."
- Agentic: Describing LLM systems that can plan, use tools, and take actions autonomously. "Recent advances in agentic LLMs have positioned them as generalist planners..."
- ALNS: Adaptive Large Neighborhood Search, a metaheuristic that iteratively destroys and repairs parts of a solution to escape local optima. "Agile satellites require specialized heuristics (e.g., ALNS, PSO) for stereoscopic imaging..."
- Area-based Recall (AR): A coverage metric defined as captured target area divided by total required area. "The coverage performance is evaluated using Area-based Recall (AR), defined as the ratio of the captured target area to the total required area:"
- Attitude maneuvers: Spacecraft rotations to point sensors or antennas at new targets or directions. "For Earth observation tasks, satellites are modeled as agile bodies requiring attitude maneuvers."
- Azimuth: The horizontal angle of a target relative to a reference direction, often measured from north. "where and represent the azimuth and elevation angles, respectively."
- Conical shadow projection: A geometric model to determine eclipse (shadow) periods by projecting Earth’s shadow cone onto satellite trajectories. "P_{gen} is conditional on the satellite's eclipse status (computed via conical shadow projection)."
- Deep Space Network (DSN): NASA’s global network of antennas for communicating with deep-space missions; also a scheduling domain. "We incorporate the SatNet environment \cite{goh2021satnet}, a standard benchmark for Deep Space Network (DSN) scheduling."
- Eclipse status: Whether a satellite is in Earth’s shadow (no direct sunlight), affecting power generation. "P_{gen} is conditional on the satellite's eclipse status (computed via conical shadow projection)."
- Gimbaled: Mounted on a gimbal, allowing independent rotation and pointing without reorienting the spacecraft. "In contrast, link terminals (Downlink/Inter-Satellite Link) are gimbaled and rotationally independent."
- Ground track: The path a satellite traces over the Earth’s surface as it orbits. "without first querying satellite ground tracks to understand orbital geometry."
- Integrated Sensing and Communications (ISAC): A paradigm where communication and sensing (e.g., Earth observation) share spectrum and hardware resources. "This task models a Low Earth Orbit (LEO) mega-constellation providing Integrated Sensing and Communications (ISAC) services..."
- Inter-Satellite Link (ISL): A communication link established directly between satellites for relaying data. "explicitly computed inter-satellite link (ISL) windows"
- Metropolis criterion: The acceptance rule in simulated annealing that probabilistically accepts worse solutions to escape local minima. "accepts worse solutions probabilistically via the Metropolis criterion to escape local minima."
- Mixed-Integer Linear Programming (MILP): An optimization framework with linear objectives/constraints and both integer and continuous variables. "Δ-MILP, a Mixed-Integer Linear Programming solver"
- Model Context Protocol (MCP): A tool-use protocol that exposes environment state and actions to LLM agents via semantic interfaces. "we provide a minimal set of task-relevant tools via the Model Context Protocol (MCP)"
- Oversubscription: Demand for a resource exceeds its available capacity, requiring prioritization or scheduling. "DSN Scheduling, dealing with antenna oversubscription, has progressed from heuristic repair..."
- Parallax: Apparent displacement of a target between two viewpoints, used to infer depth in stereo imaging. "These constraints ensure sufficient parallax for depth estimation while minimizing radiometric changes between images."
- Proximal Policy Optimization (PPO): A reinforcement learning algorithm that updates policies with clipped objectives for stability. "RL (PPO), a reinforcement learning approach trained via Proximal Policy Optimization"
- Quaternion: A four-parameter representation of 3D rotation used for spacecraft attitude. "where denotes the unit quaternion."
- ReAct: An agent pattern where the model iteratively reasons (think) and acts (use tools) to solve tasks. "We employ a standard ReAct \cite{yao2022react} loop via Claude Code"
- Revisit Gap: The time interval between consecutive observations of the same target. "We minimize the Revisit Gap, defined as the time interval between consecutive observations."
- SGP4 (Simplified General Perturbations 4): A standard analytical orbit propagator used with TLEs to compute satellite positions. "The engine uses the Simplified General Perturbations 4 (SGP4) model"
- Simulated Annealing (SA): A stochastic optimization technique that explores the solution space by probabilistically accepting uphill moves. "Simulated Annealing (SA): a metaheuristic that represents solutions as binary masks over candidate windows..."
- Slew kinematics: The dynamics of spacecraft pointing maneuvers, including velocity and acceleration limits and settling time. "Slew Kinematics: a trapezoidal velocity model simulates slew maneuvers for agile satellites, enforcing settling time constraints"
- Stereo reconstruction: 3D reconstruction from two images taken at different viewpoints, requiring proper geometry and timing. "The constraint on and ensure an appropriate geometric baseline for stereo reconstruction."
- Store-and-forward: A communication mode where data is stored temporarily on nodes before being forwarded later; contrasted with real-time relays. "This is not store-and-forward; the entire chain"
- Trapezoidal velocity profile: A motion profile with constant acceleration, constant velocity, then constant deceleration phases. "the slew time is derived from a trapezoidal velocity profile based on the angular displacement"
- Two-Line Element (TLE): A standardized text format encoding orbital elements of Earth-orbiting objects. "Two-Line Element (TLE) data, a standardized format for encoding the orbital elements of Earth-orbiting objects"
- Unsatisfied ratio: In DSN scheduling, the fraction of requested time not allocated to a mission. "we define the unsatisfied ratio for mission as "
Collections
Sign up for free to add this paper to one or more collections.

