Autoregressive Language Models are Secretly Energy-Based Models: Insights into the Lookahead Capabilities of Next-Token Prediction
Abstract: Autoregressive models (ARMs) currently constitute the dominant paradigm for LLMs. Energy-based models (EBMs) represent another class of models, which have historically been less prevalent in LLM development, yet naturally characterize the optimal policy in post-training alignment. In this paper, we provide a unified view of these two model classes. Taking the chain rule of probability as a starting point, we establish an explicit bijection between ARMs and EBMs in function space, which we show to correspond to a special case of the soft Bellman equation in maximum entropy reinforcement learning. Building upon this bijection, we derive the equivalence between supervised learning of ARMs and EBMs. Furthermore, we analyze the distillation of EBMs into ARMs by providing theoretical error bounds. Our results provide insights into the ability of ARMs to plan ahead, despite being based on the next-token prediction paradigm.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper looks at two ways of building LLMs and shows they’re more closely related than people think. One way, called an autoregressive model (ARM), writes a sentence one token at a time by guessing the next token. The other way, called an energy-based model (EBM), scores complete sentences and prefers the ones with higher total scores. The authors prove there’s a precise, two-way connection between these two kinds of models. This helps explain how next-token models (like today’s big LLMs) can still “plan ahead,” even though they only predict one token at a time.
What questions does the paper ask?
- Can a next-token model (ARM) represent the same choices as a whole-sequence model (EBM)?
- If so, how exactly do we translate between the two?
- Does standard training for next-token models (“teacher forcing”) secretly learn the same thing as training an EBM?
- When we fine-tune LLMs with reinforcement learning (RL) to align them with human feedback, how does that relate to EBMs and ARMs?
- How close can an ARM get to an EBM in practice, and can we bound the error?
How did they study it?
To keep things clear, here are the main ideas with simple analogies:
- ARMs: Think of writing a story word by word. At each step, you look at what you’ve already written (the context) and pick the next word based on a score.
- EBMs: Think of rating whole stories. Each complete story gets a single score. Better stories are more likely.
The challenge: EBMs need to consider all possible complete stories to normalize their scores (like summing up scores for every story to turn them into probabilities). That’s usually impossible to do exactly because there are way too many possibilities.
The core approach in the paper:
- The chain rule of probability. This is the basic math fact that any probability over whole sequences can be broken into “next-token” pieces, and vice versa. The authors use this to build an exact “translation” between EBMs and ARMs, assuming we can store scores for every possible context and token (this idealized setting is called “function space” or the “tabular” setting).
- A reinforcement learning (RL) view. In RL, you choose actions to get rewards over time. Here:
- A token is an action.
- The context (all tokens so far) is the state.
- The reward is like the EBM’s score.
- “Maximum entropy RL” prefers good rewards while keeping the policy “soft” (not too certain), which leads to the soft Bellman equation. The authors show their EBM↔ARM translation is exactly a special case of this equation.
- A dynamic programming view. Imagine all partial sentences form a giant tree (a directed acyclic graph). Finding the best complete sentence is like finding the best path; computing a “soft best” (considering all paths smoothly) uses a log-sum-exp operation. The mapping from EBM to ARM is like computing future values for every node in this tree.
- Teacher forcing and learning. Training ARMs with next-token prediction (“teacher forcing”) normally seems “myopic” (only looking one step ahead). The authors show that at the true optimum (again, in function space), this training actually matches what a global EBM would do—so it isn’t inherently short-sighted.
- Experiments. They run small synthetic tests where exact calculations are possible, confirming the theory.
What did they find and why is it important?
Here are the main results in plain language:
- There is an exact, two-way translation between EBMs and ARMs in function space. That means, in an ideal setting where you can store exact scores for everything, any whole-sequence model (EBM) can be turned into a next-token model (ARM), and vice versa, with no loss.
- Teacher forcing is optimal in function space. If your model is powerful enough and you can train it perfectly, next-token training reaches the same best solution as training an EBM directly. So the “myopic” concern is not about the goal; it’s about practical training limits.
- Planning ahead emerges inside ARMs. When you translate an EBM into an ARM, the ARM’s next-token score equals the immediate reward plus a “future value” term (a soft lookahead). In other words, an ARM can internally learn to plan ahead by encoding future possibilities in its next-token scores.
- Reinforcement learning fine-tuning equals “distilling” an EBM into an ARM. The best solution to common RL fine-tuning objectives (with entropy or KL regularization) is an EBM. In practice, we train ARMs to mimic that EBM—this is distillation. The authors give a theoretical error bound: if the ARM’s scores are close to the ideal ones, then its overall distribution over full sentences is also close, with an error that scales linearly with the sequence length.
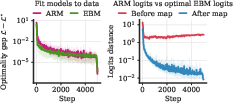
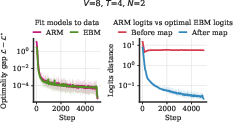
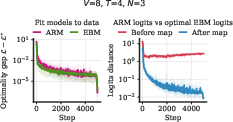
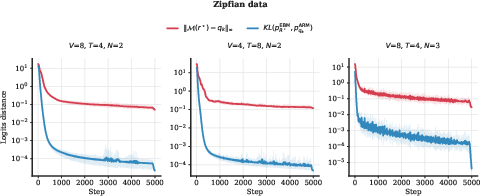
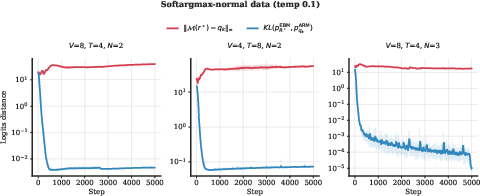
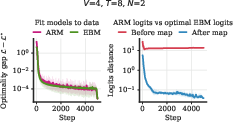
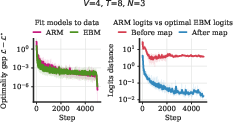
- Small-scale experiments match the theory. In controlled settings, ARMs and EBMs trained separately reach the same minimum loss, and the logits (scores) line up as predicted by the mapping.
Why this matters:
- It gives a clean mathematical explanation for why next-token prediction works so well, even for tasks that seem to require planning.
- It ties together ideas from language modeling, energy-based modeling, and reinforcement learning into one picture, making it easier to reason about alignment and training methods.
Implications and impact
- Justification for current practice: The paper supports the idea that next-token training and teacher forcing are theoretically sound strategies, not just convenient hacks. With enough capacity and the right optimization, ARMs can represent “lookahead” behavior.
- Clearer view of RL fine-tuning: RL-based alignment can be seen as learning an EBM and then approximating it with an ARM you can sample from quickly. This clarifies why we do RL-style training even if we can write down the EBM: sampling from EBMs is hard; sampling from ARMs is easy.
- Guidance for model design: Since an ARM’s next-token scores must also capture future value, architectures or training signals that help models estimate “what comes next on average” could improve planning-like behavior.
- Limits and future work: In real life, we don’t have infinite compute or perfect models. EBMs can use non-causal Transformers (which see the whole sequence), while ARMs must be causal (see only the past). Learning the “future value” inside a causal model is hard. Future research could:
- Improve how ARMs learn these future-looking values.
- Explore adding helpful latent “thinking traces.”
- Better understand optimization challenges and model capacity needs.
In short, this paper shows that next-token models aren’t doomed to be short-sighted—they can, in principle, act like whole-sequence planners. The gap is less about what they can represent, and more about how well we can train them to do it.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following points identify what is missing, uncertain, or left unexplored in the paper, and suggest concrete directions for future research.
- Scalability of the EBM→ARM mapping: The exact conversion requires computing with bottom-up dynamic programming at cost, which is infeasible for realistic vocabularies and lengths. How can we design scalable approximations (e.g., truncated DP, beam search, MCTS, learned value functions) with provable error guarantees?
- Practical estimation of (soft value function): While must implicitly encode to equate EBMs and ARMs, the paper does not propose algorithms to learn efficiently in large models. Can actor–critic-style value heads, auxiliary consistency losses, or learned soft value critics make estimation tractable?
- Optimization and approximation error: Proposition 3.2 (equivalence of minima) holds in function space, but the paper does not quantify how optimization dynamics and model misspecification affect convergence to in parameterized models. What conditions on architectures, losses, and optimization are sufficient for realizing the bijection approximately?
- Tighter and distribution-weighted KL bounds: Proposition 3.3 gives a uniform -based bound scaling as , independent of the input distribution. Can we derive tighter, distribution-weighted bounds (e.g., using occupancy measures over prefixes, Lipschitz continuity, or local curvature) that reflect typical-case rather than worst-case performance?
- Impact of limited context windows: The theoretical analysis assumes unlimited context (infinite-order Markov chain), but real LLMs have finite windows. How does truncation break the bijection and degrade estimation? Can we characterize error as a function of context length and sequence length distributions?
- Handling truly variable-length and unbounded horizons: The framework enforces termination with EOS and fixed maximum length . What changes for unbounded horizons or stochastic stopping rules? Can the bijection be extended with discounting and stopping-time distributions?
- Non-decomposable sequence-level rewards: The reduction sets to zero except at EOS for arbitrary . Is this reduction learnable and stable in practice? What are the optimization consequences of learning rewards concentrated at terminal tokens?
- Generalization to stochastic transitions: The MDP view assumes deterministic transitions (). How do results change for stochastic generative processes (e.g., latent variables, external tools) where transitions are not deterministic?
- Role of latent variables and chain-of-thought: The paper notes this as future work but does not analyze it. How do latent “thinking traces” change the bijection, the structure of , and the feasibility of planning via ARMs?
- Extension beyond KL regularization: The paper mentions -divergences but does not extend the bijection and the distillation analysis to general regularizers. Can we characterize ARM–EBM equivalences and error bounds under alternative -divergences (e.g., reverse KL, JS, )?
- Inference-time factoring vs. explicit mapping: The paper notes we can factorize EBM distributions via the chain rule without explicitly computing . What are the practical trade-offs between direct factoring (requiring partition functions) and learned mappings, and can we design hybrid schemes?
- Approximation by Transformers: The cited universal approximation result requires embedding dimension scaling with , which is impractical. Can we prove approximation with realistic dimensions, parameter sharing, and attention sparsity while retaining guarantees?
- Empirical validation at scale: Experiments are limited to “tiny LLMs” where EBM partition functions are exactly computable. How do the claims behave for large LLMs, real datasets, and preference-based post-training pipelines?
- Sample complexity and data requirements: The function-space results abstract away sample complexity. What are the data requirements to learn and with acceptable approximation error, and how do they compare?
- Robustness under reward noise and preference inconsistencies: Alignment rewards and human preferences are noisy. How does noise in or pairwise preferences affect the ARM–EBM equivalence and the learned ?
- Mode-seeking vs. distributional fidelity: EBMs can be used to predict modes without sampling; ARMs produce full conditional distributions. Under what conditions do ARMs trained with teacher forcing faithfully match EBM distributional properties (e.g., calibration, entropy), not just modes?
- Multi-modality and continuous outputs: The analysis assumes discrete vocabularies. How do results extend to continuous or hybrid outputs (vision tokens, speech), where EBMs and ARMs have different normalization structures?
- EOS design and termination behavior: Valid distributions rely on . How sensitive are planning and equivalence results to EOS frequency, training heuristics (length penalties), and length priors in real LLM training?
- Bijection with reference measures: Appendix mentions a bijection with a reference measure, but the main text does not analyze how anchors (pretrained models) alter the mapping and value functions. Can we formalize the effect of anchors on and distillation error?
- Training objectives and consistency losses: MaxEnt RL literature uses one-step/multi-step consistency losses. Can analogous losses be integrated into next-token training to explicitly enforce the soft Bellman fixed point and speed convergence?
- Planning failures and overfitting: The paper argues teacher forcing’s limitations are optimization-related. What diagnostics and interventions (regularization, data curricula, synthetic planning tasks) can detect and prevent myopic solutions in practice?
- Beam search and decoding effects: The theoretical results assume sampling from . How do common decoding strategies (beam search, top-, nucleus sampling) interact with the ARM–EBM equivalence and the implicit ?
- Distribution shift and off-policy learning: Post-training often operates off-policy relative to pretraining. How does distribution shift in prompts and responses impact the validity of the bijection and the distillation guarantees?
- Complexity comparison of learning vs. : The paper lists this as future work. Can we formalize the relative statistical and computational complexity (parameter counts, optimization curvature, gradient variance) of learning globally normalized versus locally normalized ?
Practical Applications
Immediate Applications
The following applications can be deployed now by adapting existing LLM training, evaluation, and alignment workflows, using the paper’s bijection between ARMs and EBMs, its equivalence-of-minima result, and the KL-error bound for distillation.
- Boldify teacher forcing in production pipelines (industry, academia; software, education, healthcare, finance)
- What: Use the paper’s equivalence-of-minima result to justify continued reliance on next-token prediction (teacher forcing) during supervised fine-tuning, even for tasks requiring lookahead.
- How: Keep supervised fine-tuning as the primary objective; reserve RL-style post-training for preference shaping or constraint enforcement rather than for compensating “myopia.”
- Tool/workflow: “SFT-first” post-training playbooks with explicit justification and acceptance criteria tied to sequence-level evaluation.
- Dependencies/assumptions: Optimality holds in function space; practical performance still depends on model capacity, optimization, and data coverage.
- EBM-to-ARM distillation as a standard alignment primitive (industry; software, safety, content moderation)
- What: Treat RLHF and related methods as distilling a globally normalized sequence-level reward model (EBM) into a deployable ARM (the production LLM).
- How: Train a non-causal verifier/reward model R (EBM teacher), then distill to the ARM with KL-regularized objectives; use the derived KL bound to set quality gates.
- Tool/workflow: “Verifier → Distill to policy” loop; reward/model cards include estimated sup-norm logit error and T-dependent KL bound.
- Dependencies/assumptions: Non-causal reward models require robust data and careful regularization; guarantees degrade with sequence length T and approximation error.
- Value-aware diagnostics for “lookahead” (industry, academia; software, robotics, code generation)
- What: Use the mapping r = q − Vq(next) to decompose token logits into immediate reward and future value, exposing whether the model plans ahead.
- How: Compute Vq(S⊕y) with a value head or auxiliary critic; visualize token-level future-value contributions during decoding and evaluation.
- Tool/workflow: “Lookahead meter” dashboards for beam search, sampling, and failure analysis; alerts when decisions are driven by short-term rewards.
- Dependencies/assumptions: Accurate Vq estimation is needed; exact computation is intractable for long sequences, so use learned critics or rollouts.
- Reference-aware post-training with flexible f-divergences (industry, academia; software, policy)
- What: Frame post-training as maximizing reward with a regularizer to a reference model (anchor distribution), generalized beyond KL.
- How: Swap KL for other f-divergences (as cited in the paper) to control behavior drift and compliance; tune divergence choice to safety/compliance constraints.
- Tool/workflow: Configurable “regularized policy optimization” stage with pluggable f-divergences and reward models.
- Dependencies/assumptions: Requires reliable reward signals; stability depends on divergence choice and optimization details.
- ARM-as-MDP consistency regularization (industry, academia; robotics, ops research, software)
- What: Add a soft Bellman/consistency loss to token-level training to encourage implicit value-learning within ARMs.
- How: Penalize residuals q − [r + E V(next)] with one-step or multi-step consistency terms; integrate with SFT/RLHF as an auxiliary loss.
- Tool/workflow: Critic/value head training for LLMs; regularizers that reduce myopic errors without full-blown RL.
- Dependencies/assumptions: Requires value approximation; benefits are empirical and task-dependent.
- EBM-guided constrained generation via verifier distillation (industry; software, code, enterprise search)
- What: Leverage verifiers (unit tests, consistency checkers, spec matchers) as sequence-level rewards to guide generation through distillation.
- How: Train R with pass/fail or scores; distill into a fast ARM to avoid MCMC; deploy for code generation, RAG answer verification, and structured outputs.
- Tool/workflow: “Verifier → Distill → Constrained generation” for CI/CD code bots, enterprise chat, and document drafting with compliance checks.
- Dependencies/assumptions: Verifier coverage and quality are critical; reward hacking risks must be monitored.
- Safety and compliance tuning with sequence-level reward shaping (industry, policy; healthcare, finance, legal)
- What: Encode policy/compliance requirements as an EBM reward and distill into the production LLM.
- How: Use auditor/evaluator models to score outputs end-to-end; select regularization strength to trade off utility vs. compliance drift.
- Tool/workflow: Compliance reward pipelines with monitorable divergence budgets to the base model.
- Dependencies/assumptions: Requires curated, auditable reward criteria; over-regularization can reduce task performance.
- Termination and EOS calibration checks (industry, academia; software)
- What: Adopt the paper’s treatment of EOS to guarantee valid distributions over variable-length sequences and robust stopping criteria.
- How: Add automated tests that ensure π(EOS|S_T)≈1 at maximum horizon; calibrate EOS probabilities to control verbosity and truncation.
- Tool/workflow: Decoding policy tests as part of release QA.
- Dependencies/assumptions: Requires horizon definitions and prompt-specific constraints.
- Measuring “planning gap” with bound-driven acceptance criteria (industry; software, robotics)
- What: Use the KL bound KL ≤ 2T * ||q* − q||∞ to define acceptance thresholds for distillation or model updates.
- How: Estimate sup-norm logit error on held-out states; derive implied worst-case KL and reject models exceeding the planning-gap budget.
- Tool/workflow: Bound-aware CI for policy updates; red-team protocols tied to KL budgets.
- Dependencies/assumptions: Sup-norm estimation is conservative; localized errors may still matter even with small global bounds.
- Structured decoding with value bonuses (industry; software, education)
- What: Adjust token logits during decoding by adding approximate V(S⊕y) to favor continuations with high downstream value.
- How: Train a lightweight value head; apply logit shaping at inference to reduce hallucinations and improve multi-step reasoning.
- Tool/workflow: Plug-in “value-shaped decoding” for beam search/sampling.
- Dependencies/assumptions: Requires reliable value estimation; may trade off calibration for improved task success.
Long-Term Applications
These applications require further research, scaling, or development to become routinely deployable.
- General-purpose “EBM teacher” platforms (industry, academia; software, safety, robotics)
- Vision: A platform for training non-causal, sequence-level reward models (verifiers/critics) and distilling them into ARMs for fast inference across domains.
- Potential products: Verifier marketplaces, domain-specific EBM hubs (code, biomed, legal), unified APIs for R training and ARM distillation.
- Dependencies/assumptions: Building robust, generalizable R is hard; requires scalable negative sampling, debiasing, and robust evaluation beyond MCMC-free inference.
- Value-explicit LLM architectures (industry, academia; software, robotics)
- Vision: LLMs with native value heads estimating Vq(S) and/or q(S,y), trained jointly to reduce planning failures.
- Potential products: “Lookahead LLMs” that are inherently less myopic; better chain-of-thought and tool-use planning.
- Dependencies/assumptions: Joint training stability, compute overheads, and the need for task-aligned value targets.
- Approximate dynamic programming for long-horizon text and actions (industry, academia; robotics, operations, education)
- Vision: Scalable approximations to the bijection q = r + V(next) without exponential cost—e.g., learned value iteration, amortized DP, or structured state abstractions.
- Potential workflows: Planning-aware training for long documents, multi-turn tutoring, and robot skill sequencing.
- Dependencies/assumptions: Requires principled state compression and uncertainty handling; evaluation of long-horizon consistency remains open.
- GFlowNet and MaxEnt-RL-inspired samplers for discrete generation (academia, industry; drug discovery, materials, program synthesis)
- Vision: Train EBMs over structured spaces and amortize sampling via GFlowNet/MaxEnt-RL consistency, then distill to ARMs for low-latency sampling.
- Potential products: Molecule/design generators with verifier feedback; programmable constraints via R; deployment via ARM distillation.
- Dependencies/assumptions: Quality of verifiers for scientific tasks; avoiding mode collapse; reliable exploration in massive discrete spaces.
- Evidence-grounded compliance generation with auditable energy budgets (policy, industry; healthcare, finance, legal)
- Vision: Require regulated model outputs to satisfy energy/score thresholds under certified reward models; distill to ARMs but retain verifiable audits.
- Potential products: Certifiable report generation, traceable risk assessments, and audit logs grounded in R and divergence budgets.
- Dependencies/assumptions: Standardized, transparent reward models; agreement on acceptable divergence to reference policies.
- Unified research benchmarks for “planning in LLMs” (academia; education, reasoning, robotics simulation)
- Vision: Benchmarks that measure improvements from value-aware ARMs and EBM-to-ARM distillation under controlled horizons and state spaces.
- Potential outputs: Leaderboards correlating sup-norm logit errors, KL bounds, and downstream task success; insights into teacher-forcing optimization limits.
- Dependencies/assumptions: Requires curated tasks with measurable long-horizon value; reproducibility protocols.
- Tooling for preference learning via sequence-level energies (industry, academia; personalization, UX)
- Vision: Learn user/organization preferences as EBMs at the sequence level (documents, emails, plans), then distill to ARMs for personalized assistants.
- Potential products: Preference editors with explainable r and V components; rapid distillation to local assistants.
- Dependencies/assumptions: Privacy-preserving preference learning; avoiding reward hacking; consistent generalization across contexts.
- Value-shaped multi-agent coordination (academia, industry; operations, logistics, multi-bot systems)
- Vision: Treat joint plans as sequences with shared EBMs; distill individual ARMs that coordinate via implicit value predictions.
- Potential products: Fleet routing, warehouse automation, multi-agent customer support workflows.
- Dependencies/assumptions: Credit assignment across agents; scalable value estimation for combinatorial joint spaces.
- Standards for lookahead evaluation and reporting (policy, industry; safety, compliance)
- Vision: Require vendors to report lookahead diagnostics (e.g., value attribution, distillation bounds, divergence to anchors) alongside common LLM metrics.
- Potential outputs: Compliance-ready scorecards and audits, procurement standards for safety-critical deployments.
- Dependencies/assumptions: Community consensus on metrics; nontrivial cost to compute robust diagnostics at scale.
Notes on Assumptions and Dependencies
- Function-space results assume models can fit data perfectly; in practice, capacity, optimization, and data coverage limit equivalence.
- Exact EBM→ARM conversion is exponential in sequence length; practical deployments rely on approximation or learning Vq.
- The KL bound scales with sequence length T and sup-norm logit error; it is conservative but useful for acceptance criteria.
- Reliable verifiers/reward models are the bottleneck for many applications; reward hacking and misspecification risk remain.
- Non-causal verifiers increase compute and data demands; careful regularization and validation are needed.
- EOS and horizon handling must be explicit in production decoding policies to ensure valid distributions and safe stopping.
Glossary
- Anchor distribution: A reference probability distribution used to regularize or anchor the learned policy in RL formulations. "reference ``anchor'' distribution."
- Ancestral sampling: A sampling procedure that generates sequences token-by-token following conditional probabilities defined by an autoregressive model. "autoregressive (a.k.a. ancestral) sampling"
- Autoregressive models (ARMs): Models that factorize sequence probabilities into products of next-token conditionals and generate text one token at a time. "Autoregressive models (ARMs), which are based on the next-token prediction paradigm"
- Banach fixed point theorem: A mathematical result guaranteeing unique fixed points of contractive mappings, used to justify convergence in RL. "the Banach fixed point theorem."
- Bayesian networks: Directed graphical models representing factorizations of joint distributions; here used to characterize ARMs. "ARMs are Bayesian networks (directed graphical models)"
- Bijection: A one-to-one, onto mapping; the paper establishes a bijection between EBMs and ARMs in function space. "we establish an explicit bijection between ARMs and EBMs"
- Causal Transformer: A Transformer with attention masking that restricts each position to attend only to past tokens for next-token prediction. "using a causal Transformer"
- Chain rule of probability: The identity that decomposes a joint distribution into a product of conditional distributions. "The chain rule of probability factorizes a joint probability distribution into a product of conditional probabilities."
- Contextual bandit: A decision-making framework with context-dependent single-step actions; used to contrast with the MDP view of ARMs. "the (combinatorial) contextual bandit perspective"
- Contractive mapping: A function that brings points closer together, ensuring convergence to a unique fixed point. "is a contractive mapping."
- Convex duality: A mathematical framework linking primal and dual optimization problems; referenced in RL equivalence results. "using convex duality"
- Directed acyclic graph (DAG): A graph with directed edges and no cycles; used to model sequence construction in DP. "directed acyclic graph (DAG)"
- Dynamic programming (DP): A method for solving problems by breaking them into subproblems; used here with entropy regularization over DAGs. "dynamic programming (DP)"
- Energy-based models (EBMs): Models that define probabilities via exponentiated energies (rewards) normalized by a partition function, over whole sequences. "Energy-based models (EBMs) represent another class of models"
- Entropy-regularized RL: Reinforcement learning that adds an entropy term to the objective to encourage exploration and stochasticity. "a.k.a. entropy-regularized RL"
- f-divergences: A family of divergence measures generalizing KL divergence used in regularization. "other -divergences"
- Function space (tabular setting): The setting where functions (e.g., rewards, Q-values) are represented explicitly over all states/actions rather than by parameters. "In function space (a.k.a. tabular setting in RL)"
- Gibbs (Boltzmann) distribution: A probability distribution proportional to the exponential of a score/energy, used to define EBMs and token distributions. "Gibbs (Boltzmann) distribution"
- Gibbs sampling: An MCMC method that samples each variable in turn from its conditional distribution. "Gibbs sampling."
- GFlowNets: Generative Flow Networks; methods for learning policies that sample structures proportionally to a reward via flow consistency. "GFlowNets"
- Inverse RL: The problem of inferring a reward function from demonstrations or behavior. "used for inverse RL"
- Kalman duality: The equivalence between optimal estimation (filtering) and optimal control in certain linear-quadratic systems. "Kalman duality"
- Kullback-Leibler (KL) divergence: A measure of dissimilarity between probability distributions used for regularization. "Kullback-Leibler (KL) regularization term."
- KL-regularized problem: An RL objective that maximizes reward while penalizing deviation from a reference via a KL term. "KL-regularized problem"
- Log-partition function: The log of the normalizing constant in exponential-family models; equals log-sum-exp over all sequences. "log-partition function"
- Log-sum-exp: A smooth maximum operator defined as log of a sum of exponentials; central to partition functions and soft maxima. "associativity of the log-sum-exp"
- Logits: Unnormalized scores (pre-softmax) output by models for each token. "distance between the logits of the trained ARM"
- Markov decision processes (MDPs): Formal models of sequential decision making with states, actions, transitions, and rewards. "Markov decision processes (MDPs)"
- Markov random fields: Undirected graphical models representing joint distributions via cliques; used to characterize EBMs. "Markov random fields (undirected graphical models)."
- Markov-chain Monte-Carlo (MCMC): A class of algorithms for sampling from complex distributions using Markov chains. "Markov-chain Monte-Carlo (MCMC) methods."
- Monte Carlo Tree Search (MCTS): A planning method combining tree search with Monte Carlo sampling. "using MCTS and learned soft value functions"
- Non-causal Transformer: A Transformer without causal masking that can attend bidirectionally across a sequence. "a non-causal Transformer"
- Partition function: The normalizing constant in energy-based models computed by summing exponentiated energies over all outcomes. "intractable partition function"
- Soft actor-critic: An RL algorithm that optimizes a maximum-entropy objective using actor-critic methods. "soft actor-critic algorithms"
- Soft Bellman equation: The entropy-regularized Bellman optimality relation linking rewards, values, and policies. "soft Bellman equation"
- Soft value function: The entropy-augmented state value, typically a log-sum-exp over action values. "soft value function"
- softargmax: The softmax operator interpreted as a “soft” argmax returning a distribution over choices. "softargmax"
- Teacher forcing: Training ARMs by conditioning on ground-truth tokens at each step to compute the next-token loss. "teacher forcing"
- Transition kernel: The conditional distribution over next states given the current state-action pair in an MDP. "transition kernel"
- Twisted sequential Monte Carlo: A variant of SMC methods that reweight proposals to improve inference, referenced in the RL–inference connection. "twisted sequential Monte Carlo"
Collections
Sign up for free to add this paper to one or more collections.

