- The paper introduces EmotionCLIP, a novel framework that reformulates EEG-based emotion recognition as an EEG-text matching problem to improve cross-domain accuracy.
- It utilizes a dual-encoder design combining a customized EEG encoder (SST-LegoViT) and a CLIP text encoder to extract comprehensive spatio-temporal-frequency features.
- Experimentally, EmotionCLIP achieved 88.69% on SEED and 73.50% on SEED-IV under cross-subject tests, outperforming state-of-the-art models.
Cross-domain EEG-based Emotion Recognition with Contrastive Learning
Introduction
The paper, "Cross-domain EEG-based Emotion Recognition with Contrastive Learning" (2511.05293), introduces an innovative approach to emotion recognition using electroencephalogram (EEG) signals. Utilizing EEG signals for emotion recognition has gained traction due to their direct reflection of brain activity, which is less manipulable than other modalities like facial expressions and speech. The presented approach, EmotionCLIP, aims to address challenges existing in EEG-based emotion recognition, particularly in feature extraction and cross-domain generalization. By transforming the emotion recognition task into an EEG-text matching problem within the CLIP framework, the method endeavors to improve recognition accuracy across different subjects and temporal contexts.
Model Architecture
EmotionCLIP Framework
EmotionCLIP harnesses the capabilities of a contrastive learning approach to enhance the alignment between EEG signal features and text embeddings representing emotional labels. This reformulation leverages textual emotion descriptions as a stable modality, enabling more consistent recognition across different individuals and sessions. The dual-encoder setup comprises a Text Encoder and a customized EEG Encoder, SST-LegoViT. This architectural choice focuses on maximizing the cosine similarity between EEG features and their corresponding text representations, thereby fostering robust emotional prediction accuracy.
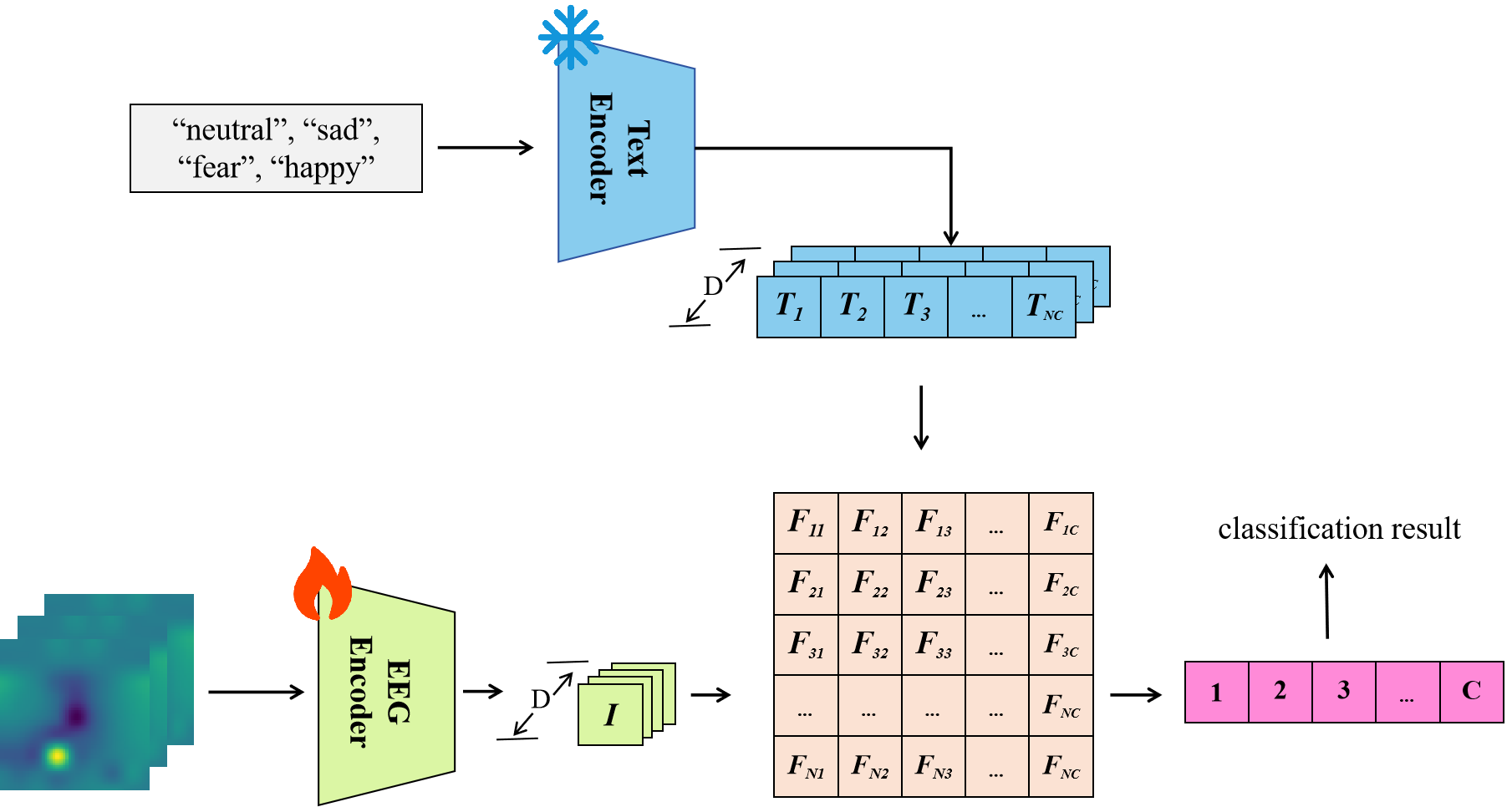
Figure 1: EmotionCLIP transforms the cross-domain emotion recognition task from a classification problem to an EEG-Text matching problem.
Text Encoder
The Text Encoder utilizes the pre-trained CLIP text encoder to generate rich semantic embeddings from emotion labels integrated into 16 distinct prompt templates. This architectural design ensures that emotion labels are represented in contextually meaningful phrases, augmenting semantic richness and reducing ambiguity inherent in using single-word labels.
EEG Encoder
The EEG Encoder, termed SST-LegoViT, is tailored to extract comprehensive spatio-temporal-frequency features from EEG signals. The encoder processes spatial, frequency-band, and temporal data sequentially, allowing for the construction of detailed 4D EEG representations. Through channel mapping and frequency segmentation, SST-LegoViT produces finely-tuned feature embeddings. It employs multi-scale convolution modules and parallel Transformer encoders to capture diverse spatial features and facilitate the fusion of DE and PSD features.
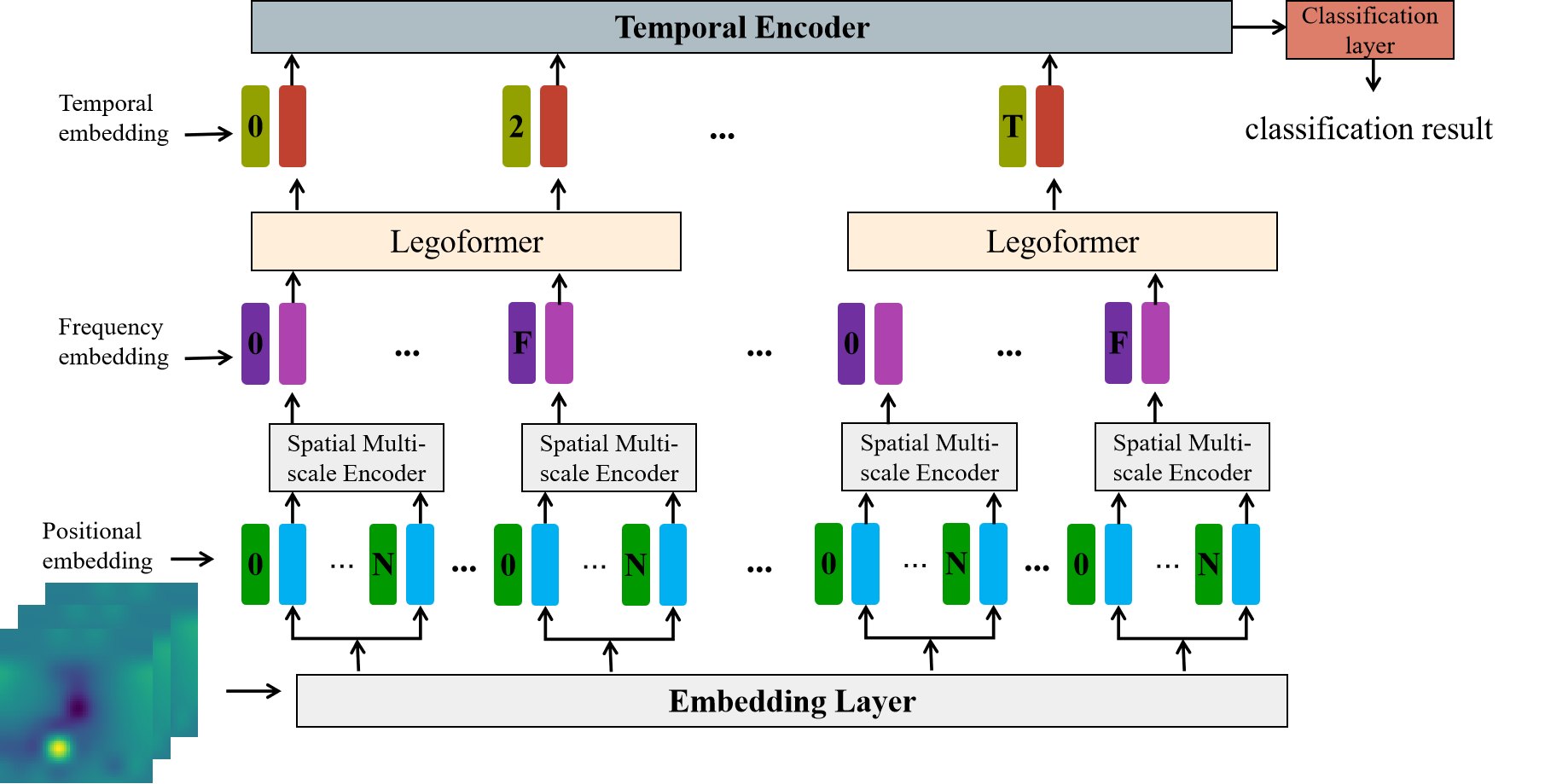
Figure 2: EEG Encoder sequentially processes spatial, frequency-band, and temporal information from a 4D EEG representation.
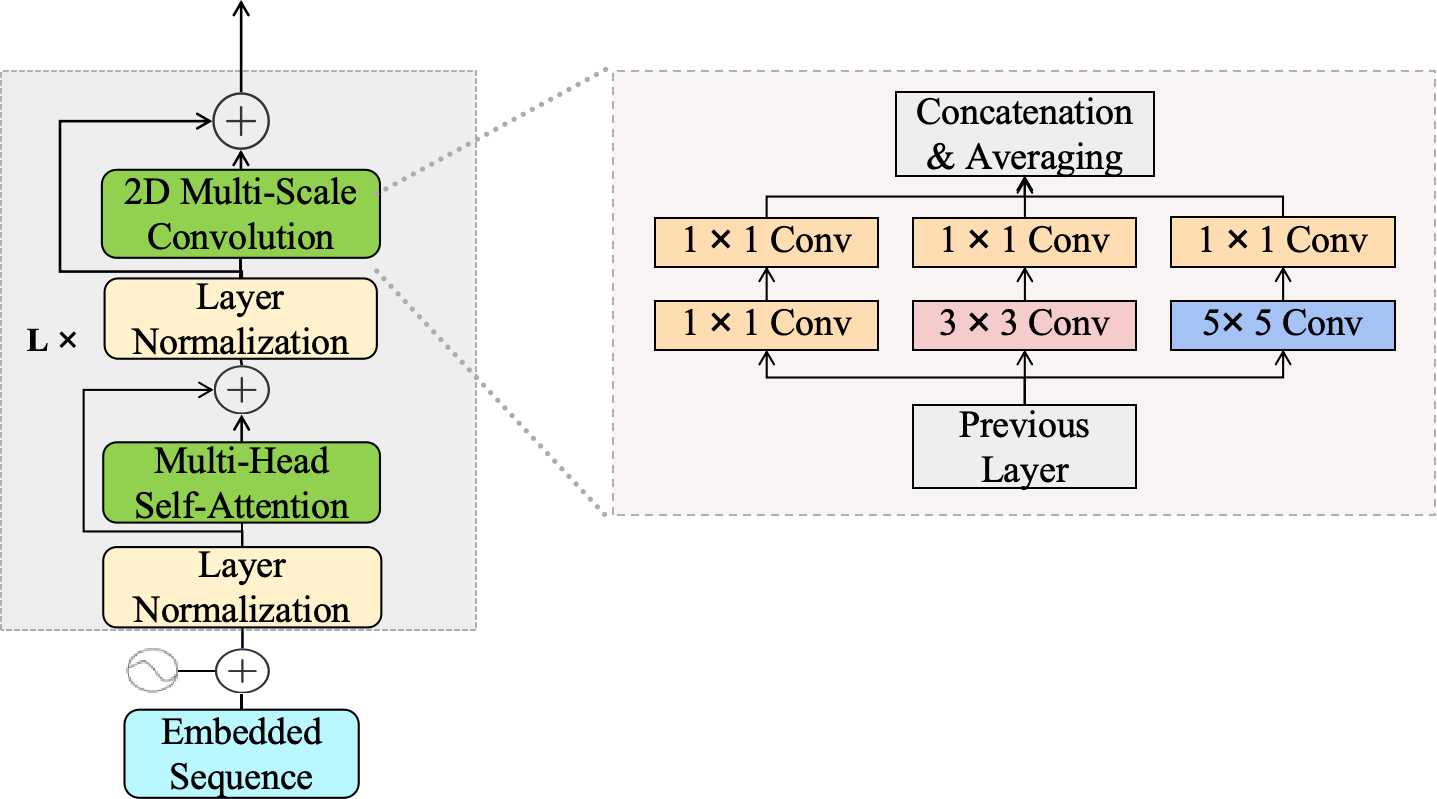
Figure 3: Spatial Multi-scale Encoder aggregates multi-resolution features to enhance spatial representation across varying scales.
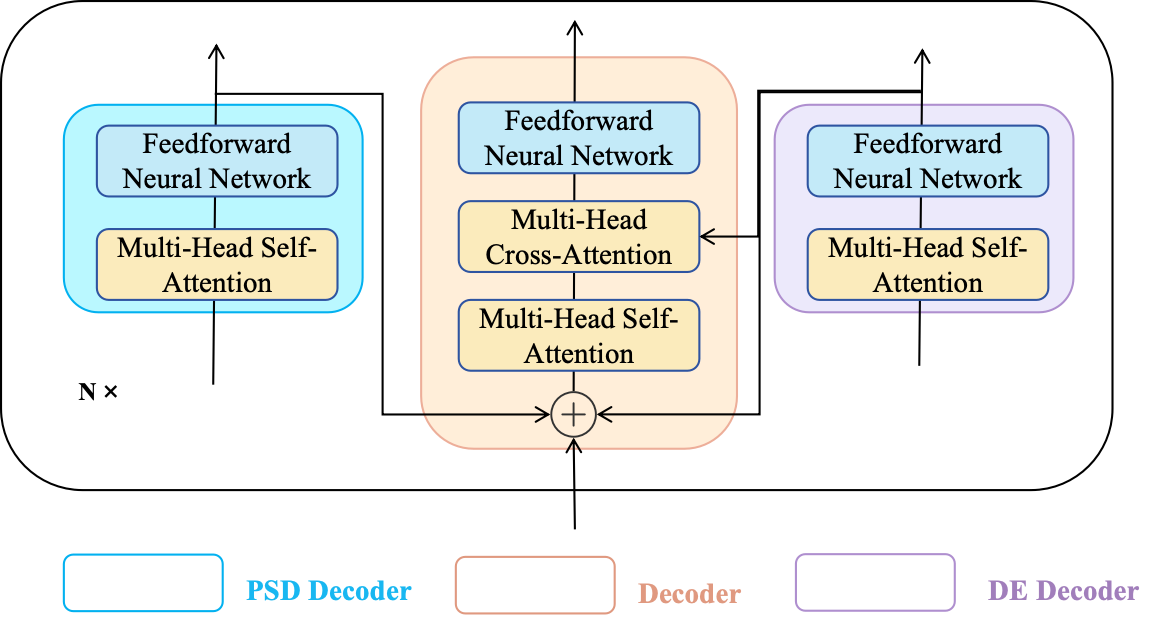
Figure 4: LegoFormer processes DE and PSD features through parallel encoders. Fuses them via cross-attention, using DE as the primary context to guide auxiliary PSD information.
Results and Evaluation
Datasets and Protocols
The experimental evaluation leveraged the SEED and SEED-IV datasets, commonly employed in EEG emotion recognition studies. The robustness of the EmotionCLIP model was tested under the leave-one-subject-out (LOS) protocol and cross-time validation, examining its capability for cross-domain generalization. The applied strategies demonstrate the applicability of EmotionCLIP in real-world scenarios where subject variability and domain shifts are prevalent.
EmotionCLIP achieved superior performance in cross-subject and cross-time tests, demonstrating enhanced generalization capabilities compared to existing state-of-the-art models. In cross-subject recognition, EmotionCLIP recorded accuracies of 88.69% on SEED and 73.50% on SEED-IV, outperforming models like MSFR-GCN and MADA. These results underscore the effectiveness of leveraging multimodal contrastive learning frameworks in improving EEG emotion recognition.
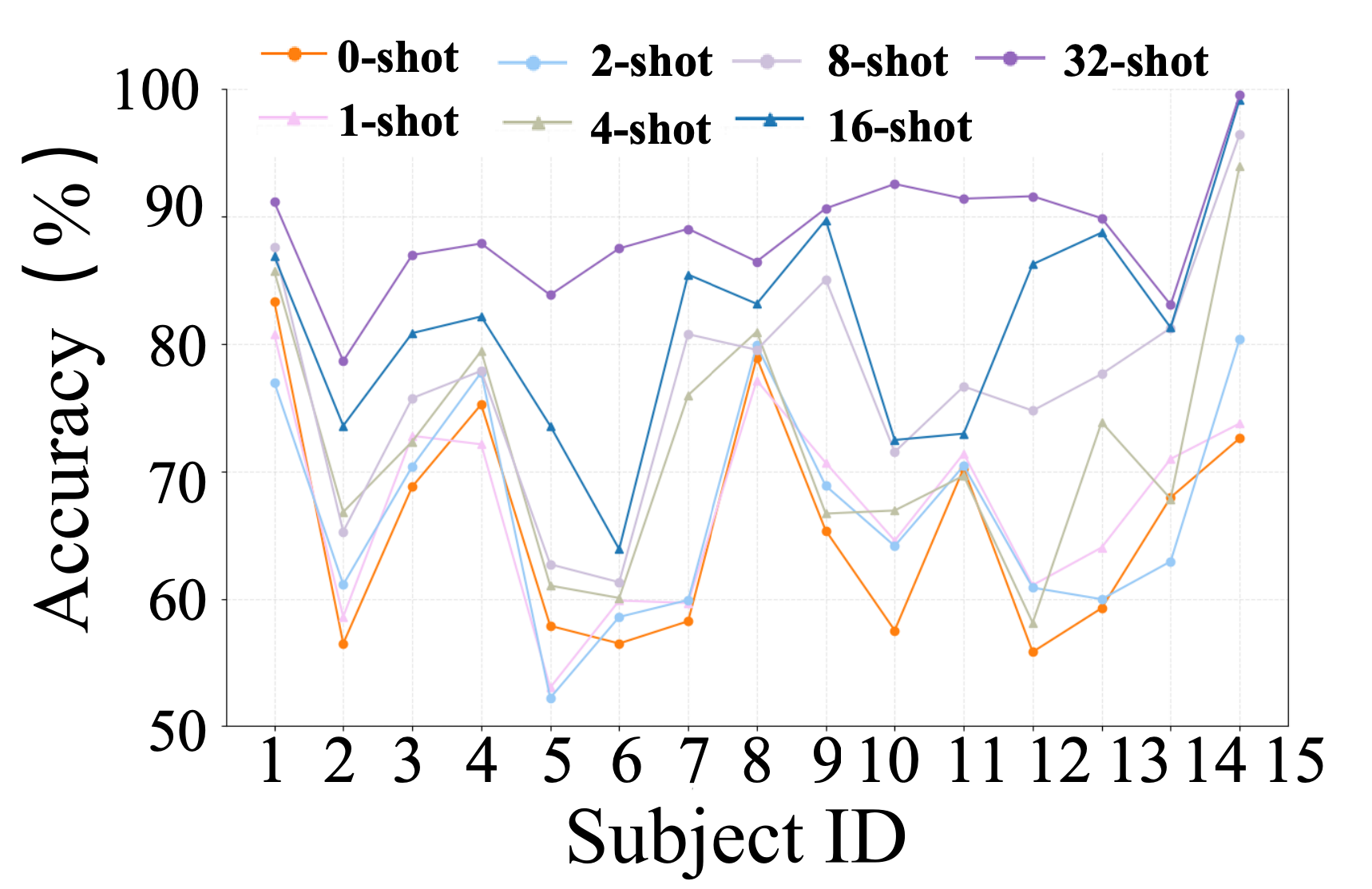
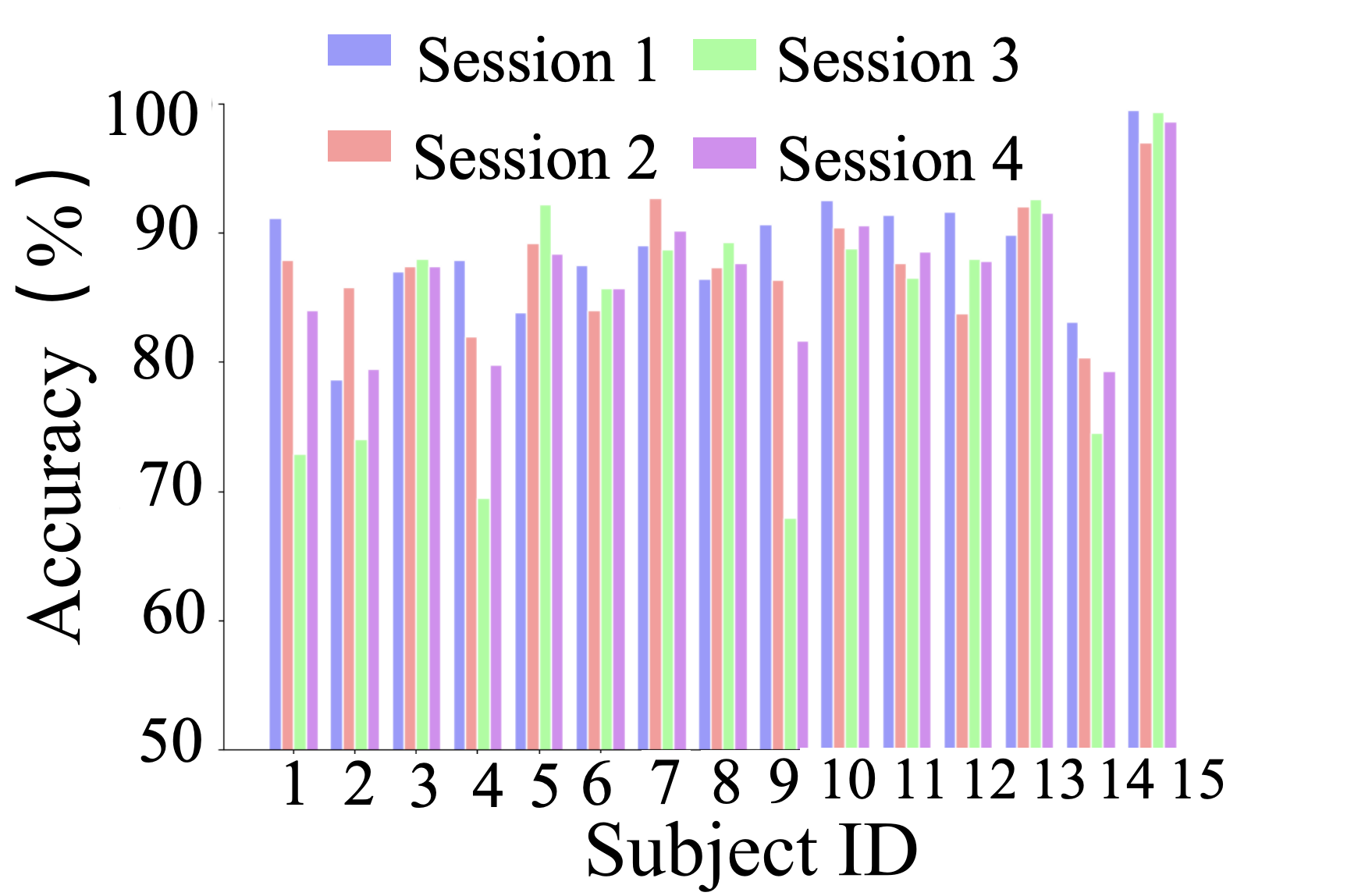
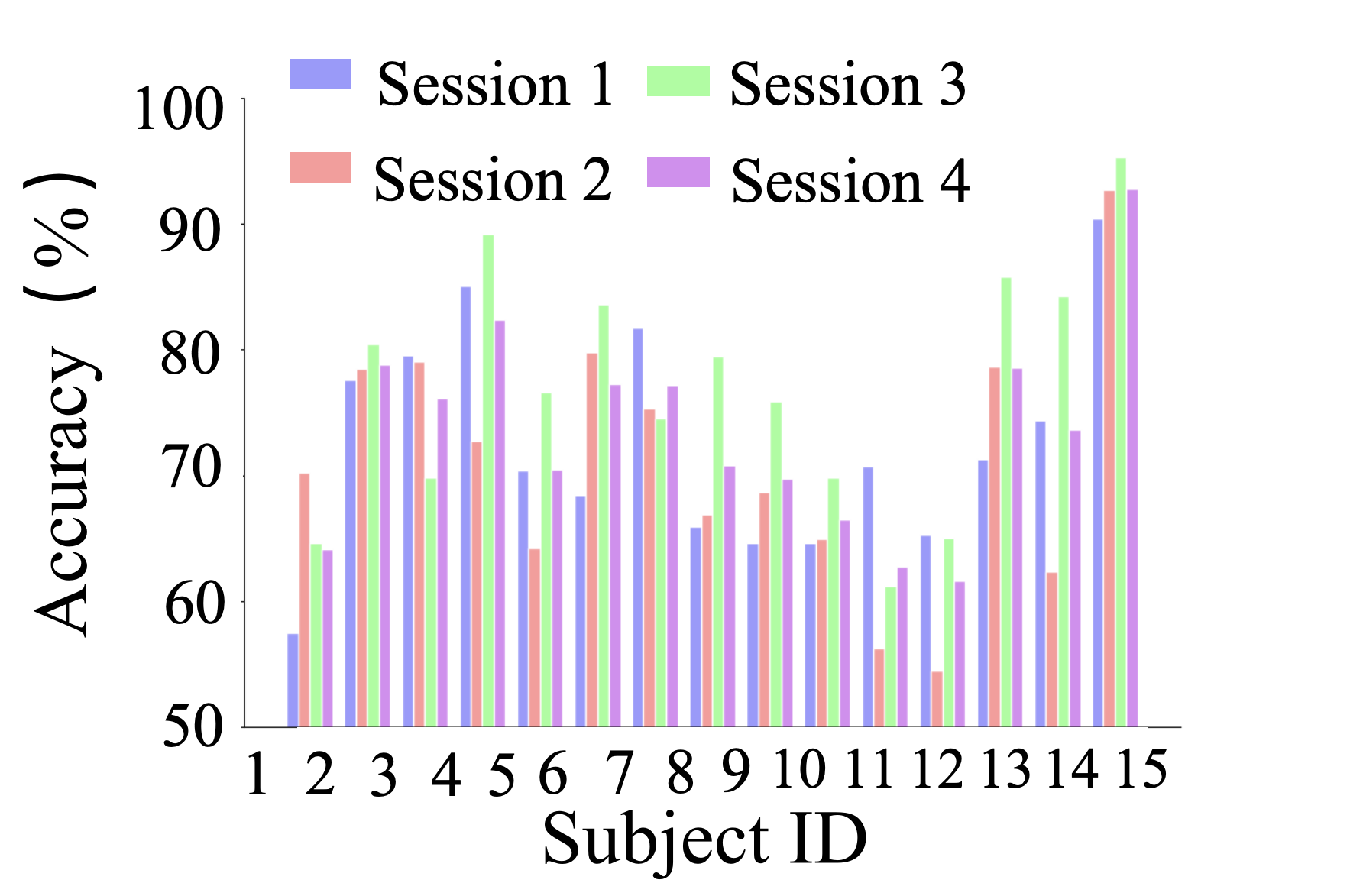
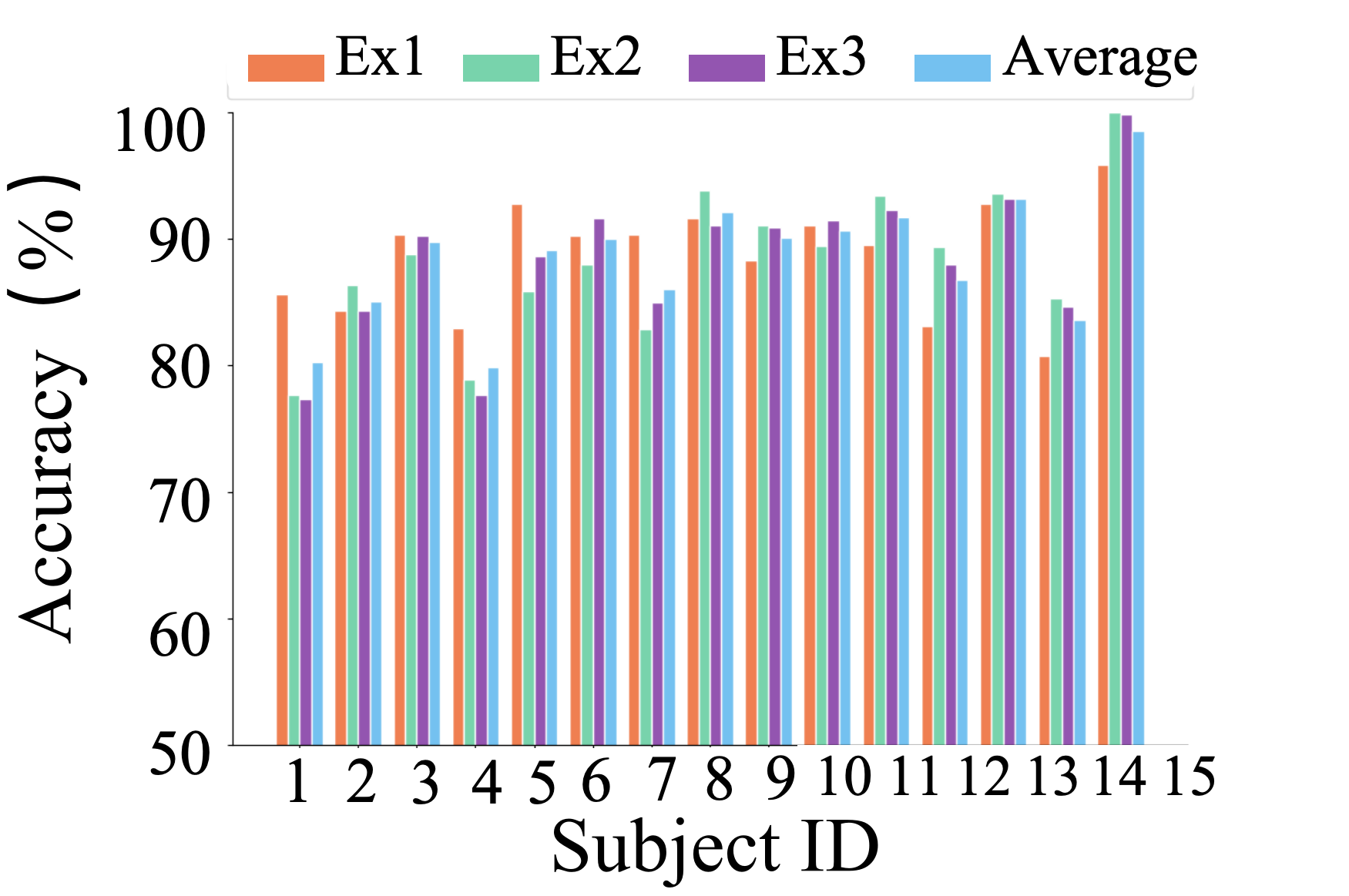
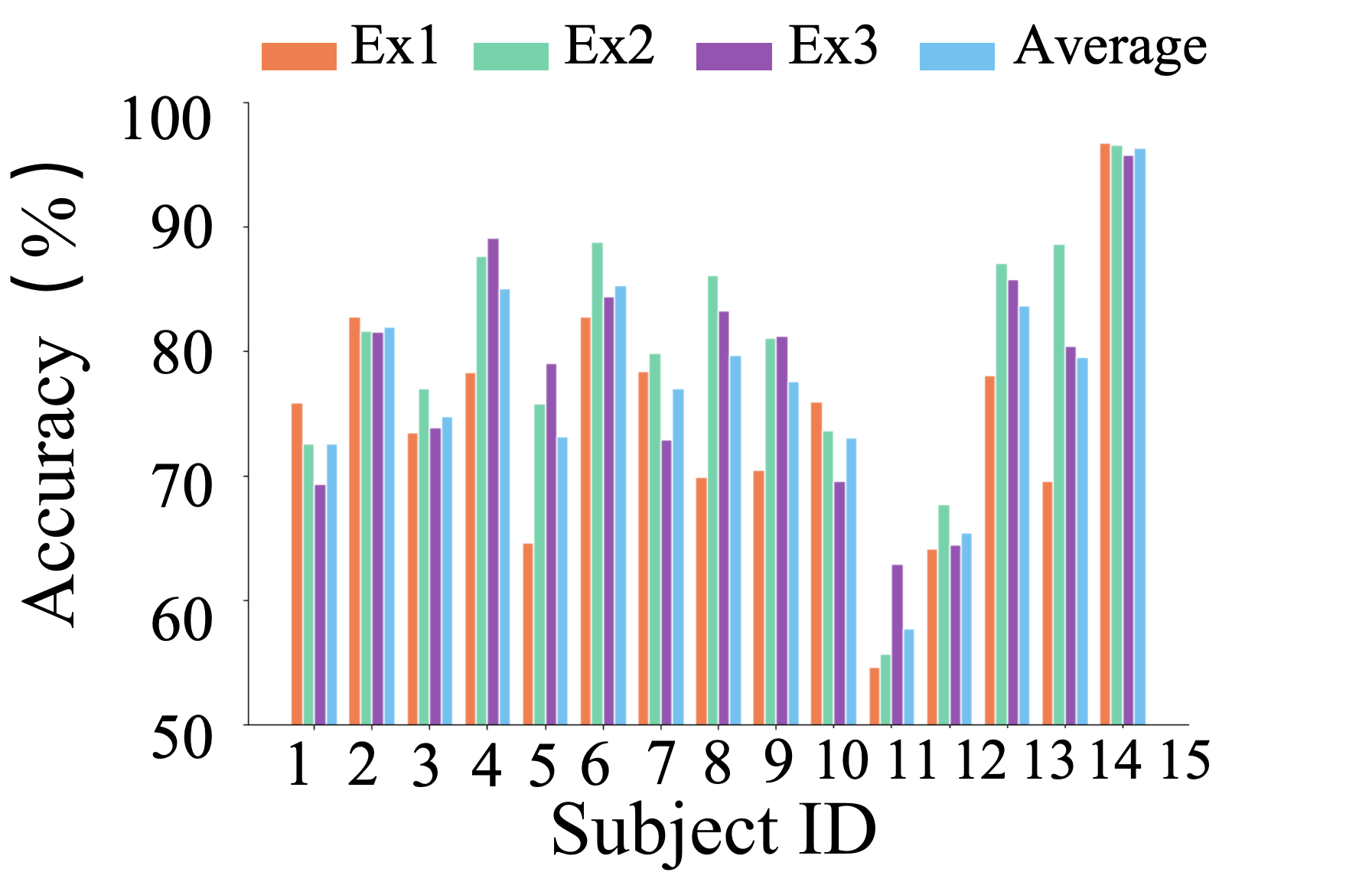
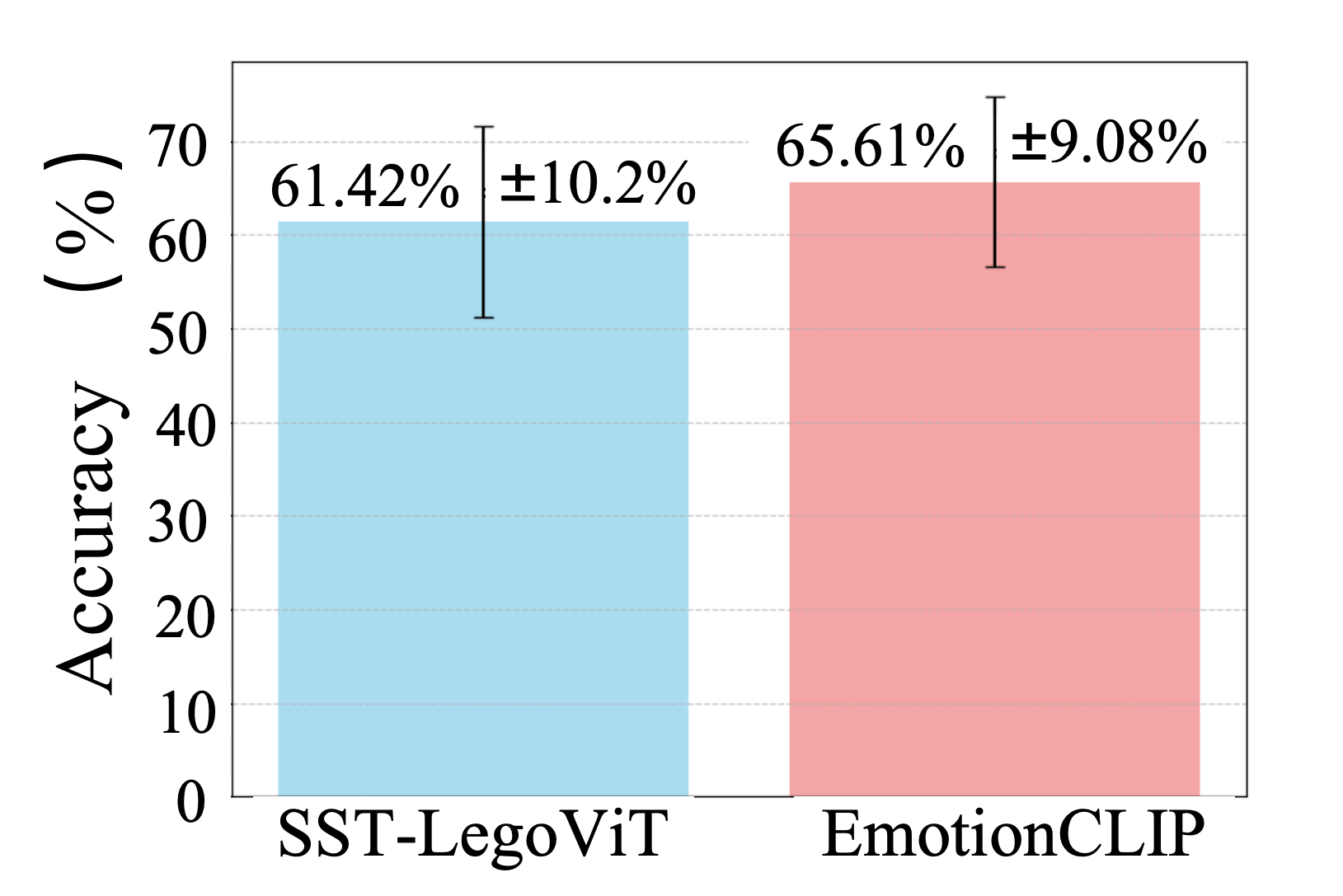
Figure 5: Few-Shot Results on SEED Dataset
Conclusion
The proposed EmotionCLIP framework marks a significant advancement in EEG-based emotion recognition, effectively addressing cross-domain challenges through EEG-text matching. By integrating CLIP's robust text encoders with novel EEG processing techniques, the framework establishes new benchmarks in accuracy and generalization capability on complex datasets. The findings in this paper indicate substantial potential for EmotionCLIP's application in various affective computing domains, suggesting promising directions for future research in multimodal emotion recognition systems.