Robust Persona-Aware Toxicity Detection with Prompt Optimization and Learned Ensembling
Abstract: Toxicity detection is inherently subjective, shaped by the diverse perspectives and social priors of different demographic groups. While ``pluralistic'' modeling as used in economics and the social sciences aims to capture perspective differences across contexts, current LLM prompting techniques have different results across different personas and base models. In this work, we conduct a systematic evaluation of persona-aware toxicity detection, showing that no single prompting method, including our proposed automated prompt optimization strategy, uniformly dominates across all model-persona pairs. To exploit complementary errors, we explore ensembling four prompting variants and propose a lightweight meta-ensemble: an SVM over the 4-bit vector of prompt predictions. Our results demonstrate that the proposed SVM ensemble consistently outperforms individual prompting methods and traditional majority-voting techniques, achieving the strongest overall performance across diverse personas. This work provides one of the first systematic comparisons of persona-conditioned prompting for toxicity detection and offers a robust method for pluralistic evaluation in subjective NLP tasks.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper looks at how AI can tell whether a piece of text is “toxic” or offensive, but with a twist: different kinds of people (different ages, genders, and races) can disagree about what’s offensive. The authors show how to make AI consider these different perspectives (called personas), and how to combine several AI “opinions” to get a more reliable answer.
What questions did the researchers ask?
They wanted to know:
- Can we prompt (instruct) AI to judge toxicity from the point of view of different groups of people?
- Which prompting style works best across different AI models and different personas?
- If no single prompt works best everywhere, can we combine multiple prompt-based answers to do better?
- Can we automatically improve the prompts themselves?
- What’s the most reliable way to combine these different answers?
How did they study it?
They tested several ways of asking LLMs to decide if a social media post is offensive, especially from the perspective of specific groups. Then they tried different ways of combining those answers.
The four ways they asked the AI (prompting methods)
Think of prompting like giving an AI a set of instructions before it answers. They tried:
- Default prompt: Plain instructions to judge if a post is offensive (no persona).
- Persona prompt: “Imagine you are a [persona]” (for example, “Asian woman” or “White man”) and judge from that viewpoint.
- Value profile prompt: A short description of values and concerns important to a persona, learned from examples, then used to guide the AI’s judgment (like a mini “profile” of what that group tends to consider offensive).
- Optimized persona prompt: An automatically improved version of the persona prompt. Another AI (an “optimizer”) critiques the prompt and suggests better wording using a method called TextGrad, trying to raise accuracy step by step—like a coach giving feedback to refine instructions.
Combining answers (ensembling)
If you ask the same model in four different ways, you get four “votes” (offensive or not). They tried combining these votes:
- Majority voting: Pick the label most prompts agree on (unweighted or weighted by how accurate each method was on training data).
- SVM meta-ensemble: Feed the four yes/no votes into a simple machine learning combiner (an SVM). You can think of the SVM as a smart referee that learns patterns like “if these two prompts say yes and the others say no, the final answer should be yes.” It can learn non-obvious combinations, not just simple counting.
Data and models
- Dataset: Social Bias Frames, a large set of social media posts with multiple human labels, including who the target is and whether it’s offensive. They focused on “personas” formed by combining gender and race (e.g., Asian woman, Black woman, White man, Hispanic man, Native man, etc.).
- Models: Several open-source LLMs (Llama 3.1 and Qwen 2.5 in different sizes), plus “reasoning-enhanced” versions (R1-distilled) that are supposed to think more step-by-step.
- Evaluation: They split the data into training, validation, and testing, and used statistical checks to be sure differences weren’t just luck.
What did they find?
Here are the main results in simple terms:
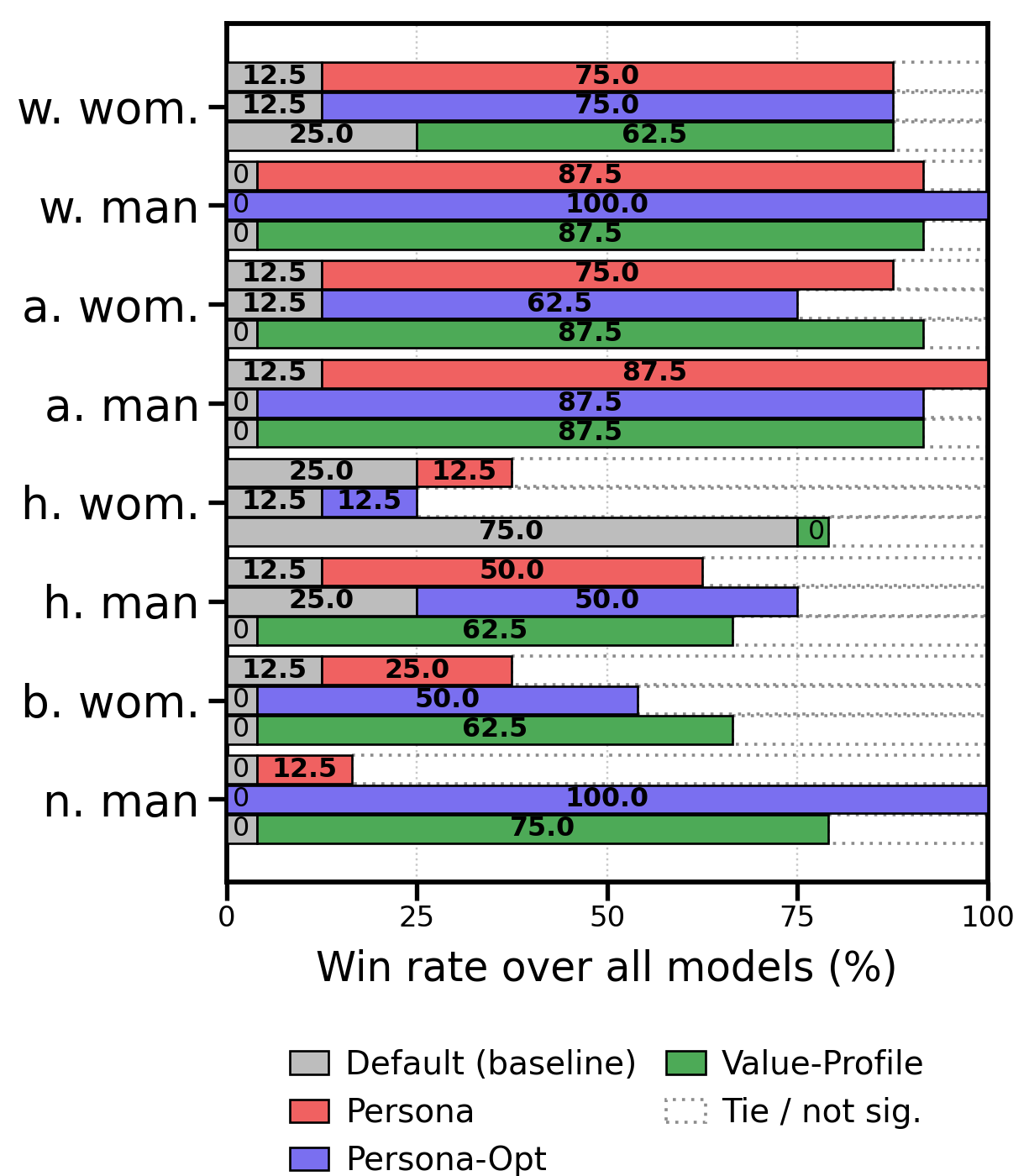
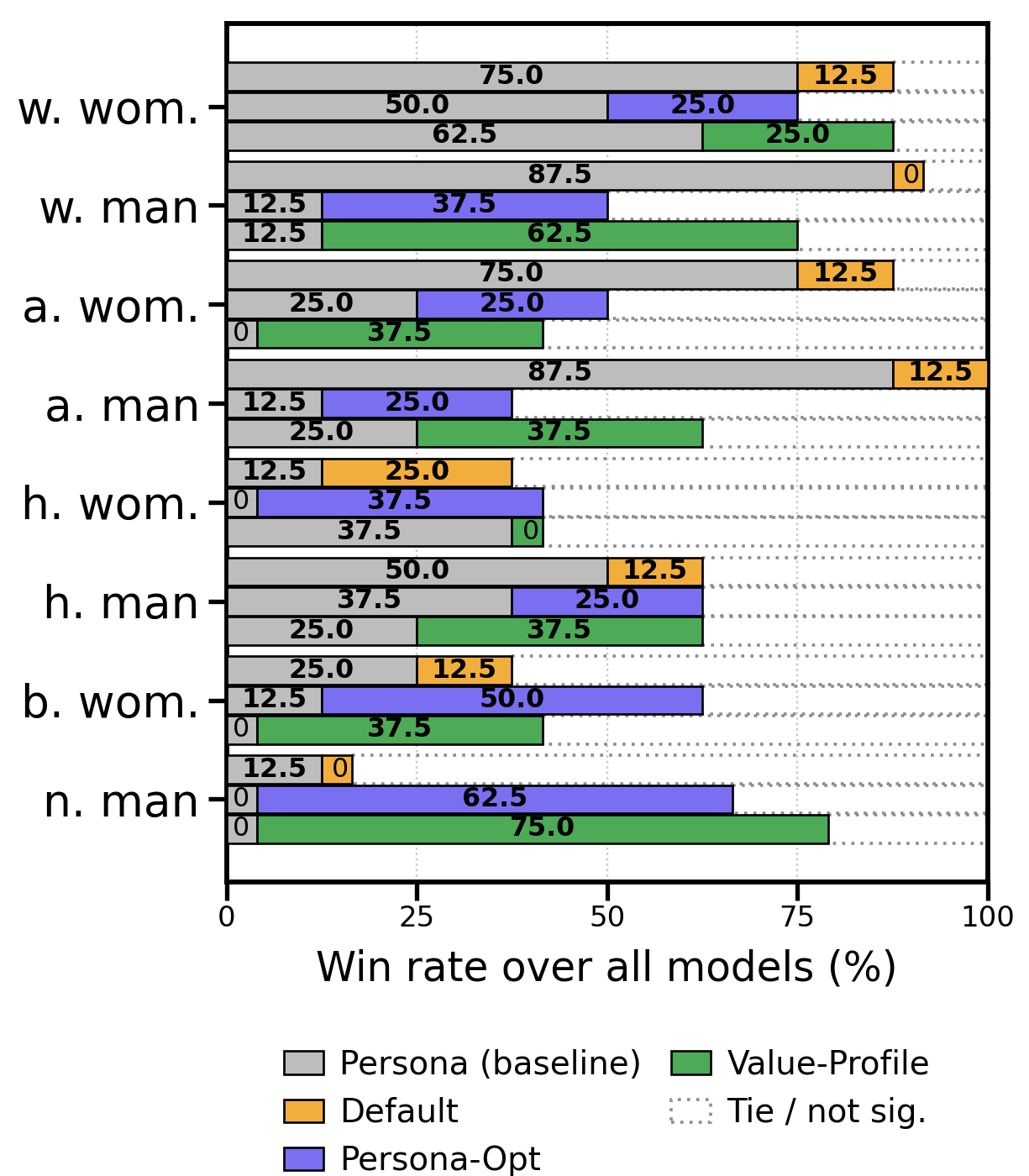
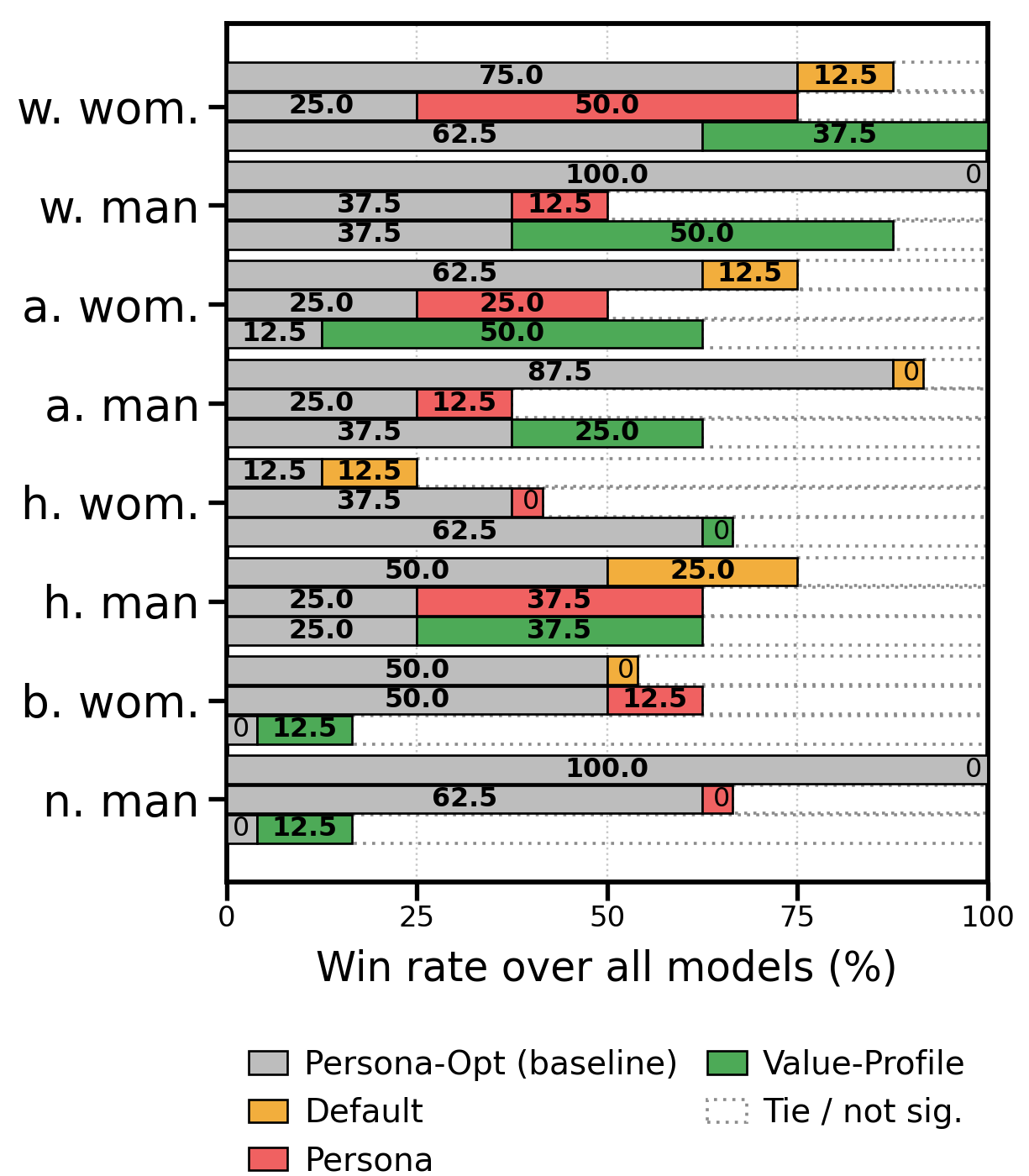
- No one-size-fits-all prompt: Across different AI models and personas, no single prompt type was always best. Sometimes a regular persona prompt won; other times the value profile or the optimized prompt did better.
- Persona-aware prompts help (usually): Asking the model to “imagine you are [persona]” improves accuracy over the default in most cases. But for some groups (like “Hispanic woman” in this dataset), persona prompts didn’t help and sometimes hurt—likely because this group’s data had a higher rate of offensive labels, and the prompts nudged models to be too lenient.
- Value profiles ≈ optimized prompts: Writing a value profile and automatically optimizing a persona prompt performed similarly overall. They often disagreed on specific examples, which means they catch different types of errors.
- Reasoning models aren’t a free win: Adding “reasoning” helped smaller models but sometimes hurt larger ones for this social task. Bigger models may already “reason” internally, and extra reasoning training tuned for math/logic might not transfer well to social judgments.
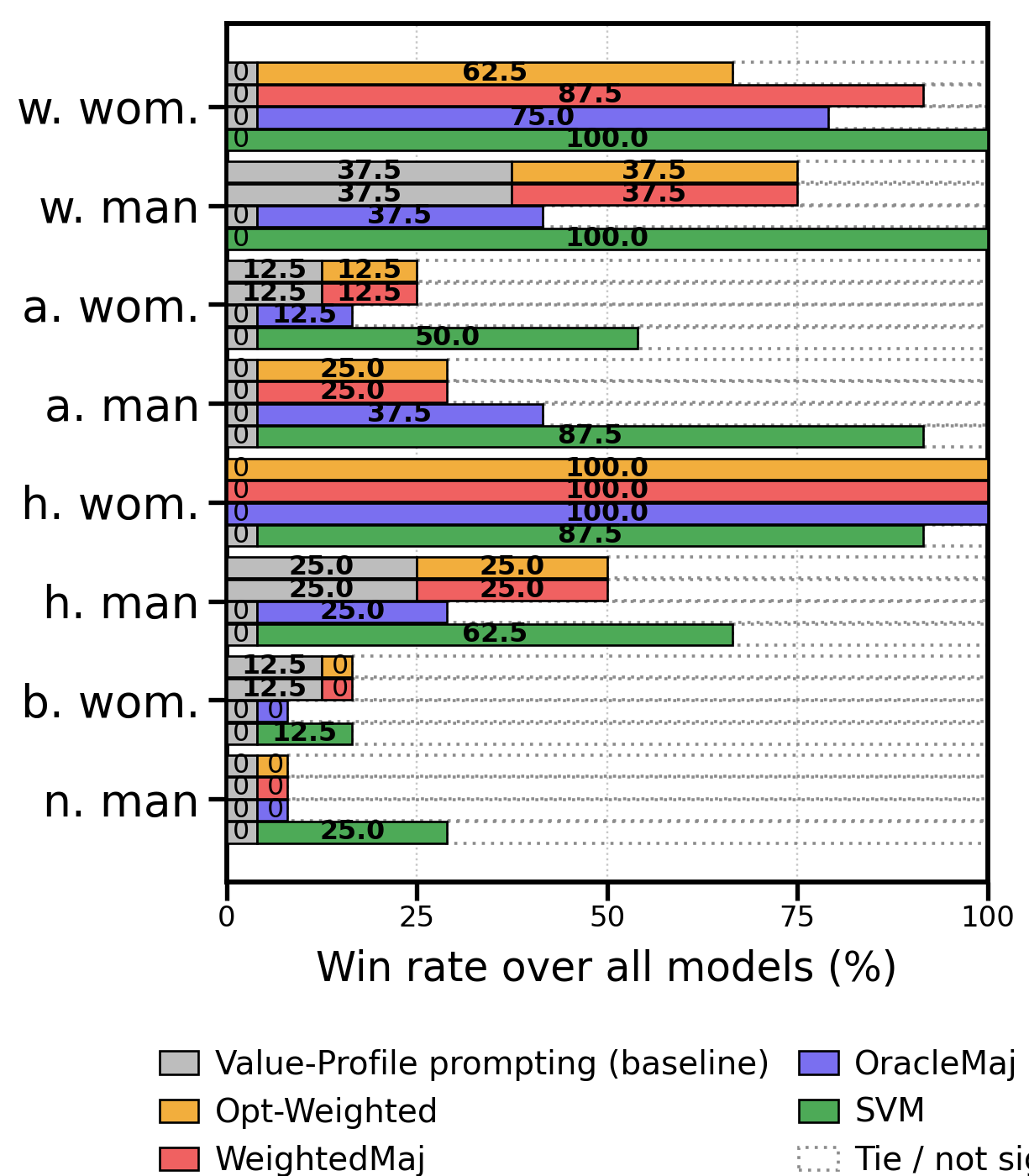
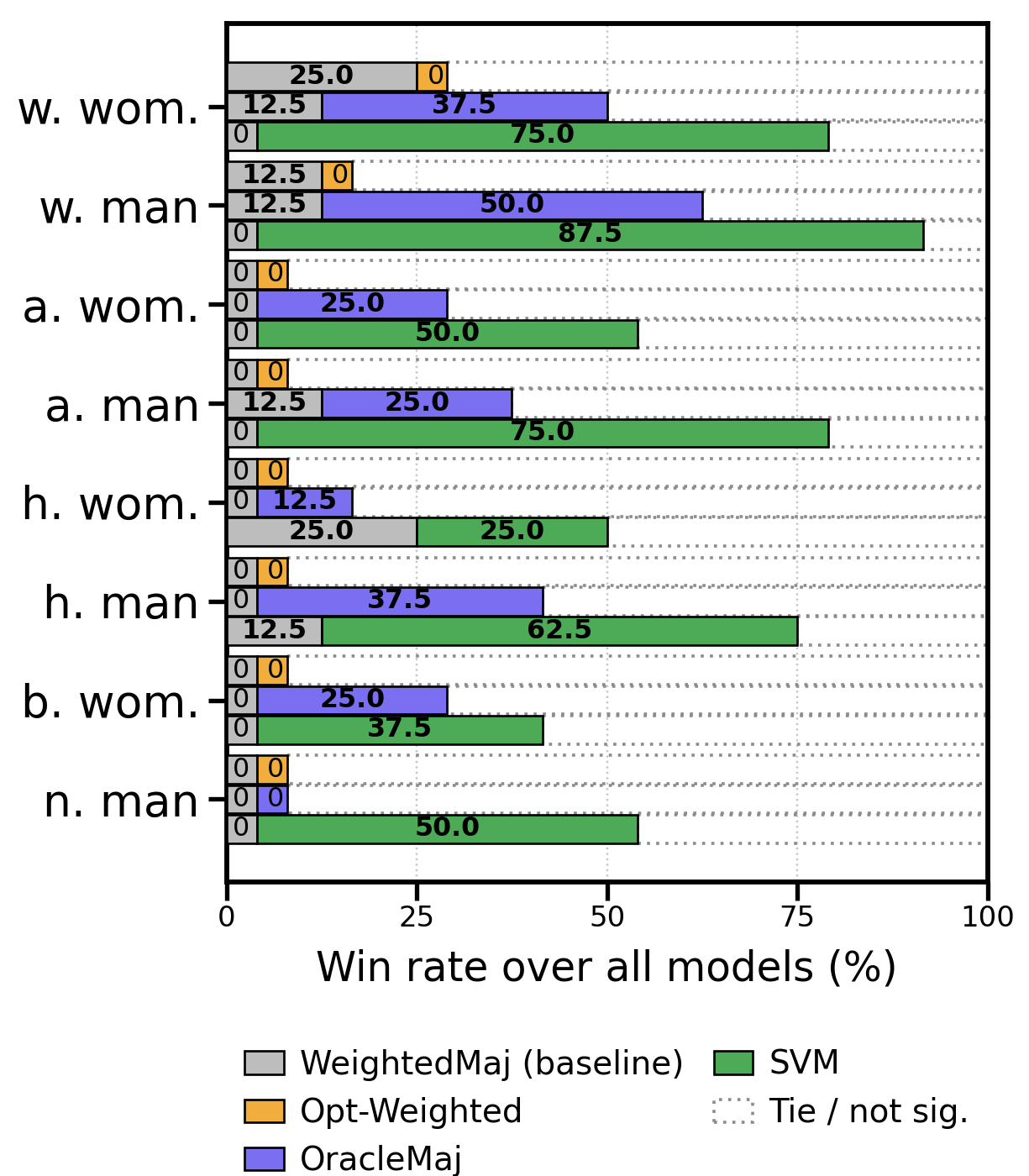
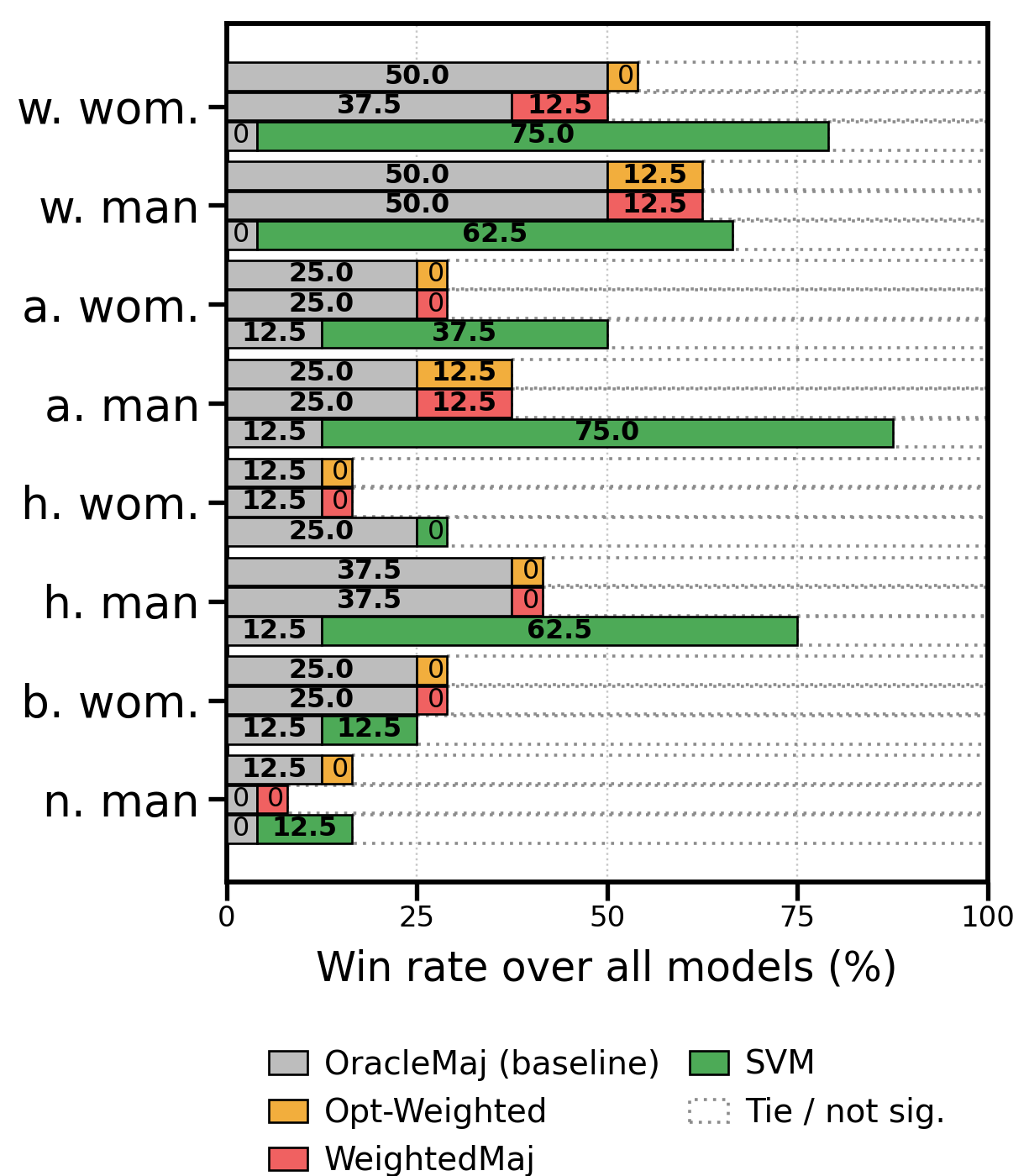
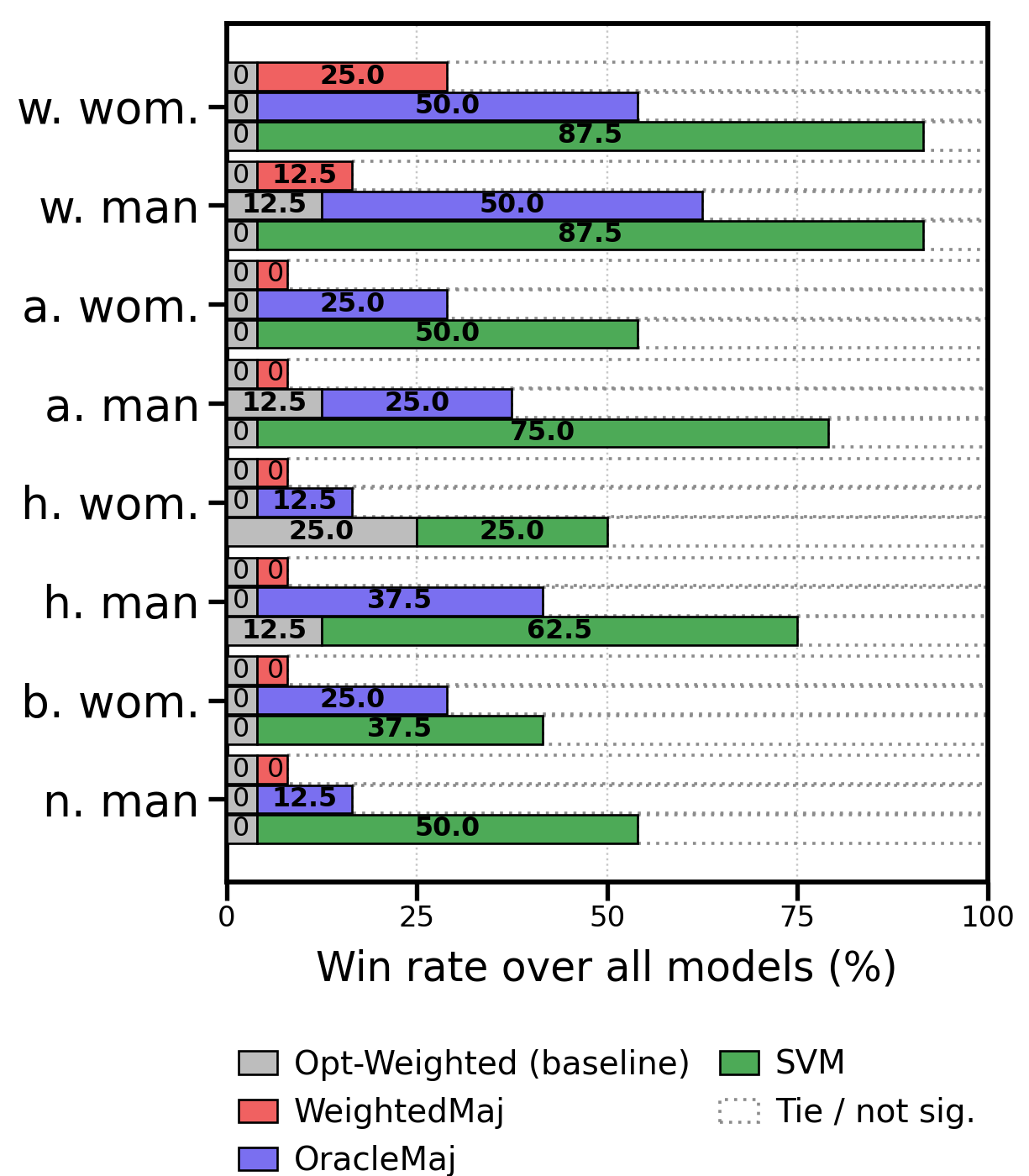
- Combining answers works best: Ensembling methods usually beat any single prompt. The best approach was the SVM meta-ensemble (the smart referee). It consistently outperformed:
- any individual prompting method
- simple majority voting
- weighted voting based on accuracy
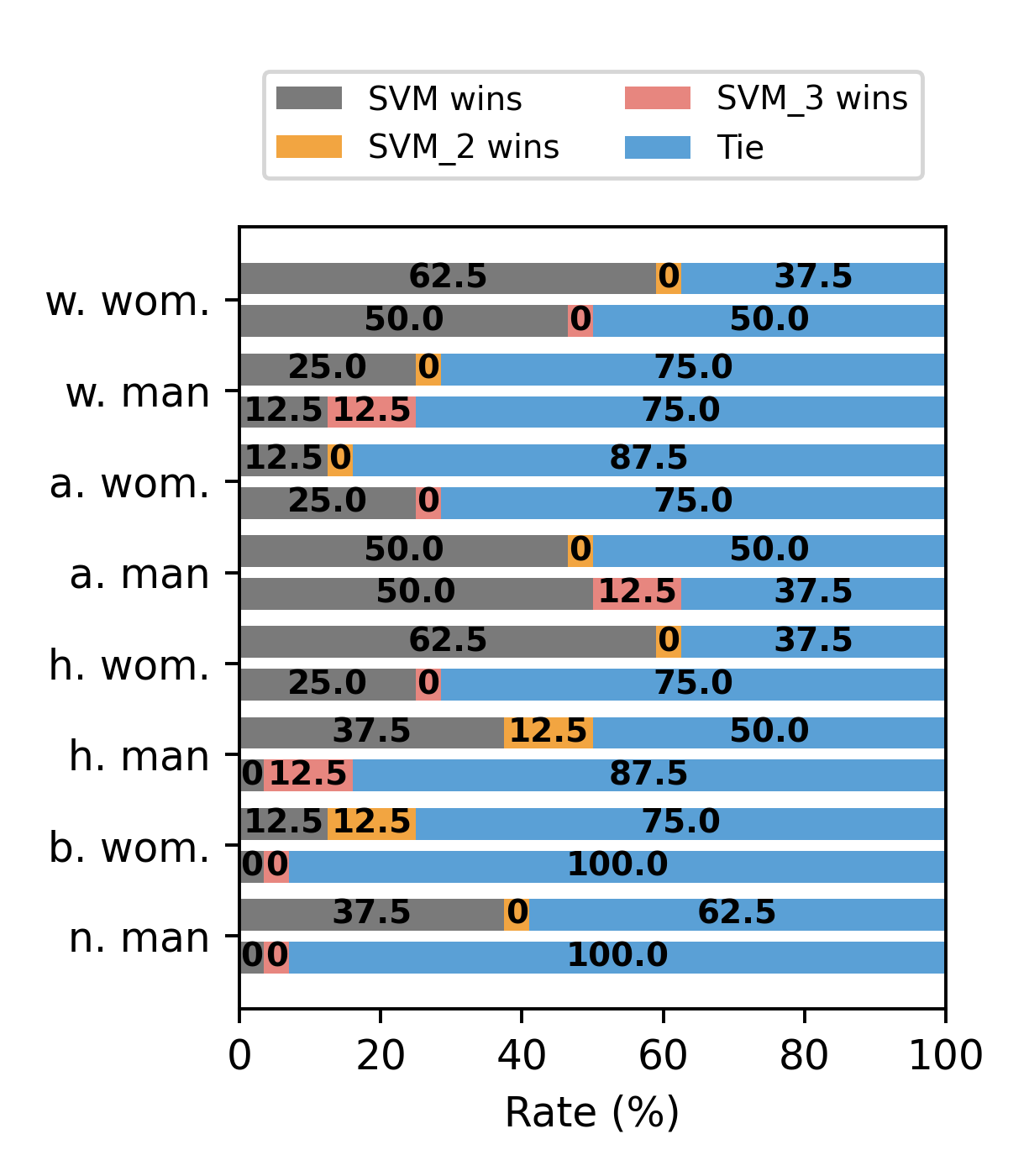
- More diverse inputs, better combo: An ablation (removal) test showed the SVM worked best when it used all four prompt outputs, not just two or three—because each prompt brings different strengths.
Why this matters:
- Toxicity is subjective. A system that can reflect different communities’ views is fairer and more realistic than a single “one-size-fits-all” label.
- When prompts disagree, a learned combiner (SVM) can reduce mistakes and improve reliability.
What’s the impact?
- For content moderation: Platforms could judge posts in a “pluralistic” way—understanding how different communities might feel—rather than forcing one universal answer. This could inform better, fairer moderation policies or community-specific settings.
- For research on subjective tasks: The idea of combining multiple perspective-aware prompts with a learned ensemble can be applied beyond toxicity (e.g., humor, politeness, offensiveness in different cultures).
- For building robust AI: Instead of searching for a single perfect prompt, it may be more effective to: 1) build multiple strong but different prompts (e.g., persona, value profile, optimized), 2) and learn how to combine their outputs.
One-sentence takeaway
When judging something subjective like offensiveness, asking the AI from multiple viewpoints and then using a smart combiner to make the final call is more reliable than relying on any single way of asking.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, actionable list of what remains missing, uncertain, or unexplored in the paper, framed to guide future research.
- Limited persona coverage: Only race+gender combinations with more than 400 examples were studied; queer identities, non-binary genders, age, religion, disability, socio-economic class, and intersectional traits remain unexamined.
- Single-language scope: All experiments are in English; cross-lingual pluralistic toxicity detection and personas in multilingual settings are unknown.
- Dataset dependence and generalizability: Results are based solely on Social Bias Frames; robustness on other toxicity datasets (e.g., HateXplain, Latent Hatred, ToxiGen) and real-world moderation logs is untested.
- Ambiguity in the “offensive to anyone” definition: The adopted definition may not align with persona-specific norms or dataset guidelines; effects of alternative definitions (e.g., target-centric harm vs. bystander offense) are not evaluated.
- Ground-truth alignment with personas: The mapping from annotator demographics to persona-specific ground truth is assumed but not audited for reliability, consistency, or bias; how well persona-conditioned predictions reproduce the target group’s judgments remains unclear.
- Base-rate calibration across personas: Personas have different offensive label prevalences (e.g., “Hispanic Woman” is highest), but prompt methods are not calibrated to those base rates; whether threshold tuning per persona improves performance is unanswered.
- Error-type analysis is missing: No breakdown of where prompts fail (e.g., implicit hate, sarcasm, coded language, dialect, reclaimed slurs); targeted error analyses could reveal which prompt variants complement each other.
- Dialect and identity mention sensitivity: Despite citing bias risks, the study does not quantify whether persona prompting mitigates or exacerbates overflagging of dialectal features (e.g., AAE) or identity mentions.
- Stability and randomness in LLM inference: Decoding parameters, temperature, and run-to-run variability are not reported; robustness of conclusions under different sampling settings is unknown.
- Prompt optimization reproducibility: TextGrad optimization used GPT‑4o with 100 train/100 validation examples per persona-model; sensitivity to optimizer choice, sample size, seeds, and prompt length/structure is not studied.
- Optimized prompts transparency: Optimized prompts and value profiles are not released or analyzed qualitatively; how these prompts encode values and whether they align with persona norms is unexplored.
- Value profile generation reliability: Value profiles are derived from just 14 examples with annotator disagreement via Gemini 1.5; how representative, stable, or biased these profiles are across different sample selections or models is untested.
- Potential data leakage risks: Using dataset examples to construct value profiles might encode test-set artifacts; safeguards and audits for leakage are not described.
- Statistical testing multiplicity: Many McNemar pairwise tests are reported, but multiple comparison corrections (e.g., Holm–Bonferroni, Benjamini–Hochberg) are absent; risk of inflated Type I error remains.
- Metric breadth: Evaluation relies primarily on F1 and McNemar; calibration (Brier score), ROC-AUC/PR-AUC, per-class precision/recall, and group fairness metrics (e.g., equalized odds, false positive rate gaps) are not reported.
- Modeling disagreement distributions: The work treats persona-conditioned classification as binary; modeling and evaluating full label distributions (e.g., probability mass over disagreeing annotators per persona) is not explored.
- Ensembling across models vs. prompts: Ensembles combine prompts within a single model, not across diverse models; whether cross-model ensembles yield larger gains is unaddressed.
- Meta-ensemble alternatives: The SVM with RBF kernel is compared to weighted voting, but not to other stacking/meta-learners (e.g., logistic regression, random forests, neural gating, mixture-of-experts) or dynamic instance-level selector policies.
- Confidence-aware aggregation: Ensembles use binary decisions; leveraging LLM confidence scores, logit proxies, or rationales for confidence-weighted fusion is not considered.
- Cost and latency trade-offs: Each inference uses four prompts; computational cost, throughput, and energy implications of the SVM ensemble vs. single-prompt baselines are not quantified.
- Transfer across personas and domains: The SVM is trained per persona; its ability to generalize to unseen personas, domain shifts, or novel targets is unknown.
- Underperformance for “Hispanic Woman”: Persistent degradation is observed but not deeply investigated; whether class imbalance, lexical priors, stereotype priming, or threshold miscalibration drive this remains unanswered.
- Human-in-the-loop validation: How pluralistic predictions should be surfaced to moderators, combined with human judgment, and used to inform decisions is not evaluated.
- Ethical and normative considerations: The choice of which personas to prioritize, risks of reinforcing stereotypes via persona prompts, and governance of pluralistic aggregation in high-stakes moderation are left open.
- Robustness under adversarial or strategic inputs: Susceptibility of persona-conditioned prompts and ensembles to prompt injection, adversarial rephrasing, or code-switching attacks is not tested.
- Safety and bias audits for optimized prompts: Automated prompt optimization could encode harmful priors; systematic safety audits (e.g., bias probes, toxicity stress tests) are absent.
- Hyperparameter sensitivity in SVM: Kernel choice, C/γ values, and their impact on performance and overfitting (given small training splits) are not reported.
- Multiple-family and closed-source LLMs: Only Llama and Qwen families (including R1-distilled variants) are assessed; whether findings replicate in closed-source/commercial models (e.g., GPT‑4, Claude, Gemini) is unknown.
- Release for reproducibility: Full prompts, optimized prompt artifacts, code, and seeds are not provided; end-to-end reproducibility and independent verification are constrained.
Practical Applications
Below is a concise mapping from the paper’s contributions (persona-conditioned prompting, TextGrad-based prompt optimization, and an SVM meta-ensemble over multi-prompt outputs) to practical, real-world applications. Each item notes sectors, suggested tools/workflows, and key dependencies that affect feasibility.
Immediate Applications
These can be piloted or deployed now using current LLMs and standard MLOps stacks.
- Pluralistic content moderation and safety triage
- Sector: software, social media, online communities, gaming, collaboration tools (e.g., Slack/Teams/Discord), media
- What: Deploy the SVM meta-ensemble over four prompting variants (default, persona, value-profile, optimized persona) to produce a more robust toxicity verdict and a disagreement signal across personas; route high-disagreement items to human review.
- Tools/workflows:
- “Pluralistic Toxicity Scorer” microservice: runs four prompts per post and feeds the 4-bit output to an SVM classifier.
- Moderator dashboard: shows per-persona predictions, consensus score, and explainability notes (e.g., disagreement heatmap by persona).
- Triage rules: auto-block consensus-toxic, queue disagreement cases, log per-persona trends for audit.
- Dependencies/assumptions: Access to at least one LLM that can be reliably prompted; a small labeled slice per community/persona to train the SVM; cost budget for multi-prompt inference; clear persona taxonomy that avoids stereotyping; compliance with data privacy and transparency rules.
- Fairness and bias audits for existing toxicity pipelines
- Sector: industry (trust & safety), academia (NLP evaluation), policy (regulators, standards bodies)
- What: Use persona-conditioned prompting as a comparative “judge” to audit current toxicity classifiers for disparate error patterns (e.g., dialect bias), report gaps across demographic perspectives.
- Tools/workflows:
- Audit harness that compares base classifier vs. pluralistic ensemble using paired tests (e.g., McNemar) and subgroup error analyses.
- Reporting pack for compliance/transparency with persona-sliced precision/recall and disagreement rates.
- Dependencies/assumptions: Representative samples for the relevant personas; governance processes to interpret persona-based findings responsibly; buy-in for pluralistic metrics instead of single “ground truth.”
- Community-guideline–aligned moderation for niche forums
- Sector: education (campus forums), healthcare (patient/peer support boards), professional associations, hobbyist communities
- What: Apply value-profile prompts or optimized persona prompts to align toxicity judgments with community norms (e.g., stricter for patient safety forums; more tolerant for reclaimed language in in-group contexts).
- Tools/workflows:
- Value-profile generation from community exemplars (7 toxic/7 non-toxic seeds per persona/community segment).
- Continuous prompt optimization using TextGrad-style APE to reflect evolving norms.
- Dependencies/assumptions: Availability of representative in-context examples; periodic re-validation by community moderators; careful safeguards against codifying harmful norms.
- Workplace compliance and HR harassment monitoring
- Sector: enterprise, finance, consulting, regulated industries
- What: Use the ensemble to reduce false positives for dialectal or culturally distinctive language while flagging high-confidence harassment cases; generate persona-aware disagreement flags for HR review.
- Tools/workflows:
- “Compliance Co-pilot” that runs in shadow mode on Slack/Teams logs with sampling and anonymization.
- Escalation rules tuned to minimize chilling effects on culturally diverse teams.
- Dependencies/assumptions: Strong privacy posture (DLP), employee consent/notification, legal review; small labeled set for SVM tuning to each org.
- Rapid A/B testing and model selection for toxicity tasks
- Sector: MLOps across software platforms
- What: Use the paper’s finding that reasoning-enhanced models may underperform on social reasoning to inform model choice; verify with small-scale A/B tests and retain ensemble output for robustness.
- Tools/workflows:
- Evaluation harness comparing base vs. reasoning LLMs across personas.
- Canary deployment of SVM ensemble as safety net while new models are tested.
- Dependencies/assumptions: Access to multiple LLM backends; evaluation data representing target communities; cost and latency budgets for multi-prompt inference.
- Scalable LLM-judge–assisted dataset curation
- Sector: academia, data providers, open-source communities
- What: Use the pluralistic ensemble to pre-label or triage examples for human annotation, focusing attention on high-disagreement items that are most informative for pluralistic datasets.
- Tools/workflows:
- Active-learning loop prioritizing examples where persona methods diverge.
- Labeling UI that surfaces per-persona scores and captures annotator demographics.
- Dependencies/assumptions: Clear annotation guidelines that acknowledge subjectivity; consent and protection for annotators; IRB/ethics oversight where required.
Long-Term Applications
These require further research, scaling, policy consensus, or product maturation.
- Personalized, opt-in moderation experiences
- Sector: consumer platforms, social media
- What: Allow users to opt into moderation settings aligned to value profiles (e.g., stricter, harm-avoidant filters) while keeping platform-wide minimum standards.
- Potential products:
- “Moderation Profiles” with transparent policy documentation and appeal workflows.
- Dependencies/assumptions: Extensive UX research to avoid filter bubbles or discrimination; rigorous legal/ethical review; transparent governance and appeal mechanisms.
- Standards for pluralistic evaluation and transparency reporting
- Sector: policy, standards bodies, regulators
- What: Use pluralistic, persona-aware scoring in transparency reports (e.g., per-persona false positive/negative rates), complementing single-number metrics.
- Potential workflows:
- Regulator-approved evaluation protocols that include multi-persona metrics and disagreement rates.
- Dependencies/assumptions: Consensus on persona definitions and ethical use; standardized benchmarks beyond English; alignment with anti-discrimination laws.
- Foundation models trained with pluralistic supervision
- Sector: AI/ML research, foundation model providers
- What: Train or fine-tune models on multi-annotator, persona-tagged labels so models natively support pluralistic scoring without multi-prompt overhead.
- Potential tools:
- Multi-head architectures or conditional adapters keyed by value profiles/personas.
- Dependencies/assumptions: Large, representative pluralistic datasets; careful avoidance of stereotyping; compute budget; guardrails against misuse.
- Cross-lingual and culturally adaptive toxicity detection
- Sector: global platforms, multilingual communities, international NGOs
- What: Extend persona/value-profile prompting and SVM ensembling to multiple languages and culturally-specific norms.
- Potential workflows:
- Localized value-profile generation; cross-lingual transfer with region-specific audits.
- Dependencies/assumptions: High-quality multilingual data; native-speaker oversight; adaptation to local legal norms.
- Multimodal pluralistic safety (text, images, audio, video)
- Sector: social media, gaming, livestreaming
- What: Generalize the ensemble approach to fuse multi-prompt judgments across modalities (e.g., toxic meme text + image), with persona-aware reasoning.
- Potential tools:
- Multimodal meta-ensembles that take per-modality prompt outputs as inputs.
- Dependencies/assumptions: Robust multimodal models; training data with pluralistic labels across modalities; explainability interfaces.
- Adaptive, online-learned ensembling with context and policy retrieval
- Sector: MLOps, enterprise platforms
- What: Replace static SVM with online or context-aware meta-learners that incorporate retrieved community guidelines and incident feedback; dynamically update weights/prompts per community.
- Potential tools:
- RAG-enhanced “Policy Aware” ensemblers; streaming feedback loops from moderator actions.
- Dependencies/assumptions: Safe online learning infrastructure; audit trails; safeguards against feedback loops and policy drift.
- Educational tools for digital citizenship and media literacy
- Sector: education, civic tech, NGOs
- What: Teaching aids that show how different groups might perceive the same post; learners explore disagreements and discuss community norms.
- Potential products:
- Interactive classroom modules with persona-aware scoring and reflection prompts.
- Dependencies/assumptions: Age-appropriate content; educator training; sensitive handling of protected characteristics.
- Healthcare and mental-health community safety
- Sector: healthcare, patient support, mental health platforms
- What: Deploy pluralistic moderation tuned to vulnerable population norms (e.g., recovery forums), reducing both harm and over-censorship.
- Potential workflows:
- Clinician- or moderator-in-the-loop review of disagreement cases; value profiles co-designed with patient advocates.
- Dependencies/assumptions: Strong privacy/security; medical governance; careful thresholding to avoid suppressing supportive peer language.
- Enterprise-grade harassment and DEI analytics
- Sector: enterprise, HR tech
- What: Longitudinal analytics of workplace communication with persona-aware fairness checks; identify departments with elevated disagreement rates for targeted training.
- Potential tools:
- DEI dashboards integrating pluralistic toxicity signals and remediation tracking.
- Dependencies/assumptions: Strict anonymization; legal review; clear separation of analytics from punitive monitoring; organizational change management.
Notes on feasibility across applications:
- Cost/latency: Multi-prompt inference is more expensive; batching and caching help; training a lightweight SVM is cheap but needs labeled slices per community/persona.
- Data/ethics: Persona constructs must be carefully defined to avoid stereotyping; opt-in where personal data is involved; robust governance for value-profile creation.
- Generalization: Results are based on English data and specific model families; outcomes may differ for other languages or closed-source systems; continuous evaluation is necessary.
- Performance disparities: The paper notes persona-specific weaknesses (e.g., Hispanic woman), implying ongoing monitoring and targeted prompt/model improvements are required.
Glossary
Accuracy-based Weighted Majority Voting: An ensembling approach that adjusts the voting weights based on the accuracy of each method on training data. Example: "...we explore weighted and unweighted majority voting approaches and propose a simple ensembling method."
Demographic-aligned language features: Features of language that are unique to certain demographic groups, such as dialect variations. Example: "Demographic-aligned language features (e.g., African-American English) differ from mainstream norms..."
Dialect variation: Differences in language use patterns among speakers from different demographic backgrounds. Example: "Dialect variation further amplifies this issue: demographic-aligned language features..."
Ensembling Techniques: Methods for combining the predictions of multiple models or approaches to improve performance. Example: "Motivated by the broader success of ensembling and aggregation for improving reliability..."
LLMs: Advanced models designed to understand and generate human-like text. Example: "...current LLM prompting techniques have different results across different personas..."
Persona-conditioned prompting: A method of designing prompts that target specific personas in order to model different perspectives. Example: "In this work, we study two persona-conditioned prompting approaches..."
Pluralistic modeling: Modeling technique that captures differences in perspectives across diverse contexts. Example: "While 'pluralistic' modeling, as used in economics and the social sciences, aims to capture perspective differences across contexts..."
Prompt optimization: The process of refining and improving prompts to enhance model performance. Example: "...including our proposed automated prompt optimization strategy, uniformly dominates across all model-persona pairs."
Social Priors: Pre-existing societal beliefs or assumptions that influence interpretation and judgment. Example: "...inherently subjective, shaped by the diverse perspectives and social priors of different demographic groups."
Support Vector Machine (SVM): A machine learning model used for classification tasks, often employed for binary classification with linear or non-linear separations. Example: "...and learns a discriminative combiner using a support vector machine (SVM)."
Collections
Sign up for free to add this paper to one or more collections.

