FedMuon: Accelerating Federated Learning with Matrix Orthogonalization
Published 31 Oct 2025 in cs.LG and cs.AI | (2510.27403v1)
Abstract: The core bottleneck of Federated Learning (FL) lies in the communication rounds. That is, how to achieve more effective local updates is crucial for reducing communication rounds. Existing FL methods still primarily use element-wise local optimizers (Adam/SGD), neglecting the geometric structure of the weight matrices. This often leads to the amplification of pathological directions in the weights during local updates, leading deterioration in the condition number and slow convergence. Therefore, we introduce the Muon optimizer in local, which has matrix orthogonalization to optimize matrix-structured parameters. Experimental results show that, in IID setting, Local Muon significantly accelerates the convergence of FL and reduces communication rounds compared to Local SGD and Local AdamW. However, in non-IID setting, independent matrix orthogonalization based on the local distributions of each client induces strong client drift. Applying Muon in non-IID FL poses significant challenges: (1) client preconditioner leading to client drift; (2) moment reinitialization. To address these challenges, we propose a novel Federated Muon optimizer (FedMuon), which incorporates two key techniques: (1) momentum aggregation, where clients use the aggregated momentum for local initialization; (2) local-global alignment, where the local gradients are aligned with the global update direction to significantly reduce client drift. Theoretically, we prove that \texttt{FedMuon} achieves a linear speedup convergence rate without the heterogeneity assumption, where $S$ is the number of participating clients per round, $K$ is the number of local iterations, and $R$ is the total number of communication rounds. Empirically, we validate the effectiveness of FedMuon on language and vision models. Compared to several baselines, FedMuon significantly reduces communication rounds and improves test accuracy.
The paper introduces FedMuon, which applies matrix orthogonalization to weight updates, thereby reducing client drift and the number of communication rounds in federated learning.
It employs local-global alignment and momentum aggregation to preserve optimizer state across rounds, yielding superior accuracy on benchmarks like CIFAR-100 and GLUE.
Empirical results demonstrate linear speedup convergence and a 95% reduction in communication overhead through top-k SVD momentum compression.
FedMuon: Matrix Orthogonalization for Accelerated Federated Learning
Motivation and Background
Federated Learning (FL) enables collaborative model training across decentralized clients while preserving data privacy. The principal bottleneck in FL is the number of communication rounds required for global convergence, especially under data heterogeneity. Conventional local optimizers such as SGD and AdamW perform element-wise updates, disregarding the geometric structure of weight matrices. This neglect leads to ill-conditioned weights, pathological update directions, and slow global convergence. The Muon optimizer, which applies matrix orthogonalization to weight updates, has demonstrated improved convergence and stability in centralized deep learning. The paper introduces FedMuon, a federated optimizer that leverages matrix orthogonalization and addresses the unique challenges of FL, particularly in non-IID regimes.
Matrix Orthogonalization and the Muon Optimizer
Muon operates directly on matrix-structured parameters, applying orthogonalization via Newton-Schulz iteration or SVD to the momentum matrix. For a weight matrix W and momentum M, the update is:
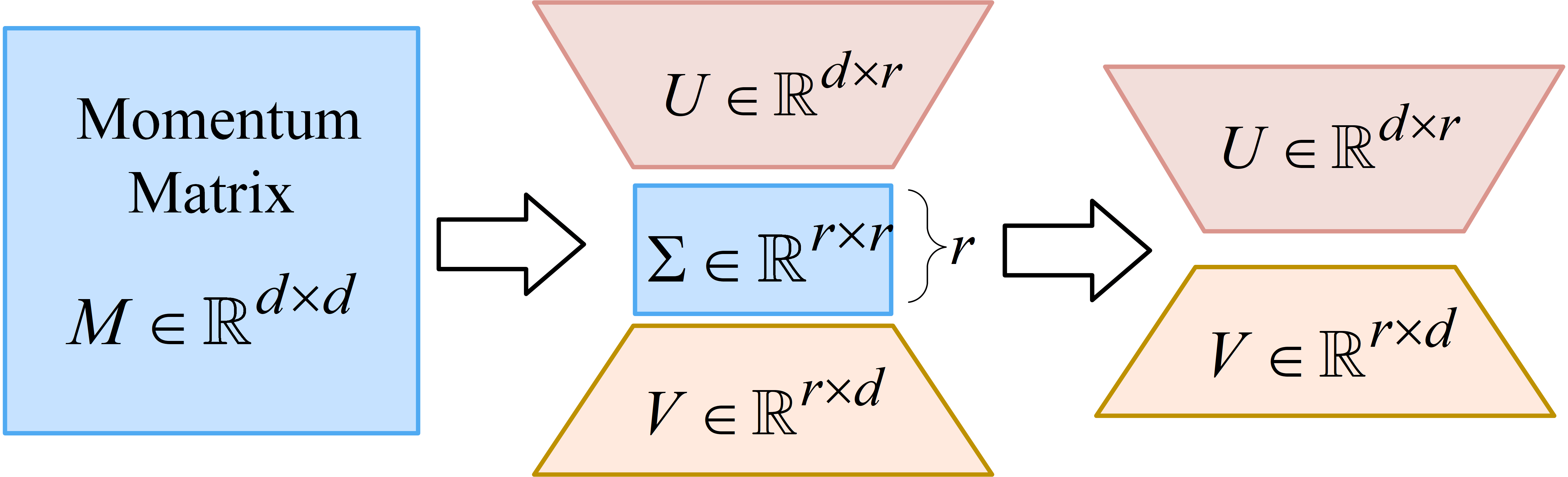
Orthogonalization ensures updates are distributed across all directions, preventing the model from learning only along dominant subspaces. This is illustrated in the SVD-based matrix orthogonalization process.
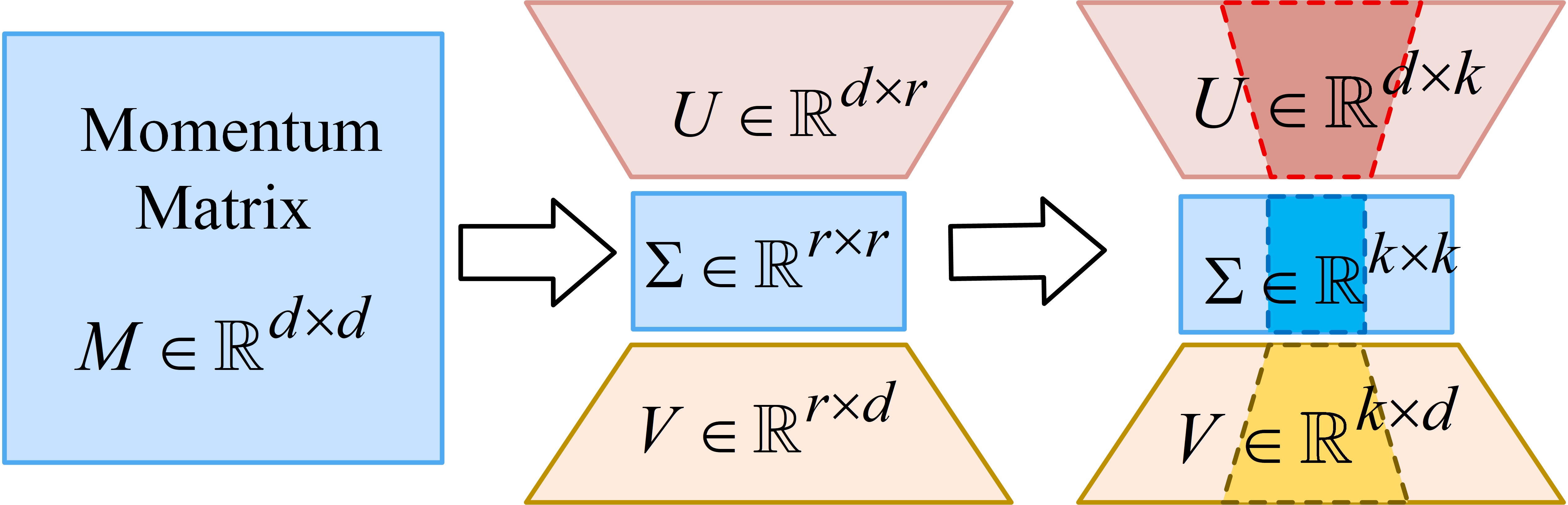
Figure 1: SVD-based matrix orthogonalization and momentum compression, retaining top-k singular vectors for communication efficiency.
Challenges in Federated Settings
Applying Muon directly in FL (Local Muon) accelerates convergence in IID settings but fails under non-IID data due to two main issues:
Client Preconditioner Drift: Each client’s matrix orthogonalization acts as a local preconditioner, misaligning update directions during aggregation and amplifying client drift.
Moment Reinitialization: Resetting momentum at each round erases temporal memory, hindering convergence and exacerbating drift.
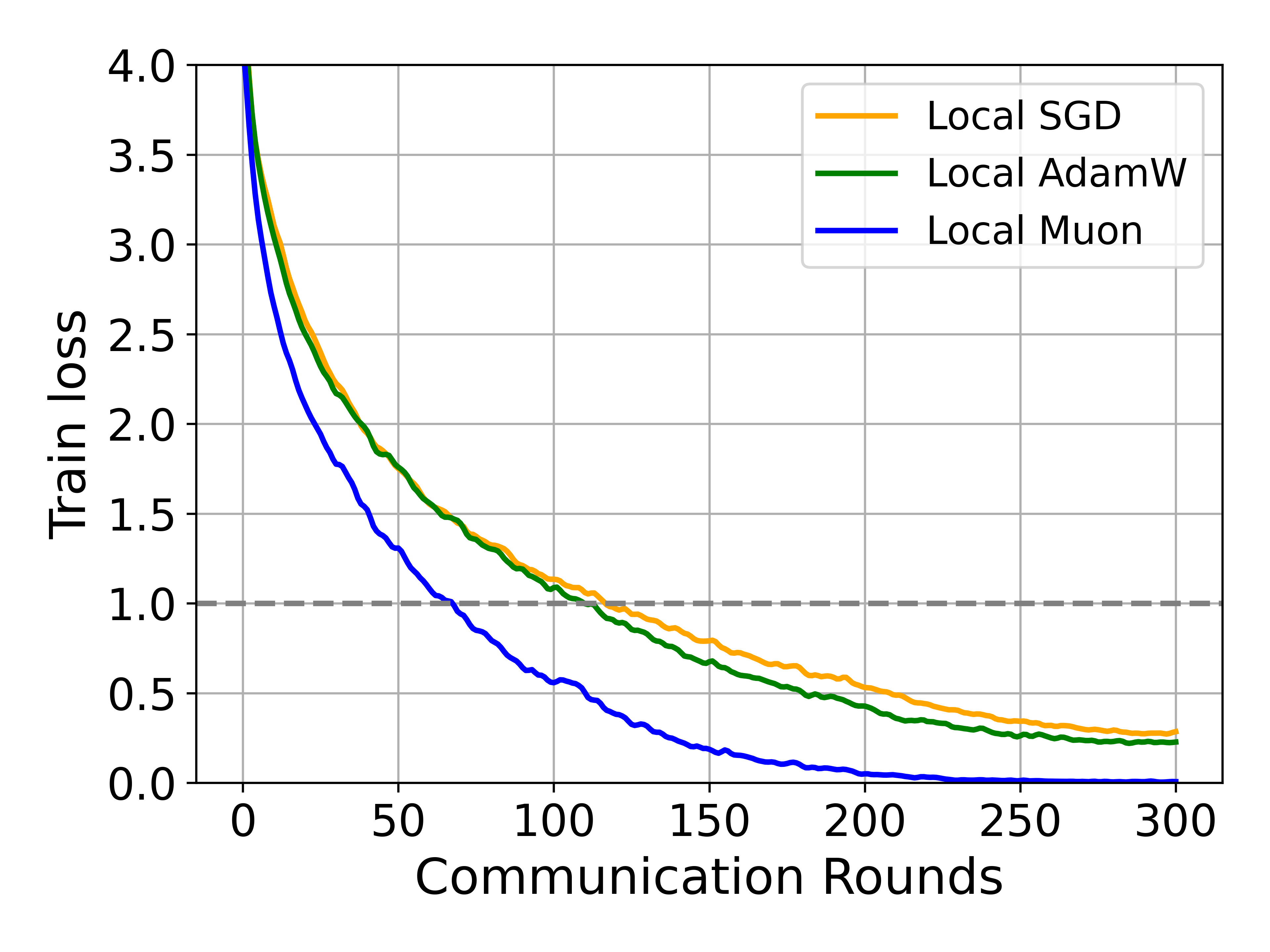
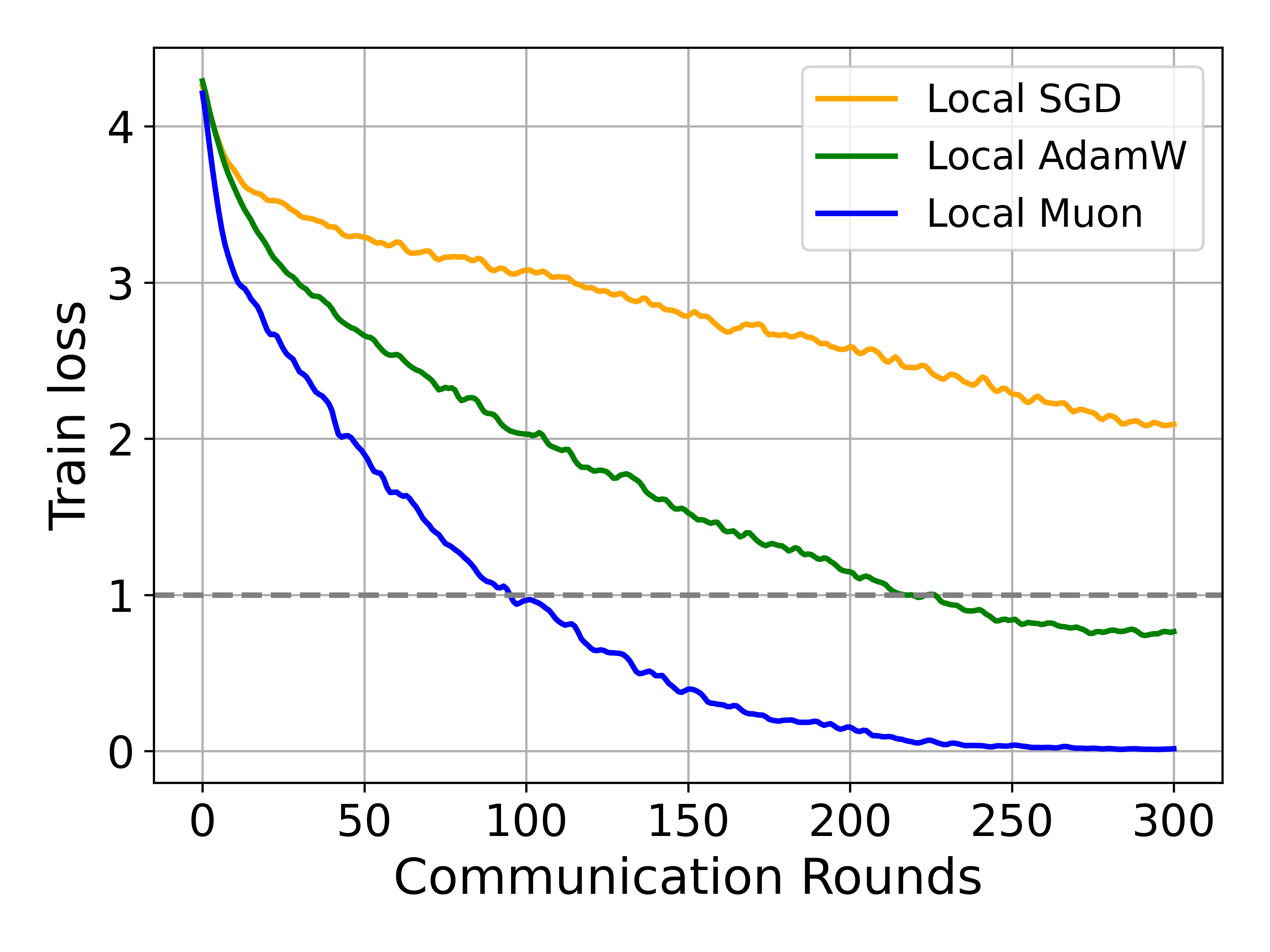
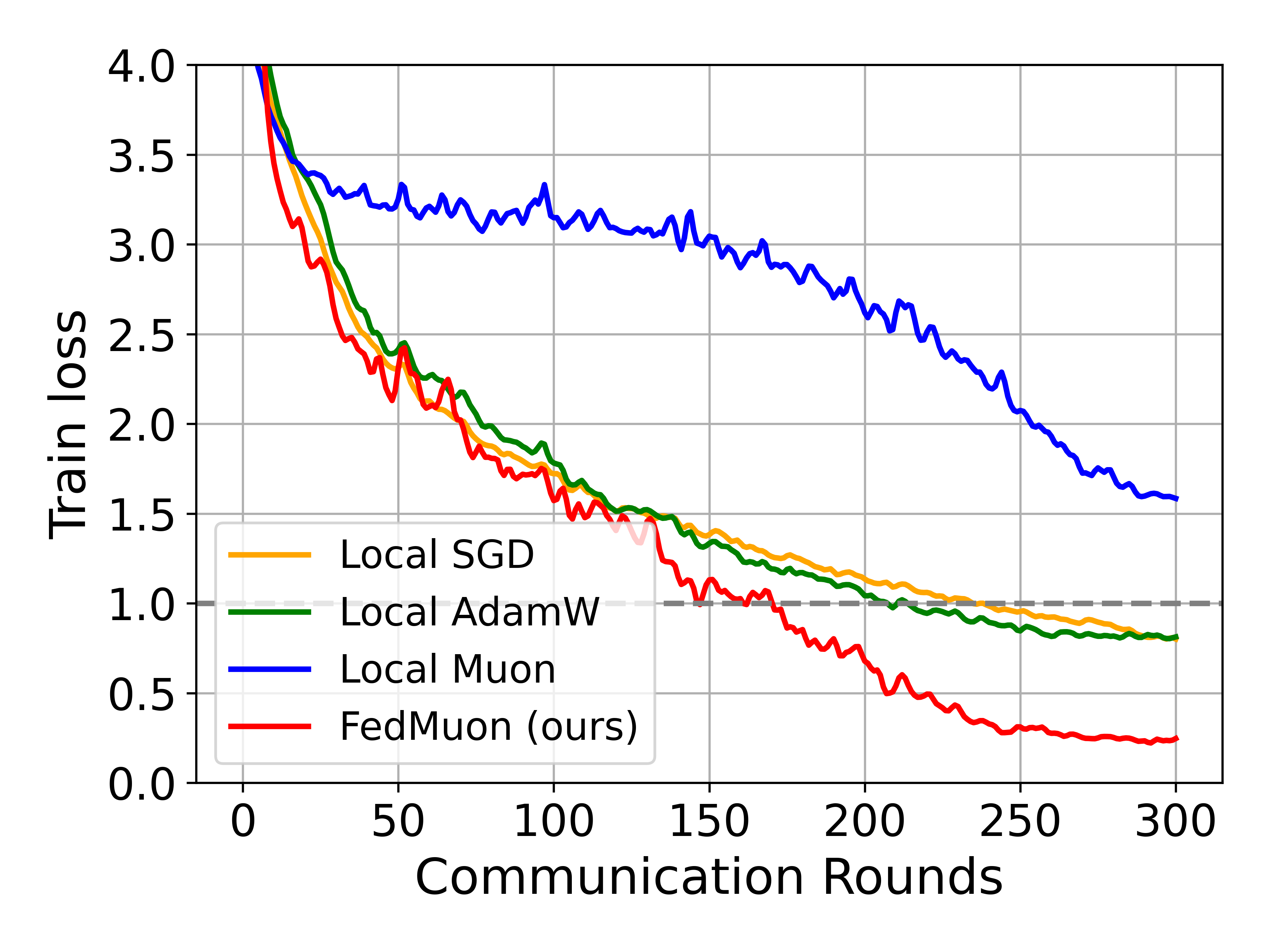
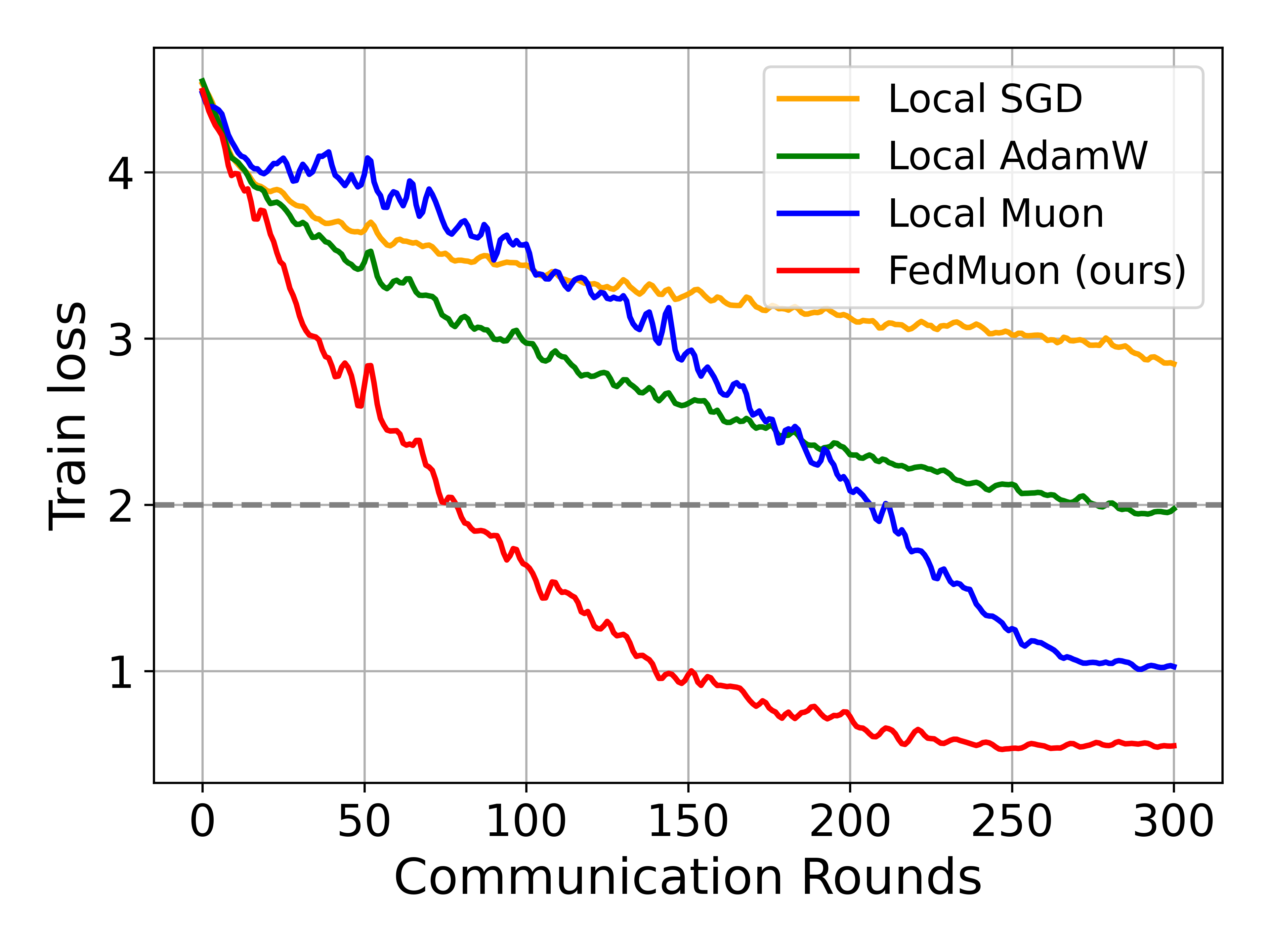
Empirical results show that Local Muon outperforms Local SGD and AdamW in IID settings, but global convergence deteriorates in non-IID scenarios.
Figure 2: Local Muon achieves faster convergence than SGD/AdamW on ResNet-18 under IID partitioning.
FedMuon Algorithm: Local-Global Alignment and Momentum Aggregation
FedMuon introduces two mechanisms to address non-IID challenges:
Local-Global Alignment: Local updates are blended with the global update direction, reducing divergence and improving consistency. The update rule is:
xir,k+1=xir,k−η[(1−α)Uir,kVir,k⊤+αΔGr]
where ΔGr is the estimated global update, and α controls the trade-off.
Momentum Aggregation: Clients initialize local momentum with the aggregated global momentum, preserving optimizer state across rounds and mitigating drift.
To reduce communication overhead, FedMuon compresses momentum matrices using SVD, retaining only the top-k singular values (typically 5% of rank), which reduces communication cost by 95% with negligible performance loss.
Theoretical Analysis
FedMuon achieves a linear speedup convergence rate:
O(SKRLΔσl2+RLΔ)
where S is the number of participating clients per round, K is the number of local iterations, and R is the total number of communication rounds. Notably, this rate does not depend on the data heterogeneity term σg2, in contrast to Local SGD and Local Muon, due to the suppression of client drift via local-global alignment.
Empirical Results
FedMuon is evaluated on vision (CIFAR-100, Tiny ImageNet) and language (GLUE benchmark) tasks using ResNet-18, ViT-Tiny, Swin Transformer, and RoBERTa-Base. Under both low and high heterogeneity (Dir-0.6, Dir-0.1), FedMuon consistently achieves the highest test accuracy and lowest training loss across all models and datasets. For example, on CIFAR-100 with ResNet-18, FedMuon attains 74.12% accuracy (Dir-0.6) and 73.05% (Dir-0.1), outperforming all baselines. On Swin Transformer, FedMuon reaches 84.88% accuracy with minimal communication cost. In NLP tasks, FedMuon surpasses strong baselines on GLUE, especially in challenging tasks such as RTE and QQP.
Ablation and Hyperparameter Analysis
Ablation studies confirm the necessity of both local-global alignment and momentum aggregation. Removing either component degrades performance. The optimal trade-off parameter α is 0.5, balancing local adaptivity and global consistency. The momentum parameter β=0.98 yields the best results, balancing global momentum preservation and responsiveness.
Implementation Considerations
Computational Overhead: Matrix orthogonalization via Newton-Schulz or SVD incurs approximately 5% higher computation time than AdamW.
Communication Efficiency: SVD compression of momentum matrices is essential for scalability, especially in large models.
Deployment: FedMuon is suitable for both vision and LLMs, including Transformers and CNNs, and can be integrated into existing FL frameworks with minor modifications to the optimizer and communication protocol.
Implications and Future Directions
FedMuon demonstrates that structure-aware optimization—treating updates as matrices rather than flat vectors—substantially improves FL efficiency and reliability, especially under non-IID data. The principles of matrix orthogonalization and cross-round momentum aggregation are broadly applicable to distributed training and parameter-efficient fine-tuning of foundation models. Future work may extend FedMuon to other structured optimizers (e.g., LAMB, Lion), explore adaptive SVD compression strategies, and investigate its impact on privacy-preserving FL and large-scale multi-modal models.
Conclusion
FedMuon provides a principled approach to federated optimization by explicitly leveraging matrix structure in local updates and addressing client drift through local-global alignment and momentum aggregation. Theoretical and empirical results substantiate its superior convergence and generalization properties across diverse architectures and data regimes. The methodology sets a precedent for structure-aware optimizers in federated and distributed learning, with significant implications for scalable, communication-efficient training of large models.