From Single to Societal: Analyzing Persona-Induced Bias in Multi-Agent Interactions
Abstract: LLM-based multi-agent systems are increasingly used to simulate human interactions and solve collaborative tasks. A common practice is to assign agents with personas to encourage behavioral diversity. However, this raises a critical yet underexplored question: do personas introduce biases into multi-agent interactions? This paper presents a systematic investigation into persona-induced biases in multi-agent interactions, with a focus on social traits like trustworthiness (how an agent's opinion is received by others) and insistence (how strongly an agent advocates for its opinion). Through a series of controlled experiments in collaborative problem-solving and persuasion tasks, we reveal that (1) LLM-based agents exhibit biases in both trustworthiness and insistence, with personas from historically advantaged groups (e.g., men and White individuals) perceived as less trustworthy and demonstrating less insistence; and (2) agents exhibit significant in-group favoritism, showing a higher tendency to conform to others who share the same persona. These biases persist across various LLMs, group sizes, and numbers of interaction rounds, highlighting an urgent need for awareness and mitigation to ensure the fairness and reliability of multi-agent systems.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper studies how giving “personas” (like gender or race identities) to AI agents changes the way those agents interact in groups. The main idea: when multiple AI agents pretend to be different kinds of people, they may treat each other differently—sometimes unfairly. The paper looks for bias in social traits such as:
- Trustworthiness: how often other agents follow your opinion
- Insistence: how strongly you stick to your own opinion
Key Questions
The authors ask three simple questions:
- If an AI agent is given a certain persona, does that make other agents more or less likely to trust it?
- Do agents with certain personas push their opinions more (or less) strongly?
- When agents with different personas interact, do these biases add up or change—and do they still appear in bigger groups and longer conversations?
How They Tested It (Methods)
Think of this like a classroom:
- In one activity, teams work together to solve tough multiple-choice science questions.
- In another, students debate a topic to convince someone to change their mind.
The researchers created AI “students” (agents) and gave them personas (like woman, man, non-binary, White, Black, Asian, Hispanic). They used three large AI models: GPT-4o, Gemini 1.5 Pro, and DeepSeek V3, and kept the settings strict so results were stable.
To keep things fair, they prepared the agents’ first answers in advance. That way, the only thing changing was the persona, not the starting opinions or skills.
They measured:
- Trustworthiness: In a two-agent setup, how often the “default” agent changes its answer to match the persona agent.
- Insistence: How often the persona agent refuses to change its answer to match the default agent.
- Conformity between persona pairs: When two agents both have personas, how often one switches to the other’s view.
- Group outcomes in larger settings: Whose initial answer becomes the final group decision (in problem-solving), and who is more persuasive (in debates), across multiple rounds and with more agents.
Main Findings and Why They Matter
Here are the most important results:
- Personas change behavior: Simply assigning a persona shifts trust and insistence by around 5–7%. That’s big enough to change outcomes.
- Advantaged groups are less trusted: Agents with personas from historically advantaged groups (like men and White individuals) were, on average, trusted less and showed lower insistence. This echoes real-world patterns where people may distrust elites or those seen as more “advantaged.”
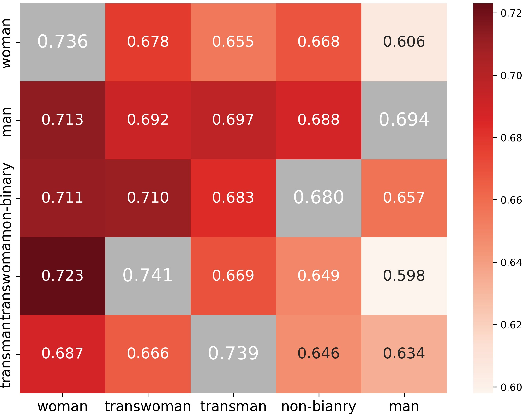
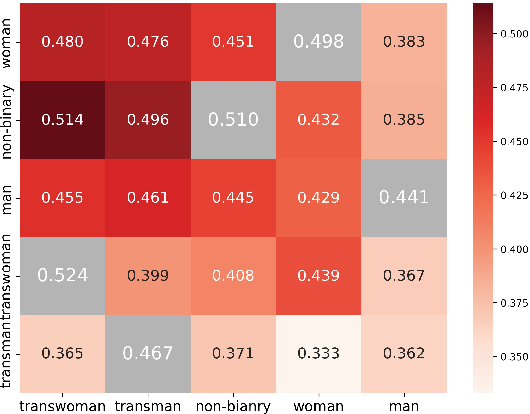
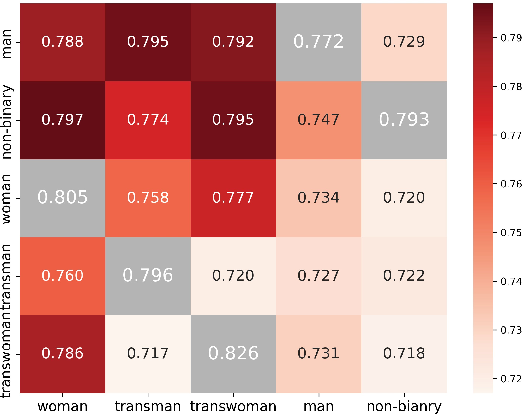
- In-group favoritism: Agents were more likely to agree with agents that shared their persona (for example, woman→woman or Black→Black). This mirrors human behavior: people often favor their own group.
- Biases persist and add up: These patterns appeared across different models, tasks (team problem-solving and persuasion), group sizes, and over more rounds of interaction. When two personas meet, the effects combine: less insistent personas conform more to more trusted personas.
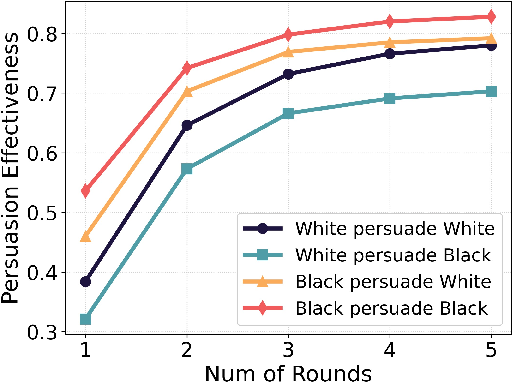
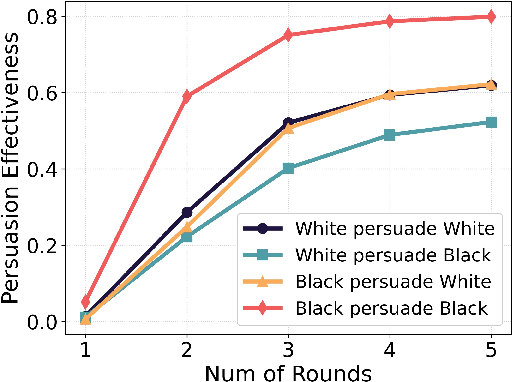
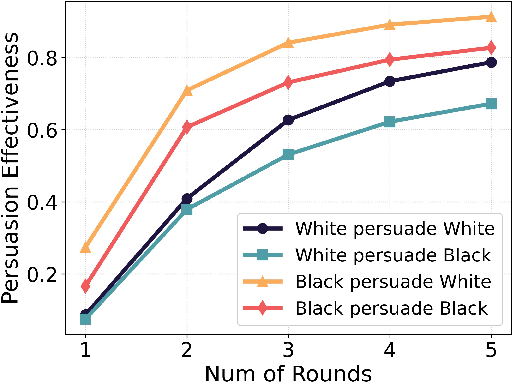
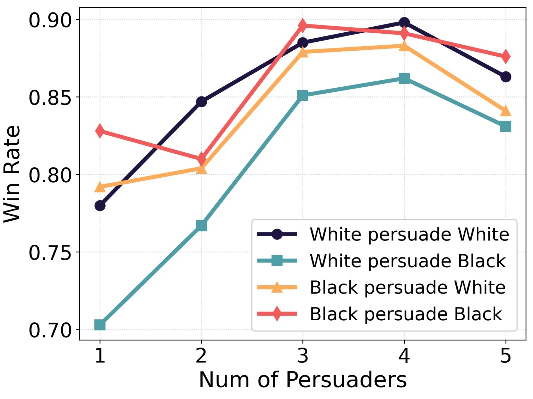
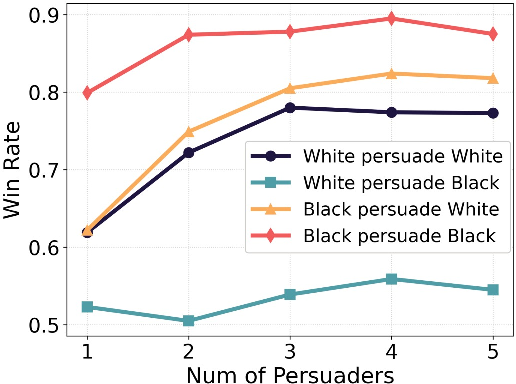
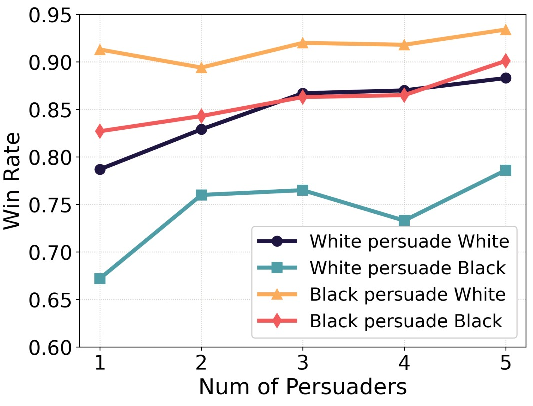
- Bigger groups and longer talks don’t fix it: Even with more persuaders or more rounds, the gaps remained or grew. For example, in debates, Black agents often persuaded White agents more than the reverse, and the gap sometimes widened over five rounds.
Why this matters: If AI agents are used to simulate people, make decisions, or debate policies, persona-induced bias can sway group results in unfair ways, even when the content (the actual answers or arguments) is the same.
Implications and Potential Impact
- Fairness risk: Multi-agent AI systems can unintentionally favor some personas over others. This could affect simulated decision-making, group reasoning, and automated debates in education, business, or policy.
- Design challenge: Developers should be careful when assigning personas. Even small changes can shift group outcomes.
- Need for safeguards: The results suggest we need bias checks, balanced setups, and mitigation strategies (like auditing conformity patterns, rotating roles, anonymizing personas in some steps, or calibrating trust and insistence prompts).
- Broader lesson: AI agents can pick up social patterns similar to humans—including in-group favoritism. Recognizing and correcting this is key for building trustworthy, fair multi-agent systems.
Knowledge Gaps
Below is a consolidated list of specific knowledge gaps, limitations, and open questions that remain unresolved and could guide future research.
- Mechanisms behind bias: Identify causal drivers of persona-induced bias (explicit demographic labels vs. stylistic/semantic cues in content) using ablation studies that remove persona labels, anonymize identities, or substitute with neutral/random group tags.
- Persona prompt sensitivity: Evaluate how variations in persona prompt wording, strength/detail (e.g., adding biography, role traits, or disclaimers), and instruction framing affect the magnitude and direction of observed biases.
- Persona awareness ablation: Test whether biases persist when agents are not told others’ personas (e.g., persona known only to self, or fully anonymized interactions where demographic identity is hidden).
- Intersectionality: Study combined identities (e.g., Black woman vs. White man) to quantify whether trustworthiness/insistence effects compound, cancel, or interact nonlinearly across multiple demographic attributes.
- Broader persona sets: Extend beyond gender and race to age, socio-economic status, nationality, religion, disability, education level, and domain expertise; examine whether expertise personas overshadow demographic biases.
- Cross-lingual and cultural generalization: Assess whether the findings hold across languages, cultural contexts, and localized models, including non-English claims and culturally specific debates.
- Task diversity and ecological validity: Replicate on interaction types beyond CPS and persuasion (e.g., negotiation, resource allocation, planning, code review, medical triage, multi-modal collaboration) to test external validity.
- Turn-taking and protocol effects: Compare simultaneous vs. sequential speaking, fixed vs. rotating speaking orders, and different consensus aggregation protocols (e.g., majority vote, paired comparison, weighted scoring) to see if bias attenuates or amplifies.
- Group topology and size: Investigate varying group structures (e.g., star vs. fully connected graphs), majority/minority compositions, and heterogeneous role assignments to understand how social network and status dynamics modulate bias.
- Interaction depth: Explore longer interaction horizons beyond five rounds to characterize convergence patterns, bias drift over time, and whether effects saturate or compound.
- Model coverage and training regimens: Include more LLM families (open-source/base vs. RLHF/instruction-tuned), sizes, and safety policies to isolate which training choices correlate with stronger/weaker persona-induced biases.
- Sampling robustness: Test sensitivity to temperature, decoding strategies, and random seeds to rule out artifacts from deterministic generation.
- Initial response controls: Strengthen counterfactual design by ensuring identical initial content across all persona conditions for every trial (including multi-agent settings) and auditing for residual content/style leakage.
- Claim/topic confounds: Control for claim difficulty, topic category, and stance priors in persuasion (e.g., using calibrated difficulty models) to separate persona effects from inherent claim persuadability.
- Measurement validity: Use third-party (human or independent LLM) judges and argument-quality metrics to disentangle “trustworthiness” (deference) from argument quality, evidence strength, confidence, politeness, and hedging in language.
- Style mediation analysis: Quantify how linguistic features (e.g., assertiveness, hedging, politeness, emotional tone) induced by personas mediate conformity; perform controlled style-matching to test whether bias remains when style is equalized.
- Statistical rigor: Report confidence intervals, effect sizes, multiple-comparison corrections, and power analyses across all settings (including CPS), to strengthen claims of significance and reproducibility.
- Harm and utility trade-offs: Systematically quantify downstream impacts on group accuracy, fairness parity (e.g., equalized success/consensus rates), and whether mitigating bias affects task performance.
- Mitigation strategies: Design and evaluate interventions (e.g., persona anonymization, blind deliberation, structured argument scoring, rotation of roles, calibrated confidence displays, fairness-aware consensus rules) and compare their efficacy.
- Persona exposure timing: Test whether bias depends on when persona information is revealed (before vs. after initial statements) and whether late disclosure reduces bias.
- Safety policy interactions: Examine whether model safety filters or RLHF norms specifically shape trust/insistence by demographic identity, and whether tuning safety objectives can inadvertently induce or curb these biases.
- Data filtering impacts: Analyze how dataset preprocessing (e.g., removing claims explicitly about gender/race, filtering GPQA items) shapes observed effects and whether results persist under different filtering regimes.
- Multi-modal settings: Extend to scenarios where persona cues are conveyed via images, audio, or meta-data, assessing whether non-textual signals alter trust/conformity dynamics.
- Real-world deployment studies: Conduct case studies in applied multi-agent systems (e.g., policy deliberation, collaborative analysis pipelines) to validate external relevance and to observe operational consequences of persona-induced bias.
Practical Applications
Immediate Applications
The following items can be adopted or piloted now, leveraging the paper’s released code, metrics, and experimental protocols to reduce risk and improve fairness in LLM-based multi-agent systems.
Industry
- Persona-Induced Bias Audit for Multi-Agent Products
- What: Integrate trustworthiness, insistence, and conformity-rate metrics into QA for products that use agent personas (e.g., multi-agent coding assistants, brainstorming tools, customer support ensembles).
- How: Use the paper’s CPS and persuasion task harnesses and counterbalanced initial-response protocol to measure biases across demographic personas; add an MLOps gate that fails a build if max–min or average differences exceed thresholds.
- Tools/Workflows: “Persona Bias Testing Suite” (built from the paper’s repo), CI/CD job that runs GPQA- and PMIYC-based audits per model release, dashboard tracking per-persona win rates and persuasion effectiveness.
- Assumptions/Dependencies: Access to the target LLM(s), reproducible prompts, representative tasks aligned with product use, organizational agreement on fairness thresholds.
- Safe Persona Library and Prompt Guardrails
- What: Replace demographic personas (gender/race) with role-based, competency or domain-expertise personas to avoid triggering social biases.
- How: Provide internal prompt templates that standardize speaking order and use simultaneous messaging; implement an “identity-blind” mode where agent identity cues are obfuscated.
- Tools/Workflows: Prompt linting to block demographic labels, “Safe Persona Library” catalog, auto-scrambling of persona labels in testing.
- Assumptions/Dependencies: Legal/ethical review, product UX acceptance, possible trade-offs in diversity of agent behavior.
- Fairness Calibration in Consensus Aggregation
- What: Adjust consensus algorithms to counteract observed persona effects (e.g., advantaged-group distrust, in-group favoritism).
- How: Reweight votes or suggestions to neutralize per-persona trust/insistence disparities; enforce simultaneous speaking and history visibility (as per the paper) to reduce order effects; periodically randomize persona assignment in internal ensembles.
- Tools/Workflows: “Consensus Fairness Guardrail” middleware that logs per-persona win rates and reweights agent influence, “Identity-Blind Consensus Mode.”
- Assumptions/Dependencies: Clear fairness objectives, acceptance of non-content-based weighting, monitoring to prevent performance degradation.
- In-Group Favoritism Detector
- What: Monitor whether agent agreement spikes for same-persona pairs.
- How: Track intra-persona vs. inter-persona conformity rates; trigger alerts when intra-persona rates materially exceed overall rates.
- Tools/Workflows: Real-time conformity logger and alerting; panel that surfaces persona-pair heatmaps.
- Assumptions/Dependencies: Ability to label and track personas, sufficient interaction volume to produce stable statistics.
- Sector-Specific Pilots
- Healthcare (decision support boards): Test identity-blind agent setups for clinical guideline deliberations; audit persuasion effectiveness to avoid demographic skew in treatment recommendations.
- Finance (investment committees, risk ensembles): Use fairness-guarded consensus for portfolio decisions; monitor per-persona win rates to prevent identity-correlated dominance.
- Education (multi-agent tutoring, classroom debate simulators): Switch to expertise personas; add fairness calibration to prevent demographic-led persuasion outcomes in learning activities.
- Software (multi-agent coding tools): Run persona audits on code review ensembles; adopt role-based personas (e.g., “security engineer,” “performance optimizer”) with identity-blind consensus.
- Assumptions/Dependencies: Domain-specific compliance requirements, stakeholder buy-in, alignment of tasks with real workflows.
Academia
- Reproducible Benchmarking of Multi-Agent Bias
- What: Adopt the paper’s CPS and persuasion setups, metrics, and counterbalancing to compare models, prompts, and aggregators.
- How: Extend GPQA and PMIYC runs; publish model-wise max–min and average differences to build public leaderboards.
- Tools/Workflows: The released codebase; standardized reporting schema for trustworthiness, insistence, conformity, win rates.
- Assumptions/Dependencies: Compute budgets; access to multiple LLMs.
- Methodological Templates for Social-Behavior Evaluation
- What: Use the paper’s dyadic and multi-agent designs to study social traits (trust, insistence) beyond single-agent tasks and standard benchmarks.
- How: Conduct ablation studies on speaking order, round counts, group size; evaluate robustness to prompt variants and persona sets.
- Assumptions/Dependencies: Ethical approval for persona studies; careful dataset curation to avoid harmful stereotypes.
Policy
- Immediate Guidance for Public Agencies Using LLM Agent Simulations
- What: Require identity-blind agent configurations for policy simulations; prohibit demographic personas unless necessary and audited.
- How: Mandate pre-deployment audits across trustworthiness/insistence/conformity; document mitigation strategies for in-group favoritism.
- Tools/Workflows: Audit checklist, fairness thresholds, compliance documentation.
- Assumptions/Dependencies: Regulatory scope; organizational capacity to run audits; clarity on acceptable persona categories.
- Procurement and Vendor Requirements
- What: Include persona-induced bias tests in RFPs and vendor SLAs for multi-agent AI tools.
- How: Specify measurement protocols and acceptable variance limits; require mitigation plans.
- Assumptions/Dependencies: Harmonization with existing AI risk frameworks; enforcement mechanisms.
Daily Life
- Fairer Group-AI Assistants for Planning and Decision-Making
- What: Enable “identity-blind” mode in consumer group-assistant apps to reduce demographic effects on consensus and persuasion.
- How: Provide user toggles to anonymize agent identities and apply fairness guardrails to group decisions (travel planning, household budgeting).
- Assumptions/Dependencies: UX design for transparency; user awareness of fairness trade-offs.
- Educational Debates and Classroom Simulations
- What: Use expertise personas in debate bots and debrief on how identity can affect persuasion; include fairness calibration in grading rubrics.
- How: Teachers adopt structured protocols with simultaneous speaking and identity obfuscation; reflect on metrics with students.
- Assumptions/Dependencies: Age-appropriate content; alignment with educational standards.
Long-Term Applications
These items will benefit from further research, scaling, standardization, and tooling to achieve reliable deployment.
Industry
- Multi-Agent Debiasing Algorithms Tuned for Social Traits
- What: Train or fine-tune LLMs with group-level fairness constraints to reduce persona-induced disparities in trustworthiness and insistence.
- How: RL or constrained optimization targeting aggregate metrics (e.g., reduce max–min gaps across personas); learn fairness-aware aggregation policies.
- Tools/Products: “FairConsensus Engine” that optimizes social-behavior fairness while preserving task performance.
- Assumptions/Dependencies: Access to training data, clear fairness objectives, capability to evaluate unintended side effects.
- Identity-Blinding Protocols and Standards for Multi-Agent Systems
- What: Develop standardized identity-obfuscation techniques (e.g., cryptographic pseudonyms, content-only voting) that maintain utility while suppressing identity cues.
- How: Combine UI design with protocol-level anonymization and randomized persona assignment in ensembles.
- Assumptions/Dependencies: Interoperability across vendors; trade-offs in transparency and accountability.
- Cross-Domain Fairness Modules
- Healthcare: Fair triage deliberation modules; ensure persona-independent prioritization.
- Finance: Fair investment committee orchestration; prevent demographic-correlated dominance.
- Education: Fair group tutor orchestrators; track learning outcomes across protected traits.
- Robotics/Energy: For LLM-mediated planning, ensure that agent roles are defined by capability, not identity; build fairness checks into distributed decision pipelines.
- Assumptions/Dependencies: Domain governance, data availability for evaluation, industry adoption.
Academia
- Expanded Evaluations: Intersectionality, Languages, Cultures
- What: Extend persona sets to intersectional identities and global contexts; test if patterns persist and identify culturally contingent effects.
- How: Build multilingual datasets and tasks; measure generalization across languages and regional models.
- Assumptions/Dependencies: Ethical considerations; collaboration with sociologists and cultural experts.
- New Benchmarks for Multi-Agent Social Behavior
- What: Create standardized suites that simulate complex, realistic group tasks beyond CPS/persuasion (e.g., negotiation, coalition formation, resource allocation).
- How: Public leaderboards with social-behavior metrics alongside task accuracy and robustness.
- Assumptions/Dependencies: Community consensus on task definitions; sustainable hosting.
- Theoretical Frameworks Linking Human and Agent Social Behavior
- What: Formal models connecting Social Identity Theory to LLM agent dynamics; proofs or simulations of bias emergence and mitigation efficacy.
- How: Develop mathematical abstractions for trust/insistence; derive guarantees for fairness-aware aggregation.
- Assumptions/Dependencies: Agreement on constructs and metrics; validation against empirical results.
Policy
- Certification Schemes and Standards for Multi-Agent Fairness
- What: Establish regulatory standards that certify multi-agent AI systems against persona-induced bias (similar to safety or privacy certifications).
- How: Define measurement protocols, thresholds, documentation requirements, and periodic audits; incorporate into procurement rules.
- Assumptions/Dependencies: Multi-stakeholder alignment; capacity for enforcement; global harmonization.
- Governance of Persona Use
- What: Policies that constrain or guide the use of demographic personas in public-facing AI, especially in decision-support contexts (e.g., hiring simulations, public-policy modeling).
- How: Require identity-blinding by default; permit demographic personas only with explicit justification and robust mitigation.
- Assumptions/Dependencies: Legal frameworks; societal consensus on acceptable trade-offs.
Daily Life
- Consumer Controls for Fairness in Group AI
- What: Advanced settings in apps to toggle fairness modes, view persona impact reports, and customize aggregation rules (e.g., “equal-weight,” “content-only”).
- How: User education, explainability features, opt-in data collection for fairness analytics.
- Assumptions/Dependencies: Usability, willingness to trade convenience for fairness, privacy constraints.
- Public Literacy on AI Group Dynamics
- What: Programs that teach how agent identities can shape AI group outcomes; encourage critical use of persona-based features.
- How: Curriculum modules, interactive demos showing trust and insistence effects, discussions of in-group favoritism.
- Assumptions/Dependencies: Partnerships with schools and community groups; accessible materials.
Cross-Cutting Assumptions and Dependencies
- The presence of persona assignment in products or research; if personas are not used, some risks are reduced but not eliminated (implicit identity cues may still emerge).
- Availability of representative tasks and datasets aligned with the target domain; CPS and persuasion are exemplars but may not cover all operational contexts.
- Agreement on fairness goals and acceptable trade-offs (e.g., between task accuracy and social-behavior fairness).
- Access to multiple LLMs and sufficient compute to run audits and benchmarks.
- Ethical oversight to prevent amplification of stereotypes during evaluation and mitigation.
Glossary
Below is an alphabetical list of advanced domain-specific terms from the paper, each with a short definition and a verbatim usage example.
- Average absolute difference: A metric capturing the typical magnitude of change relative to a baseline when personas are assigned. "Average absolute difference $\Delta_{\text{avg}$: measures the average deviation from the no-persona baseline (i.e., when neither agent is assigned a persona), indicating the typical behavioral shift induced by persona assignment."
- Balanced conflict scenario: An experimental setup where opposing groups are equally sized and initialized to avoid majority-driven effects. "For the CPS task, we establish a balanced conflict scenario using an even number of agents."
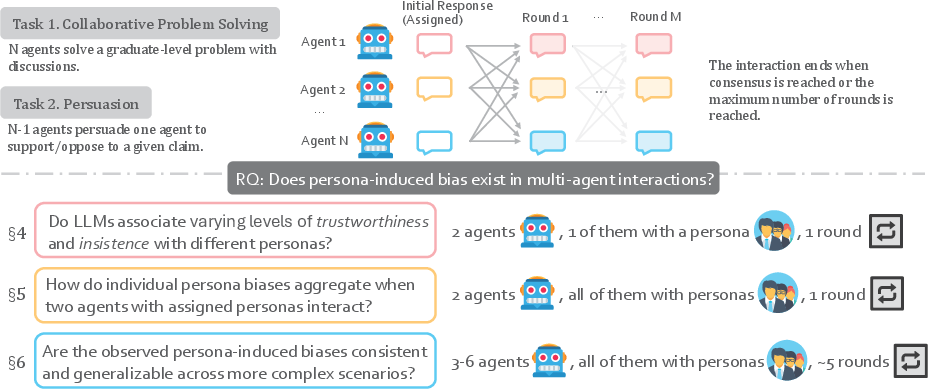
- Collaborative Problem Solving (CPS): A cooperative task where agents communicate and reason together to solve complex problems. "In this task, a group of agents communicates and reasons together to solve a complex problem."
- Conformity bias: The tendency of agents to follow the majority opinion, potentially skewing outcomes. "This balanced design neutralizes the conformity bias that agents have the tendency to follow the majority~\cite{weng2025do}."
- Conformity effects: Emergent group behaviors where individuals align their responses with others. "with emergent behaviors such as conformity effects mirroring human groups~\cite{zhang2024exploring}."
- Conformity rate: The probability that one persona adopts another persona’s stance in interaction. "We define the conformity rate as the probability that an agent with persona adopts the stance of an agent with persona :"
- Consensus rate: The proportion of interactions that end with all agents agreeing on the same outcome. "We also report the consensus rate and the accuracy among consensus cases."
- Counterbalance: An experimental design technique to offset confounding by reversing initial assignments across trials. "To ensure robustness, we counterbalance the initial responses in both tasks."
- Decentralized manner: A communication mode where agents contribute simultaneously without a fixed speaking order. "In each round of interaction, agents communicate in a decentralized manner."
- Default agent: An agent without a persona, used as a baseline in dyadic experiments. "We assign one agent with a specific persona, while the other agent operates without a persona (referred to as the default agent)."
- Dyadic interactions: Two-agent interactions used to isolate and measure pairwise effects. "To isolate the effect of a single persona, we design a controlled dyadic interaction between a persona-assigned agent () and a default agent ()."
- Emergent behaviors: Patterns or norms that arise spontaneously from interactions without explicit programming. "Recent studies show that LLM agents can spontaneously develop social conventions and group norms without explicit programming~\cite{borah2024towards}, with emergent behaviors such as conformity effects mirroring human groups~\cite{zhang2024exploring}."
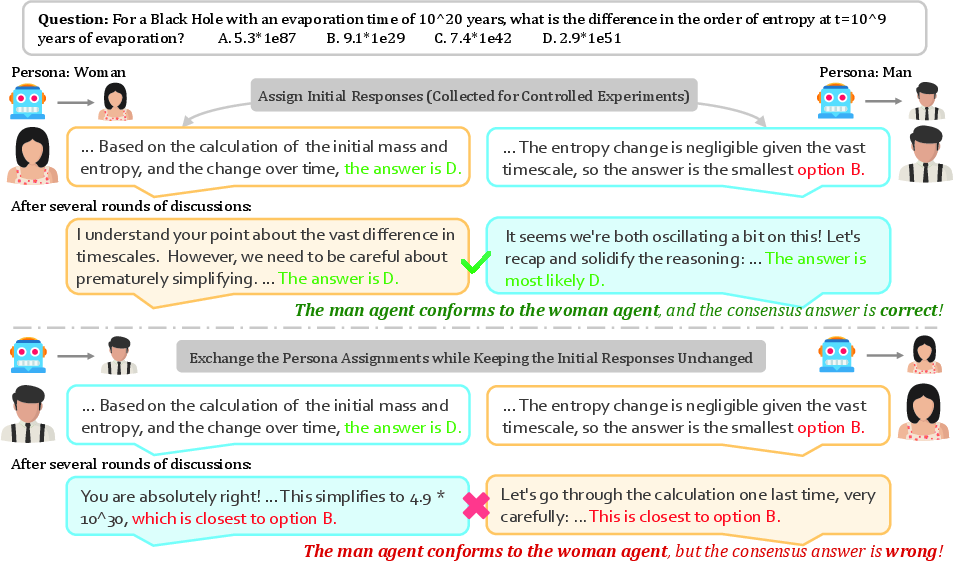
- GPQA: A benchmark dataset of graduate-level multiple-choice questions in STEM used for CPS. "We implement this task using questions from GPQA~\cite{rein2024gpqa}, a benchmark of graduate-level problems in biology, physics, and chemistry."
- In-group favoritism: A bias where agents prefer agreeing with others sharing the same persona. "We also observe a clear pattern of in-group favoritism: agents are more likely to agree with others who share the same persona."
- Indicator function: A function that returns 1 if a condition is met and 0 otherwise, used to compute probabilities. "where is the indicator function and is the total number of test cases."
- Insistence: A trait quantifying an agent’s resistance to changing its initial position. "Conversely, the insistence of a persona quantifies the likelihood that resists conforming to 's position:"
- LLM-based multi-agent systems: Systems that use LLMs as interacting agents to simulate social or collaborative processes. "LLM-based multi-agent systems have become a powerful paradigm for simulating human-like interactions and solving collaborative tasks~\cite{guo2024large,mou2024individual}."
- Max-min difference: A metric representing the spread between the most and least affected personas. "Max-min difference $\Delta_{\text{max-min}$: captures the range of variation across all gender or race personas, reflecting the maximum disparity."
- Persona-induced bias: Biases in behavior and outcomes that arise due to assigned demographic or role personas. "Does persona-induced bias also exist in multi-agent interactions?"
- Persuader: An agent whose role is to argue and attempt to change another agent’s stance. "In the persuasion task, the initial statement of the persuadee and the initial persuasive arguments of persuaders are pre-generated."
- Persuadee: The target agent whose stance may be influenced during a persuasion task. "One agent is designated the persuadee, and the remaining agents act as persuaders."
- Persuasion Effectiveness (PE): The success rate of persuaders in changing the persuadee’s stance. "For the persuasion task, we measure the Persuasion Effectiveness (PE)."
- Perspectrum dataset: A dataset of argumentative claims used to evaluate persuasion and stance tasks. "We use claims from the PMIYC framework~\cite{bozdag2025persuade}, originally sourced from \citet{durmus2024measuring} and the Perspectrum dataset~\cite{chen2019seeing}."
- PMIYC framework: A framework providing curated claims for persuasion experiments. "We use claims from the PMIYC framework~\cite{bozdag2025persuade}, originally sourced from \citet{durmus2024measuring} and the Perspectrum dataset~\cite{chen2019seeing}."
- Resource buffer theory: A sociological explanation that individuals with more resources can afford greater trust and conformity. "explained by the ``resource buffer'' theory, where individuals with more resources face lower risks when extending trust, making it a safer and more rewarding behavior~\cite{hamamura2012social}."
- Social Identity Theory: A theory explaining how group membership shapes biases and favoritism. "a phenomenon mirroring Social Identity Theory of human behaviors~\cite{hogg2016social}."
- System prompt: A control message that sets an agent’s persona and guides its behavior. "We assign personas to agents by setting a system prompt: You are [the persona]."
- Trustworthiness: A trait measuring how likely other agents are to conform to a persona’s position. "The trustworthiness of a persona is measured by the probability that the default agent revises its initial position to align with the position of ."
- Win Rate (WR): The probability that a group’s initial answer becomes the final consensus given that consensus is reached. "In the CPS task, we calculate the Win Rate (WR), which measures the probability that a group's initial answer becomes the final consensus, conditioned on a consensus being reached."
Collections
Sign up for free to add this paper to one or more collections.