- The paper presents a unified RL model, CrossAgent, that dynamically selects among heterogeneous action spaces.
- It employs a three-stage pipeline (SFT, STRL, and MTRL) to achieve context-aware action selection and improved sample efficiency.
- Empirical results in Minecraft tasks demonstrate high success rates and strong out-of-distribution generalization.
A Unified Agentic Model for Dynamic Action-Space Selection via Reinforcement Learning
Introduction
The challenge of scaling generalist agents to complex, open-ended environments lies in the diversity of skill representations and the essential requirement to transition fluently between different interaction interfaces. Conventional approaches anchor agents to a fixed action abstraction—atomic movements, GUI events, API calls, or natural language commands. This design bottleneck fundamentally restricts adaptability and hinders generalization over heterogeneous environments.
"Training One Model to Master Cross-Level Agentic Actions via Reinforcement Learning" (2512.09706) proposes CrossAgent, a unified agentic model that autonomously learns to select and switch among heterogeneous action spaces—ranging from low-level primitive controls to high-level abstract commands—at each step in a trajectory. The model is instantiated and evaluated in the Minecraft environment, encompassing both embodied control and GUI-based interaction, and utilizes a comprehensive reinforcement learning pipeline.
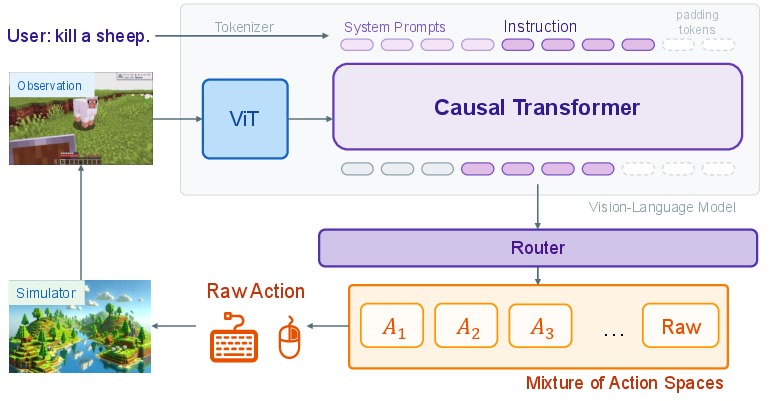
Figure 1: CrossAgent dynamically switches between different action spaces to adapt to complex task requirements, eschewing static, fixed interaction modes.
CrossAgent Framework and Action-Space Design
CrossAgent is formulated as a policy over a union of N heterogeneous action spaces A=⋃x=1NAx with each subspace corresponding to a unique control interface (e.g., motion primitives, spatial grounding, keyboard and mouse events). At each timestep, the agent jointly chooses an action space and an action within that space, optimizing a composite objective that balances task rewards and context-dependent execution costs.
The paper systematically categorizes action abstraction levels prevalent in existing agentic models:
- Raw actions: Direct low-level interface controls (keyboard/mouse).
- Motion actions: Parameterized movement or navigation primitives.
- Grounding actions: Perceptual grounding of actions to spatial scene coordinates or objects.
- Language actions: High-level, semantic task descriptions.
- Latent actions: Abstract, learned sub-behaviors emergent from offline or self-supervised data.
The central design innovation is that action-space selection is not hardwired but induced as a learnable component, enabling in-context adaptation and interface blending over task phases.
Reinforcement Learning Training Pipeline
The CrossAgent training pipeline comprises three progressive optimization stages:
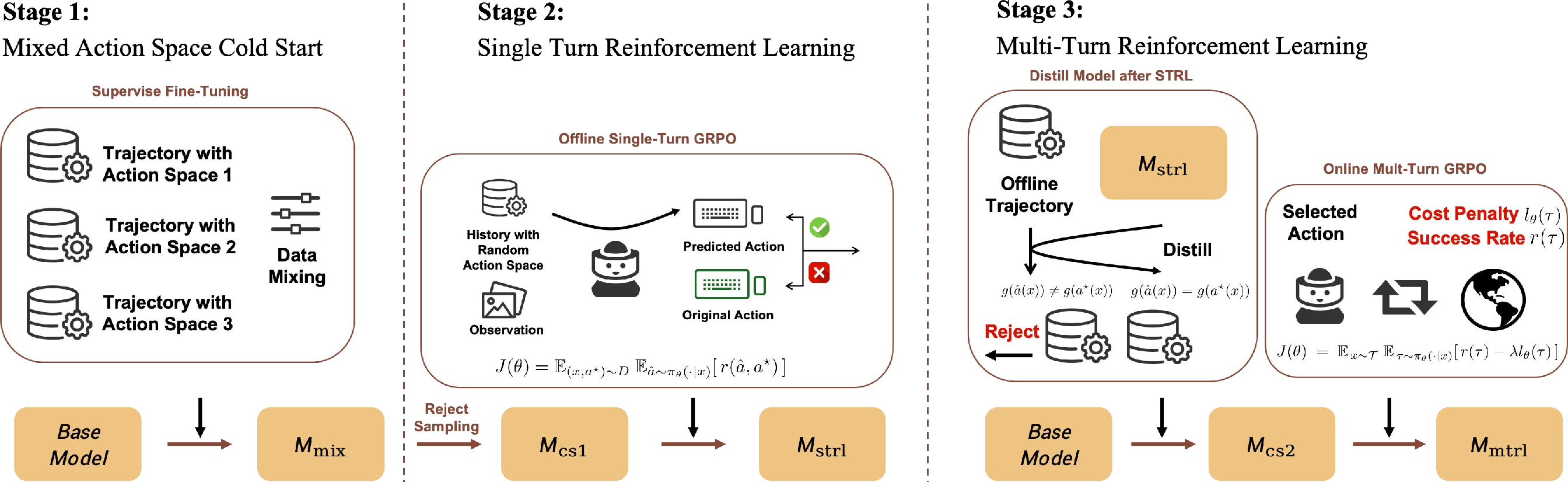
Figure 2: The CrossAgent training regimen incrementally builds adaptive multi-action-space capabilities via Cold-Start SFT, STRL, and MTRL.
Stage 1: Cold-Start Supervised Fine-Tuning (SFT)
A vision-LLM (Qwen2-VL-7B-Instruct) is first fine-tuned on a balanced, composite action-space dataset derived from Minecraft online tasks. The base model thus acquires the syntactic grounding to decode and emit valid actions across all interfaced modalities, but without strategic action-space selection.
Stage 2: Single-Turn Reinforcement Learning (STRL)
Here, the model learns to discriminate and prefer action subspaces based on immediate context. Group Relative Policy Optimization (GRPO) is applied on one-step tasks with a reward function agnostic to surface form, evaluating only the underlying environmental effect of the executed action. This yields a policy that stochastically explores action spaces and begins to develop local context-aware action-space preferences.
The inclusion of STRL is empirically crucial. Models trained with STRL converge faster and reach higher asymptotic performance in downstream multi-turn RL, as demonstrated in ablation.
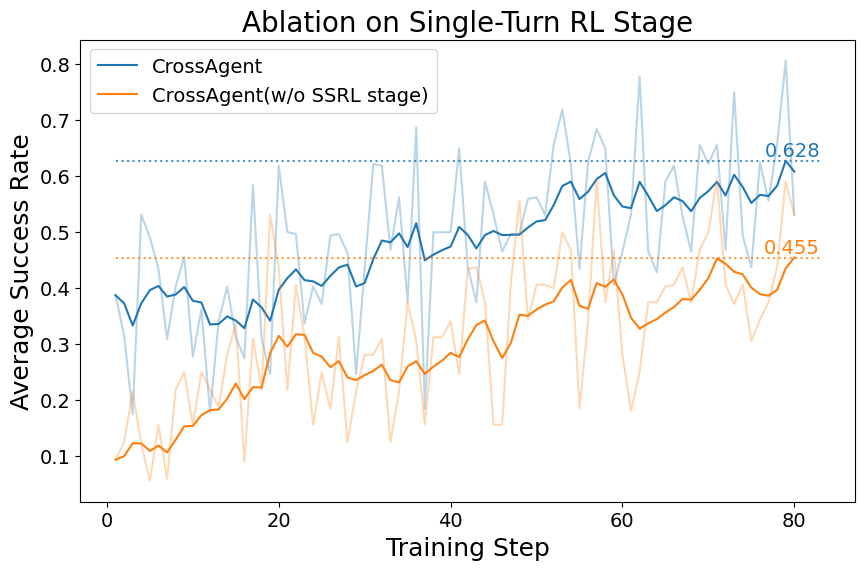
Figure 3: STRL-augmented CrossAgent exhibits marked sample efficiency and improved convergence in subsequent multi-turn RL.
Stage 3: Multi-Turn Reinforcement Learning (MTRL)
The final stage involves episodic trajectory optimization via GRPO, using sparse, long-horizon rewards directly tied to eventual task completion. To prevent mode collapse, the action-space selection policy distilled from STRL is initially preferred. The model ultimately learns to orchestrate granular and abstract actions to maximize long-horizon success rates and resource efficiency.
Empirical Analysis and Results
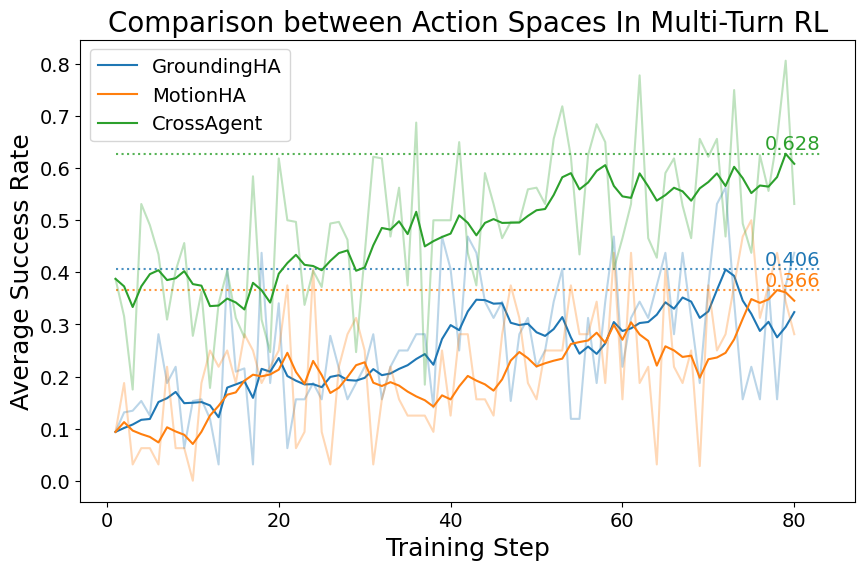
CrossAgent is evaluated across the OpenHA benchmark suite—over 800 Minecraft tasks, spanning navigation, combat, and GUI-based crafting. The experiments place strong emphasis on task diversity, requiring robust phase-specific adaptation due to the heterogeneity of interface demands.
Key empirical findings:
STRL importance: Removing the STRL phase leads to a notable drop-off in OOD generalization, especially in tasks requiring non-trivial interface adaptation.
Dynamic Action-Space Adaptation: Qualitative Analysis
Case studies further illustrate how CrossAgent’s switching policy is intrinsically context- and phase-aware, not stochastic. In the Kill Sheep task, the agent utilizes motion primitives for terrain traversal, spatial grounding for entity targeting, and atomic actions for high-frequency attacks, adapting interface choice seamlessly with task progression.
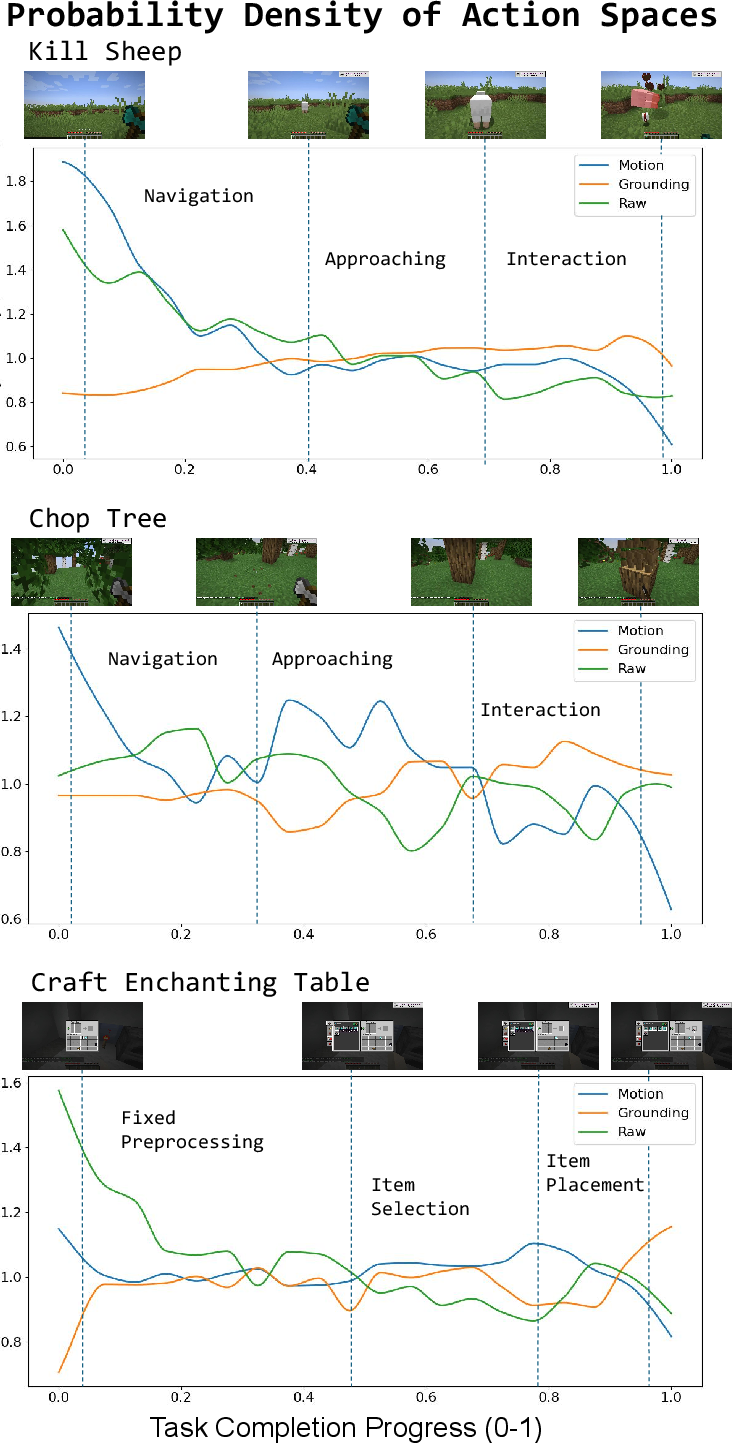
Figure 5: The density of chosen action spaces dynamically shifts with progression through different task phases, underlying in-context adaptation.

Figure 6: Example action sequences show semantically coherent interface transitions, e.g., from raw movement to GUI operations.
Implications and Forward Directions
CrossAgent’s learning-based action-space arbitration addresses the critical bottleneck of static interface design in embodied agent architectures. Theoretical implications include:
- Learned hierarchy: The policy implicitly reasons over hierarchies of abstraction, aligning with optimal option discovery perspectives.
- Robustness across distribution: Unified multi-space policies mitigate overfitting and mode collapse, outperforming domain-specialized experts.
- Efficient RL adaptation: The two-stage RL (STRL+MTRL) protocol enhances both sample efficiency and robustness, suggesting that step-level and trajectory-level policy regularization is valuable in open-world RL.
Practical avenues for future investigation include sim-to-real transfer for physical robotic systems—where interface switching also reflects reliability and safety constraints—and reduction in sample complexity for online RL by further exploiting offline or curriculum-based paradigms.
Conclusion
This work demonstrates that learning the arbitration over heterogeneous action spaces is tractable, empirically valuable, and vital for scalable, generalist agent architectures. By integrating flexible action-space selection into the reinforcement learning objective, embodied agents achieve stronger generalization and robustness. The CrossAgent framework establishes a clear foundation for unified agentic models in open-world settings, with direct implications for the design of future multi-modal, multi-interface autonomous systems.