Epistemological Fault Lines Between Human and Artificial Intelligence
Abstract: LLMs are widely described as artificial intelligence, yet their epistemic profile diverges sharply from human cognition. Here we show that the apparent alignment between human and machine outputs conceals a deeper structural mismatch in how judgments are produced. Tracing the historical shift from symbolic AI and information filtering systems to large-scale generative transformers, we argue that LLMs are not epistemic agents but stochastic pattern-completion systems, formally describable as walks on high-dimensional graphs of linguistic transitions rather than as systems that form beliefs or models of the world. By systematically mapping human and artificial epistemic pipelines, we identify seven epistemic fault lines, divergences in grounding, parsing, experience, motivation, causal reasoning, metacognition, and value. We call the resulting condition Epistemia: a structural situation in which linguistic plausibility substitutes for epistemic evaluation, producing the feeling of knowing without the labor of judgment. We conclude by outlining consequences for evaluation, governance, and epistemic literacy in societies increasingly organized around generative AI.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper looks at a big question: Do today’s AI chatbots (like ChatGPT and others) “think” like people? The authors argue that, even when AI gives answers that sound human, the way it creates those answers is totally different from how humans make judgments. They call the gap between “what sounds right” and “what is truly known” Epistemia, and they explain why this matters for schools, science, media, and society.
What are the main questions the paper asks?
The paper focuses on simple, but important questions:
- How do LLMs actually produce their answers?
- In what ways is this process different from human thinking and judgment?
- Why do AI answers often sound smart and convincing even when they’re wrong or ungrounded?
- What risks come from replacing human evaluation with AI-generated “plausible” text?
- How should we adjust our tools, rules, and education to handle these differences?
How did the authors approach the topic?
The authors explain AI in everyday terms and compare it step-by-step with human judgment. Here are the key ideas in plain language:
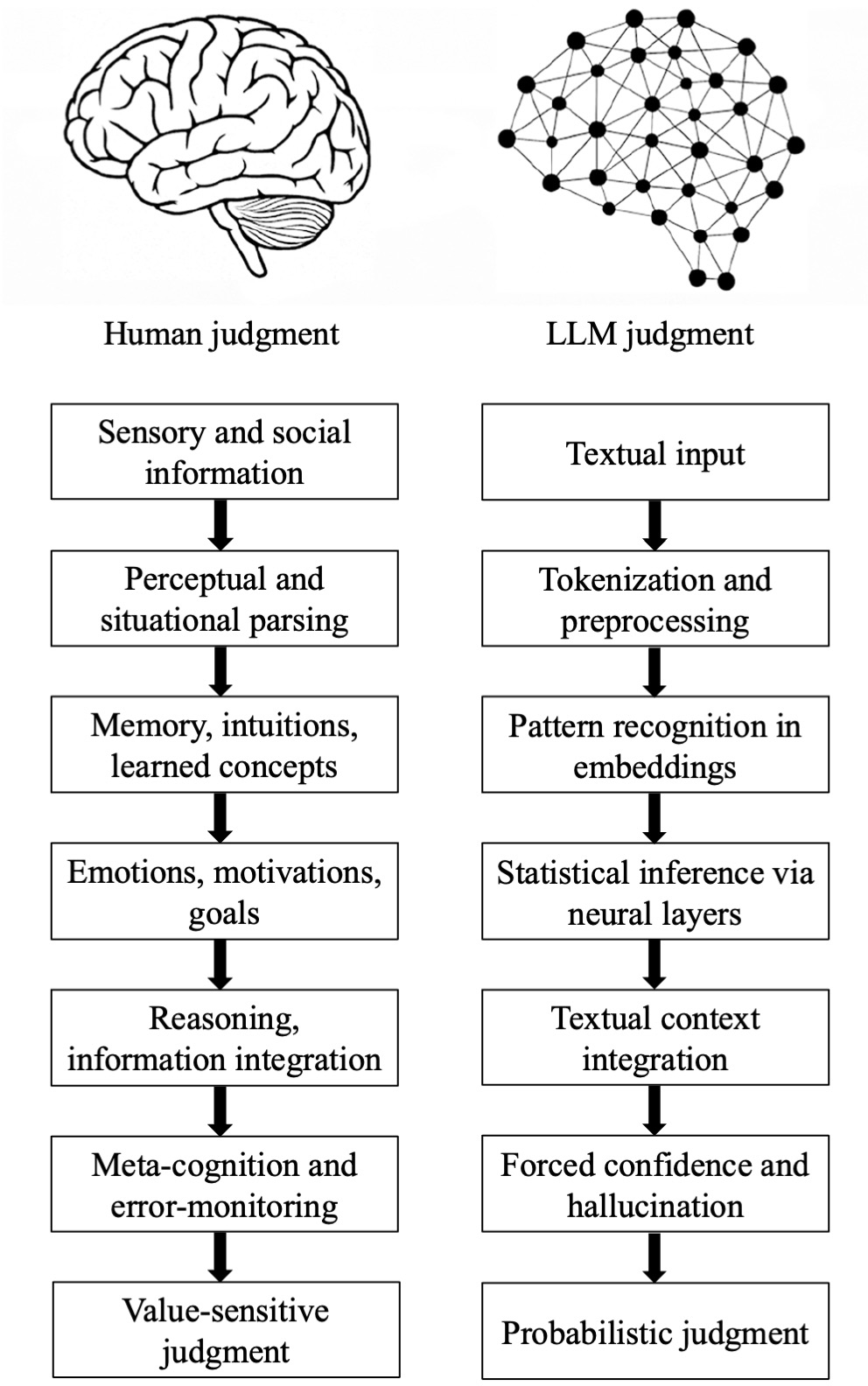
- Think of an LLM as a super-powered autocomplete. It looks at a lot of text and guesses the next word, then the next, and so on. Its job is to continue language smoothly, not to “know” things the way people do.
- They describe AI text generation like walking through a giant map of words. Each word is a “node,” and the model moves from one to the next along paths that are more or less likely. Choices are guided by probability, not by truth or understanding.
- They show how AI moved from “information filtering” (like search engines that give you a list of sources) to “information generation” (chatbots that give you one polished answer). This shift matters because the answer looks ready-to-use and can skip the human step of checking, comparing, and judging sources.
- They compare the human “judgment pipeline” (how people form beliefs) with the AI “answer pipeline” (how models produce text). This comparison reveals seven “fault lines.”
What did they find?
The authors identify seven big differences—called “epistemological fault lines”—between human judgment and AI output. Here they are in simple terms:
- Grounding: Humans start with the real world—seeing, hearing, feeling, and social context. AI starts with text. No bodies or environments, just symbols.
- Parsing: Humans take messy situations and understand them as scenes, people, intentions, and risks. AI breaks strings into tokens (little text pieces) for calculation. It’s a mechanical split, not a scene understanding.
- Experience: Humans have memories, intuition about physics and people (like “objects don’t pass through walls,” “others have beliefs”), and learned concepts. AI has statistical patterns from text but no lived experience or built-in commonsense.
- Motivation: Humans care—emotions and goals give direction (safety, fairness, identity). AI has no feelings or aims. It just optimizes predictions.
- Causality: Humans reason about causes (“X leads to Y”) and imagine “what if” scenarios. AI leans on correlations in text, which can be misleading.
- Metacognition: Humans can notice uncertainty, say “I don’t know,” and double-check. AI doesn’t have an inner “uncertainty meter.” It tends to answer confidently, even when it’s guessing (“hallucinating”).
- Value: Human judgments reflect values, stakes, and accountability (your choices matter to real people). AI outputs are probability-based word predictions—no intrinsic values or responsibility.
Why is this important? Because AI can give fluent, confident answers that feel right. People often equate smooth language and confidence with credibility. That creates an “illusion of knowing”—a persuasive answer without the hard work of evaluating evidence.
What is “Epistemia”?
Epistemia is the name the authors give to a new problem: when “linguistic plausibility” (what sounds right) replaces “epistemic evaluation” (careful checking of what’s true and justified). In Epistemia:
- Answers arrive fully formed and polished.
- The thinking and checking steps are hidden or skipped.
- Users feel like they “know,” even if no one actually did the work of judging evidence.
This problem doesn’t disappear if the AI is often accurate. The core issue is that the process of judgment—questioning, verifying, revising—is being replaced by quick acceptance of well-written answers.
What does this mean for the future?
The authors suggest three simple directions to reduce harm and strengthen human judgment:
- Better evaluation: Don’t just check if AI sounds human. Assess whether it is grounded in evidence: show sources, uncertainty, and reasoning steps. Make it easy to see when an answer is speculative.
- Smarter governance: Rules should focus on epistemic integrity (how claims are verified and corrected), not only on polite behavior or surface safety. Systems should be accountable when they present unverified claims as facts.
- Epistemic literacy: Teach people how AI really works (pattern completion, not belief) and how to spot the difference between a fluent answer and a well-supported one. Move beyond “critical thinking” buzzwords to practical habits: compare sources, look for evidence, tolerate uncertainty, and ask “How do we know?”
In short, the paper says: AI is great at producing language, but it does not “know” like humans do. As AI becomes more convincing, we must protect the human practices of judging, verifying, and taking responsibility for what we claim to know.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
The paper advances a conceptual argument but leaves multiple empirical, formal, and governance questions unresolved. Future work could address the following gaps:
- Formalize the “text generation as a walk on a graph” claim: specify the state space (tokens vs. contexts), prove or refute Markov assumptions under self-attention, characterize mixing times, recurrence, and concentration phenomena in transformer decoding, and test whether any learned invariants function as epistemic attractors.
- Quantify when scale changes qualitative behavior: empirically test whether increasing model size, context window, and training data produce measurable gains in epistemic properties (e.g., factuality, causal consistency, uncertainty calibration) beyond surface fluency.
- Operationalize “epistemic evaluation”: define measurable criteria (e.g., evidence-backed assertions, counterfactual robustness, causal sufficiency, uncertainty expression, provenance traceability) and build standardized benchmarks that assess judgments along these dimensions rather than task accuracy alone.
- Build a “fault-lines benchmark suite”: create tasks explicitly targeting the seven fault lines (grounding, parsing, experience, motivation, causality, metacognition, value), with clear scoring protocols and out-of-distribution variants to assess brittleness.
- Test the “no metacognition” claim rigorously: evaluate abstention, selective prediction, and uncertainty quantification methods (e.g., log-prob calibration, Bayesian wrappers, ensemble variance, verification chains) across domains and model families; determine whether any approach provides reliable, instance-level confidence tied to factuality.
- Measure the illusion-of-veracity effect sizes: run controlled user studies quantifying how fluency and expressed confidence in LLM outputs drive perceived credibility, trust, and adoption across languages, cultures, expertise levels, and stakes; identify conditions where the illusion amplifies or attenuates.
- Compare generation vs. filtering regimes: experimentally assess how synthesized single answers versus ranked document lists affect users’ verification behavior, belief formation, memory retention, and downstream decisions.
- Investigate UI/UX mitigations for Epistemia: test interventions (evidence citations with verifiability scores, uncertainty overlays, multi-source contrastive summaries, provenance cards, “agree/disagree/withhold” prompts) for their ability to restore evaluation rather than consumption.
- Quantify tokenization-induced semantic errors: measure real-world rates and impact of subword segmentation artifacts across languages (e.g., Chinese radicals, agglutinative morphology), domains, and noisy inputs; evaluate semantics-aware tokenizers or adaptive segmentation.
- Examine multimodality and embodiment as grounding: empirically test whether sensorimotor data, interactive environments, or embodied agents produce measurable gains in intuitive physics, theory-of-mind, and situational parsing beyond image/audio embeddings.
- Evaluate retrieval-augmented generation (RAG): determine when RAG genuinely improves epistemic grounding (correctness, source fidelity, citation integrity) and when it merely increases plausibility; quantify hallucination substitution with “plausible but unsupported” citations.
- Assess tool-use and external verifiers: measure whether programmatic tools (calculation, database queries, fact-check APIs) introduce an internal locus of evaluation (e.g., claim–evidence graphs, truth maintenance) or just decorate fluent outputs.
- Study causal reasoning capacity: develop benchmarks that separate correlation from causation (interventions, counterfactuals, invariance tests) and test whether neuro-symbolic approaches or causal representation learning improve causal judgments.
- Define and measure a “Metacognitive Integrity Index”: combine abstention behavior, calibration curves, selective accuracy, and cost-sensitive decision policies; evaluate trade-offs between helpfulness and epistemic humility.
- Operationalize the Epistemia construct: develop a scalable “Epistemia Index” for platforms capturing the degree to which users accept answers without independent evaluation (e.g., click-through to sources, time-on-evidence, revision frequency, error correction).
- Analyze RLHF/constitutional alignment side effects: quantify introduced political/moral biases, miscalibrated confidence, and value distortions; design audits that separate helpfulness gains from epistemic harms.
- Specify governance standards beyond behavioral alignment: propose concrete requirements (evidence provenance, uncertainty disclosures, abstention thresholds, audit trails, error reporting, red-teaming for epistemic risks) and test their efficacy in production systems.
- Address value-sensitive judgment in pluralistic contexts: develop methods for representing contested values, stakeholder diversity, and context-sensitive stakes; evaluate whether models can present value-aware trade-offs without prescriptive bias.
- Study human–AI hybrid workflows: identify task designs that preserve accountable human judgment (e.g., staged adjudication, mandatory evidence review, disagreement triggers); measure impacts on accuracy, speed, and responsibility.
- Longitudinal societal impact of Epistemia: track changes in public epistemic practices (verification habits, rumor propagation, institutional trust) as generative systems proliferate; identify causal pathways and policy levers.
- Domain-specific epistemic risk maps: characterize where plausibility most dangerously substitutes for evaluation (medicine, law, finance, education), and set domain-tailored thresholds for abstention, evidence, and oversight.
- Investigate cross-cultural variability: test whether fluency and confidence heuristics, sarcasm detection, and value interpretations vary by language, culture, and media ecosystem; adapt literacy and governance accordingly.
- Develop truth-maintenance architectures: prototype claim–evidence graphs, formal semantics layers, and consistency checkers integrated with generation; measure reductions in hallucination and increased defendability of outputs.
- Clarify falsifiability of core claims: specify empirical predictions (e.g., “LLMs cannot track counterfactual invariance without external causal models”), design experiments, and pre-register analyses to move from perspective to testable theory.
Practical Applications
Immediate Applications
Below are practical, deployable applications that leverage the paper’s insights about “epistemic fault lines” and Epistemia. Each item notes relevant sectors, potential tools/workflows, and key assumptions or dependencies.
- Epistemia-aware product design patterns
- Sectors: software, education, healthcare, finance, legal, journalism
- What: UI/UX features that counter fluency-confidence illusions, including “Show Sources,” “Confidence/Uncertainty Indicators,” “Don’t Know” default buttons, and “Evidence-first” mode that presents sources before synthesized answers.
- Tools/workflows: interface components for citation/provenance panels, confidence sliders, abstain/ask-for-more-evidence flows, and source-quality badges.
- Assumptions/dependencies: high-quality retrieval corpora; vendor support for provenance APIs; user acceptance of additional friction.
- Epistemic Risk Assessment (ERA) checklist for AI deployments
- Sectors: enterprise IT, healthcare, finance, public sector, HR
- What: A standardized pre-deployment checklist that maps failure modes to the seven fault lines (Grounding, Parsing, Experience, Motivation, Causality, Metacognition, Value) and gates use in judgment-critical contexts.
- Tools/workflows: risk-tiering, decision-type catalogs (advisory vs. determinations), human sign-off requirements, incident logging.
- Assumptions/dependencies: organizational governance maturity; role clarity; buy-in from compliance/QA.
- Epistemic Faultline Stress Tests
- Sectors: model vendors, AI evaluation labs, academia
- What: A test suite that probes each fault line (e.g., sarcasm and multimodal cues for Grounding; negation/tokenization edge cases for Parsing; intuitive physics and theory of mind tasks for Experience; causal counterfactuals for Causality; abstention calibration for Metacognition; domain value conflicts for Value).
- Tools/workflows: benchmark datasets; automated evaluation harnesses; red-team playbooks targeting spurious correlations and confidence miscalibration.
- Assumptions/dependencies: access to testbeds; accepted scoring protocols; reproducibility infrastructure.
- RAG-by-default policies for high-stakes workflows
- Sectors: healthcare (clinical support), finance (risk/compliance), legal (research), journalism (fact-checking)
- What: Require retrieval-augmented generation on judgment-sensitive tasks; disallow free-form generation without source anchoring; enforce source freshness and authority thresholds.
- Tools/workflows: curated corpora; authority ranking; document provenance; “no-source, no-answer” gating.
- Assumptions/dependencies: licensed databases; robust retrieval quality; domain ontology alignment.
- Confidence calibration and abstention tuning
- Sectors: software, safety-critical applications
- What: Configure decoding and ensemble/self-consistency checks to estimate uncertainty and trigger abstentions (“I don’t know”), with escalation to human review.
- Tools/workflows: temperature/top‑p controls; variance across sampled outputs; calibration curves; abstain thresholds; deferral workflows.
- Assumptions/dependencies: reliable uncertainty proxies; latency budget; clear handoff channels.
- Claims provenance logging API
- Sectors: enterprise AI platforms, newsrooms, research tools
- What: Standardized logging of prompt, model version, decoding parameters, sources cited, and timestamps for auditability and reproducibility.
- Tools/workflows: provenance schema; append-only audit ledger; exportable “evidence bundles.”
- Assumptions/dependencies: privacy/security policies; storage costs; interop standards (e.g., W3C provenance).
- Human-in-the-loop triage for judgment-critical decisions
- Sectors: healthcare, finance, legal, HR
- What: Two-tier pipelines where generative answers are treated as drafts; human validators check causality, stakes, and values before action.
- Tools/workflows: routing rules by risk tier; reviewer dashboards; exception handling; feedback loops to improve prompts and retrieval.
- Assumptions/dependencies: staffing capacity; measurable SLAs; clear accountability.
- Epistemic literacy micro-training
- Sectors: education, professional training (clinicians, journalists, analysts), public agencies
- What: Bite-sized curricula on Epistemia, fluency and confidence heuristics, source evaluation, uncertainty recognition, and “pause–verify–triangulate” habits.
- Tools/workflows: scenario-based modules; checklists; interactive case studies with AI outputs and adversarial examples.
- Assumptions/dependencies: institutional adoption; baseline digital literacy; localized examples.
- Sarcasm/emotion/context capture in customer operations
- Sectors: customer service, healthcare teletriage, law enforcement intake
- What: Explicitly collect non-textual cues (tone, timing, context metadata) to reduce Grounding/Parsing errors when LLMs assist, with human verification of affect/intent.
- Tools/workflows: structured context forms; multimodal recording; escalation flags for ambiguity.
- Assumptions/dependencies: consent and privacy compliance; secure storage; multimodal preprocessing quality.
- Organization-wide AI-use policies specifying judgment boundaries
- Sectors: enterprise, public sector
- What: Define categories where generative outputs cannot be final (e.g., diagnosis, legal determinations, credit decisions); require disclosure when AI assistance shapes judgments.
- Tools/workflows: policy catalogs; decision registers; disclosure prompts; periodic audits.
- Assumptions/dependencies: regulatory alignment; leadership support; enforcement mechanisms.
- Personal AI-interaction checklists
- Sectors: daily life
- What: Simple habits for consumers: prefer search/filtering over generation for high-stakes decisions; demand sources; compare at least two independent references; watch for confident fluency without evidence.
- Tools/workflows: printable/phone-friendly checklists; browser extensions that nudge verification.
- Assumptions/dependencies: user willingness; accessible tools; clear messaging.
Long-Term Applications
These applications require additional research, scaling, standardization, or technological advances to address deeper epistemic gaps identified in the paper.
- Epistemic agent architectures (belief, uncertainty, metacognition)
- Sectors: foundational AI research, software
- What: Models with explicit belief representations, uncertainty tracking, ability to suspend judgment, and mechanisms for revising/defending claims.
- Tools/workflows: persistent memory stores; belief graphs; confidence calibration modules; abstention policies.
- Assumptions/dependencies: new learning paradigms; benchmarks for metacognition; compute and data for belief maintenance.
- Causality-aware generative systems
- Sectors: healthcare, policy, economics, engineering
- What: Integrate structural causal models (SCM), program synthesis, and simulation with LLMs to reason about interventions, counterfactuals, and mechanisms.
- Tools/workflows: causal inference engines; hybrid pipelines (LLM + SCM + RAG); audit trails for causal assumptions.
- Assumptions/dependencies: high-quality causal datasets; domain ontologies; standardized representation of causal claims.
- Grounded multimodal/embodied agents
- Sectors: robotics, AR/VR, autonomous systems, assistive tech
- What: Agents with sensorimotor grounding to reduce Grounding/Parsing faults by learning from embodied interaction rather than text-only corpora.
- Tools/workflows: real-time perception stacks; simulation-to-real training; safety monitors; alignment with human-provided affordances.
- Assumptions/dependencies: safe deployment environments; robust multimodal learning; better transfer from simulation.
- Machine metacognition and abstention standards
- Sectors: safety-critical software, regulation
- What: Formal protocols for confidence estimation, “refusal-to-answer” capability, and reporting of epistemic stakes and uncertainties.
- Tools/workflows: standardized uncertainty metrics; certification tests; interoperable “don’t-know” APIs.
- Assumptions/dependencies: consensus on metrics; regulator acceptance; vendor compliance.
- Epistemic governance and certification regimes
- Sectors: policy/regulation, industry consortia
- What: Certifications that require evidence grounding, provenance logging, abstention capability, and stress-test performance across the seven fault lines.
- Tools/workflows: audit frameworks; compliance dashboards; third-party testing bodies.
- Assumptions/dependencies: legal mandates; international harmonization; funding for oversight.
- Web-scale verifiable claim/provenance infrastructure
- Sectors: media, research, public information platforms
- What: Machine-readable provenance standards and distributed ledgers/registries for claims, sources, and revisions (“Verifiable Claim Graph”).
- Tools/workflows: content signing; cross-platform provenance exchange; trust signals in user interfaces.
- Assumptions/dependencies: standards bodies (e.g., W3C); publisher adoption; privacy-preserving design.
- Epistemia Index and cross-fault benchmarks
- Sectors: academia, model evaluation, procurement
- What: Composite metrics that quantify exposure to Epistemia across Grounding/Parsing/Experience/Motivation/Causality/Metacognition/Value dimensions.
- Tools/workflows: public leaderboards; procurement scorecards; longitudinal monitoring.
- Assumptions/dependencies: community consensus; reproducible testbeds; avoidance of gaming.
- Value-sensitive AI and normative risk frameworks
- Sectors: healthcare, education, justice, HR
- What: Systems that explicitly encode stakeholder values, ethical constraints, and real-world stakes into generation and decision-support.
- Tools/workflows: participatory value elicitation; constraint learning; trade-off transparency modules.
- Assumptions/dependencies: societal deliberation; domain-specific ethics guidelines; monitoring for unintended biases.
- Deliberation-scaffolded interfaces
- Sectors: productivity, education, civic tech
- What: Interaction designs that prompt users to articulate goals, alternatives, and reasons, converting “answer consumption” into “judgment formation.”
- Tools/workflows: structured prompts; reasoning canvases; comparison/triangulation views.
- Assumptions/dependencies: user adoption; minimal friction; integration with existing tools.
- Sector-specific co-pilots with epistemic guarantees
- Sectors: healthcare (clinical evidence co-pilot), legal (authority-first research), finance (reg-compliant advisory), energy (grid operations support)
- What: Domain co-pilots that cannot finalize recommendations without authoritative sources, causal justification, and uncertainty disclosure.
- Tools/workflows: domain-specific corpora; authority hierarchies; “no auto-accept” guardrails; audit logs.
- Assumptions/dependencies: data licensing; expert curation; continuous validation.
- Societal-scale epistemic literacy
- Sectors: K–12, higher education, public communication
- What: Curricular and media initiatives that teach the difference between linguistic plausibility and justified belief, and how to work with generative systems without outsourcing judgment.
- Tools/workflows: standards-aligned curricula; teacher training; public campaigns.
- Assumptions/dependencies: education policy support; culturally adapted materials; sustained funding.
These applications translate the paper’s core insights—LLMs as stochastic language continuers, seven epistemic fault lines, and the Epistemia condition—into concrete products, workflows, evaluation regimes, and governance mechanisms that preserve accountable human judgment while harnessing generative AI’s strengths.
Glossary
- Anisotropic: Exhibiting direction-dependent properties in distributions or structures. "Empirical language distributions are heavy-tailed and structurally anisotropic"
- Attention-weighted aggregation: Mechanism in transformers that combines token representations using learned attention weights. "Each layer performs linear transformations, attention-weighted aggregation, and nonlinear mappings"
- Automation bias: The tendency to over-trust automated systems or recommendations. "It is not reducible to automation bias---the tendency to over-trust automated recommendations"
- Calculus ratiocinator: Leibniz’s proposed universal symbolic language for reasoning via computation. "Leibnizâs proposal of a calculus ratiocinator, a universal symbolic language that could in principle resolve disputes through computation"
- Causal models: Structured representations that encode cause-and-effect relationships used for reasoning and explanation. "Humans reason using causal models, counterfactuals, and principled evaluation"
- Confidence heuristic: Inferring credibility or correctness from expressed confidence when better cues are absent. "scholars have proposed a âconfidence heuristicâ, whereby, in the absence of stronger diagnostic cues, expressed confidence substitutes for knowledge, competence, and correctness"
- Conditional transition probabilities: Learned probabilities of moving from one token to another given the current context. "edges encode conditional transition probabilities learned from data"
- Counterfactuals: Hypothetical alternatives to past events used for reasoning about causality and outcomes. "Humans reason using causal models, counterfactuals, and principled evaluation"
- Embeddings: High-dimensional vector representations encoding statistical relationships among tokens or sequences. "statistical pattern extraction in high-dimensional embedding spaces"
- Entropy: A measure of uncertainty in the token distribution used to modulate generation variability. "Greedy decoding, temperature scaling, top- and nucleus sampling modulate the entropy and effective support of "
- Epistemia: Structural condition where linguistic plausibility substitutes for epistemic evaluation. "We define Epistemia \cite{loru2025judgment} as the structural condition in which linguistic plausibility substitutes for epistemic evaluation."
- Epistemic pipeline: A staged process outlining how judgments are formed and evaluated. "The human and LLM epistemic pipelines, each organized into seven corresponding stages."
- Epistemological fault lines: Structural divergences between human and machine judgment processes. "The previous section highlights seven epistemological fault lines that separate human judgment from LLM judgment"
- Ergodic process: A stochastic process where long-run behavior reflects statistical properties rather than convergence to truth. "Text generation is therefore an ergodic process under statistical constraints"
- External memory modules: Auxiliary components that store or retrieve information outside the core model. "and external memory modules"
- Forced confidence: The tendency of generative systems to present outputs with certainty without internal uncertainty tracking. "forced confidence and hallucination replace metacognition"
- Greedy decoding: A generation strategy that selects the highest-probability token at each step. "Greedy decoding, temperature scaling, top- and nucleus sampling modulate the entropy"
- Hallucinations: Ungrounded or incorrect outputs produced by generative models despite fluent presentation. "so-called âhallucinationsâ are not anomalous failure modes of an otherwise epistemic system."
- Heavy-tailed distributions: Probability distributions with large tails, indicating many rare events with non-negligible probabilities. "Empirical language distributions are heavy-tailed and structurally anisotropic"
- High-dimensional state space: A large, multi-parameter space in which token sequences evolve during generation. "stochastic process evolving on a discrete, high-dimensional state space."
- Imitation game: Turing’s test for machine intelligence based on indistinguishability from human behavior. "what he called the imitation game---now widely known as the Turing Test"
- Markov process: A stochastic process where the next state depends only on the current context; time-inhomogeneous when transition rules vary over time. "This defines a time-inhomogeneous Markov process over "
- Metacognition: Monitoring and regulation of one’s own cognitive processes, including uncertainty and error detection. "LLMs lack metacognition entirely."
- Next-token distribution: The probability distribution over possible next tokens given the current context. "An LLMâs âjudgmentâ is simply the next-token distribution conditioned on context."
- Nucleus sampling: A decoding technique that samples from the smallest set of tokens whose cumulative probability exceeds a threshold. "top- and nucleus sampling"
- Probability measure: A function assigning probabilities to events or tokens under given conditions. "instantiates a probability measure over "
- Proprioception: The sense of body position and movement used in human perception and judgment. "Vision, audition, proprioception \cite{gibson2014ecological}, and emotional expressions"
- Random walks on graphs: Stochastic transitions across nodes in a graph according to learned probabilities. "consistent with classical formulations of random walks on graphs"
- Reinforcement learning with human feedback (RLHF): Training method that aligns model outputs to human preferences via reward signals. "reinforcement learning with human feedback (RLHF)"
- Retrieval-augmented generation (RAG): Technique that grounds generative outputs by retrieving relevant documents during generation. "retrieval-augmented generation (RAG)"
- Scaling laws: Empirical relationships showing how model performance changes with data, parameters, and compute. "When combined with massive training corpora and scaling laws this architecture yields systems that appear fluent, versatile, and adaptable across domains"
- Self-attention layers: Transformer components that relate each token to others in the sequence to compute contextualized representations. "stacked self-attention layers that propagate and remix information across positions in the input"
- Spurious associations: Correlations that do not reflect true causal relationships and can mislead models. "making them especially vulnerable to spurious associations"
- Stochastic trajectory: A random path through the token space resulting from probabilistic sampling. "Each output is therefore the realization of a stochastic trajectory"
- Subword tokenization: Segmenting text into smaller units (subwords) to handle rare or complex words. "Because LLMs rely on subword tokenization"
- Temperature scaling: Adjusting distribution sharpness to control randomness in token sampling. "Greedy decoding, temperature scaling, top- and nucleus sampling modulate the entropy"
- Tokenization: Converting raw text into discrete tokens for model processing. "the analogous stage is tokenization and text preprocessing"
- Top-k sampling: Decoding method that samples from the k most probable tokens at each step. "Greedy decoding, temperature scaling, top- and nucleus sampling"
- Truth conditions: Criteria under which statements are true in relation to the world. "They do not track truth conditions or causal structure"
- Value-sensitive judgment: Decisions informed by values, norms, stakes, and accountability. "value-sensitive judgment"
Collections
Sign up for free to add this paper to one or more collections.