- The paper introduces BanglaMedQA and BanglaMMedBench, the first large-scale Bangla biomedical MCQ datasets created using robust retrieval-augmented generation techniques.
- It compares multiple RAG architectures—including traditional, agentic, iterative feedback, and aggregate k-values—to enhance answer accuracy and rationale quality.
- Empirical results highlight the superior performance of the agentic RAG pipeline, which dynamically adapts its retrieval strategy to address low-resource challenges in Bangla biomedical QA.
Evaluating Retrieval-Augmented Generation Strategies for Bangla Biomedical Question Answering
Introduction: Domain-Specific QA in Low-Resource Languages
The paper "BanglaMedQA and BanglaMMedBench: Evaluating Retrieval-Augmented Generation Strategies for Bangla Biomedical Question Answering" (2511.04560) addresses the development and benchmarking of biomedical QA systems in Bangla—a critical, low-resource language with over 230 million speakers. By releasing BanglaMedQA and BanglaMMedBench, the first large-scale Bangla biomedical MCQ datasets, the paper fills major gaps in multilingual medical AI. It systematically benchmarks multiple RAG strategies, integrating textbook OCR and agentic routing for dynamic retrieval, thereby enhancing answer and rationale quality for Bangla biomedical MCQs.
Dataset Construction and Preprocessing
Curating robust domain-specific datasets is foundational for low-resource QA systems. BanglaMedQA comprises 1,000 authentic medical MCQs, each rigorously cleaned for ambiguity, deduplication, and consistent structure. BanglaMMedBench contains an additional 1,000 situational questions translated from the English MMedBench dataset using validated LLM translation (Gemini-1.5-Flash), with careful manual review to preserve medical terminology and clarity. Preprocessing steps included Unicode and whitespace normalization, regular expression parsing of options, and standalone rationale fields. This ensures uniformity for both human and automated evaluation.
Retrieval Corpus: OCR and Knowledge Integration
The Bangla Biology textbook corpus, digitized using Google Lens OCR to handle complex Bangla character combinations, serves as the backbone for knowledge retrieval in RAG pipelines. Manual post-OCR curation guaranteed sequence integrity and completeness, mitigating noise from character segmentation errors. This domain alignment is critical for grounding biomedical reasoning in Bangla, overcoming the scarcity of web and research literature resources in the language.
RAG Pipeline Variants and Architectures
Traditional RAG and Fallback
The baseline RAG pipeline retrieves top-k textbook chunks per query, combining them with MCQ options for answer and rationale generation. The fallback mechanism supplements zero-shot LLM predictions when retrieval context is insufficient or null, improving recall and minimizing unanswered cases.
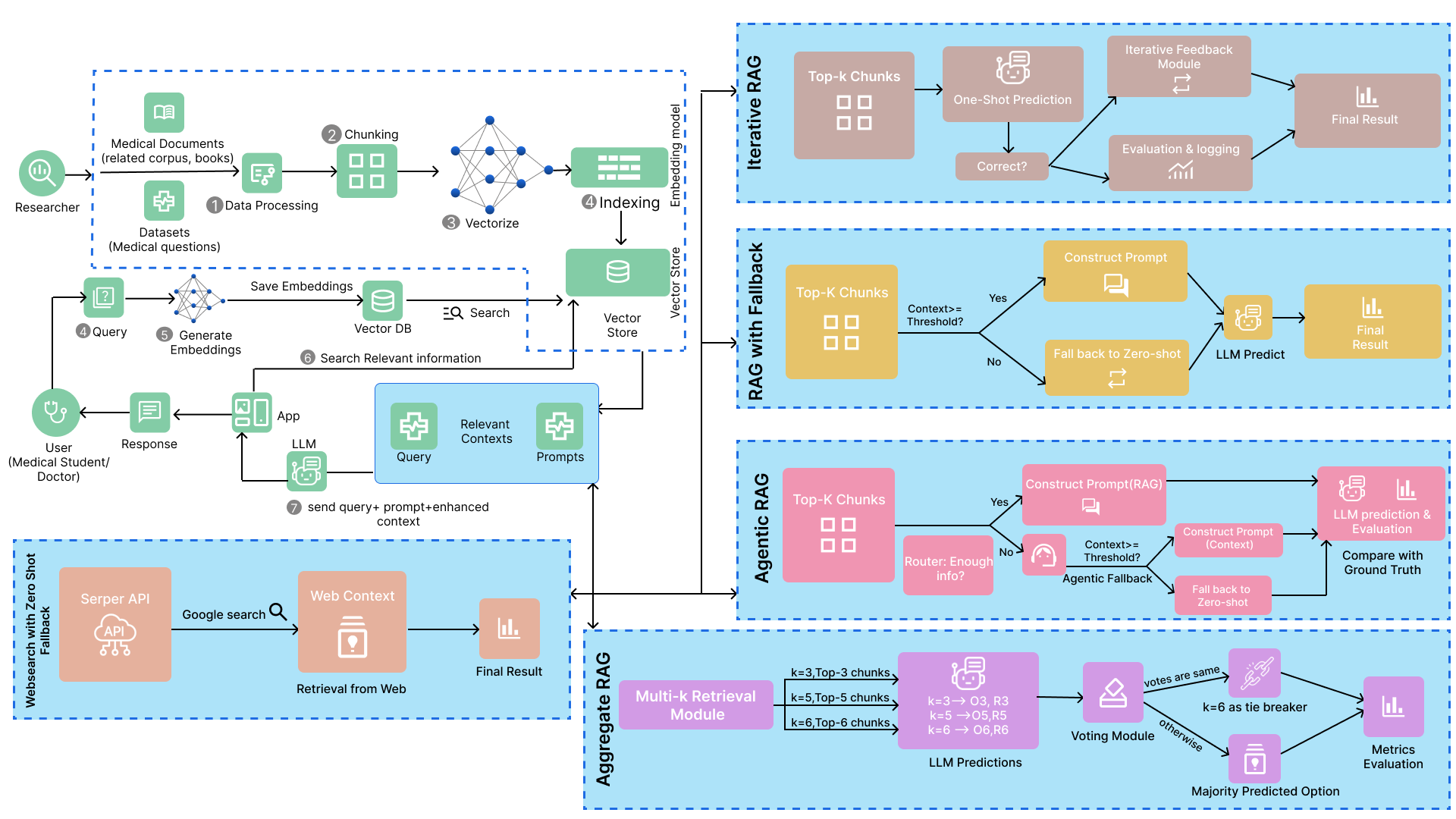
Figure 1: Workflow visualization of the Bangla RAG framework spanning traditional, fallback, and agentic modes.
Agentic RAG
Agentic RAG introduces a routing module: it dynamically switches between local textbook retrieval, web retrieval (Serper API), and zero-shot generation based on context sufficiency assessed with router prompts. This architecture enables context-sensitive adaptation, robust against content sparsity and retrieval errors, and demonstrates superior accuracy in answer selection and rationale construction.
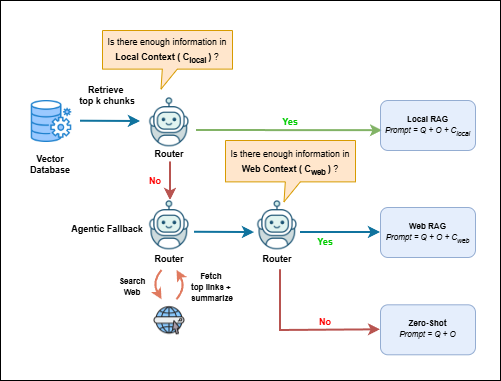
Figure 2: Illustration of the agentic RAG pipeline, integrating textbook, web, and zero-shot strategies with explicit routing.
Iterative Feedback RAG
Iterative Feedback RAG mimics reflective reasoning by performing multiple rounds of answer prediction, query refinement (via extracted key terms), and retrieval. Up to two iterations are executed; if initial predictions are incorrect, the query is reformulated and context is re-retrieved, improving robustness to initial retrieval errors.
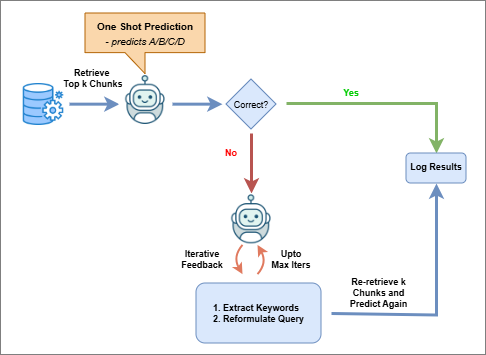
Figure 3: Iterative feedback pipeline demonstrating introspective answer refinement for Bangla biomedical MCQs.
Aggregate k-values RAG
Aggregate k-values RAG addresses retrieval sensitivity by leveraging predictions across different values of k (3, 5, 6). Final answers and rationales are selected by majority voting, ensuring balanced precision, recall, and error tolerance across diverse retrieval depths.
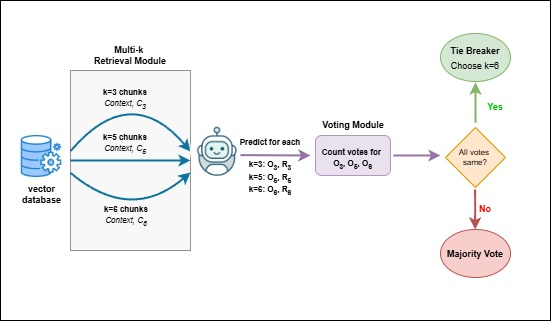
Figure 4: Pipeline for aggregating votes across multiple retrieval depths (k values) to improve stability and coverage.
Web Retrieval and Fallback
For scenario-based reasoning unsuitable for textbook retrieval (BanglaMMedBench), a pipeline utilizes web search, with up to 8 links per query and summarization of three top passages into Bangla. If web retrieval fails, zero-shot fallback maintains coverage, preventing null responses.
Experimental Setup
Models were served via Groq API (llama-3.3-70b-versatile, llama-3.1-8b-instant, openai/gpt-oss-20b/120b) with BengaliSBERT embeddings for semantic retrieval, chunked textbook passages (1,000 char, 200 overlap), Serper API for web search, and FAISS indexing for efficient vector storage. Robust error handling included exponential backoff retries and local result caching.
Evaluation Metrics
Answer accuracy was complemented by BERTScore (semantic alignment), METEOR (linguistic similarity), ROUGE (coverage/content), and BLEU (surface-level correspondence) for rationale quality. This factorial assessment ensures comprehensive evaluation of both answer correctness and explanation fidelity.
BanglaMedQA Benchmarking
Agentic RAG with openai/gpt-oss-120b achieved the highest accuracy (89.54%) and strong rationale metrics (ROUGE-1 0.0897, BLEU-1 0.1228), outperforming traditional, fallback, iterative, and aggregate variants. Gains from textbook retrieval were substantial for Bengali models, diminishing for highly performant zero-shot-capable LLMs (e.g., gpt-oss-20b/120b). Iterative Feedback RAG, while interpretable, lagged advanced methods in accuracy.

Figure 5: Llama-3.3-70b-versatile responses to BanglaMedQA queries across retrieval strategies illustrating differences in rationale depth and correctness.
Aggregate k-values RAG (openai/gpt-oss-120b, 84.51% accuracy) provided stable predictions via combined voting, mitigating context retrieval noise.
MMedBench and BanglaMMedBench Comparative Analysis
Zero-shot and Web RAG pipelines performed strongly on English MMedBench (gpt-oss-120b, 92.47% accuracy), but accuracy dropped for BanglaMMedBench (gpt-oss-120b, 90.59%). Web-based context occasionally degraded accuracy in Bangla due to generic or non-domain-aligned results—underscoring the necessity of high-quality domain-specific retrieval across languages.
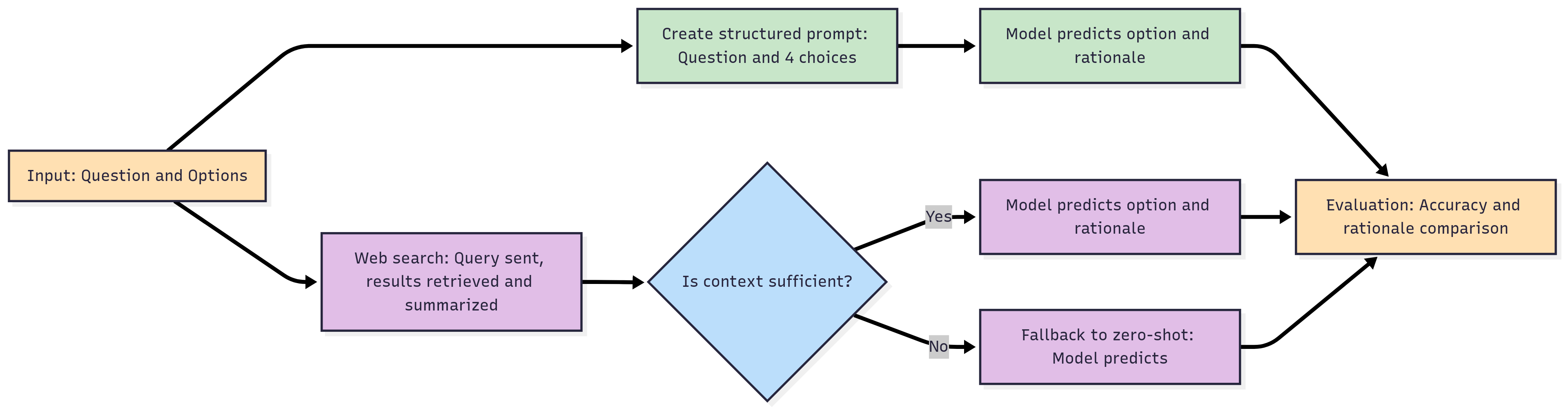
Figure 6: Comparative accuracy and rationale performance for zero-shot and web search retrieval on English and Bangla MMedBench datasets.
Practical and Theoretical Implications
Practical: The agentic RAG architecture with well-tuned routing and fallback enables robust, high-accuracy biomedical QA in resource-constrained Bangla. Curated textbook retrieval empirically improves factual grounding and rationale explainability. Aggregate k-values voting stabilizes prediction variance from context chunking. For clinical scenario QA, translation fidelity and query-relevant web sources remain limiting factors.
Theoretical: Dynamic routing and iterative feedback exemplify the importance of context sufficiency assessment and self-improving query mechanisms in multilingual RAG. The results demonstrate that scale alone (e.g., LLM size) does not guarantee cross-lingual transfer on high-stakes medical QA; retrieval augmentation is essential when domain knowledge and reasoning must be local and explainable.
Limitations and Future Directions
Dataset size (2,000 questions) and translation fidelity may limit generalizability; textbook OCR errors impose noise. Answer rationale scoring depends on reference similarity, not clinical correctness. Computational requirements scale with model size, embedding, and retrieval complexity—indicating trade-offs between inference latency and QA accuracy.
Future work may consider: (1) expanding Bangla biomedical datasets and textbook corpora; (2) fine-tuning Bangla-centric LLMs with domain rationales; (3) developing improved router modules for nuanced retrieval and context fusion; (4) exploring hybrid web/textbook knowledge fusion with adversarial filtering; and (5) proposing multilingual 'gold standard' rationales for human evaluation.
Conclusion
BanglaMedQA and BanglaMMedBench provide the first large-scale benchmarks for Bangla biomedical MCQ QA, demonstrating that RAG—especially agentic, dynamic variants—substantially improves both accuracy and rationale quality in low-resource settings. Model scale, retrieval quality, and adaptive QA architectures must co-evolve to bridge cross-lingual deficits and support equitable AI-driven medical education and assistance. These findings furnish a methodological blueprint for future multilingual biomedical AI system development and evaluation.