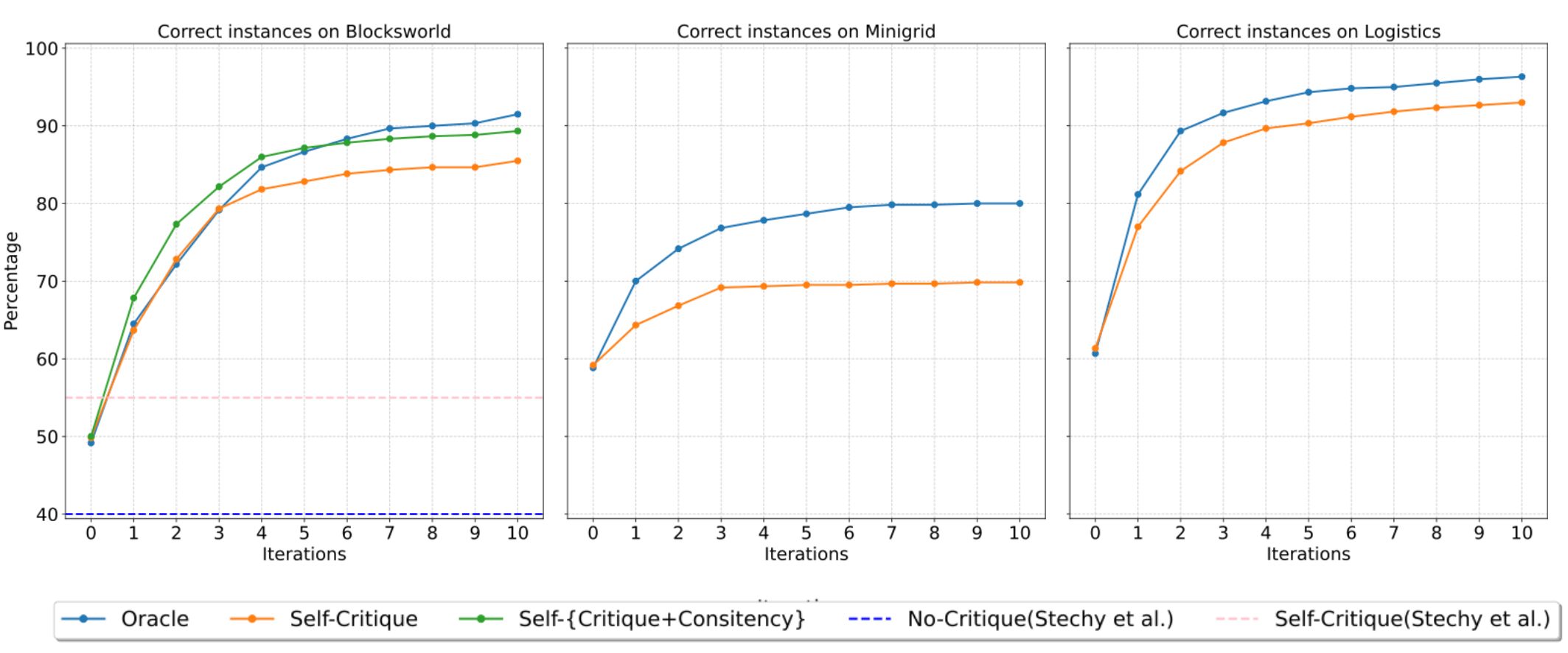
- The paper demonstrates that intrinsic self-critique can significantly boost planning accuracy, with improvements up to 89.3% in Blocksworld tasks.
- It introduces an iterative pipeline combining plan generation, self-evaluation, and context augmentation to refine LLM outputs without external feedback.
- Empirical results across domains like Logistics and Mini-grid validate the approach's robustness and practical applicability for LLM-based planning.
Intrinsic Self-Critique for Planning with LLMs
Introduction
Planning with LLMs presents a challenging application space at the intersection of symbolic AI and neural sequence modeling. Historically, LLMs have underperformed in structured planning compared to classic combinatorial planners. However, the intrinsic ability of LLMs to self-evaluate and refine their outputs, commonly termed self-critique, holds promise for bridging this gap without reliance on external oracles or human feedback. "Enhancing LLM Planning Capabilities through Intrinsic Self-Critique" (2512.24103) systematically investigates an iterative, purely in-context self-critique procedure and demonstrates substantial performance improvements across standard benchmarks, establishing new state-of-the-art results for the model class considered.
Methodological Framework
The central methodological contribution is an iterative self-critique pipeline for plan synthesis:
- Plan Generation: At each iteration, the LLM is prompted with the planning problem (typically specified in PDDL, sometimes obfuscated as in mystery Blocksworld), along with domain definitions and a context window containing previous plans and critiques.
- Self-Critique: The LLM evaluates the proposed plan using an automatically constructed prompt that instructs the model to check, for each action, whether its preconditions are met, simulating a step-by-step verifier.
- Context Augmentation: Both the failed plan and analysis are appended to the context for subsequent iterations, directly supplying the model with observed failures.
- Termination: The loop continues until either a plan is declared correct by the model’s self-critique or a maximum number of iterations is reached.
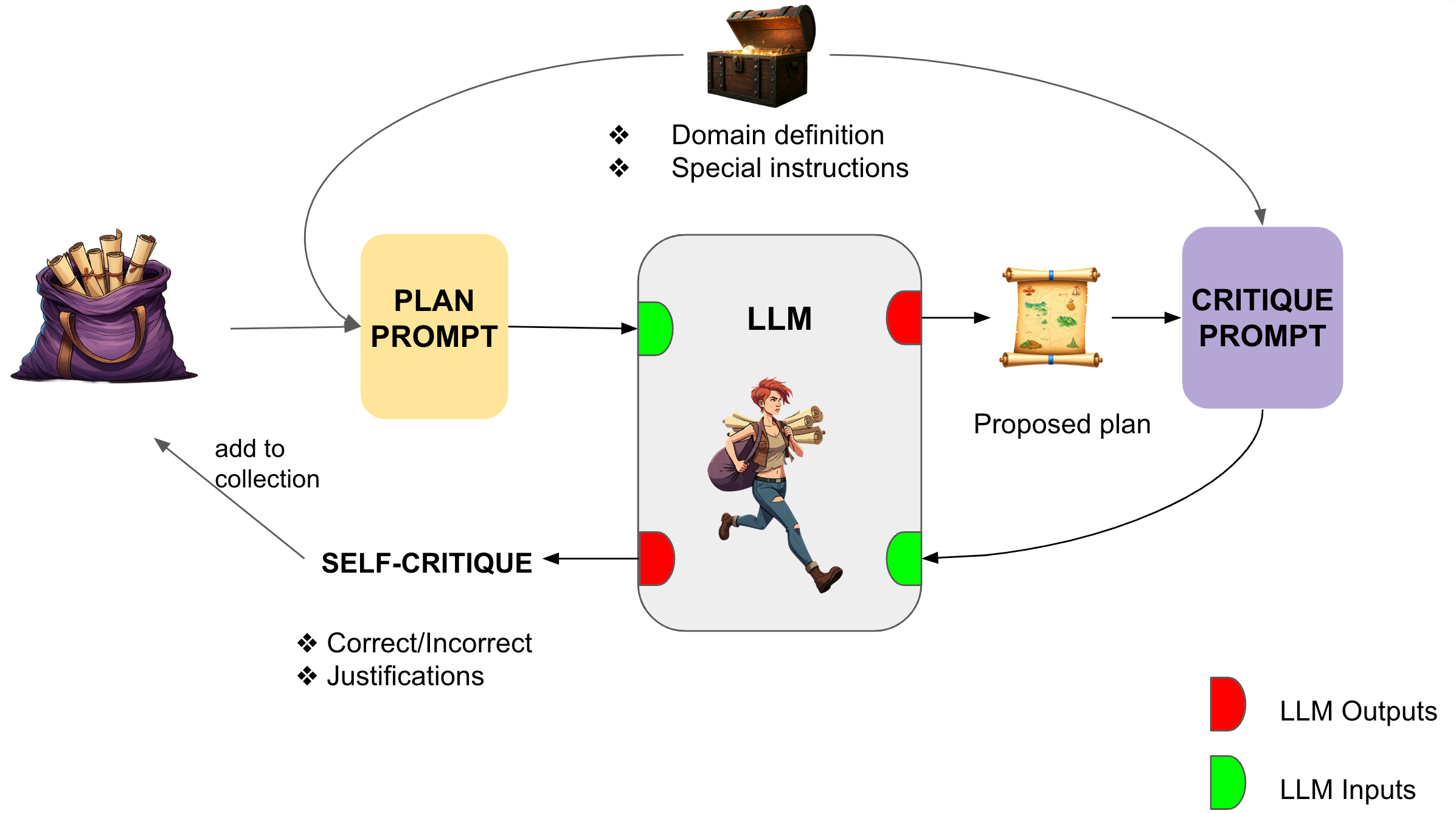
Figure 1: Illustration of the core iterative self-critique loop, with LLM-generated plans, self-verification, failure collection, and context augmentation.
Key to this approach is a rigorous prompt design, supplying explicit domain definitions, concrete instructions for state-tracking, and optionally, few-shot examples for the planning and critique subtasks. The self-critique prompt can operate in zero-shot or few-shot regimes and incorporates step-by-step logic for action verification, significantly improving error localization and downstream self-correction.
Experimental Protocol and Benchmarks
The evaluation spans a breadth of symbolic planning domains:
- Blocksworld (Standard and Mystery Variants): Classical stacking, with both plain predicate names and intentionally obfuscated versions.
- Logistics and Mini-grid: Multi-object, multi-location domains with combinatorially complex state spaces.
- AutoPlanBench: Extension to additional domains to validate generalization.
- Multiple LLMs are assessed, including Gemini 1.5 Pro, GPT-4o, Claude 3.5 Sonnet, and Gemma 2-27B.
Performance is measured as strict plan correctness (goal achieved per ground-truth validator), not relaxed metrics. Extensive ablation studies dissect the impact of prompt elements, number of self-critique iterations, temperature, few-shot strategy, and model class.
Empirical Results
A primary finding is that iterative intrinsic self-critique, even without external validation, drives dramatic and sustained accuracy gains across major planning benchmarks:
Influence of Few-Shot Prompting
In-depth analysis shows that increasing the number of exemplars in planning prompts yields further accuracy gains, especially on more regular domains (e.g., Blocksworld), with diminishing returns and context budget constraints appearing at higher shot counts.
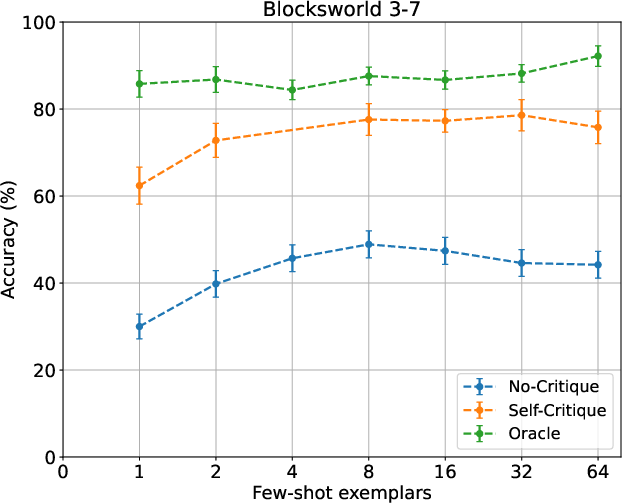
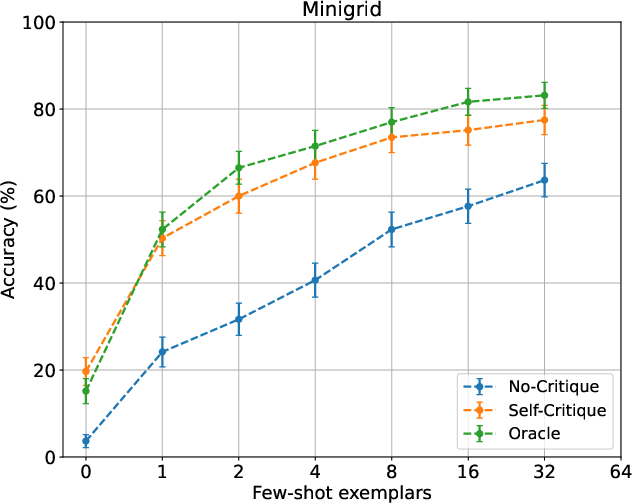
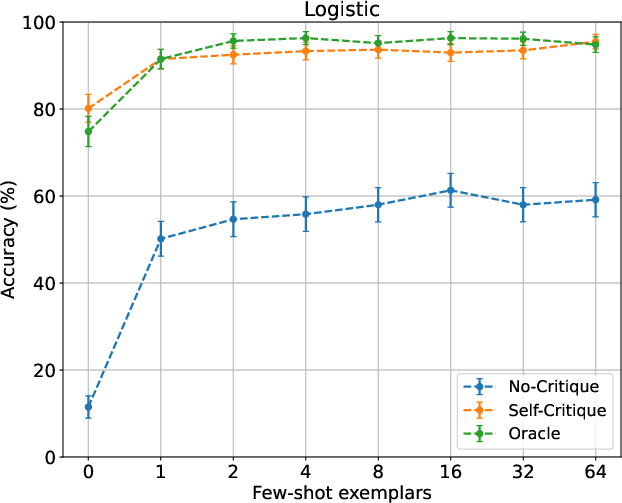
Figure 3: Improvement in planning accuracy with increasing few-shot exemplars; Blocksworld and Mini-grid benefit substantially from more shots.
Self-Critique Prompt Structure and Self-Consistency
Prompt ablation reveals that including the full domain definition and explicit step-by-step state verification instructions are essential for maximal accuracy. Self-consistency (majority voting over multiple critiques) further narrows the gap between intrinsic self-critique and oracle-verified iterative planning.
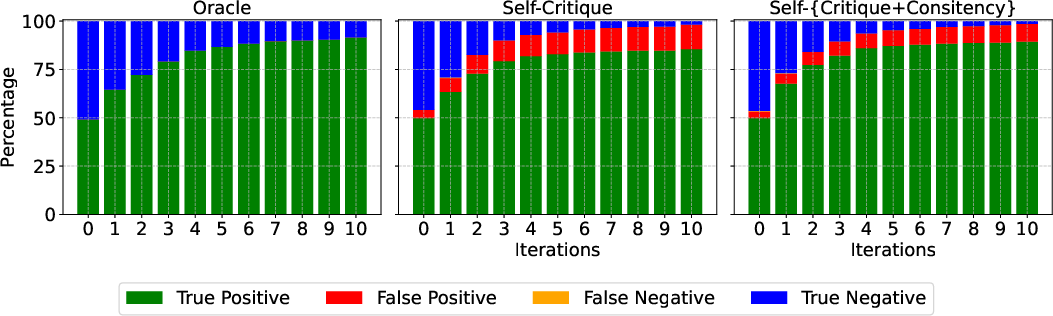
Figure 4: Accuracy, recall, and precision of the self-critique process through multiple refinement steps, highlighting robust recall but room for reducing false positives.
Error Analysis, Limitations, and Ablations
A recurring pattern in error analysis is the prevalence of false positives in the self-critique judgments, with the majority of ablation-induced degradations stemming from omission of domain definitions or explicit verification steps. Prompt temperature modulates the diversity/variance of model proposals, but a low value is preferred for reliability in both plan generation and critique.
Broader benchmarking (AutoPlanBench, additional foundation models) confirms the method’s generality, but also highlights that larger models (e.g., Gemini 1.5 Pro, Claude 3.5 Sonnet) exhibit more effective self-improvement than smaller open models (Gemma 2-27B).
Theoretical and Practical Implications
The findings contradict prior negative results on the self-verification and self-correction capabilities of LLMs in planning [valmeekam2023largelanguagemodelsreally, huang2024largelanguagemodelsselfcorrect], demonstrating that with sufficient prompt engineering and in-context iterative feedback, substantial intrinsic plan refinement is possible. The absence of reliance on external verifiers makes this approach applicable in settings where ground-truth oracles are impractical.
Practically, the results point toward planning agents that can self-correct using only their own generative and evaluative faculties, promising particular utility in open-world natural language planning, where symbolic validators are inapplicable. Theoretically, they highlight the latent ability of sufficiently capable LLMs to learn constraint satisfaction and stepwise error localization in context, reinforcing the hypothesis that planning proficiency in LLMs is a function of scaling, prompt granularity, and iterative feedback.
Future Directions in LLM Planning
Several open directions are implied. Integrating more advanced search schemes (e.g., Monte-Carlo Tree Search, Chain-of-Thought with iterative refinement [wei2022chain, yao2023tree, madaan2023selfrefine]), further increasing shot count or context length, and hybridizing with RL-style self-play or debate [du2023improving] could yield further performance gains. Moreover, closing the gap with classic planners in more complex domains remains an outstanding challenge.
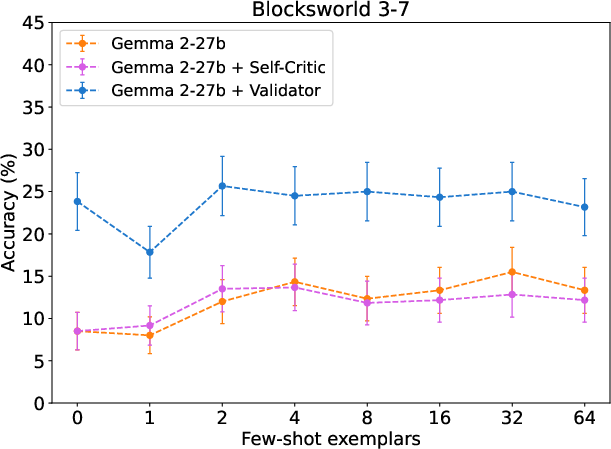
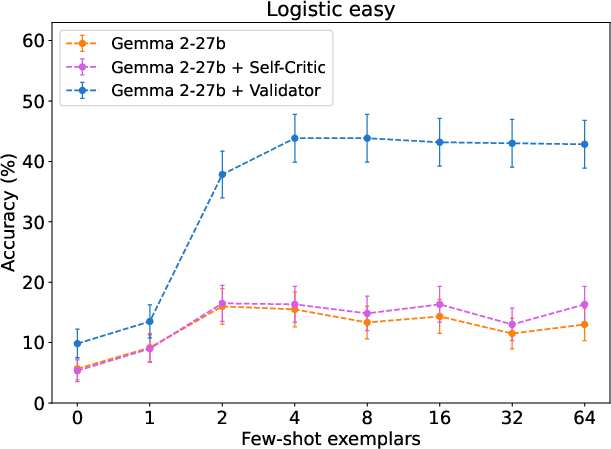
Figure 5: Evaluation of performance scaling with open-source Gemma 2-27B across planning domains.
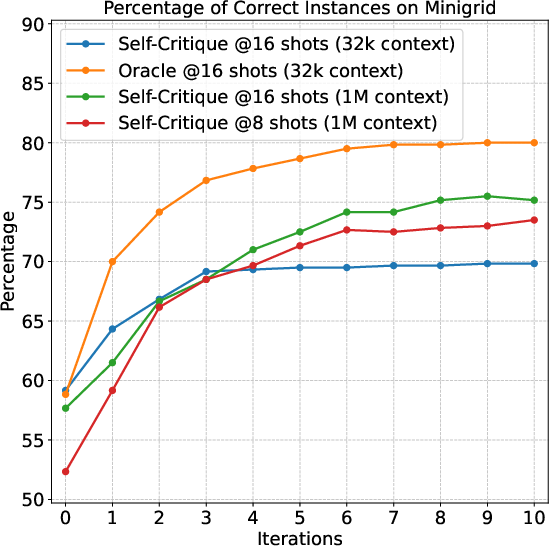
Figure 6: Comparison of planning performance on Mini-grid with varying context length and shot count, indicating robustness of the self-critique method at large scale.
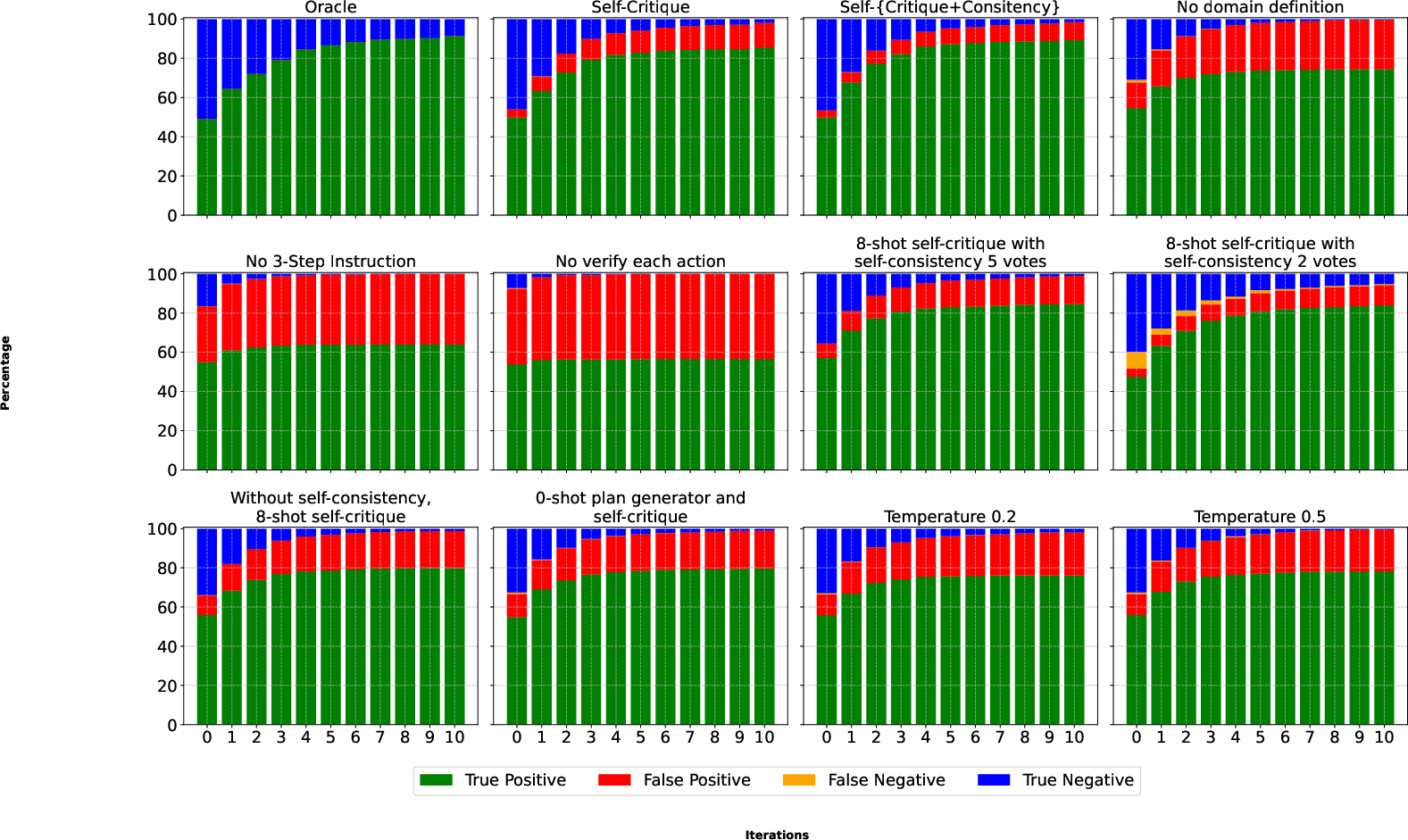
Figure 7: Longitudinal analysis of self-critique accuracy and recall over 11 improvement steps.
Conclusion
This work rigorously demonstrates that intrinsic, purely in-context self-critique can robustly and substantially enhance the symbolic planning performance of state-of-the-art LLMs, achieving or surpassing previously unattainable accuracy levels on multiple benchmarks without any external feedback. The protocol generalizes to several domains and model classes and invites numerous extensions at the intersection of symbolic reasoning, prompt design, and scalable neural AI planning.