- The paper demonstrates a novel self-referential mechanism for RL in vision-language-action models, eliminating reliance on expert demonstrations and hand-crafted rewards.
- It clusters latent embeddings of successful trajectories to generate progress-wise rewards, achieving over 99% success on the LIBERO benchmark with significant efficiency gains.
- SRPO's approach generalizes robustly to real-world tasks and diverse sensor modalities, enabling scalable, input-light policy optimization.
Self-Referential Policy Optimization (SRPO) for Vision-Language-Action Models
Introduction
The paper "SRPO: Self-Referential Policy Optimization for Vision-Language-Action Models" (2511.15605) introduces a novel RL framework for VLA models that addresses the persistent challenge of reward sparsity and demonstration bias in robotic manipulation. Conventional VLA-RL paradigms largely depend on binary success signals and costly external process rewards, hindering efficient policy learning and generalization. SRPO proposes a self-referential mechanism: leveraging the model's own in-batch successful trajectories as behavioral references for failed attempts, with progress-wise rewards estimated in a world model latent space. This formulation eliminates the need for expert demonstrations and manual reward engineering, providing dense, transferable learning signals.
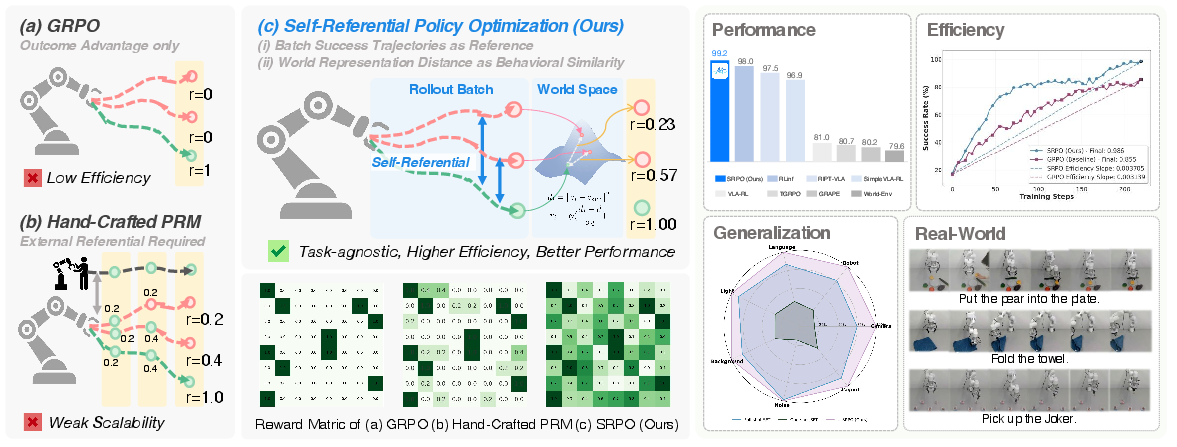
Figure 1: SRPO leverages self-referential progress-wise rewards, synthesizing information from successful rollouts and latent world encodings to overcome sparse and engineered reward approaches.
Methodology
SRPO operates within an episodic RL framework, where the agent receives partial observations and acts toward goals specified in natural language. Unlike sparse outcome rewards or hand-crafted process supervision, SRPO employs a world model encoder, pre-trained on large-scale robotics video, to map both successful and failed trajectory observations into a latent embedding space.
During each RL iteration, SRPO clusters embeddings of successful trajectories via DBSCAN, establishing prototypic behavioral references. Progress-wise reward for any trajectory is modeled as the inverse L2 distance to the nearest reference centroid in latent space, with a smooth activation normalization. This enables gradated credit assignment for failed trajectories based on their closeness to successful behavioral patterns, as opposed to flat penalization.
Policy optimization follows a GRPO-inspired trajectory-level KL-regularized objective, with advantage computed on self-referential batch statistics over world progress rewards, rather than outcome-only supervision.
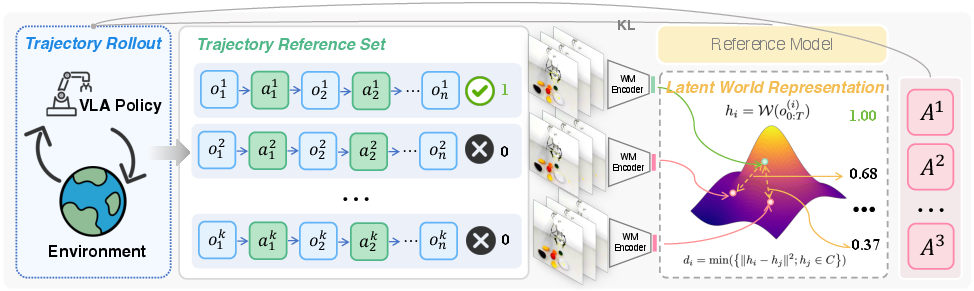
Figure 2: SRPO collects rollouts and computes progress-wise rewards via world model latent encodings and clustering, enabling trajectory-level credit assignment.
Empirical Results
On the LIBERO benchmark, SRPO achieves an average success rate of 99.2% within 200 RL steps, starting from a one-shot SFT baseline of 48.9%. This reflects a 103% relative improvement, without requiring additional expert data or task-specific reward shaping. Furthermore, robustness evaluation on LIBERO-Plus with seven perturbation factors demonstrates a relative improvement of up to 167% over the SFT baseline, outperforming full-shot and multimodal baselines relying on depth, wristcam, or proprioceptive inputs. Notably, this generalization is achieved using only third-view images and language, indicating strong input-efficiency.
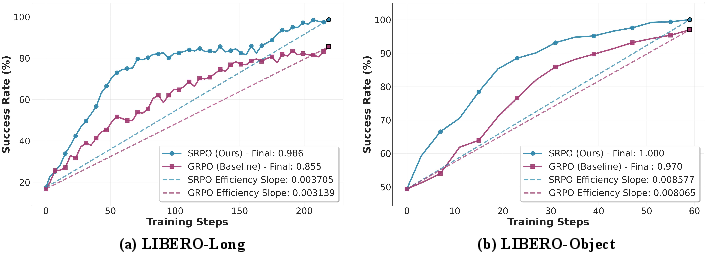
Figure 3: SRPO attains steeper training efficiency slopes than GRPO, particularly in long-horizon and object-centric tasks.
Reward Modeling Analysis
SRPO’s progress reward shows superior monotonicity, temporal correlation, and distribution discriminability compared to pixel-level and ImageBind-based formulations. Quantitative benchmarks on curated success/failure datasets confirm that SRPO’s latent world reward sharply distinguishes consecutive progress and outcome separation.
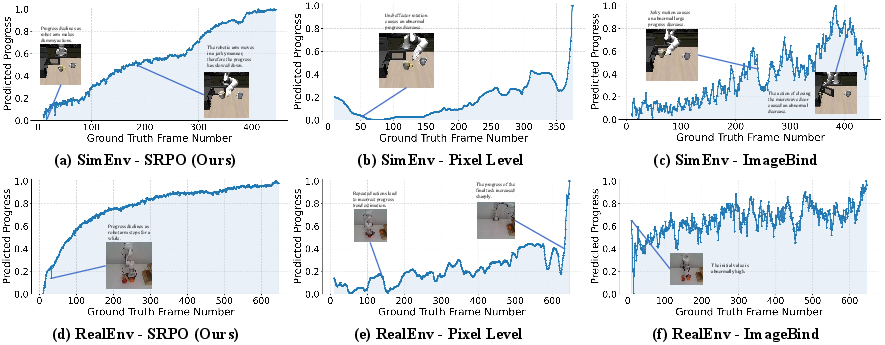
Figure 4: SRPO progress rewards are monotonic and robust, outperforming pixel-level and ImageBind reward models in simulation and real-world domains.
Reward curves for both successful and failed trajectories demonstrate SRPO’s capability to provide smooth, physically plausible signals, further validated by ablation studies on clustering and referential mechanisms. Notably, policy learning with SRPO converges more rapidly and reliably than pixel-level or vision-only encoders, which suffer from perceptual sensitivity and erratic motion-induced artifacts.
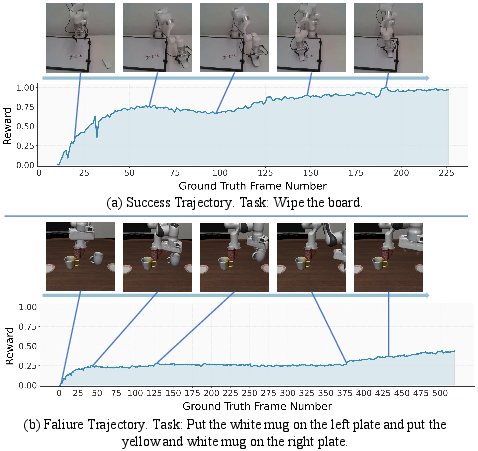
Figure 5: Successful SRPO trajectories show measurable reward growth; failure curves remain stagnant, enabling fine-grained discrimination for RL.
Exploration and Novelty
Analysis of policy-generated action trajectories in spatial manipulation tasks reveals that SRPO-trained agents diversify motor strategies and explore previously unreachable workspace regions, surpassing demonstration-constrained SFT policies.
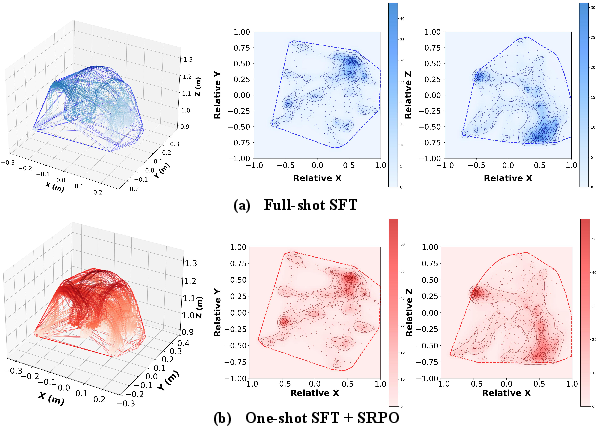
Figure 6: SRPO-trained RL policies explore a broader, more diverse action space than full-shot SFT, enabling novel solutions and increased robustness.
Sim2Real Transfer
Offline RL experiments with SRPO on X-ARM 7 across five real-world tasks—object placement, towel folding, board cleaning, and poker card selection—demonstrate substantial performance gains over SFT baselines (average improvements of +66.8% and +86.7% for diffusion-based and autoregressive policies, respectively). Progress-aware rewards generalize robustly despite domain shift, confirmed by reward quality metrics and consistently high success rates in challenging interaction scenarios.

Figure 7: SRPO demonstrates strong success rates in diverse real-world robotic manipulation tasks.
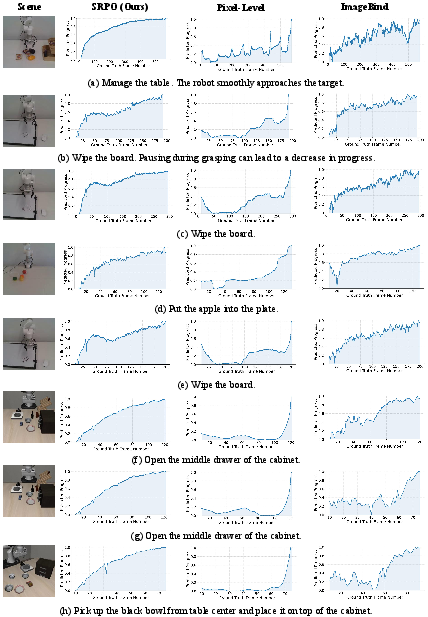
Figure 8: Reward curves of different methods illustrate SRPO’s smooth and accurate progress signals on success trajectories.
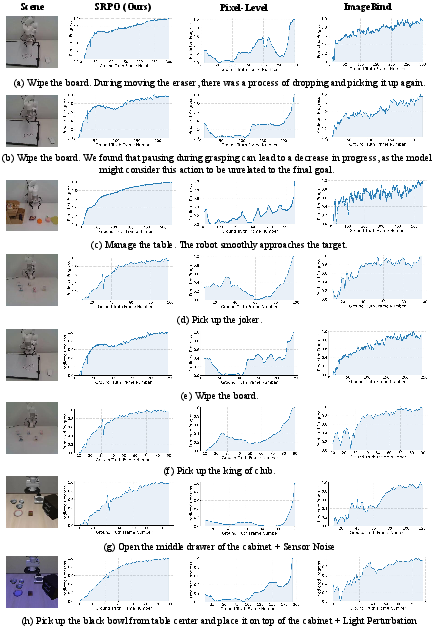
Figure 9: Continued reward curve comparisons validate SRPO’s trajectory-level progress assessment.
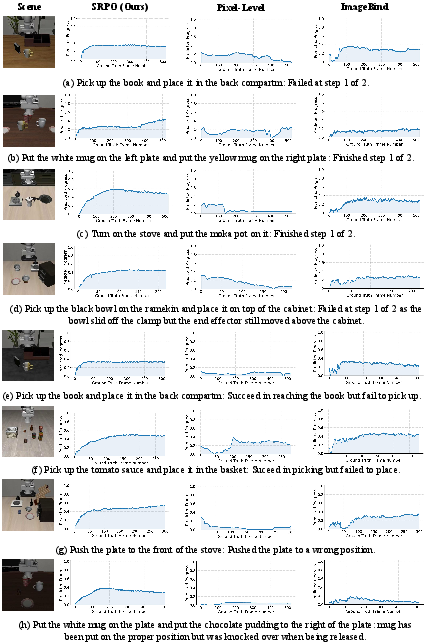
Figure 10: SRPO maintains reliability in discriminating failure scenarios through non-increasing reward trends.
Ablation and Hyperparameter Analysis
Ablation studies confirm that eliminating clustering or the self-referential batch mechanism degrades performance and learning rate. Hyperparameter tuning of the progress reward weighting (α) reveals an optimal balance at α=0.8, maximizing both intermediate guidance and final outcome orientation. Use of external pixel-level world models (e.g., Cosmos-Predict2) for reward synthesis proves suboptimal in practice due to scene inconsistency and computational cost compared to latent representation-based SRPO.

Figure 11: Cosmo-Predict2 reference rollouts demonstrate limitations of pixel-level world modeling as compared to latent SRPO progress rewards.
Implications and Future Directions
SRPO introduces a scalable, task-agnostic RL paradigm for VLA policy optimization, significantly reducing supervision cost while enhancing sample efficiency and generalization. Its latent world progress reward leverages transferable behavioral representations, obviating environment reconstruction and domain-specific encoder fine-tuning. The framework is applicable to both simulation and real-world platforms, opens promising avenues for autonomous, lifelong robotic policy improvement, and is immediately extensible to new tasks without additional expert overhead.
On a theoretical level, SRPO demonstrates the efficacy of self-referential, batch-relative advantage estimation and world progress modeling for RL in high-dimensional observation spaces. The approach is compatible with foundation models and vision-language architectures, suggesting strong potential for continual learning and rapid domain adaptation. Future work may explore hierarchical latent reward modeling and episodic memory integration for more sophisticated credit assignment and exploration incentives.
Conclusion
Self-Referential Policy Optimization (SRPO) provides a principled, efficient, and input-light solution for vision-language-action RL, overcoming demonstration bias, reward sparsity, and poor failure trajectory utilization. By constructing progress-wise rewards in a world model latent space and adopting batch-level self-referential learning, SRPO sets state-of-the-art benchmarks in both simulation and real-world settings. The method generalizes across modality perturbations and enables robust, autonomous skill acquisition, thereby establishing a compelling framework for scalable VLA model development.