- The paper demonstrates that Vision Transformers exhibit a dynamic inductive bottleneck, adapting representational sparsity based on image data complexity.
- It employs Effective Encoding Dimension to quantify the compression and expansion of feature representations across network layers.
- Empirical results highlight that dataset characteristics, such as texture versus feature diversity, significantly influence the emergence of the bottleneck.
Introduction
Vision Transformers (ViTs) have emerged as a significant advancement in the field of computer vision, transitioning from the hierarchical inductive biases inherent in Convolutional Neural Networks (CNNs) towards a framework that retains high-dimensional representations throughout layers. Despite their theoretical isotropic design, recent findings highlight an emergent compressive structure within ViTs, known as the "Inductive Bottleneck". This paper presents a detailed investigation into this phenomenon, demonstrating that it is not merely an architectural byproduct but a data-driven adaptation mechanism.
Theoretical Framework
The concept of effective dimensionality is central to understanding the Inductive Bottleneck. By employing the Effective Encoding Dimension (EED), the paper quantifies the rank of feature representations at each layer in ViTs. This measure reveals a U-shaped entropy profile, aligning with the Information Bottleneck principle where the network balances between rich, predictive representations and compact, noise-ignoring transformations.
Methodology
The study utilizes a ViT-Small architecture trained with the self-supervised DINO method across datasets of varying compositional complexity: UC Merced, Tiny ImageNet, and CIFAR-100. DINO's self-distillation approach avoids collapse in self-supervision, crucial for observing attention map properties that denote object-background segmentation. Effective Encoding Dimension calculations reveal adaptive rank profiles responsive to the nature of image data.
Results: The Emergence of the Bottleneck
Empirical results underscore the Inductive Bottleneck's adaptability. In datasets like CIFAR-100, a pronounced bottleneck is observed, with EED reducing to approximately 23%, as the model compresses information to focus on salient features. By contrast, texture-heavy datasets like UC Merced maintain high EED percentages above 95%, as the task requires the preservation of high-frequency texture data.
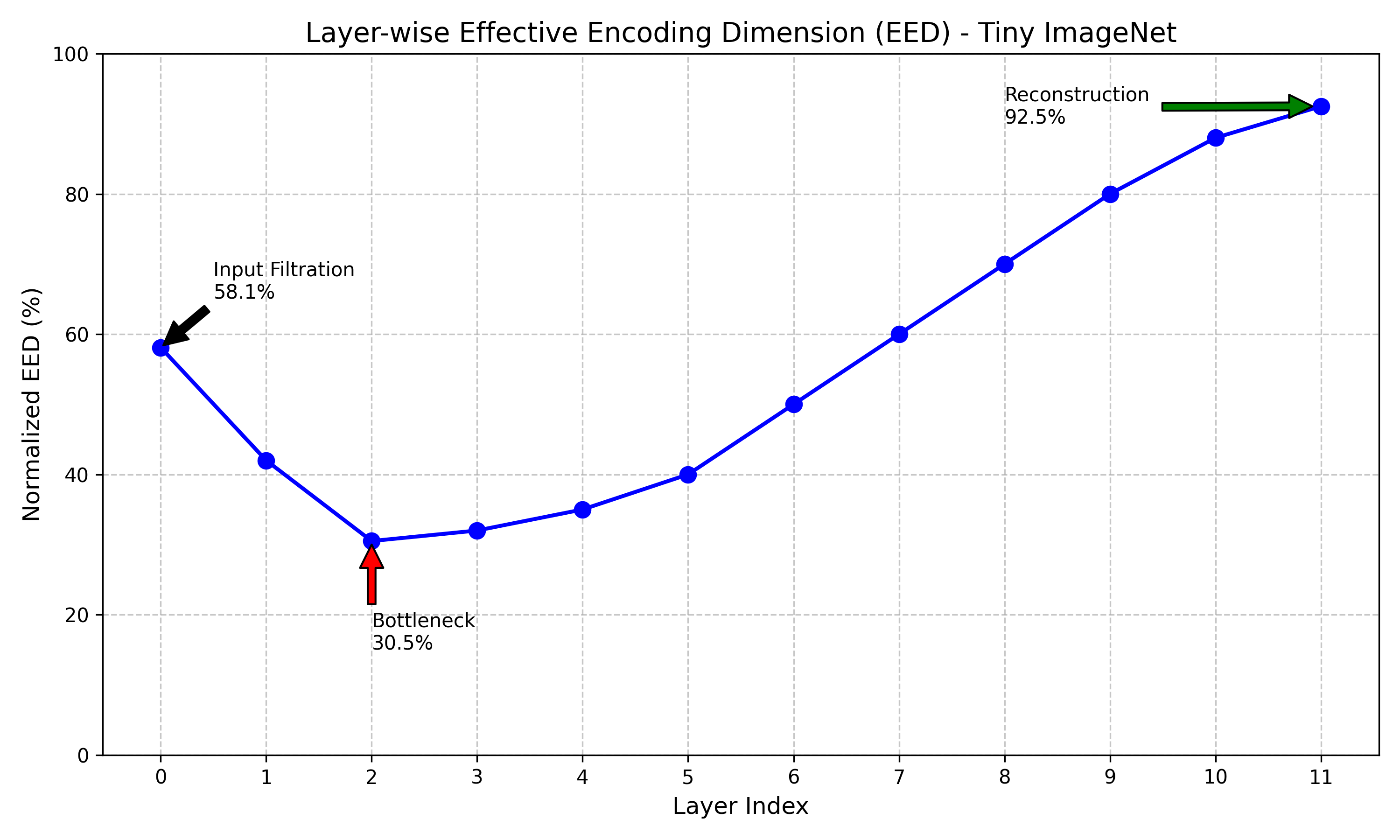
Figure 1: Layer-wise Effective Encoding Dimension (EED) for ViT-Small on Tiny ImageNet. The profile clearly shows the "Inductive Bottleneck" structure: high rank at input, compression in the middle (L2), and expansion at output (L11).
Discussion
This study elucidates the critical role of data in shaping the representational capacity of ViTs. The Inductive Bottleneck exemplifies the network's dynamic ability to adjust spatial dimensionality based on the task's demands. This contrasts with the static compression stages enforced in hierarchical architectures like Swin Transformers. The ability of ViTs to flexibly establish these bottlenecks highlights their potential for diverse applications, extending beyond image classification to other modalities.
Limitations and Future Work
The findings, while robust, are derived from ViT-Small architectures and warrant extension to larger variants to verify scalability. Additionally, the observed bottleneck behavior's applicability to tasks beyond classification, such as segmentation and object detection, remains an open question. Future research should explore causal interventions in architectural design and training regimes to optimize or even enhance these emergent properties strategically.
Conclusion
The Inductive Bottleneck is a pivotal finding in understanding Vision Transformers. It reveals that ViTs are not only capable of maintaining high dimensionality but can strategically compress and adapt representations according to the compositional complexity of the data. This behavior positions ViTs as versatile models with potential advancements in efficiency and performance across a broad spectrum of artificial intelligence applications.
