Real2Edit2Real: Generating Robotic Demonstrations via a 3D Control Interface
Abstract: Recent progress in robot learning has been driven by large-scale datasets and powerful visuomotor policy architectures, yet policy robustness remains limited by the substantial cost of collecting diverse demonstrations, particularly for spatial generalization in manipulation tasks. To reduce repetitive data collection, we present Real2Edit2Real, a framework that generates new demonstrations by bridging 3D editability with 2D visual data through a 3D control interface. Our approach first reconstructs scene geometry from multi-view RGB observations with a metric-scale 3D reconstruction model. Based on the reconstructed geometry, we perform depth-reliable 3D editing on point clouds to generate new manipulation trajectories while geometrically correcting the robot poses to recover physically consistent depth, which serves as a reliable condition for synthesizing new demonstrations. Finally, we propose a multi-conditional video generation model guided by depth as the primary control signal, together with action, edge, and ray maps, to synthesize spatially augmented multi-view manipulation videos. Experiments on four real-world manipulation tasks demonstrate that policies trained on data generated from only 1-5 source demonstrations can match or outperform those trained on 50 real-world demonstrations, improving data efficiency by up to 10-50x. Moreover, experimental results on height and texture editing demonstrate the framework's flexibility and extensibility, indicating its potential to serve as a unified data generation framework.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a system called Real2Edit2Real that makes it much faster and cheaper to create training videos for robots. Instead of recording hundreds of new examples, it takes just a few real videos of a robot doing a task and automatically creates many new, realistic, multi-camera videos showing the same task with objects in different places. These “fake” videos look real and keep the robot’s movements physically correct, so they can be used to train robot control models effectively.
What questions did the researchers ask?
The paper focuses on a few simple questions:
- How can we turn a small number of real robot demonstrations into many high-quality, realistic training videos?
- How can we keep the robot’s motion and object interactions physically correct while changing where objects are placed?
- How can we make sure the generated videos look good from multiple cameras at once?
- Will robots trained on these generated videos perform as well as (or better than) robots trained on lots of real videos?
How did they do it? (Methods)
The team built a three-part system. Think of it like turning a few “seed” videos into a lot of new, believable videos by using 3D information as a control signal.
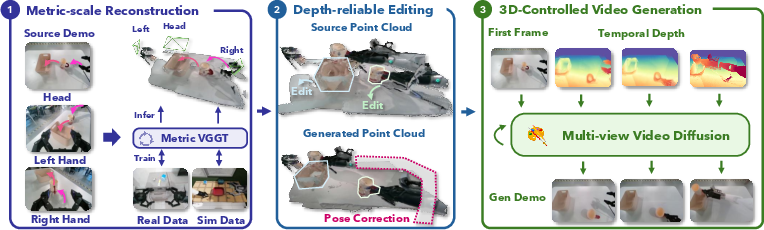
1) Reconstructing the scene in 3D (Metric-scale geometry reconstruction)
- Idea: From a few camera views (like the robot’s head and wrist cameras), the system estimates the 3D shape of the scene—where the robot, table, and objects are, and how far everything is from the cameras.
- Key terms explained:
- Depth map: An image where each pixel tells you how far that point is from the camera (like a grayscale “distance” picture).
- Point cloud: A 3D set of dots that represent surfaces of objects (like a “dot sculpture” of the scene).
- Camera pose: Where a camera is and where it’s pointing.
- How they improved accuracy: They trained the 3D model using a mix of simulated data (perfect, noise-free) and real data (messy but true to real sizes). Simulation helps with precise camera positions; real data helps match real-world scale.
2) Editing the 3D scene safely (Depth-reliable spatial editing)
- Idea: Change where objects are placed and adjust the robot’s trajectory accordingly—without breaking physics.
- Process in simple steps:
- Split the original demonstration into “moving” parts (robot moving freely) and “interaction” parts (robot touching or using objects).
- Move the object to a new location and update the robot’s hand (end-effector) position to match so the interaction still makes sense.
- Plan safe movements for the robot to reach the new spot (motion planning is like plotting a careful route around obstacles).
- Fix the robot’s arm joints to match the new hand position correctly (inverse kinematics is like figuring out how to bend elbows and shoulders so your hand reaches a target).
- Render new depth maps that match the edited 3D scene from each camera.
- Why this matters: These corrected depth maps become a “control knob” for generating realistic videos that match the new placements and motions.
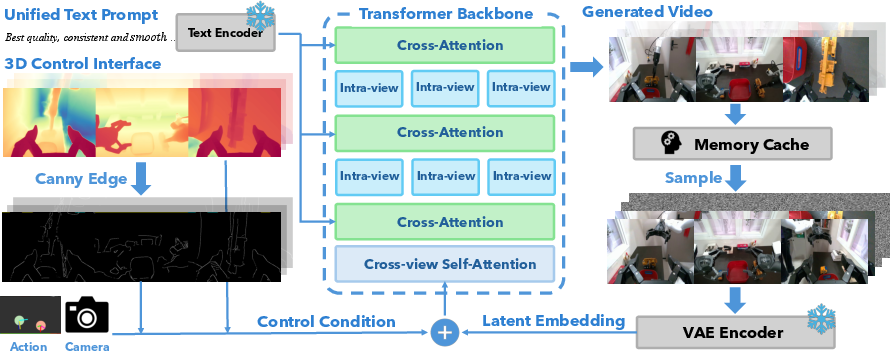
3) Generating videos guided by 3D signals (3D-controlled video generation)
- Idea: Starting from the first real frame, the system uses the edited depth maps to guide a video-generation model to produce multi-view videos that look real and stay consistent across cameras.
- Extra guidance used:
- Edges: Sharp outlines of objects (helps keep boundaries crisp).
- Actions: The robot’s intended movements (keeps motion aligned with behavior).
- Ray maps: Information that ties views together (helps all cameras agree on what they see).
- Special design:
- Dual attention: One attention focuses inside each camera view, and another connects information across cameras. This helps the system keep all views consistent while staying efficient.
- Smooth object relocation: Instead of “teleporting” objects between frames, it gently slides and rotates them over time, so the generator sees a natural motion sequence.
What did they find and why does it matter?
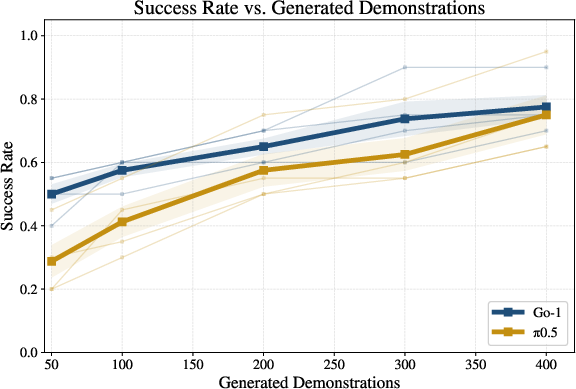
- Big data efficiency gains: Using only 1–5 real demonstrations to generate 200 new videos led to robot policies that matched or beat policies trained on 50 real demonstrations. That’s up to 10–50× less real data needed.
- Works on multiple tasks: The system was tested on four real robot tasks—placing a mug into a basket, pouring water, lifting a box with two arms, and scanning a barcode while holding both the item and scanner. Success rates were high even when objects were placed randomly.
- Flexible editing:
- Height changes: The robot could adapt to objects on a higher platform, not just a table, when videos were generated for both heights.
- Texture changes: Training with generated videos that included different table colors and textures made the policy more robust to visual changes.
- Ablation studies: Removing key parts (like robot pose correction or smooth relocation) hurt video quality and robot performance. This shows each module is necessary.
Why it matters: Training robots often needs lots of data collected by people, which is slow and expensive. This method cuts the cost while keeping realism and physical correctness, making robot learning much more practical.
Why is this important? (Implications)
- Faster, cheaper training: Teams can build strong robot skills without collecting huge datasets in the real world.
- Better generalization: Robots trained with these generated videos handle different object placements, heights, and backgrounds more reliably.
- Unified framework: By using depth as the “3D control interface,” the same system can edit scenes, adjust motions, and generate multi-camera videos in a consistent way.
- Real-world impact: This reduces the gap between simulation and reality and helps vision-language-action (VLA) models learn robust manipulation skills that work in everyday settings.
- Future possibilities: The approach could be extended to more complex tasks, different robot bodies, and richer environments, further scaling up robot learning.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single consolidated list of what remains missing, uncertain, or unexplored in the paper, phrased to enable concrete follow-up by future researchers.
- Generalization across embodiments and camera setups: The framework is only evaluated on a single humanoid robot with three fixed RGB cameras (head and two wrists). It remains unknown how Real2Edit2Real performs with different robots (e.g., mobile bases, industrial arms, various grippers), alternative camera topologies (single wrist camera, overhead camera, moving cameras), or different numbers of views.
- Reliance on large-scale fine-tuning for geometry: Metric-VGGT is fine-tuned using 100K real robot frames and 40K simulated frames, which partially undermines the claim of reducing data collection burden. A key open question is whether the framework remains effective with substantially fewer (or no) real depth frames, or with domain-adaptive/self-supervised geometry learning that minimizes lab-specific data requirements.
- Lack of quantitative geometry metrics: There is no quantitative evaluation of reconstruction accuracy (e.g., camera pose error, depth MAE/RMSE, point cloud completeness/precision) versus baselines (VGGT, DUSt3R/MASt3R). A standardized geometry benchmark in robotic scenes is needed to validate the “metric-scale” claim.
- Multi-view consistency not measured: The dual-attention video generator is motivated by cross-view consistency, but no quantitative metric (e.g., epipolar alignment, cross-view reprojection error, disparity/consistency scores) is reported. A concrete evaluation protocol for multi-view coherence is needed.
- Physical interaction fidelity remains unvalidated: The video generation pipeline is conditioned on depth/action but lacks explicit physics constraints. It is unclear whether generated interactions are contact-consistent (no interpenetration, realistic grasp closure) or dynamics-aware. Experiments on force-sensitive tasks (insertion, tool use), deformables (cloth, cables), and liquids (beyond visual pouring) are needed, potentially with contact-aware or differentiable physics conditioning.
- Collision-safe trajectory synthesis not characterized: Motion segments are planned with CUROBO after object relocation, but planning success rates, collision rates, and clearance margins are not reported. A systematic analysis of planning reliability under randomized placements and clutter is required.
- Distribution shift due to “smooth object relocation”: Objects are moved in the video pre-roll to achieve target placement. It is unknown whether training on videos where objects move before manipulation induces policies that expect object motion at test time. A comparison to static-relocation editing (no pre-roll movement) and a study of downstream behavioral bias are needed.
- Robustness of depth control under difficult materials: The pipeline does not evaluate cases with transparent, specular, or textureless objects/surfaces where depth and reconstruction are known to fail. Experiments quantifying failure rates and the impact on generated videos/policies are needed, along with robustness strategies (e.g., uncertainty-aware conditioning, alternative 3D cues).
- Clutter and occlusion tolerance: All tasks are in a sparsely cluttered, small tabletop workspace. Performance in dense clutter, heavy occlusions, multi-object scenes, and narrow clearances remains unexplored; realistic kitchen/warehouse settings should be evaluated.
- Novel object category generalization: The method edits point clouds from source demos, implicitly tying generations to the same objects. It is unclear how to generalize to unseen object categories without assets. A pipeline for incorporating few-shot/new-object scans (or generative object priors) and measuring zero-/few-shot generalization is needed.
- Compute and scalability trade-offs: Generation takes ~48.6 seconds per 20-second episode on 8×H100 GPUs. A cost–benefit analysis comparing compute-time and energy versus real data collection, and experiments with commodity GPUs or distilled/lightweight generators, are missing.
- Absence of automated quality control: The paper notes unusable demonstrations without smooth relocation but provides no automated filtering/scoring. A practical filter (e.g., action–depth consistency checks, realism scores like FVD/KID, cross-view alignment thresholds) to reject low-quality generations is needed.
- No head-to-head baselines on identical tasks: Claims against MimicGen/DemoGen/Real2Render2Real/RoboSplat are not substantiated with controlled comparisons on the same tasks/policies/datasets. A standardized Gen2Real benchmark with matched training budgets and evaluation protocols is needed.
- Policy diversity and architecture sensitivity: Only Go-1 and π₀.₅ are evaluated. It is unknown how Real2Edit2Real impacts other dominant policy types (e.g., Diffusion Policy, 3D policies/DP3, state-conditioned controllers). Cross-policy experiments and sensitivity analyses are needed.
- Camera calibration drift and online adaptation: Camera pose supervision relies on simulated accuracy; real setups can drift. Methods for online self-calibration, temporal drift handling, and robustness to kinematic inaccuracies should be explored.
- Robot pose correction accuracy not quantified: The URDF-based arm re-rendering is shown qualitatively; no metrics (joint angle error, link alignment error, reprojection error versus real arm depth) are reported. A quantitative validation of pose correction is required.
- Video generation failure modes uncharacterized: Temporal artifacts (flicker), identity drift (object/robot appearance changes), and motion misalignment are not measured. Reporting FVD/LPIPS/C-VFID, temporal coherence metrics, and failure case analyses will aid reliability assessment.
- Fewer/moving view robustness: The generator assumes fixed three views. Performance with fewer views, moving/pan-tilt cameras, or cameras with varying intrinsics/extrinsics over time is unknown; experiments under these perturbations are needed.
- Dynamics and haptics omission: The framework conditions on kinematics but not contact forces or tactile feedback. Assess whether policies trained on kinematics-only videos can handle dynamic contacts; explore conditioning on force/torque or tactile signals.
- Limited coverage of height/texture editing: Height generalization is shown for one platform and texture edits for a small set. A systematic sweep over continuous height ranges, diverse materials/patterns, and lighting conditions is needed to map robustness boundaries.
- Pipeline success rates and failure taxonomy: The proportion of generated episodes that pass all stages (reconstruction, editing, planning, generation) is not reported; nor is a taxonomy of failure modes. Publishing stage-wise success/failure stats and diagnostic tools would make the pipeline actionable.
- Cross-domain portability: Results are tied to Agibot Genie G1 and specific lab settings. Experiments across different labs, robots, camera models, and lighting environments, plus domain adaptation recipes, are missing.
- Online/closed-loop data generation: The method is offline. Investigate on-the-fly generation integrated with training (e.g., policy-in-the-loop, active placement sampling), and whether interactive generation improves sample efficiency further.
- Action-space alignment across policies: The generator conditions on actions, but cross-embodiment/action-space mismatches (e.g., 6D end-effector vs 7-DoF joints) are not analyzed. Methods for action retargeting and robustness to action noise should be evaluated.
- Long-horizon, multi-stage tasks: Episodes are ~20 seconds and tasks are short-horizon. Scalability to extended sequences (tool chains, multi-step assembly) and maintenance of temporal consistency over minutes remain open.
- Non-rigid and precision tasks: Performance on deformable objects, small parts requiring high precision, and tasks with tight tolerances is unknown; targeted evaluations are required.
- Uncertainty-aware conditioning: Depth and camera pose are treated deterministically post-editing. Propagating and leveraging uncertainty (e.g., probabilistic depth, pose distributions) through video generation and into policy training is unexplored.
- Reproducibility and release: It is not stated whether code/models/datasets for Metric-VGGT fine-tuning, the editing pipeline, and the video generator are released. Clear release plans and standardized scripts would enable independent validation.
Practical Applications
Practical Applications Derived from Real2Edit2Real
Below are actionable, real-world applications that leverage the framework’s findings and innovations. They are grouped by deployment horizon and annotated with sectors, potential tools/products/workflows, and key assumptions or dependencies that affect feasibility.
Immediate Applications
- Industry (Robotics, Manufacturing, Logistics): Rapid dataset expansion for manipulation tasks
- Use case: Scale training data for pick-and-place, kitting, barcode scanning, pouring, dual-arm lifting in workcells and warehouses from 1–5 teleoperated demos.
- Tools/products/workflows: “Real2Edit2Real Data Engine” integrated with VLA training (e.g., Go-1, π₀.₅); pipeline includes metric-scale geometry reconstruction, depth-reliable 3D editing, multi-view video generation; motion planning via cuRobo; automated spatial augmentation (position/orientation sweeps).
- Assumptions/dependencies: Accurate URDF and camera intrinsics/extrinsics; sufficiently trained VGGT variant for geometry; initial demos must capture valid contact patterns; H100-class GPUs or cloud compute (≈48.6 s per 20 s episode in reported setup); task kinematics remain feasible under edited placements.
- Industry (Robotics Deployment/Systems Integration): Fast workspace adaptation via height and texture editing
- Use case: Pre-commissioning or on-site adaptation to new bench heights, shelves, or varying surface textures (table colors/patterns) without re-collecting large datasets.
- Tools/products/workflows: “Spatial Generalization Booster” that batch-generates episodes across height ranges and surface textures from a few seed demos; first-frame editing plus smooth object relocation to synthesize pre-manipulation transitions.
- Assumptions/dependencies: Valid camera re-projection under relocations; basic dynamics unaffected by surface changes; the policy can leverage visual cues encoded in depth and edges.
- Academia (Robot Learning Research): Low-cost, multi-view demonstration generation for policy benchmarks
- Use case: Create controlled spatial-generalization benchmarks; ablate depth vs. edge/action/ray conditioning; compare 2D policy training versus point-cloud baselines.
- Tools/products/workflows: Open-source pipeline for “multi-view, depth-guided demonstration synthesis” with reproducible training scripts; datasets for manip tasks across diverse placements.
- Assumptions/dependencies: Access to multi-view RGB data (3 cameras are demonstrated); correctness of camera pose estimation; reproducibility of VGGT fine-tuning on robotic domains.
- Software (ML Tooling for Robotics): 3D-controlled video authoring for robotic demonstrations
- Use case: Author and edit robot demos with physically plausible kinematics (robot pose correction), multi-view consistency, and realistic appearance; export paired observations/actions for training.
- Tools/products/workflows: “3D-Controlled Video Editor” plugin that ingests source demos, applies depth-conditioned generation with dual-attention (intra-/cross-view), and exports training-ready datasets.
- Assumptions/dependencies: Depth serves as a reliable interface; generator trained on relevant domain data; labeling alignment maintained for actions after edits.
- Quality Assurance (Robotics Safety & Robustness): Scenario fuzzing for policy evaluation
- Use case: Systematically stress-test trained policies by varying object placements, orientations, heights, and backgrounds; identify failure modes before deployment.
- Tools/products/workflows: “Policy Fuzzer for Manipulation” generating evaluation suites; automated scoring of success rates; comparison against real demos (e.g., 50 real vs. 200 generated).
- Assumptions/dependencies: Synthetic demonstrations reflect real observation distribution sufficiently; evaluation tasks don’t require high-fidelity physics beyond kinematics encoded via depth.
- Education (STEM/Robotics Courses & Clubs): Hands-on curriculum for data-efficient policy training
- Use case: Teach students geometry reconstruction, spatial editing, and depth-controlled video generation; run small-scale projects that train policies from minimal demos.
- Tools/products/workflows: Course kits with sample data, code notebooks, and lab assignments; “Campus Cloud” generation service to offset local compute constraints.
- Assumptions/dependencies: Simplified hardware (multi-view webcams) and accessible robots; cloud credits or shared GPU time.
- Daily Life (Consumer/Home Robotics Personalization): Few-shot personalization of household tasks
- Use case: Adapt a home robot to local kitchen/desk layouts for placing objects, pouring water, scanning items, or two-arm lifting, using minimal demo capture.
- Tools/products/workflows: “Home Setup Wizard” that guides users through capturing 1–5 demos and auto-generates diverse episodes to fine-tune the robot’s policy.
- Assumptions/dependencies: Consumer robot with multi-view RGB and known kinematics; safe-contact tasks; edge compute or cloud support; privacy-preserving pipeline for home data.
- Policy (Workforce Safety & Privacy): Reduce teleoperation burden and human exposure during data collection
- Use case: Minimize repeated teleop collection by generating large, varied datasets from few seeds; produce privacy-preserving datasets with synthetic backgrounds and controlled views.
- Tools/products/workflows: Organizational guidelines for synthetic data provenance; audit logs for edits; “synthetic-only” training regimes for non-sensitive tasks.
- Assumptions/dependencies: Acceptability of synthetic training under regulatory and compliance standards; documented data generation processes.
Long-Term Applications
- Healthcare (Assistive/Clinical Robotics): Task training adapted to ward/patient room variability
- Use case: Medication delivery, sample handling, instrument pickup; spatial variability across rooms and bed heights; few-shot site adaptation while minimizing data collection overhead.
- Tools/products/workflows: “Clinical Scenario Generator” tuned to hospital embodiments; height and texture domain edits; compliance-aware datasets.
- Assumptions/dependencies: Robust contact dynamics (beyond current kinematic depth control), safety certification, integration of tactile/force sensing.
- Cross-Embodiment Transfer (Multi-Robot Ecosystems): Generate demonstrations across different morphologies
- Use case: Automate dataset creation for robots with varying DoF and link lengths; share edited depth/action trajectories across fleets.
- Tools/products/workflows: “Embodiment Mapper” aligning end-effector trajectories via IK/FK across URDFs; re-rendered depth conditioned on robot-specific kinematics.
- Assumptions/dependencies: Reliable cross-robot IK; video generator robustness to new embodiments; broader training covering multiple robots.
- Synthetic Demonstration Cloud (Data-as-a-Service): Scalable generation API for enterprises
- Use case: On-demand generation of multi-view manipulation datasets with specified spatial distributions; SLA-backed data delivery for training and validation.
- Tools/products/workflows: Managed cloud service offering “Spatial Distributions as Configs,” automatic motion planning, dataset QA, and secure data handling.
- Assumptions/dependencies: Standardized URDFs/camera models; governance for synthetic data; cost-effective GPU provisioning; customer trust in synthetic-only training.
- On-Robot Online Augmentation (Edge Learning): Real-time generation for continual adaptation
- Use case: Robots generate/refresh datasets on-device to adapt to drifted conditions (layout changes, lighting, surfaces) and fine-tune policies continuously.
- Tools/products/workflows: Lightweight, on-device video generation models; streaming depth/action conditioning; “Nightly Adaptation Jobs” with scheduled fine-tuning.
- Assumptions/dependencies: Efficient edge models; thermal and power constraints; safe online learning policies; robust monitoring.
- Advanced Manipulation with Complex Physics (Deformables/Liquids): Extend beyond kinematic plausibility
- Use case: Cloth folding, cooking, cleaning, industrial assembly with flexible parts; accurate modeling of contact, friction, and fluid dynamics.
- Tools/products/workflows: Hybrid pipeline combining depth control with physics-aware simulators or learned dynamics models; “Physics-Grounded Generator.”
- Assumptions/dependencies: High-fidelity sensor fusion (force/tactile), domain-specific simulators, model validation against real outcomes.
- Energy & Industrial Plant Operations (Mobile Manipulation): Variable environments and safety-critical tasks
- Use case: Valve turning, panel operation, sample collection across large facilities with non-uniform layouts and surfaces.
- Tools/products/workflows: “Plant Variability Generator” for mobile platforms; multi-view configurations with moving cameras; integration with SLAM and mapping stacks.
- Assumptions/dependencies: Robust geometry reconstruction under motion and harsh conditions; expanded multi-view handling; regulatory safety compliance.
- Standards and Certification (Policy/Regulation): Synthetic data quality frameworks
- Use case: Establish accepted practices for synthetic demonstration generation, provenance tracking, bias audits, and safety validation.
- Tools/products/workflows: “Synthetic Data QMS” (Quality Management System) templates; third-party certification schemes; reporting dashboards.
- Assumptions/dependencies: Multi-stakeholder consensus; sector-specific guidelines; evidence correlating synthetic training with real-world performance.
- Finance & Operations (ROI Modeling for Robotics): Data efficiency analytics to inform procurement and deployment
- Use case: Quantify savings from 10–50× data efficiency improvements; scenario planning for training budgets and timelines.
- Tools/products/workflows: “Robotics Data ROI Calculator” integrating generation costs, training outcomes, and success rates; procurement playbooks.
- Assumptions/dependencies: Reliable performance predictors; organizational readiness to adopt synthetic pipelines.
- Multimodal Expansion (Audio/Tactile/Force Conditioning): Richer control interfaces for video generation
- Use case: Improve fidelity and policy transfer by conditioning on additional sensors; better grounding in contact-rich tasks.
- Tools/products/workflows: “Multimodal Control Interface” for video generation; synchronized sensor streams.
- Assumptions/dependencies: Sensor integration complexity; model architecture extensions; labeled multimodal datasets.
- World-Model–Driven Closed-Loop Training (Software + Robotics): Unified environment for policy learning and evaluation
- Use case: Combine predictive video generation with policy rollouts to create realistic, controllable training loops; minimize physical trials.
- Tools/products/workflows: “Embodied World Simulator” integrating depth/action conditioning with planning; policy-in-the-loop generation and evaluation.
- Assumptions/dependencies: Stability of closed-loop learning; reliable generalization across tasks; safeguards against compounding model errors.
Glossary
- 3D control interface: A mechanism that uses 3D signals (primarily depth) to guide 2D video generation and editing. "We utilize depth as the 3D control interface, in conjunction with edges, actions, and ray maps, to guide the generation of multi-view demonstrations."
- 3D Diffusion Policy: A policy learning approach that uses diffusion models over 3D representations for visuomotor control. "enhanced spatial generalization of 3D Diffusion Policy~\cite{Ze2024DP3}"
- 3D Gaussian Splatting (3DGS): A rendering technique representing scenes with 3D Gaussians to enable photorealistic view synthesis. "use 3D Gaussian Splatting (3DGS)~\cite{3dgs} with trajectory generation to reduce the gaps in visual fidelity and interaction reality."
- 3D-Controlled video generation: Video synthesis conditioned on 3D signals (e.g., depth) to ensure multi-view consistency and realistic interactions. "3D-Controlled Video Generation."
- 7-DoF joint angles: A seven degrees-of-freedom configuration of a manipulator’s joints used as the action representation. "The action is the 7-DoF joint angles."
- Action-conditioned video generation: Generating videos conditioned on future actions to evaluate or simulate policies. "Second, action-conditioned video generation~\cite{jiang2025enerverse, liao2025genie, wang2025embodiedreamer, shang2025roboscape} performs as the policy evaluator or realistic simulation environment,"
- Canny edges: Edge maps computed by the Canny detector, used as auxiliary conditioning signals. "including Canny edges, action maps, and ray maps, which further sharpen object boundaries,"
- Cross-view attention: An attention mechanism that computes dependencies across multiple camera views. "Cross-view attention, on the other hand, computes self-attention across all views simultaneously,"
- Diffusion Policy: A visuomotor policy framework that models actions via diffusion processes. "such as the Diffusion Policy~\cite{chi2023diffusionpolicy, chi2024diffusionpolicy}"
- Dual-attention mechanism: A design combining intra-view and cross-view attention to balance detail and multi-view correspondence. "The dual-attention mechanism consists of intra-view attention and cross-view attention."
- Embodiment mismatch: Differences between the robot embodiment in pretraining and deployment that necessitate finetuning. "For , due to embodiment mismatch, we perform full finetuning."
- End-effector: The robot’s tool or hand at the end of its kinematic chain. "Since the camera is rigidly attached to the robot’s end-effector,"
- End-effector pose (6D): The 3D position and orientation (six degrees of freedom) of a robot’s end-effector. "The action is the 6D end-effector pose."
- Feed-forward geometry reconstruction: Predicting scene geometry (e.g., depth, poses) in one forward pass without iterative optimization. "Recently, feed-forward geometry reconstruction~\cite{dust3r_cvpr24,mast3r_eccv24,wang2025vggt,wang2025pi3,keetha2025mapanything,lu2025matrix3d,zhang2025flare} unlocks sparse-view reconstruction in seconds,"
- Forward kinematics (FK): Computing link poses from joint angles along the robot’s kinematic chain. ""
- Gen2Real: The performance of generated data when transferred to real-world policy training and evaluation. "limiting the Gen2Real performance."
- Inpainting: Filling missing or occluded regions in images or depth to reduce artifacts. "We mitigate these artifacts through background~\cite{wang2025seededit30fasthighquality} inpainting and depth filtering."
- Intra-view attention: Attention computed within a single view to capture fine-grained spatial context. "Intra-view attention performs self-attention over the tokens of each individual view,"
- Inverse kinematics (IK): Computing joint configurations to achieve a desired end-effector pose. ""
- Kinematic validity: Adherence to the robot’s kinematic constraints (joint limits, link geometry). "only the end-effector should be transformed, and the remaining arm must be realigned to preserve kinematic validity."
- Kinematically consistent depth: Depth maps that correspond to physically plausible robot configurations. "thereby producing kinematically consistent depth maps that serve as reliable control signals for subsequent video generation."
- Metric-scale geometry reconstruction: Recovering scene geometry with correct physical scale. "Metric-scale Geometry Reconstruction"
- Motion planning: Algorithmic computation of collision-free, feasible manipulation or navigation trajectories. "The new motion segment is generated through motion planning~\cite{sundaralingam2023curobo}."
- Multi-conditional video generation: Video synthesis conditioned on multiple signals (e.g., depth, edges, actions, ray maps). "we propose a multi-conditional video generation model guided by depth as the primary control signal, together with action, edge, and ray maps,"
- Multi-view consistency: Maintaining coherent content across multiple camera viewpoints. "Reconstructing the detailed environmental geometry is the key to generating controllable and multi-view consistent demonstrations."
- NeuS: A neural implicit surface method using volume rendering for multi-view reconstruction. "Early methods such as NeuS~\cite{wang2021neus} and 2DGS~\cite{huang20242dgs} use radiance fields and gaussian splatting as 3D representations,"
- Point cloud: A set of 3D points representing scene geometry used for editing and depth synthesis. "we perform depth-reliable 3D editing on point clouds to generate new manipulation trajectories"
- Point-cloud editing: Modifying 3D point clouds to change object placements and generate new trajectories. "Depth-reliable spatial editing which combines point-cloud editing with trajectory planning"
- Radiance fields: Continuous volumetric scene representations enabling novel view synthesis. "use radiance fields and gaussian splatting as 3D representations,"
- Ray maps: Per-pixel ray descriptors used as conditioning signals for multi-view consistency. "including Canny edges, action maps, and ray maps,"
- Sim2Real gap: The performance drop when transferring from simulation to real-world deployment. "However, the lack of real-world interaction leads to the Sim2Real gap."
- Smooth object relocation: Interpolated object motion to move from original to target placement prior to manipulation. "Smooth Object Relocation. With the condition's control, the model is able to generate the manipulation video from the first frame,"
- Trajectory interpolation: Creating new paths by interpolating between existing trajectories or poses. "through pose tracking and trajectory interpolation."
- URDF (Unified Robot Description Format): A standard XML format describing a robot’s kinematic and visual structure. "the robot’s standardized URDF model."
- VGGT (Visual Geometry Grounded Transformer): A transformer architecture for multi-view geometry prediction (depth, poses) from images. "fine-tune VGGT~\cite{wang2025vggt}, enhancing metric-scale depth map and camera pose prediction in humanoid scenarios."
- Vision-Language-Action (VLA): Models linking visual inputs, language, and actions for robot control. "We conduct experiments on two VLA policies: Go-1~\cite{agibot2025agibotworld} and ~\cite{intelligence2025pi05}."
- Visuomotor policy: A control policy mapping visual observations to motor actions for manipulation. "visuomotor policy learning"
Collections
Sign up for free to add this paper to one or more collections.