- The paper demonstrates that temporal aggregation of financial tick data significantly increases randomness, converting sequences into pseudo-random streams.
- It employs model-free binary encoding and extensive randomness tests (NIST and TestU01) to reveal non-monotonic predictability in asset prices.
- These findings suggest potential applications in cryptography and market efficiency evaluations, highlighting areas for further research.
Emergence of Randomness in Temporally Aggregated Financial Tick Sequences
Introduction
The paper "Emergence of Randomness in Temporally Aggregated Financial Tick Sequences" (2511.17479) investigates the degree to which ultra-high frequency financial data can resemble random sequences. With markets efficiency being a key concept under the Efficient Market Hypothesis (EMH), asset prices within such markets are theoretically unpredictable—akin to outputs from random number generators. This research extends traditional analyses by applying comprehensive randomness tests to high-frequency stock market data, beyond serial correlation and entropy measures. Through temporal aggregation, the authors transform highly correlated trade data into random streams, exploring the stochastic properties with statistical test batteries such as NIST Statistical Test Suite and TestU01. This model-free approach aids in assessing randomness in financial time series and may hold relevance for generating pseudo-random sequences, with applications in cryptography and other domains.
Methodology
The study first sets out to encode financial price sequences into binary strings to measure randomness. For each sequence of transaction prices, binary strings are constructed by comparing consecutive price ratios. Detailed temporal aggregation is applied, creating numerous binary subsequences per day, which are analyzed across varying levels of aggregation. This innovative encoding approach captures frequency-based patterns within high-frequency trading data.
The paper employs diverse randomness tests from the NIST Statistical Test Suite and TestU01 batteries—spanning frequencies, patterns, entropy measures, spectral characteristics, and random walks. By testing these sequences, the study yields empirical estimations of randomness, presenting a thorough characterization of stochastic financial data without relying on any prior model assumptions.

Figure 1: Results of smultin_MultinomialBitsOver (L=4) test from Alphabit applied to CCL, INTC, LLY, and SPY data.
Results
The research demonstrates that temporal aggregation significantly enhances the randomness of financial tick data. With increasing aggregation levels, the binarized transaction sequences exhibit intensified randomness, subsequently resembling outputs from random number generators in many cases. Such aggregation mitigates predictable microstructure patterns, transforming intra-day frequency data into random-like sequences over larger time intervals.
Notable results include the unveiling of non-monotonic behaviors in predictability for certain assets, observed through numerous tests. Furthermore, surprising instances of persistent predictability emerge even at high aggregation levels, particularly for actively traded stocks like AAPL and TSLA, indicating that random-like sequences might require even higher levels of aggregation.
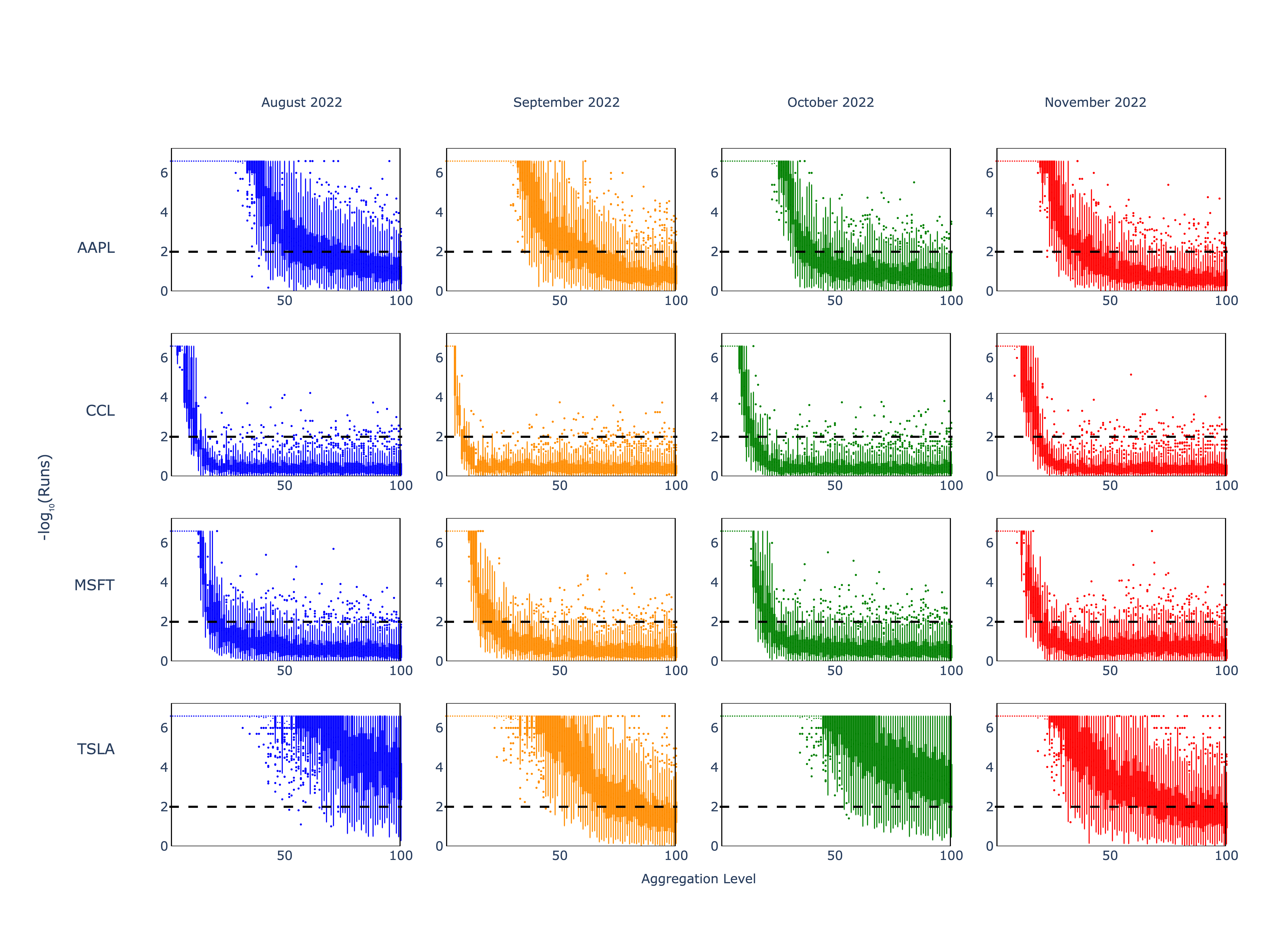
Figure 2: Results of Runs test from NIST STS applied to AAPL, CCL, MSFT, and TSLA data.
Figure 3: Results of ApproximateEntropy test from NIST STS applied to AAPL, CCL, INTC, and SPY data.
Implications and Future Work
This research lays a robust foundation for deploying pseudo-random number sequences derived from financial data, enhancing the scope for applications in cryptographic and data security models where randomness is pivotal. Future research could further explore the applications of such sequences in randomness beacons and PRNGs, while expanding the dataset across broader asset baskets for verification.
The methodology provides valuable insight into detecting algorithmic trading influences at microstructural levels. Future work could explore understanding how algorithmic periodicity might impact randomness patterns, potentially refining randomness tests to capture deterministic market influences more accurately.
Conclusion
In summary, this study successfully demonstrates how temporal aggregation can enhance the randomness of high-frequency financial tick sequences. By employing a detailed suite of randomness tests, the research reaffirms that financial data can generically transform into pseudo-random streams under aggregation, providing a model-free approach with profound implications for cryptography and market efficiency evaluations. Further development in randomness assessments might leverage improved visualization techniques to summarize stochastic properties across diverse markets and timeframes, optimizing randomness extraction from traded data.