- The paper introduces OneReward, a unified RL framework that leverages a VLM-based reward mechanism for versatile and high-performance image editing tasks.
- The paper employs dynamic multi-dimensional reward signals derived from human preference data to provide task-specific feedback without the need for separate models.
- The paper demonstrates through experiments that OneReward outperforms state-of-the-art methods like Ideogram and Adobe Photoshop in usability and visual quality.
"OneReward: Unified Mask-Guided Image Generation via Multi-Task Human Preference Learning" Summary
Introduction
The paper introduces OneReward, a unified RL framework designed to enhance generative model capabilities across several image editing tasks using a single reward model. This framework is remarkable for its adaptability across tasks with varied objectives and evaluation metrics. By leveraging a reward mechanism based on a VLM, OneReward provides versatile feedback that enables models to achieve high performance in tasks like image fill, image extend, object removal, and text rendering. The need for task-specific fine-tuning, which limits broader applicability in existing models, is effectively circumvented by this approach.
The need for a unified model is underscored by the limitations of current diffusion models, which exhibit strengths in specific tasks like image inpainting but falter in others. Existing RLHF methods, such as DPO, grapple with preference order due to conflicting dimension evaluations. ReFL, despite boosting model performance in specified dimensions, is encumbered by separate reward models for different criteria. OneReward consolidates promising aspects of reward-driven learning while circumventing the shortcomings of existing methodologies by embracing a VLM to contextualize task-specific criteria dynamically.
Methodology
The OneReward framework employs a novel multi-dimensional reward model that leverages human preference data collected across diverse image editing tasks. The framework is designed to handle input variability, ensuring coherent and seamless content generation. The VLM-based reward model facilitates nuanced, task-specific feedback without resorting to computationally excessive separate models.
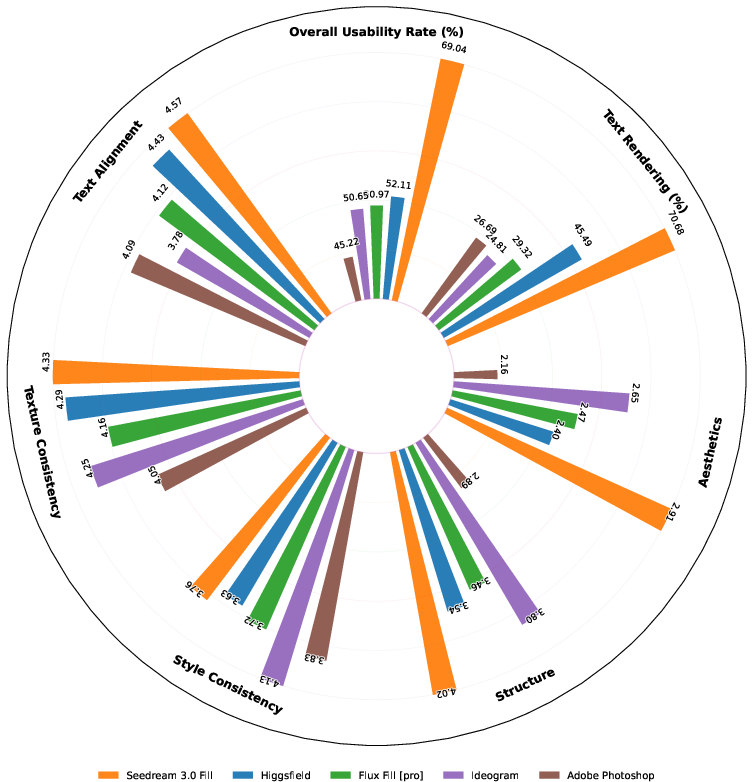
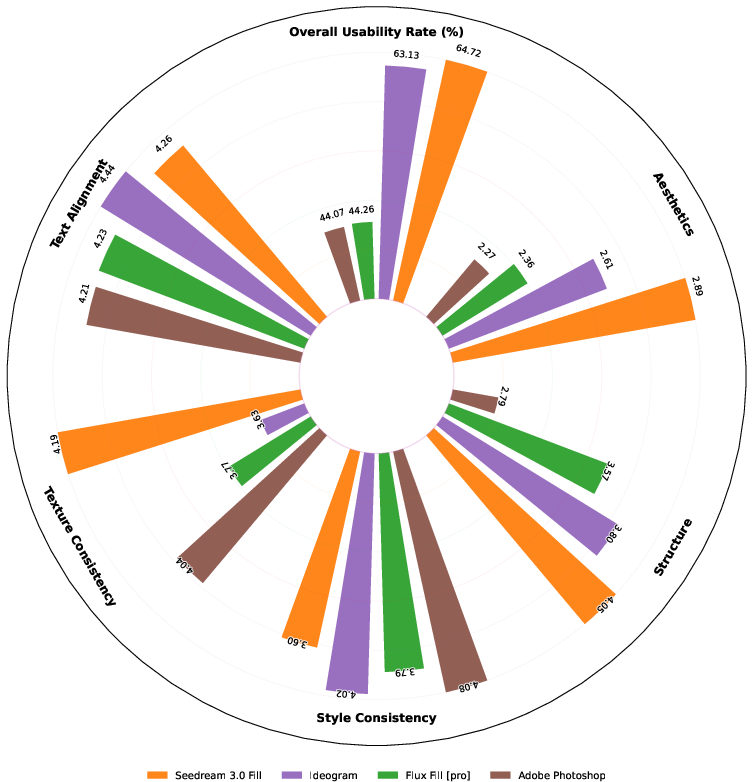
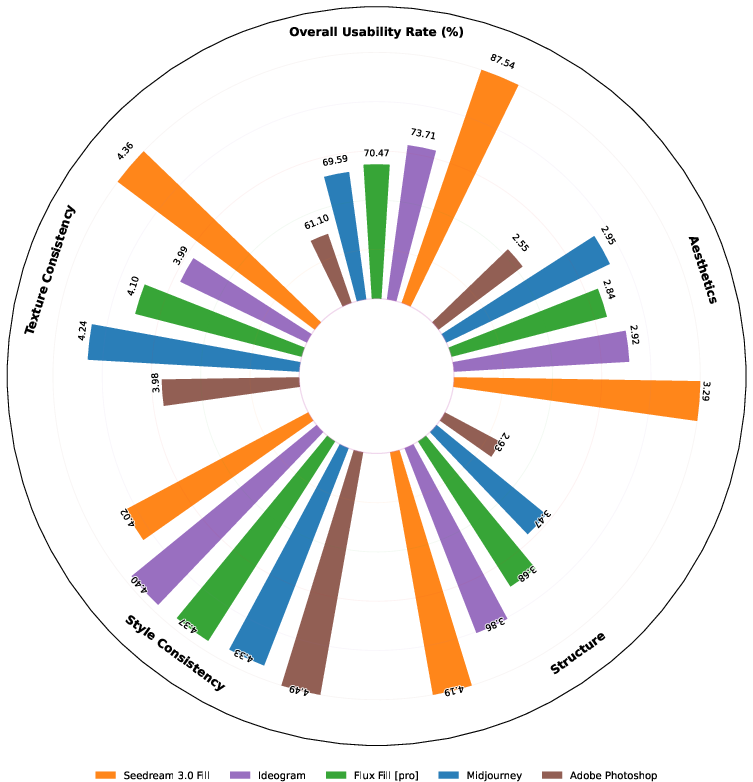
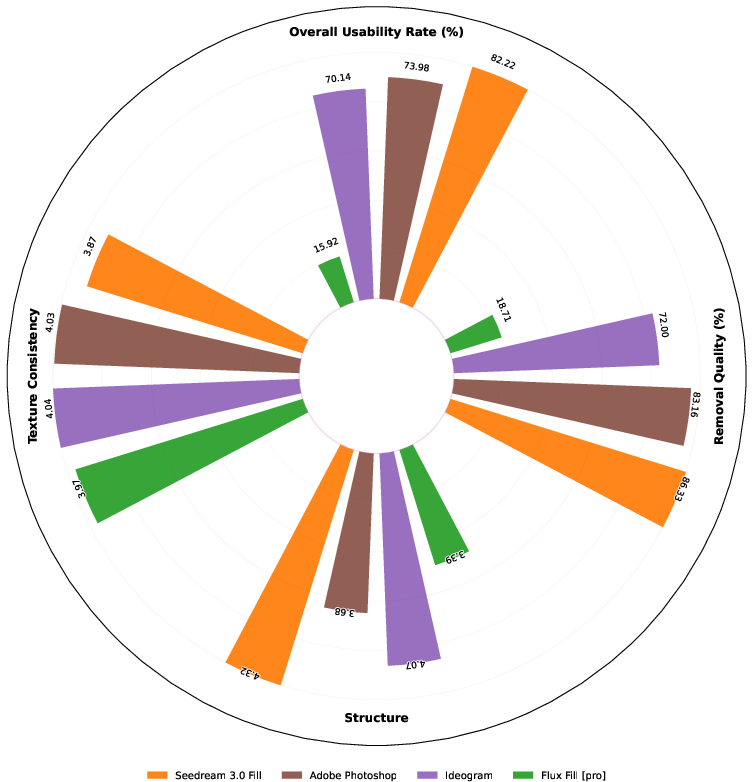
Figure 1: Overall evaluation across four image editing tasks, and text rendering is included in image fill. For each sub-task, we selected only state-of-the-art models or closed-source APIs as competitors and conducted detailed evaluations in multiple dimensions.
The pseudo-reward mechanism motivates efficient optimization by treating the likelihood of a preference token as the reinforcement signal. This supports dynamic adjustment of evaluation criteria across tasks without semantic bias.
Experiments
Experimental results confirm OneReward's capability to outperform contemporary models such as Ideogram, Adobe Photoshop, and Flux Fill in usability and visual quality. The dynamic incentivization strategy in RLHF facilitates robustness in multi-task learning, evident from superior performance indicators such as usability and structural coherence. Exploratory experiments exhibit pronounced capability enhancements when utilizing the dynamic RL framework, meeting and often exceeding benchmarks set by closed-source models.
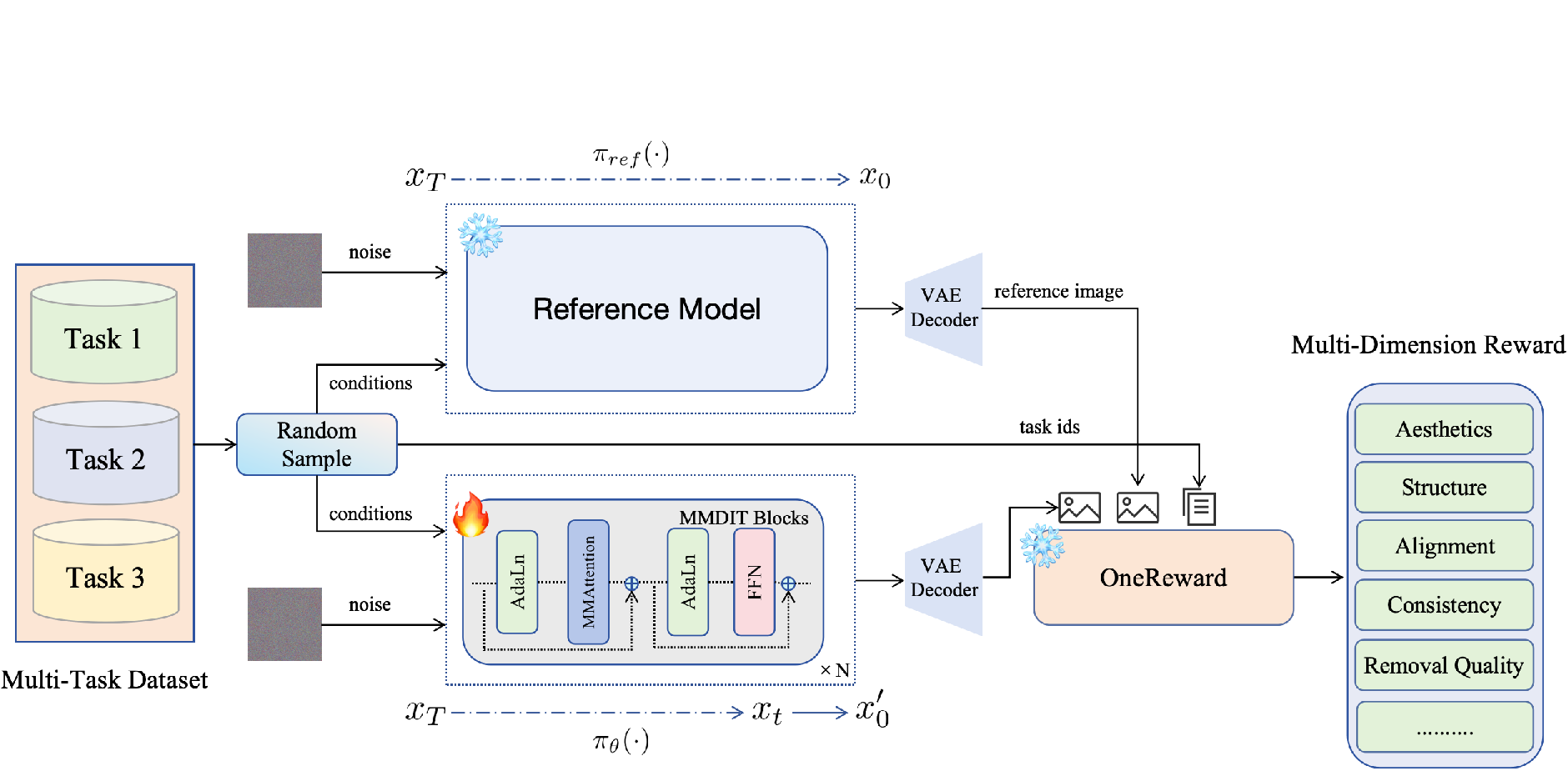
Figure 2: Overall pipeline of our unified RL procedure. We first random sample image and conditions from different tasks with a certain probability...
Conclusions
OneReward emerges as a robust unified framework for guided image generation with demonstrable efficacy in aligning model outputs with complex human preferences across varied tasks. The framework represents a significant advancement over traditional approaches by harmonizing reward-driven learning across multiple generative objectives in a single model. Future explorations might focus on refining the framework to include even more nuanced criteria or adapting the model for broader generative applications beyond immediate image editing tasks.
Implications and Future Work
The success of OneReward signals promising directions in reinforcement learning applications in generative tasks. Future work may capitalize on this approach by integrating even more complex multi-modal task requirements or expanding the model's adaptability to novel task families not traditionally associated with image editing, such as video synthesis or 3D model generation. The unified approach in managing task-specific evaluations can potentially lead to more holistic generative systems, capable of servicing wider creative demands with precise and contextually aware outputs.
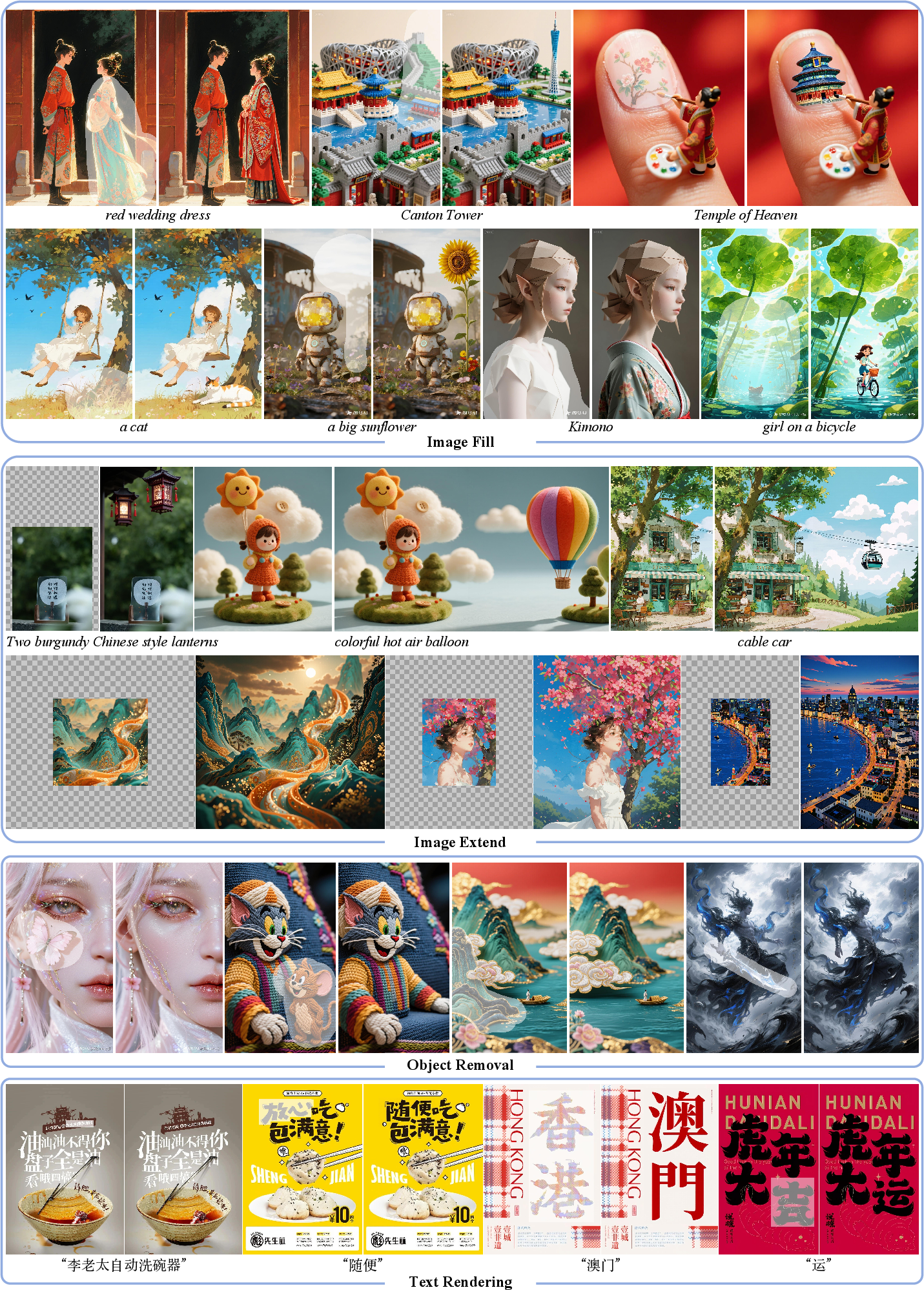
Figure 3: Visual showcase of Seedream 3.0 Fill results across four scenarios: image fill, image extend, object removal, and text rendering. Each column presents a representative example with corresponding prompts and outputs, demonstrating the model's unified capability across diverse generation objectives.