Orion-MSP: Multi-Scale Sparse Attention for Tabular In-Context Learning
Abstract: Tabular data remain the predominant format for real-world applications. Yet, developing effective neural models for tabular data remains challenging due to heterogeneous feature types and complex interactions occurring at multiple scales. Recent advances in tabular in-context learning (ICL), such as TabPFN and TabICL, have achieved state-of-the-art performance comparable to gradient-boosted trees (GBTs) without task-specific fine-tuning. However, current architectures exhibit key limitations: (1) single-scale feature processing that overlooks hierarchical dependencies, (2) dense attention with quadratic scaling in table width, and (3) strictly sequential component processing that prevents iterative representation refinement and cross-component communication. To address these challenges, we introduce Orion-MSP, a tabular ICL architecture featuring three key innovations: (1) multi-scale processing to capture hierarchical feature interactions; (2) block-sparse attention combining windowed, global, and random patterns for scalable efficiency and long-range connectivity; and (3) a Perceiver-style memory enabling safe bidirectional information flow across components. Across diverse benchmarks, Orion-MSP matches or surpasses state-of-the-art performance while scaling effectively to high-dimensional tables, establishing a new standard for efficient tabular in-context learning. The model is publicly available at https://github.com/Lexsi-Labs/Orion-MSP .
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a new AI model called Orion-MSP. It’s designed to work with “tabular data,” which are regular tables like spreadsheets with rows and columns. The goal is to help the model learn quickly from examples given “in context” (like seeing a few labeled rows in the table and then predicting labels for new rows) without needing to retrain the model every time.
The authors show how Orion-MSP can understand complex relationships in big, wide tables more efficiently and accurately than earlier models.
What questions does the paper try to answer?
The paper focuses on three main problems with existing table-focused AI models:
- Can we make models see patterns at different “zoom levels” (small details and big-picture groups) instead of treating every column the same way?
- Can we reduce the heavy computation required when every feature (column) tries to “look at” every other feature?
- Can we let different parts of the model share useful information back and forth safely, without accidentally using test data to influence training (which would be cheating)?
How does Orion-MSP work? (Explained with simple ideas)
Think of a table as a classroom of students (features/columns) and rows as different class days. The model has four main steps:
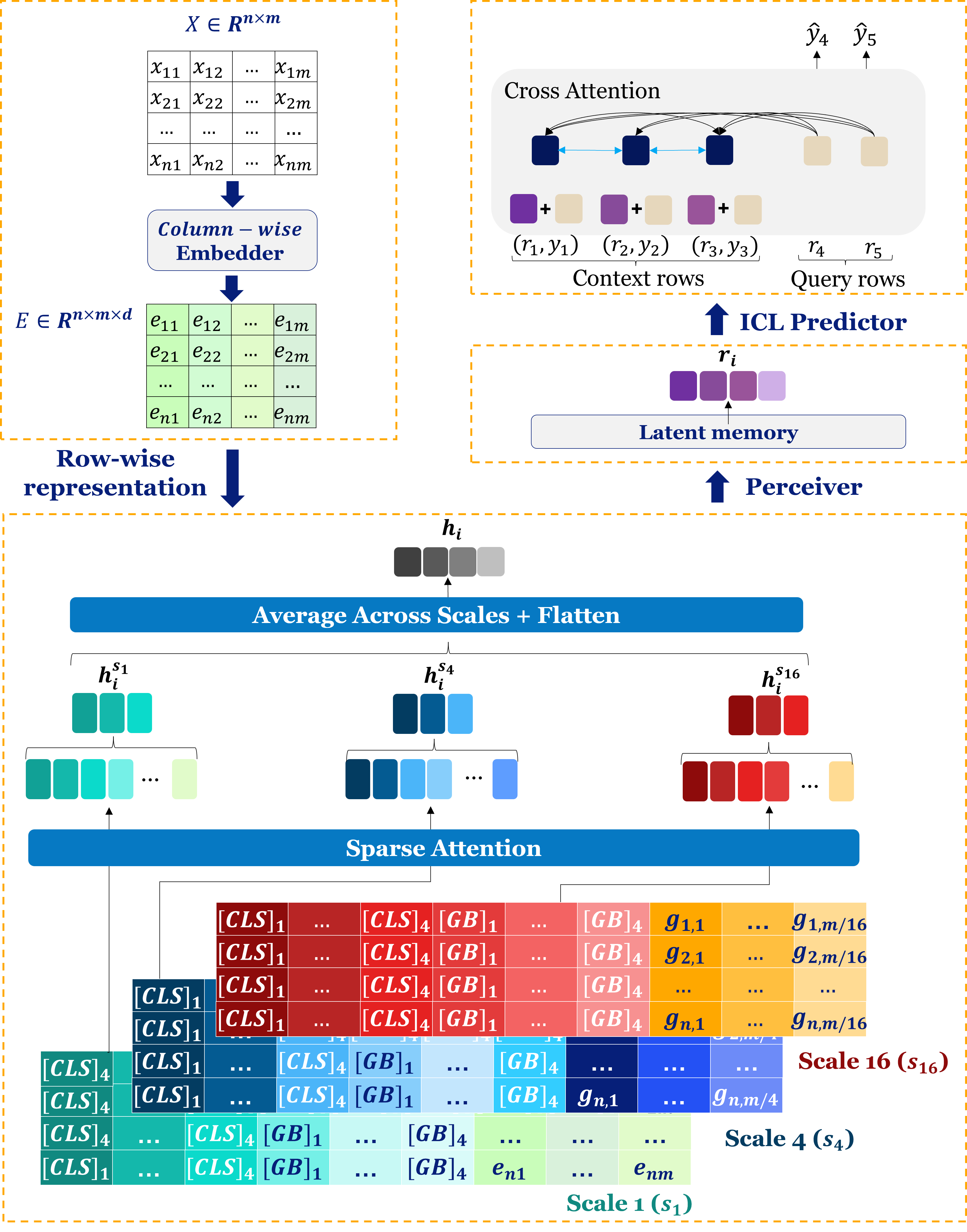
1) Column-wise embedding: understanding each feature in context
- Imagine each column is a “club” (like Drama Club, Chess Club). The numbers in that column are the members’ scores or activities.
- The model learns the “vibe” of each club using a special tool called a Set Transformer. It doesn’t care about the order of rows; it looks at the whole column’s distribution (like average, spread, and outliers).
- Important rule: it builds this summary using only training rows, so it doesn’t peek at test rows. That keeps in-context learning fair and safe.
2) Multi-scale row interaction: looking at features at different zoom levels
- Now the model looks across features within each row (across clubs on the same day).
- It does this at three scales, like zooming in and out:
- Fine scale: individual features (zoomed-in details).
- Medium scale: small groups of features (like groups of 4).
- Coarse scale: bigger groups (like groups of 16).
- Attention made efficient:
- Instead of every feature talking to every other feature (which is slow), it uses a smart pattern:
- Local window: each feature mainly talks to its neighbors.
- Global tokens: special “class leaders” that can talk to everyone and help spread important info.
- A few random links: occasional random connections help cover long-distance relationships.
- This cuts the cost dramatically. For example, with 100 features:
- Old way: about 10,000 interactions per layer.
- Orion-MSP’s way: roughly 1,400 interactions per layer (neighbors + global + random), which is much faster and uses less memory.
3) Perceiver-style memory: a shared, safe notebook
- Picture a shared notebook in class:
- Only training rows can write in it (so it doesn’t learn from test rows by accident).
- Both training and test rows can read from it to get useful context.
- This lets earlier parts of the model benefit from later discoveries without breaking the “no test leakage” rule.
4) In-context learning predictor: using examples to make new predictions
- Finally, the model predicts labels for test rows by “looking” at the labeled training rows and the refined row representations.
- It doesn’t retrain; it reasons from the context (the examples you provide, plus the shared notebook).
What did the researchers find, and why does it matter?
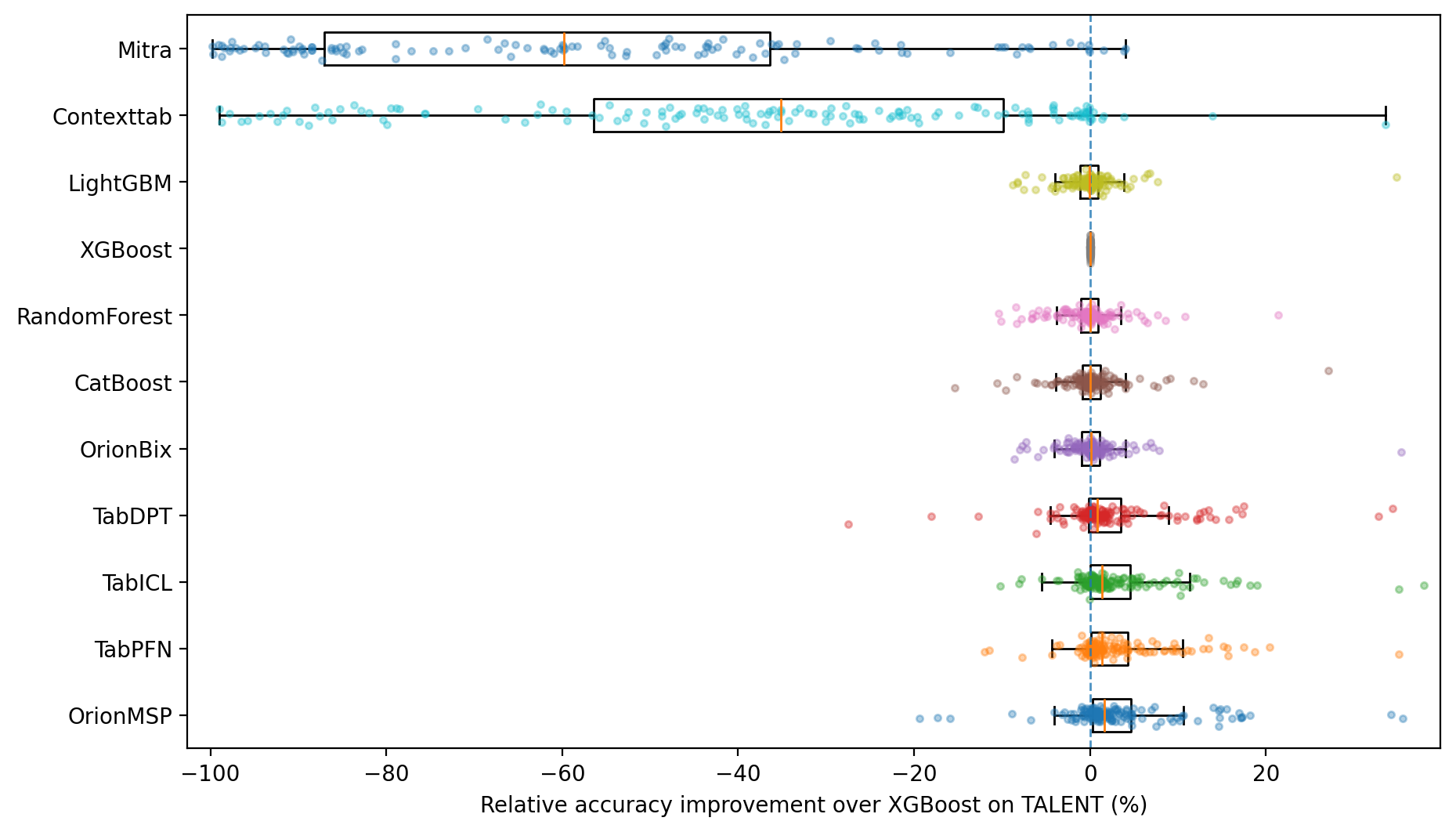
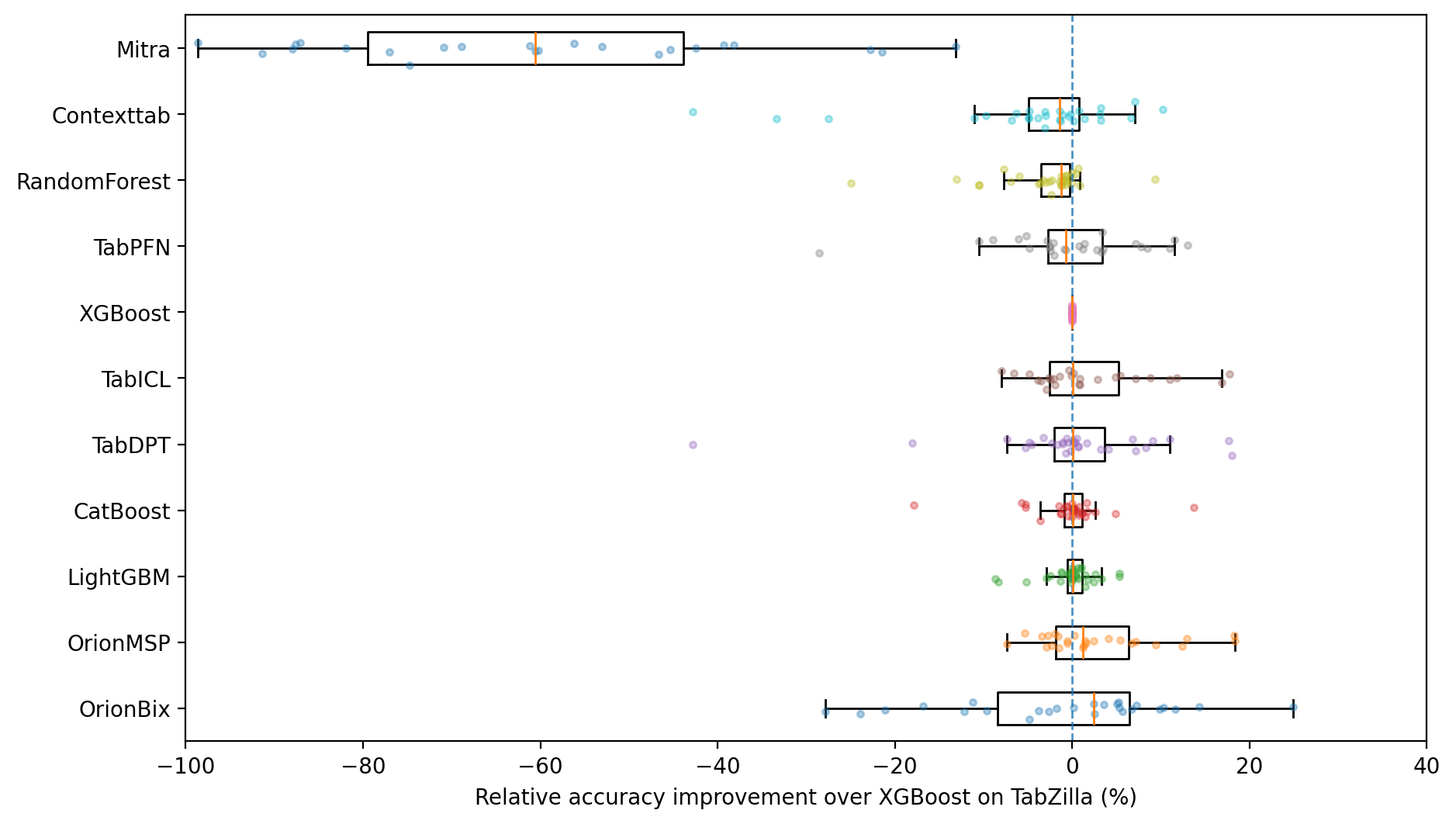
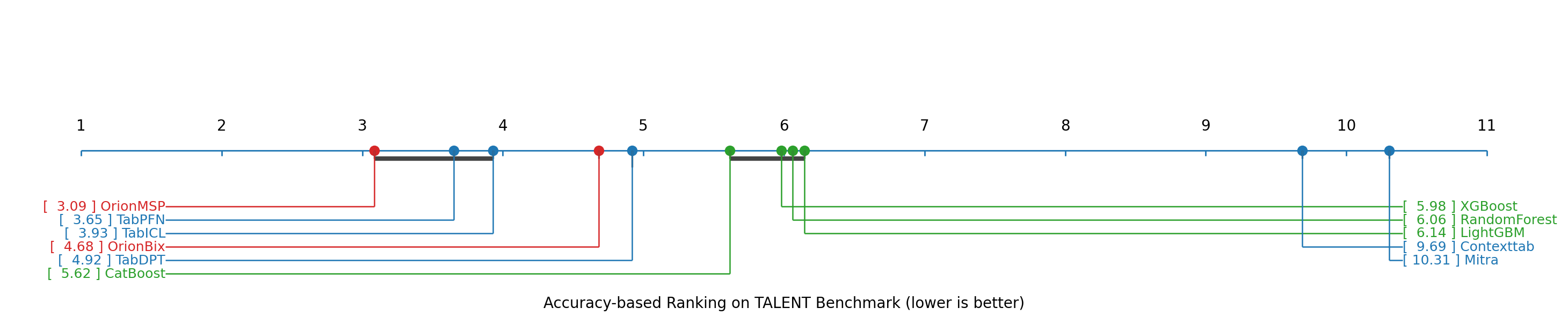
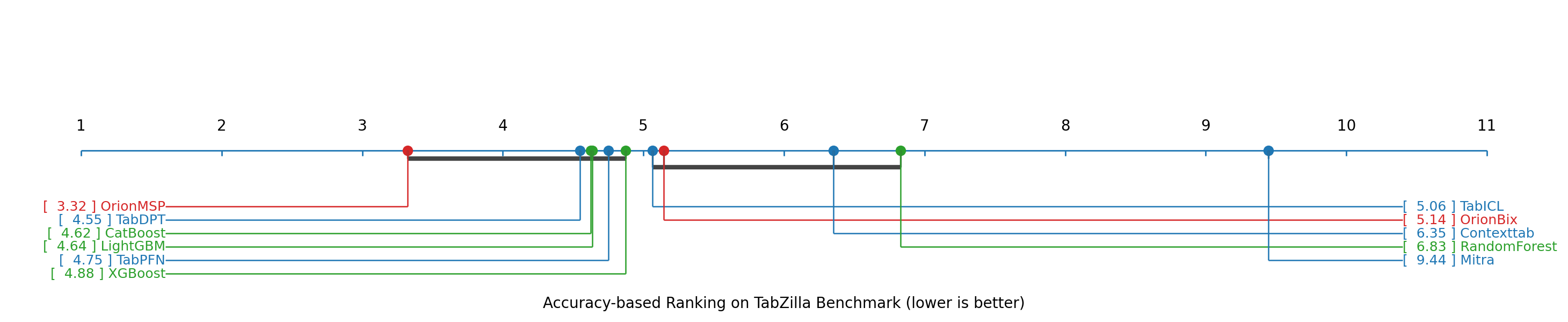
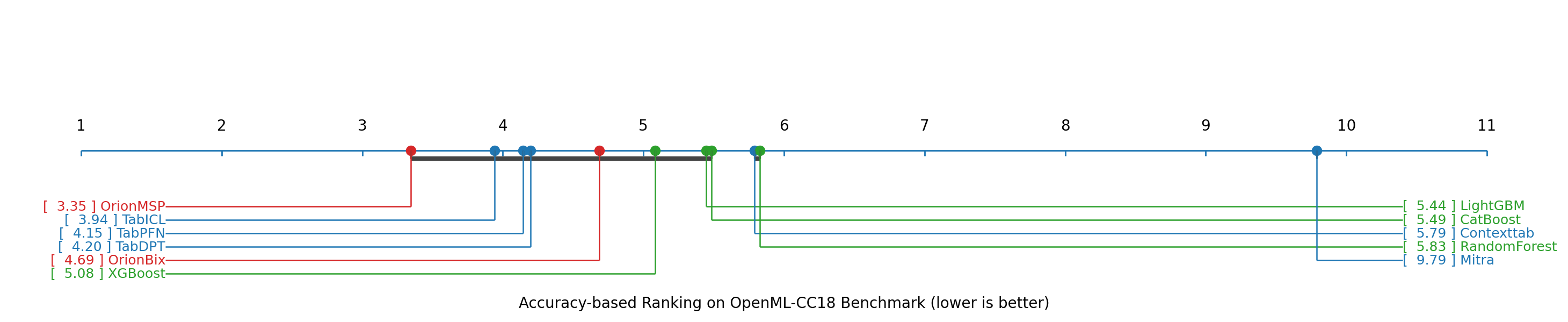
- Accuracy: Orion-MSP matches or beats the best existing tabular in-context learning models on many benchmarks.
- Efficiency: It scales well to tables with more than 100 features (columns), where older models struggle or run out of memory.
- Safety: The memory design keeps predictions fair by ensuring test information never influences training representations.
- Practicality: It’s fast and handles complex, high-dimensional data often found in areas like finance, healthcare, genomics, and sensor data.
This matters because real-world tables can be big and complicated. A model that is both fast and accurate, and doesn’t require retraining for each new dataset, can save a lot of time and make advanced analytics more accessible.
Why is this research important for the future?
- Better tools for real data: Many businesses and scientists use tables. Orion-MSP makes it easier to get strong predictions from them without extensive tuning.
- Handles bigger problems: Thanks to multi-scale processing and sparse attention, it can work on wide datasets efficiently.
- Safer AI behavior: The “shared notebook” (Perceiver memory) respects in-context learning rules, which is important for trustworthy AI.
- Open source: The model is publicly available, so others can build on it, test it, and use it in real applications.
In short, Orion-MSP sets a new standard for how AI can learn from tables quickly and safely, making it a powerful choice for many real-world tasks.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a consolidated list of concrete gaps and unresolved questions that emerge from the paper. Each point highlights what is missing or uncertain and suggests directions for actionable follow-up work.
- Permutation sensitivity of features: The row-wise module uses RoPE and sliding-window attention along the feature axis, implicitly imposing an order over columns. The paper does not define a canonical column ordering or prove feature-permutation invariance. Needed: ablations with random column shuffling, a principled canonicalization procedure, or an order-invariant alternative to RoPE/windowing.
- Formal ICL safety guarantees: The Perceiver-style memory includes an argument for safety (train-only writes, all-rows read), but no formal proof under training dynamics. Needed: a causality/graphical-model proof and adversarial tests showing no test-to-train leakage via gradients, residual paths, or shared parameters.
- Train/test masking in grouping and attention: Multi-scale feature grouping via PMA appears to operate over embeddings with shape suggestions that could conflate rows or datasets. It is unclear whether any step lets test rows influence training representations. Needed: explicit row-wise grouping formulation, attention masks for all cross-sample operations, and verification artifacts.
- Complexity claims inconsistency and profiling: The paper states both O(H log H) and O(m * (w + g + r)) reductions, and later “near-linear” complexity. Needed: reconcile the bounds, provide formal asymptotics per module (column embedder, row interaction, ICL), and report wall-clock speedups and memory metrics on GPUs/TPUs with and without block-sparse kernels.
- Sample dimension scaling (n): While feature-wise complexity is addressed, scaling in the number of samples is under-specified. ISAB uses training samples as K/V; complexity and memory vs ntrain are not characterized. Needed: empirical and theoretical scaling for n up to 10k–100k, including batching/truncation strategies.
- Very wide tables (m >> 100): Claims focus on >100 features, but many real datasets have 1k–10k features. Needed: experiments and failure-mode analysis at these widths, and kernel-level optimizations for block-sparse attention at scale.
- Task coverage beyond classification: The architecture and label injection are classification-centric. Needed: extensions and evaluations for regression, multi-label, ranking, survival analysis, and ordinal outcomes, including how label injection generalizes.
- Handling heterogeneous feature types: The approach does not detail encoding strategies for high-cardinality categorical, ordinal, binary, and mixed-type columns. Needed: systematic pre-processing/embedding pipelines, ablations across type mixes, and performance vs. top tree baselines for categorical-heavy datasets.
- Missing values and MNAR robustness: No mechanism is described for missingness patterns (MCAR/MAR/MNAR), despite citing diffusion-based robustness elsewhere. Needed: explicit masking schemes, imputation strategies, or missingness-aware attention, with controlled missingness benchmarks.
- Distribution shift and OOD generalization: Robustness to covariate and label shift is not evaluated. Needed: benchmarks with controlled shifts, domain adaptation settings, and uncertainty estimation/calibration diagnostics (ECE, NLL under shift).
- Hyperparameter sensitivity and auto-tuning: Model performance likely depends on scales, window size w, number of globals g, random links r, number of memory slots P, and Nblocks per module. Needed: sensitivity analyses and an AutoML/heuristic recipe for choosing these across datasets with different m and n.
- Random-link attention stability: The role, determinism, and reproducibility of random connections (r) are underexplored. Needed: fixed vs. re-sampled links across layers/epochs, impact on variance across runs, and whether learned topologies outperform random ones.
- Global token count and function: The number of [GLOBAL] tokens and their learned roles are not studied. Needed: ablations on connectivity patterns, interpretability studies of learned global representations, and minimal global sets preserving accuracy.
- Multi-scale grouping design: Choice of scales {1,4,16} is fixed and unmotivated beyond analogy; aggregation is a simple average. Needed: principled scale selection, learned or data-adaptive scaling, and alternative fusion (gating/attention) with ablations.
- Interpretability of learned groups: PMA-based soft grouping may discover feature clusters, but no analysis is provided. Needed: stability of group assignments, correlations with known domain semantics, and methods to surface group-level attributions.
- Column embedder invariances: The per-cell affine mapping depends on column distributions learned from training keys. It is unclear how robust this is to rescaling, monotone transforms, and extreme outliers. Needed: tests for invariances (scale, shift, monotone), outlier stress tests, and normalization guidelines.
- Pretraining and meta-training regimen: The paper does not specify whether Orion-MSP is trained on synthetic or real tabular tasks, nor the task distribution and objectives. Needed: detailed pretraining corpus, task-sampling, augmentation, and comparisons of synthetic vs. real meta-training.
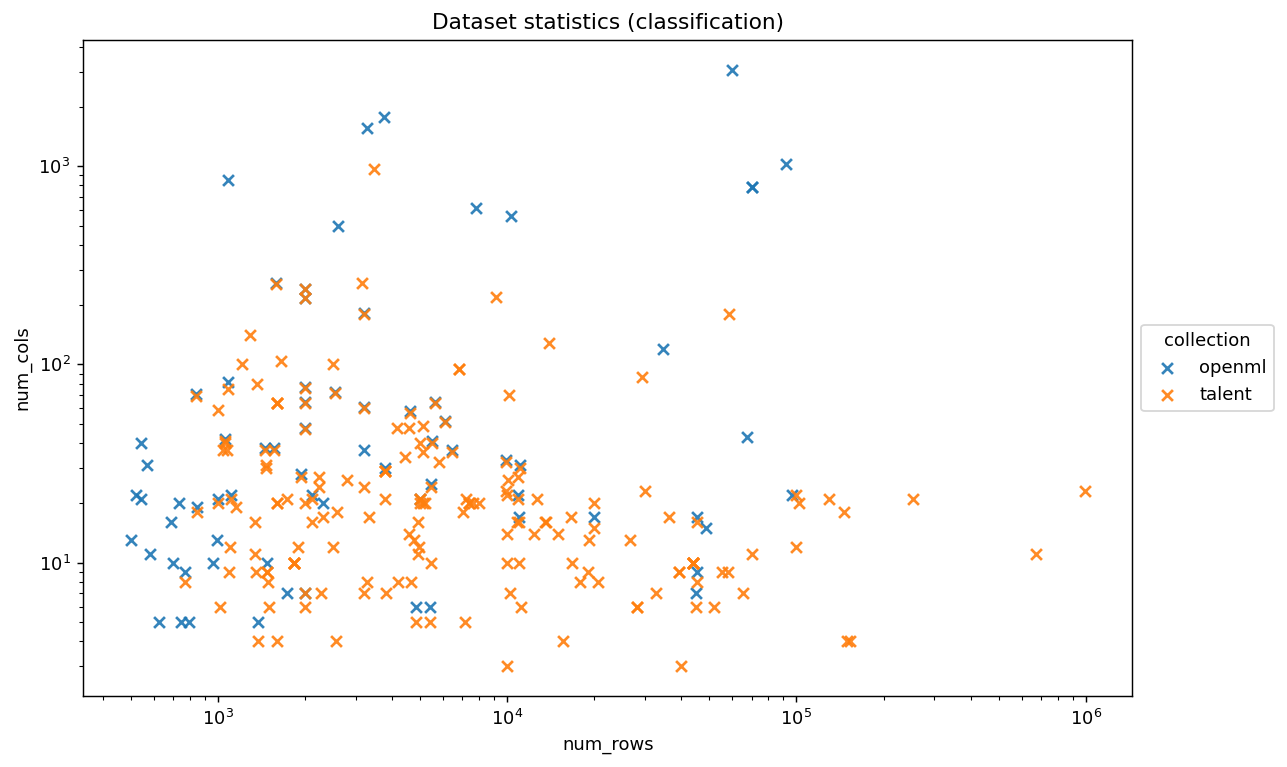
- Benchmark coverage and baselines: “Diverse benchmarks” are referenced without specifics. Needed: systematic evaluations across OpenML/UC Irvine suites spanning small-to-large m and n, including strong GBT baselines (CatBoost/LightGBM/XGBoost), TabPFN/TabPFN-v2/TabICL/ContextTab, and LLM-serialization approaches.
- Wall-clock efficiency vs. dense attention: Sparse attention can underperform in real time without optimized kernels. Needed: fair runtime/memory profiles across hardware backends, batch sizes, and sequence lengths, plus end-to-end latency for inference with realistic ntrain/n test.
- Memory module capacity and scaling: The effect of the number of memory slots P, write/read depths, and bottleneck size on accuracy/efficiency is unreported. Needed: scaling laws for P and analyses of under/over-compression regimes.
- Interaction of memory and label injection: The sequencing of Perceiver read/write and label injection could affect safety and performance. Needed: ablations on ordering (read-before/after label injection), and proofs/tests that labels cannot leak to test rows.
- Cross-dataset contamination in batches: The memory initialization is shared parameters (L0), but dataset-specific memories are separate. It remains to be shown that batching does not introduce cross-dataset interference. Needed: tests where tasks are batched vs. isolated, with controls for contamination.
- Feature-importance and explanation: No method is provided for attributing predictions to features or scales. Needed: adaptations of attention-based attribution, input perturbations, or Shapley approximations compatible with the multi-scale sparse architecture.
- Extreme class imbalance and few-shot ntrain: Performance under heavy imbalance and very small context (e.g., ntrain ≤ 5) is unknown. Needed: controlled imbalance experiments, reweighting or focal objectives, and context construction strategies.
- Context construction and selection: For large datasets, which training examples constitute the context is unspecified. Needed: retrieval strategies (similarity, diversity), budgets vs. accuracy curves, and dynamic context pruning.
- Robustness to feature noise and adversarial perturbations: No analysis of noise sensitivity or adversarial robustness. Needed: controlled noise/attack benchmarks and defenses (robust normalization, adversarial training).
- Multi-table/relational and temporal tabular data: The method is single-table and static. Needed: extensions for relational joins and row-wise temporal sequences, assessing how multi-scale/sparse designs adapt.
- Calibration and uncertainty: No uncertainty quantification is reported. Needed: calibration (ECE/Brier), conformal wrappers for ICL predictions, and OOD detection with memory-aware scores.
- Practical deployment details: Preprocessing (scaling, encoding), training schedules, and early stopping criteria are unspecified. Needed: a reproducible pipeline and sensitivity tests to common preprocessing choices.
- Licensing, reproducibility, and kernel availability: Public code is promised, but the performance of block-sparse ops depends on kernel support. Needed: open-source kernels, deterministic training configs, and scripts to reproduce speed/accuracy claims.
These gaps, if addressed, would substantially strengthen the empirical, theoretical, and practical foundations of Orion-MSP and clarify its advantages and limits across real-world tabular settings.
Practical Applications
Practical Applications of Orion-MSP (Multi-Scale Sparse Attention for Tabular In-Context Learning)
Orion-MSP is a table-native foundation model for in-context learning (ICL) that delivers three practical advances: multi-scale feature processing (capturing hierarchical interactions), block-sparse attention (near-linear scaling in table width), and Perceiver-style cross-component memory (safe bidirectional information flow without test leakage). These innovations enable efficient, scalable, and safer zero/few-shot prediction on tabular data. Below are actionable applications grouped by deployability.
Immediate Applications
The following applications can be piloted or deployed today using the released model and standard MLOps tooling.
- AutoML acceleration and baselining for tabular ML
- Sector: Software, MLOps, Data Science
- Use case: Drop-in baseline for new tabular tasks (classification), rapid feasibility checks, and few-shot performance probes without dataset-specific training. Adds a strong non-GBT baseline to AutoML systems.
- Potential tools/workflows:
- scikit-learn–style “OrionMSPClassifier” wrapper
- AutoML plugins that try Orion-MSP before/alongside GBT
- Context builder to assemble labeled rows (e.g., top-k retrieval from feature store)
- Assumptions/dependencies:
- Current implementation focuses on classification; regression support may require minor extensions
- Data preprocessing (missing values, categorical handling) must be consistent with Orion-MSP inputs
- GPU with support for block-sparse attention or efficient CPU fallback
- Rapid cold-start prediction in new market segments
- Sector: Finance (credit, fraud), E-commerce, Insurance
- Use case: Few-shot credit scoring for new geographies, fraud risk for newly onboarded merchants/verticals, cohort-specific underwriting rules exploration.
- Potential tools/workflows:
- Real-time or batch scoring service where analysts provide a small labeled context set and score new applicants or transactions
- Calibration module to align probabilities to policy thresholds
- Assumptions/dependencies:
- Careful fairness and compliance auditing; transparent train/test masking in ICL pipeline
- Representative context selection (e.g., curated or retrieved by similarity) to avoid bias
- Clinical triage and cohort-risk estimation without model retraining
- Sector: Healthcare
- Use case: Triage new patient cohorts with limited labels (e.g., rare disease screening), leveraging many lab and demographic features (wide tables).
- Potential tools/workflows:
- EHR integration for batch scoring of new admissions using small, clinician-curated labeled examples
- Decision support dashboards showing hierarchical feature-group contributions (via multi-scale CLS token attributions)
- Assumptions/dependencies:
- IRB/ethics approvals, clinical validation, privacy-preserving deployment
- Robust missing-value handling and strict test-leakage controls (supported by the ICL safety design)
- Predictive maintenance across heterogeneous fleets
- Sector: Manufacturing, IoT, Logistics
- Use case: Few-shot failure prediction for new equipment models/sites with high-dimensional sensor tables; per-site contexts without retraining a global model.
- Potential tools/workflows:
- On-prem scoring service with per-site context windows
- Drift monitoring via column-level embeddings and Perceiver memory summaries
- Assumptions/dependencies:
- Stable feature alignment or schema-mapping; performance depends on relevance of context samples
- Compute availability for near-real-time inference
- Small-n, high-m scientific modeling
- Sector: Life sciences (omics, proteomics), Materials science, Social science
- Use case: Classification in experiments with few samples but many features (e.g., gene expression), leveraging hierarchical grouping of features.
- Potential tools/workflows:
- Notebook-based research workflows; integration with analysis libraries (e.g., an Orion-MSP Python API)
- Exploration of feature-group interactions via multi-scale outputs
- Assumptions/dependencies:
- Proper normalization and domain-specific preprocessing (e.g., log transforms)
- Labels must be clean; few-shot settings are sensitive to label noise
- Data profiling, outlier, and drift detection via learned embeddings
- Sector: Cross-sector data engineering and governance
- Use case: Use column-wise inducing points and row CLS embeddings to detect outliers, drift across batches, or mislabeled rows.
- Potential tools/workflows:
- Data quality dashboards computing embedding distances and drift metrics
- Alerts triggered by shifts in memory summaries or column embedding statistics
- Assumptions/dependencies:
- Thresholds and metrics require calibration per domain
- This is auxiliary to prediction; needs lightweight integration into ETL
- Enterprise analytics acceleration in BI/SQL environments
- Sector: Enterprise Analytics, BI
- Use case: Analysts provide a small labeled cohort in SQL/BI and score large cohorts without training new models; useful for campaign propensity, churn segmentation.
- Potential tools/workflows:
- UDF or microservice that accepts (context rows, query rows) and returns predictions
- Feature-store integration to consistently build contexts
- Assumptions/dependencies:
- Access control and PII governance; batch sizes sized to hardware
- Probability calibration and A/B testing before production rollout
- Teaching and curriculum support for ML on tabular ICL
- Sector: Education
- Use case: Demonstrate table-native ICL, sparsity, and hierarchical attention in advanced ML courses and labs.
- Potential tools/workflows:
- Open-source notebooks with ablations (dense vs sparse attention, multi-scale on/off)
- Visualization of attention masks and memory write/read phases
- Assumptions/dependencies:
- GPU access for classroom labs; licensed/open datasets
- Lightweight “ICL for spreadsheets” for small businesses
- Sector: Daily life, SMBs
- Use case: In Excel/Google Sheets, mark a handful of labeled rows and get predictions for the rest (e.g., lead qualification, invoice categorization).
- Potential tools/workflows:
- Add-in calling a cloud inference endpoint; simple UI for selecting context rows
- Assumptions/dependencies:
- Networked deployment; data privacy agreements
- Reasonable table width and dataset size to meet latency/cost constraints
Long-Term Applications
These applications are high-impact but require additional research, engineering, scaling, or regulatory work.
- Enterprise tabular foundation service with cross-task memory
- Sector: Enterprise software, Platform ML
- Use case: Organization-wide few-shot service where teams supply small contexts; reusable memory for recurring schemas and tasks to improve stability and speed.
- Potential tools/workflows:
- Centralized “Tabular ICL Service” with context retrieval, schema canonicalization, and policy-guarded memory
- Assumptions/dependencies:
- Research on safe cross-task memory reuse and governance
- Strong tenancy and audit controls to prevent cross-client leakage
- RegTech-grade, audited ICL pipelines
- Sector: Finance, Healthcare, Public sector
- Use case: Certifiable guarantees of no test leakage and explanations of hierarchical feature interactions for compliance audits.
- Potential tools/workflows:
- Formal verification of ICL masks, lineage logs, per-prediction “no-leakage proofs,” and multi-scale attribution reports
- Assumptions/dependencies:
- XAI methods tailored to multi-scale sparse attention and Perceiver memory
- Standard-setting collaborations with regulators
- Real-time streaming decisioning with rolling contexts
- Sector: AdTech, Fraud/Abuse, Ops
- Use case: Continuous scoring where the context adapts over time (e.g., last N labeled events), memory updated under strict safety constraints.
- Potential tools/workflows:
- Low-latency engines with stateful context windows and streaming feature stores
- Assumptions/dependencies:
- Efficient state management for memory read/write; tight latency budgets
- Robust concept drift detection and context refresh policies
- Federated and edge ICL for privacy-sensitive domains
- Sector: Healthcare, Industrial IoT, Smart city
- Use case: On-device or federated few-shot predictions without centralizing data; sparse attention accelerators on edge hardware.
- Potential tools/workflows:
- Quantized/compiled Orion-MSP variants, hardware-aware sparsity kernels, secure enclave deployment
- Assumptions/dependencies:
- Compiler support for block-sparse ops; model compression/quantization research
- Privacy-preserving orchestration (federated contexts, secure aggregation)
- Personalized medicine and N-of-1 modeling
- Sector: Healthcare, Precision medicine
- Use case: Patient-specific predictions using a small personalized context (e.g., prior visits) plus population exemplars, across high-dimensional labs/omics.
- Potential tools/workflows:
- Clinical decision support integrating EHR tables, lab panels, and genomic features
- Assumptions/dependencies:
- Rigorous clinical trials and generalizability studies
- Robust handling of missingness and harmonization across hospitals
- LLM–tabular hybrid agents for analytics
- Sector: Software, Enterprise analytics
- Use case: LLMs handle schema understanding, data cleaning, and context selection; Orion-MSP handles numeric/tabular reasoning and predictions.
- Potential tools/workflows:
- Agent frameworks where LLM selects context and calls Orion-MSP via tools API; automatic report generation with interpretable summaries
- Assumptions/dependencies:
- Reliable orchestration and guardrails against prompt-induced context bias
- Benchmarks that measure combined system reliability
- Public health and policy rapid modeling
- Sector: Public policy, Epidemiology
- Use case: Fast, few-shot risk estimations during emerging events (outbreaks, disasters) where labeled data are scarce and tables are heterogeneous.
- Potential tools/workflows:
- Government dashboards with curated contexts, uncertainty overlays, and scenario comparisons
- Assumptions/dependencies:
- Data-sharing agreements and governance
- Uncertainty quantification extensions (e.g., context ensembles)
- Energy grid anomaly and fault detection at scale
- Sector: Energy, Utilities
- Use case: Wide, heterogeneous sensor tables per substation; few-shot detection of rare fault types in new assets/regions.
- Potential tools/workflows:
- SCADA-integrated scoring with per-site contexts; hierarchy-aware feature grouping aligned to asset topology
- Assumptions/dependencies:
- High-availability infrastructure; integration with existing OT/IT systems
- Robustness to missing, delayed, or noisy telemetry
- Explainable feature-group discovery tools
- Sector: Cross-sector analytics, Research
- Use case: Use multi-scale grouping to discover semantically meaningful feature clusters and their contributions to decisions.
- Potential tools/workflows:
- Interactive visualization of learned groups and per-scale CLS token attributions; governance reviews of feature reliance
- Assumptions/dependencies:
- Additional interpretability tooling; user studies to validate usefulness for analysts
Notes on Feasibility and Dependencies
- Compute and scaling: Block-sparse attention reduces complexity from quadratic to near-linear in feature count, but extremely wide tables (thousands of features) and large contexts still demand substantial memory/compute and efficient sparse kernels.
- Data hygiene: ICL performance hinges on high-quality, representative context selection; retrieval or curation is a critical dependency.
- Safety and governance: Orion-MSP’s design enforces no test-to-train leakage within a task; end-to-end pipelines must preserve this (correct masking, label injection only on training rows).
- Calibration and fairness: Probabilistic calibration, bias checks, and drift monitoring are recommended before production, especially in regulated sectors.
- Modal coverage: The paper emphasizes classification; regression and survival analysis may require minor adaptations and validation.
- Tooling maturity: Production-grade block-sparse kernels, quantization, and explainability for multi-scale attention/perceiver memory will improve deployability over time.
Glossary
- Additive masking: An attention masking technique where disallowed positions receive negative infinity so they contribute zero after softmax. "where contains $0$ for allowed positions and for disallowed positions (additive masking)."
- Affine map: A linear transformation with an added bias term. "predicts a per-cell affine map, assigning each cell its own weight and bias."
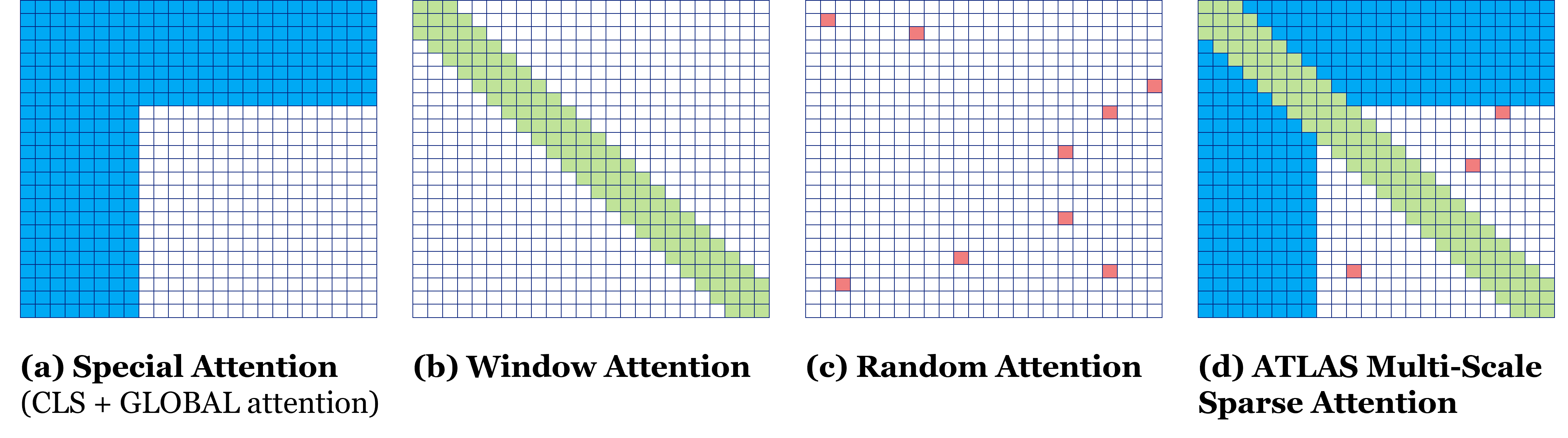
- Block-sparse attention: An attention pattern that restricts connections to structured subsets (e.g., windows, globals, random) to reduce complexity. "structured block-sparse attention patterns combining windowed local attention, global tokens for long-range dependencies, and random connectivity for universal approximation"
- CLS token: A special learnable token used to summarize a sequence or row representation. "prepends learnable [CLS] and [GLOBAL] tokens to "
- Cross-attention: An attention mechanism where one set of queries attends to a different set of keys/values. "Cross-Attention Block: At the core of the memory is a cross-attention mechanism allowing one representation to attend to another."
- Cross-component memory: A shared latent memory enabling information flow between architectural modules without leakage. "Cross-component Perceiver memory enables bidirectional communication: training rows write to latent memory, which all rows read for enhanced representations ."
- Dataset-wise in-context learning: Performing predictions for test samples by conditioning on labeled training examples within the same dataset, in a single forward pass. "The final component, dataset-wise in-context learning ($\text{TF}_{\text{icl}$), leverages these embeddings to predict test labels"
- Dense attention: Full self-attention over all tokens, with quadratic cost in sequence length. "the dense attention mechanisms scale quadratically with feature count ()"
- Diffusion-based representation learning: Using diffusion processes to learn robust data representations. "integrating diffusion-based representation learning, improving robustness to missing values and distributional shifts."
- Element-wise (Hadamard) product: Multiplication applied entrywise between two equal-shaped tensors. "where denotes element-wise (Hadamard) product"
- Gradient Boosted Trees (GBTs): An ensemble method that builds additive models by sequentially training decision trees to correct prior errors. "gradient boosted trees (GBTs) remain the predominant state-of-the-art (SOTA) for tabular prediction tasks."
- Global tokens: Special tokens that attend to (and are attended by) all positions to carry long-range information. "Global tokens: Specialized tokens with full connectivity, ensuring stable long-range information flow."
- Induced Set Attention Blocks (ISAB): Set Transformer blocks that use a small number of learned inducing points to summarize set inputs efficiently. "we employ ISAB \cite{isab} with learnable inducing points."
- Inducing points: Learnable vectors that compress a set’s information for efficient attention. "where denote trainable inducing point embeddings (), which serve as a compressed representation of the column distribution."
- In-context learning (ICL): The ability of a model to perform tasks by conditioning on examples provided in its input without updating parameters. "their remarkable in-context learning (ICL) capabilities"
- Label injection: Incorporating training labels directly into embeddings to condition predictions. "This ICL component employs split attention with label injection, ensuring proper train-test separation."
- Latent memory: A set of learned vectors acting as a bottleneck to store and share global context. "Cross-Component Perceiver Memory: introduces a latent memory bottleneck that enables safe bidirectional communication between modules, promoting iterative refinement without information leakage;"
- Multi-scale hierarchical feature processing: Modeling interactions at multiple granularities (e.g., features, groups) to capture hierarchical structure. "we propose multi-scale hierarchical feature processing that simultaneously captures interactions at multiple granularities"
- Perceiver-style memory: A latent bottleneck inspired by Perceiver that writes from training data and reads for all samples. "a Perceiver-style memory enabling safe bidirectional information flow across components."
- Permutation-invariant: A property where outputs do not depend on the ordering of inputs. "The Set Transformer architecture ensures that $\text{TF}_{\text{col}$ is permutation-invariant with respect to the order of samples within a column."
- Per-head dimension: The dimensionality of each attention head’s queries/keys/values. "and is the per-head dimension."
- Pooling by Multihead Attention (PMA): A method that uses a set of seed vectors attending to inputs to produce a fixed-size pooled representation. "The default grouping strategy uses a learnable soft grouping via Pooling by Multihead Attention (PMA)~\cite{pma} to adaptively attend to features:"
- Pre-norm architecture: Transformer design that applies layer normalization before attention and feed-forward sublayers. "Pre-norm architecture: Layer normalization before each sub-layer"
- Random links: Stochastic additional attention connections to improve expressivity and graph connectivity. "Random links (Optional): For each feature token $i > N_{\text{special}$, we randomly select additional tokens to attend to"
- Rotary positional encoding (RoPE): A positional encoding method that rotates queries and keys to inject relative position information. "Rotary positional encoding (RoPE): Applied to queries and keys before attention~\cite{roformer}"
- Set Transformer: A transformer variant designed for sets, providing permutation invariance and set-level pooling. "using Set Transformers with Induced Set Attention Blocks (ISAB) to create distribution-aware feature embeddings in a permutation-invariant manner."
- Skippable linear layer: A lightly initialized linear layer used for reserved token positions to allow learning from near-zero outputs. "we use a skippable linear layer that outputs zeros or small random values"
- Sliding window attention: Local attention restricted to a fixed-radius neighborhood to reduce complexity. "Sliding window attention: Local connectivity within a fixed radius , preserving fine-grained structure."
- Split attention: An attention scheme that enforces separation between training and test representations. "dataset-level ICL prediction through split attention, ensuring a clear separation between training and test samples."
- Split mask: An attention mask that prevents test-to-train information leakage during ICL. "// ICL Transformer with Split Mask"
- Structural causal models: Generative models based on causal relationships, used to synthesize training data. "meta-training a transformer on synthetically generated datasets using structural causal models."
- Table serialization: Converting rows and columns of a table into text suitable for tokenization by LLMs. "table serialization, which is the process of converting table rows into text or sentences suitable for tokenization."
- Truncated normal distribution: A normal distribution constrained to a bounded range, used for parameter initialization. "drawn from a truncated normal distribution ."
- Universal approximation: Theoretical capability of a model to approximate any function under certain conditions. "random connectivity for universal approximation"
- Zero-shot prediction: Making predictions for unseen tasks without any task-specific gradient updates. "enabling zero-shot predictions without gradient-based fine-tuning."
Collections
Sign up for free to add this paper to one or more collections.