- The paper introduces Persona-LLMs that incorporate socio-demographic attributes to mitigate bias in hate speech detection.
- It employs both shallow and deeply contextualized persona prompting, using Gemini and GPT-4.1-mini to balance sensitivity and specificity.
- Findings reveal that aligning simulator personas with target groups improves accuracy, paving the way for more equitable content moderation.
Algorithmic Fairness in NLP: Persona-Infused LLMs for Human-Centric Hate Speech Detection
Introduction
The detection and moderation of hate speech in online platforms represent major challenges in NLP due to linguistic variability, context dependency, and inherent biases in datasets. Traditional lexicon-based methods and machine learning techniques have proven inadequate due to their lack of context-awareness and susceptibility to biases. The advent of deep learning, particularly with models like RNNs and Transformer-based architectures such as BERT, has significantly advanced the field by capturing complex linguistic patterns and leveraging extensive contextual information. However, these models still suffer from significant biases when trained on datasets that reflect societal prejudices, leading to unfair outcomes in content moderation.
The research presented in "Algorithmic Fairness in NLP: Persona-Infused LLMs for Human-Centric Hate Speech Detection" (2510.19331) tackles these biases by introducing Persona-LLMs, which incorporate socio-demographic attributes into their methodology. The approach leverages in-group and out-group annotator dynamics to enhance fairness and sensitivity in hate speech detection.
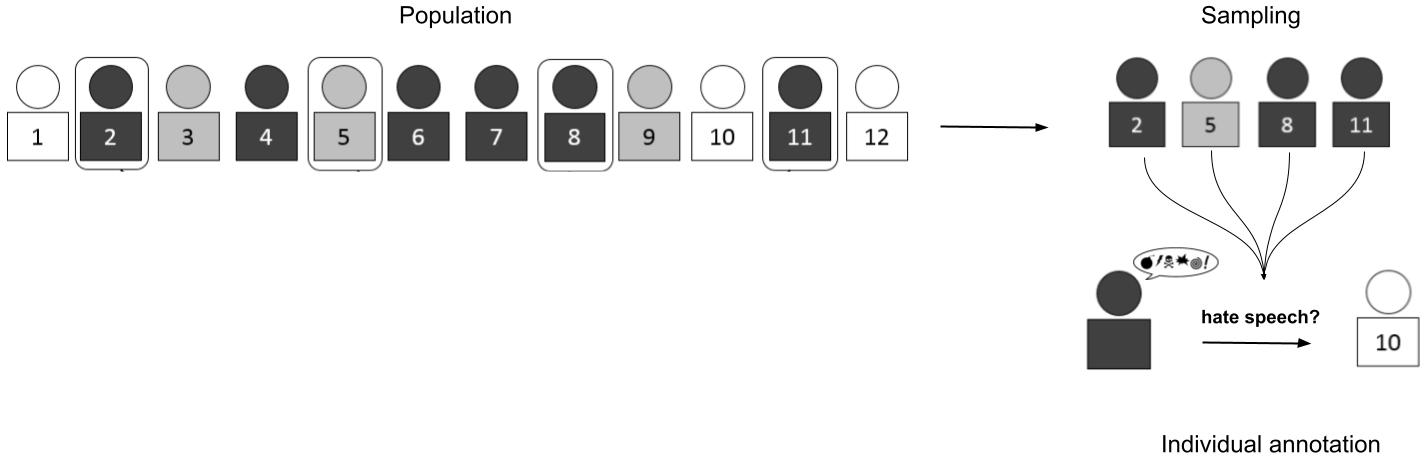
Figure 1: A sample versus a population - how sampling bias of the annotator pool can influence hate speech annotation.
Methodology
The research employs two advanced models, Google's Gemini and OpenAI's GPT-4.1-mini, coupled with persona-prompting methods to simulate diverse human perspectives in hate speech detection. The shallow persona prompting assigns LLMs basic identity attributes to guide hate speech annotation, whereas deeply contextualised persona development employs Retrieval-Augmented Generation (RAG) to enrich these personas with comprehensive identity profiles.
The study explores the impact of using in-group versus out-group personas on model performance. By modeling these dynamics, the research investigates whether incorporating the personas related to specific identity groups can mitigate biases by accurately reflecting the perceptions and experiences of those impacted by hate speech. This approach aims to capture the complex interplay between language, identity, and context in shaping perceptions of hate.
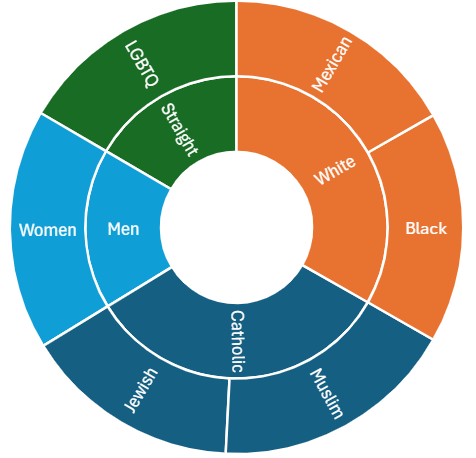
Figure 2: A distribution of annotations by ingroup (outward categories in the chart) and outgroup (inward categories) LLM annotators.
Results
The results demonstrate a clear performance advantage of Persona-LLMs, showing improved accuracy in hate speech detection when the simulator persona aligns with the target group. In-group personas exhibit higher false positive rates due to an increased sensitivity, while out-group personas show higher false negative rates, failing to detect nuanced hate speech.
The deeply contextualised personas, incorporating rich contextual cues, significantly outperform their shallow counterparts by improving detection precisely and balancing sensitivity and specificity. This enhancement in detection illustrates the importance of comprehensive persona modeling in bias mitigation.
Implications and Future Directions
The implications of this research are significant for advancing the fairness and effectiveness of hate speech detection systems. By incorporating diverse identity perspectives into model design, the study offers a pathway towards mitigating biases inherent in traditional NLP methodologies. This persona-infused approach also provides valuable insights for enhancing dataset annotation processes, potentially forming the foundation for more equitable content moderation systems in digital platforms.
Future research should focus on expanding this framework to incorporate additional contextual signals and validate simulated annotations against real-world perceptions. Further exploration is needed to apply this paradigm in other sensitive areas of NLP that are socially and culturally nuanced.

Figure 3: The process of developing and annotating text with deeply contextualised persona prompting.
Conclusion
The study addresses a pressing need in hate speech detection by integrating socio-demographic awareness into LLMs. By synthesizing psychological insights on group identity with state-of-the-art NLP technologies, the research demonstrates a novel approach to tackling biases in automated systems. The findings underscore the potential of Persona-LLMs in promoting equitable and contextually aware hate speech detection, paving the way for more inclusive artificial intelligence systems that better serve diverse online communities.