Published 23 Mar 2023 in cs.LG, cs.AI, and cs.RO | (2303.13002v1)
Abstract: Dropped into an unknown environment, what should an agent do to quickly learn about the environment and how to accomplish diverse tasks within it? We address this question within the goal-conditioned reinforcement learning paradigm, by identifying how the agent should set its goals at training time to maximize exploration. We propose "Planning Exploratory Goals" (PEG), a method that sets goals for each training episode to directly optimize an intrinsic exploration reward. PEG first chooses goal commands such that the agent's goal-conditioned policy, at its current level of training, will end up in states with high exploration potential. It then launches an exploration policy starting at those promising states. To enable this direct optimization, PEG learns world models and adapts sampling-based planning algorithms to "plan goal commands". In challenging simulated robotics environments including a multi-legged ant robot in a maze, and a robot arm on a cluttered tabletop, PEG exploration enables more efficient and effective training of goal-conditioned policies relative to baselines and ablations. Our ant successfully navigates a long maze, and the robot arm successfully builds a stack of three blocks upon command. Website: https://penn-pal-lab.github.io/peg/
The paper presents PEG, a novel method to optimize exploratory goal selection in goal-conditioned reinforcement learning.
It employs a learned world model and sampling-based planning (MPPI) to estimate potential exploration rewards.
Experiments across diverse environments show that PEG significantly improves learning efficiency over baseline methods.
Planning Goals for Exploration
The paper "Planning Goals for Exploration" presents a novel approach to enhancing exploration in goal-conditioned reinforcement learning (GCRL) by utilizing planned exploratory goals (PEG). This method optimizes goal setting using intrinsic exploration rewards, offering a strategy to improve an agent’s learning efficiency in unknown environments.
PEG Framework
Introduction
The PEG framework addresses the core challenge in GCRL: optimally setting exploration goals that maximize exploration benefits. It builds upon the Go-explore methodology by proposing exploratory goals that lead to trajectories with high exploration potential. This involves learning world models and employing sampling-based planning algorithms.
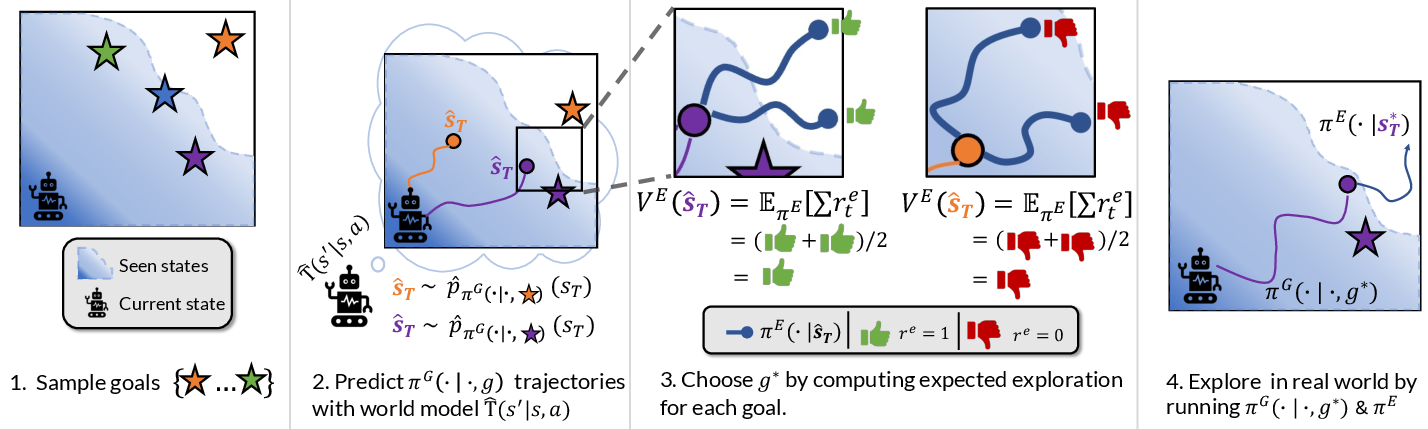
Figure 1: PEG proposes goals for Go-explore style exploration. 1) We start by sampling goal candidates g1…gN. 2) For each goal g, we execute the goal-conditioned policy πG in the world modelT.
Methodology
The proposed method, PEG, optimizes goal selection to derive maximal exploration value by calculating the potential exploration reward of the end-states achievable by a goal-conditioned policy. Using a learned world model facilitates on-the-fly estimation of an up-to-date goal's potential. The framework's core is the exploitation of these potential states to use sampling-based optimizers such as the Model Predictive Path Integral control (MPPI) for goal planning.
Utilizing an intrinsic motivation policy (Plan2Explore) to generate exploration rewards and facilitate exploration phases.
Continuous adaptation of value functions and goal-conditioned policies using model rollouts.
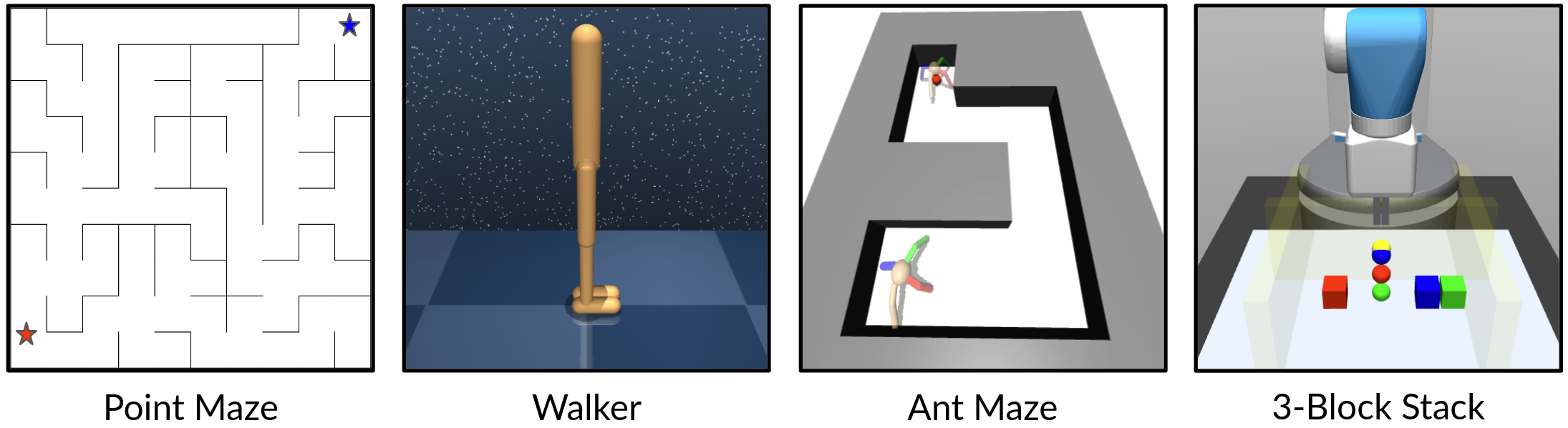
Figure 2: We evaluate PEG across four diverse environments, stress-testing exploration in Point Maze, Walker, Ant Maze, and 3-Block Stack.
Experimental Setup
Environments
PEG was evaluated in complex environments, including Point Maze, Walker, Ant Maze, and 3-Block Stack. These diverse settings highlight PEG's capability to manage long-horizon tasks requiring diverse exploration strategies.
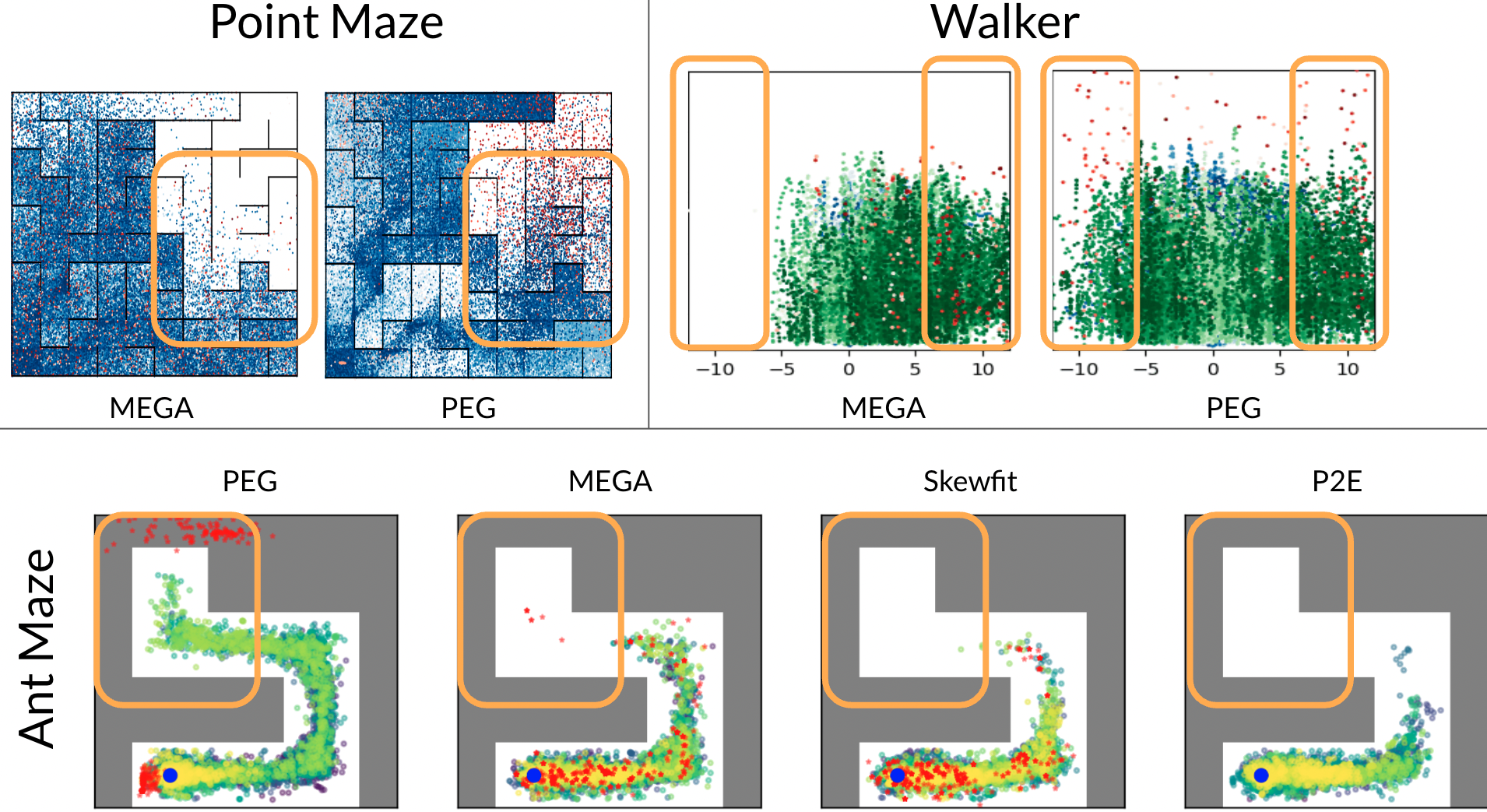
Figure 3: Achieved states and goals for PEG and baselines in different environments highlight PEG’s ability to choose exploratory goals effectively.
Results
PEG consistently outperformed baseline methods across different tasks and environments. The ability of PEG to set exploratory goals leading to high reward trajectories proved advantageous in learning efficiency and capability to handle challenging goal-reaching tasks.
Ablations and Analysis
An ablation study confirmed the significance of the exploration phase and the goal optimization strategy. Removing the goal optimization step or the exploration policy substantially degraded performance, indicating their critical roles in PEG's success.
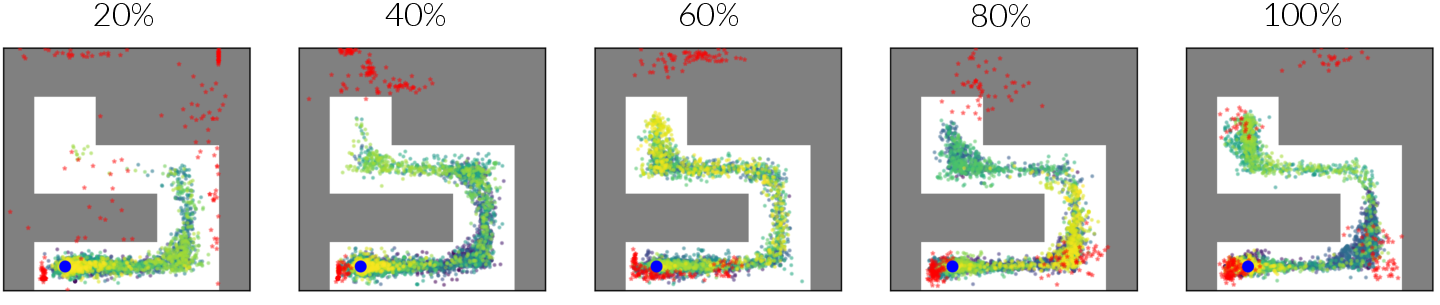
Figure 4: Evolution of states and goals of PEG throughout training demonstrates its efficiency in exploring beyond the known state distribution.
Conclusions and Future Work
PEG provides a proficient approach to goal-directed exploration within GCRL, proposing a systematic and efficient way to select exploratory goals. However, its effectiveness hinges on accurate world modeling and optimization strategies. Future research could focus on integrating hierarchical models to extend PEG's capabilities further and address limitations in environments with extremely large goal spaces.
Overall, PEG represents a significant advance in exploration strategies, improving data collection efficacy in learning diverse environment-relevant capabilities.