Think Twice: Branch-and-Rethink Reasoning Reward Model
Abstract: LLMs increasingly rely on thinking models that externalize intermediate steps and allocate extra test-time compute, with think-twice strategies showing that a deliberate second pass can elicit stronger reasoning. In contrast, most reward models (RMs) still compress many quality dimensions into a single scalar in one shot, a design that induces judgment diffusion: attention spreads across evaluation criteria, yielding diluted focus and shallow analysis. We introduce branch-and-rethink (BR-RM), a two-turn RM that transfers the think-twice principle to reward modeling. Turn 1 performs adaptive branching, selecting a small set of instance-critical dimensions (such as factuality and safety) and sketching concise, evidence-seeking hypotheses. Turn 2 executes branch-conditioned rethinking, a targeted reread that tests those hypotheses and scrutinizes only what matters most. We train with GRPO-style reinforcement learning over structured two-turn traces using a simple binary outcome reward with strict format checks, making the approach compatible with standard RLHF pipelines. By converting all-at-oncescoringintofocused, second-lookreasoning, BR-RMreducesjudgmentdiffusionandimproves sensitivity to subtle yet consequential errors while remaining practical and scalable. Experimental results demonstrate that our model achieves state-of-the-art performance on three challenging reward modeling benchmarks across diverse domains. The code and the model will be released soon.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about building a better “judge” for AI chatbots. When a chatbot gives two possible answers to a question, a judge model (called a reward model) decides which answer is better. The authors introduce a new judge that doesn’t just skim once and score—it “thinks twice.” First, it picks a few things that matter most for that specific question (like facts or safety), then it re-reads the answers focusing only on those. They call this approach Branch-and-Rethink (BR-RM).
Key Objectives
The paper aims to answer straightforward questions:
- Can a judge model do a better job by first choosing what to check and then re-reading carefully?
- Will “thinking twice” help the judge catch subtle mistakes that are easy to miss?
- Can this approach be trained and used with standard AI training systems?
- Does it beat other judge models on well-known tests?
Methods and Approach
Think of a teacher grading essays. If the teacher tries to check everything at once—facts, logic, safety, clarity, style—their attention gets spread too thin. Small mistakes slip through. This paper’s method teaches the AI judge to act more like a careful teacher who plans first, then reviews with focus.
Here’s how the two-turn process works:
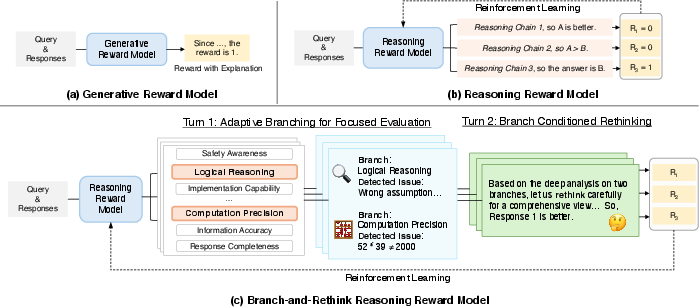
- Turn 1: Adaptive Branching
- The judge picks a small number of key “rubric items” to focus on, chosen from a set like factual accuracy, logical reasoning, safety, instruction following, etc.
- It writes short notes or hypotheses about what might be wrong or worth checking.
- Turn 2: Branch-Conditioned Rethinking
- Now the judge re-reads the answers, but only through the lens of the chosen items.
- It checks the specific things it flagged, like verifying a fact or inspecting a tricky piece of logic.
- Finally, it decides which answer is better.
How it’s trained:
- The training uses reinforcement learning (RL), which is like coaching the judge with points.
- The judge must follow a strict format (two turns with the right structure). Good format gets no penalty; bad format gets a big penalty.
- The final decision (Answer A or Answer B) gets a simple reward: correct decisions are good; wrong ones are bad.
- This setup keeps training simple and compatible with common “RLHF” pipelines used to train chatbots.
Extra details made simple:
- “Judgment diffusion” means attention gets spread too thin across too many criteria, causing shallow checks. The two-turn method fights this by focusing only on what matters most.
- “GRPO-style reinforcement learning” is a stable training method similar to PPO. It helps the judge improve without wild swings.
- The authors also use task-specific priorities (for example, correctness is more important than style in math problems) to guide what the judge should focus on.
Main Findings and Why They Matter
The authors tested their judge on three tough benchmarks that measure how well AI judges pick better answers:
- RewardBench
- RM-Bench
- RMB
What they found:
- BR-RM reached state-of-the-art results across these benchmarks.
- The 14B model had the best overall average performance, and even the 8B model beat some larger, strong baselines.
- Compared to typical judges:
- Simple “score-in-one-number” judges were good in some areas but missed subtle errors.
- Judges that “explain then score” helped, but still tended to spread attention and collapse everything down too quickly.
- Reasoning judges improved things, especially when large, but BR-RM’s focused second pass did even better.
Why this matters:
- Judges that think twice catch quiet factual slips, local logic mistakes, and safety issues more reliably.
- Better judges help train better chatbots, because chatbots learn from what judges reward.
Extra evidence from analyses:
- Ablation studies (turning off parts of the method) show both turns are important:
- Removing the second “rethinking” turn hurts performance the most.
- Doing a generic second pass without focusing on selected items also hurts.
- Trying to cram everything into one big turn leads to shallow checks.
- Reward design matters:
- A simple binary reward with strict format checks works best.
- Fancy scoring scales or indirect signals made training noisy or misaligned with the real goal.
- Training data matters:
- General preference data helps overall accuracy.
- Safety-focused data is crucial for safe decisions.
- Math and code preference data strengthens reasoning and logic.
Implications and Potential Impact
This “think twice” judge design can make AI systems safer, more accurate, and more trustworthy. Because the judge focuses on what’s truly important for each question, it:
- Reduces mistakes that come from style or length bias.
- Detects subtle factual errors and logic bugs.
- Scales well with existing training pipelines (it’s practical, not just theoretical).
Looking ahead, this idea could be extended by:
- Plugging in tools to verify facts (like search or calculators).
- Automatically adapting rubrics to the task at hand.
- Using uncertainty to decide when to spend extra “thinking time.”
In short, the same strategy that helps AI solve problems more reliably—thinking twice—also helps the AI judge that trains and evaluates them.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, framed to be actionable for future research.
- Generalization beyond current benchmarks: The model is evaluated on RewardBench, RM-Bench, and RMB; its robustness on out-of-distribution tasks, non-English prompts, and multimodal settings remains untested.
- End-to-end RLHF impact: The paper optimizes the judge in isolation; it does not demonstrate whether using BR-RM to train a policy (e.g., via RLHF/RLAIF) improves user-facing helpfulness, harmlessness, or reasoning quality relative to scalar RMs.
- Compute and latency trade-offs: Two-turn inference likely incurs extra tokens and wall-clock time; there is no measurement of inference cost, throughput impacts, or cost–accuracy trade-offs versus one-turn judges.
- Adaptive compute gating: The framework always performs two turns; it does not explore dynamically deciding when a second pass is needed (e.g., based on uncertainty) or how deeply to rethink, nor report compute allocation strategies on easy vs. hard instances.
- Branch selection design: The set of nine candidate dimensions and the number of branches selected per instance are fixed; there is no study of optimal dimension sets, automatic criterion discovery, or sensitivity to the number and composition of branches.
- Task-specific hierarchies: The “evaluation hierarchies” are hand-crafted; their provenance, coverage, and generality across tasks are not validated, and there is no exploration of learning or adapting hierarchy weights from data.
- Explanation faithfulness: The paper claims improved sensitivity due to structured traces but does not evaluate whether selected dimensions and issue sketches faithfully reflect real error sources (e.g., via human annotation of error types).
- Bias and robustness: The judge’s susceptibility to known biases (length, position, verbosity, style) and adversarial manipulations (prompt injection, obfuscation, strategic formatting) is not quantified across diverse settings.
- Format enforcement vs. substance: Strict format penalties (-100) may bias optimization toward formatting compliance; the trade-off between format adherence and substantive judgment quality, and parsing error rates for the final decision extraction, are not reported.
- Credit assignment granularity: All tokens receive uniform advantages; alternative credit assignment (per-turn differentiated rewards, token-level weighting, or structured shaping tied to correct sub-analyses) is unexplored.
- Reward shaping alternatives: The binary outcome reward is simple but coarse; the paper does not examine calibrated probability outputs, margin-based preferences, or uncertainty-aware rewards to capture preference strength without the pitfalls found in their scaled-score attempt.
- Data dependence and overfitting: While data ablations identify influential sources (e.g., HelpSteer3, Skywork), there is no evaluation on unseen, open-world tasks or cross-benchmark generalization to detect potential overfitting to popular RM datasets.
- Safety judging capabilities: Although Skywork contributes safety data, there is no focused red-teaming or jailbreak evaluation of BR-RM’s reliability in detecting and penalizing harmful content or manipulative responses.
- Multi-candidate ranking: The model operates on pairwise comparisons; support for listwise ranking (3+ candidates), tournament-style selection, or aggregation methods is not addressed.
- Model scale and efficiency: Results are reported for 8B and 14B models; scaling laws (accuracy vs. parameters vs. compute) and efficiency under smaller footprints (e.g., 1–3B) or quantized deployment conditions are unknown.
- Hyperparameter sensitivity: Key training choices (format penalty magnitude, weight w, number of sampled traces K, KL coefficients) are not subjected to sensitivity analyses; robustness of performance to these settings is unclear.
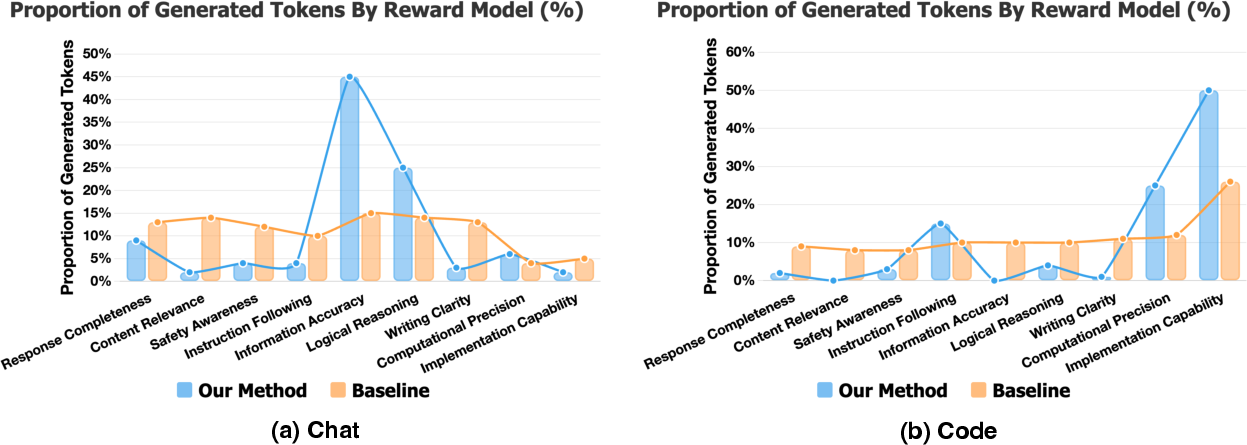
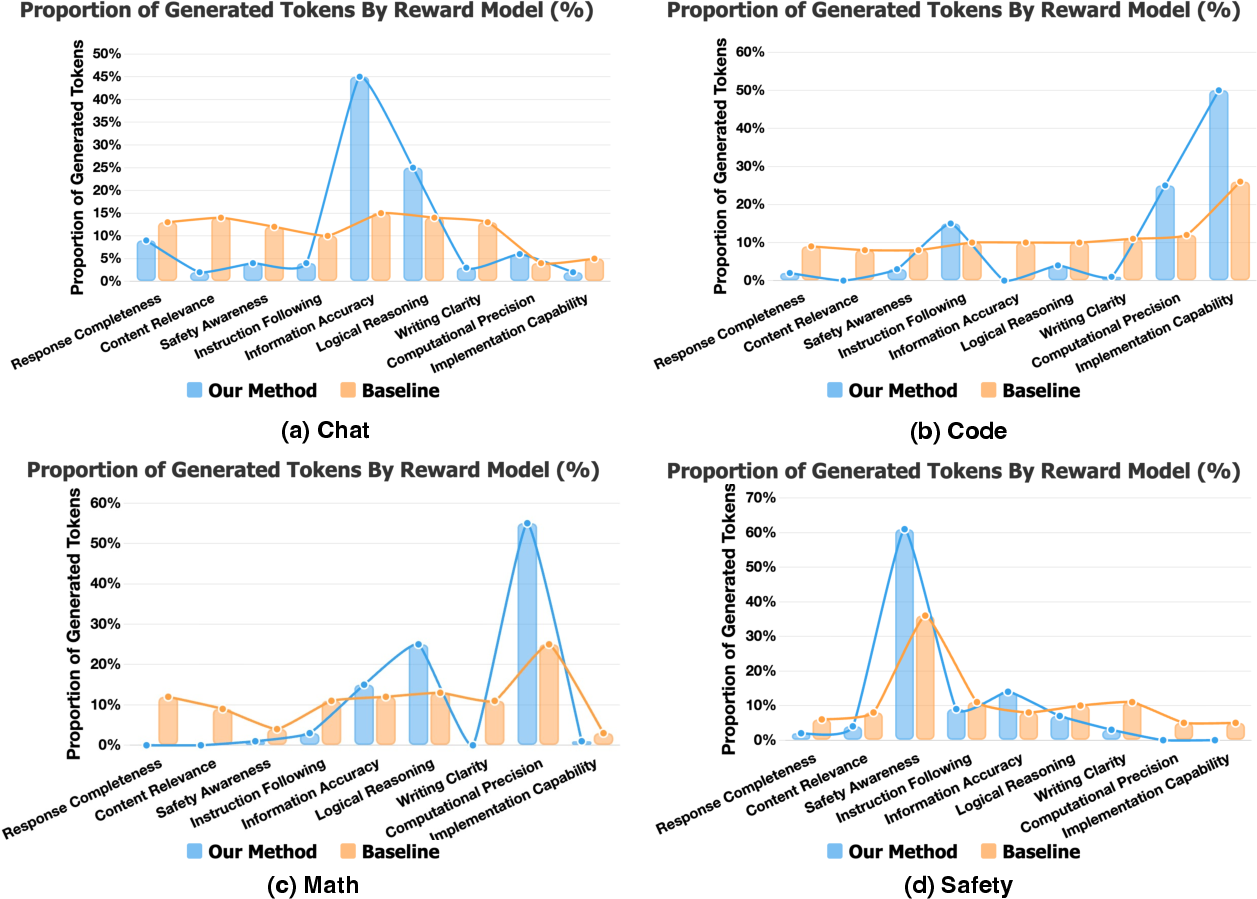
- Compute allocation diagnostics: Beyond a single token-allocation figure, there is no systematic measurement of how BR-RM reallocates tokens across dimensions or instances, nor correlation between allocation patterns and error detection gains.
- Fairness and baseline comparability: Several baselines lack results on certain benchmarks (e.g., RMB), and parameter scales differ; a matched-compute, matched-size study would strengthen comparative claims.
- Tool-augmented verification: Proposed extensions (retrieval, code execution) are not implemented; the gains and failure modes of integrating verifiers into Turn 2 remain open.
- Uncertainty estimation: The framework does not estimate or report confidence in preferences; calibrated probabilities or abstain options could improve reliability, but these are untested.
- Trace quality metrics: There is no metric or automated check for the internal quality of Stage 1 sketches or Stage 2 re-analyses (e.g., factual verification success, logical consistency), beyond the final binary correctness.
- Reproducibility: Code, prompts, and criteria are “to be released”; without them, independent replication of the two-turn format, branching prompts, and extraction procedures is limited.
- Ethical and data licensing considerations: The paper does not discuss licensing, provenance, or potential biases within the training datasets (e.g., synthetic vs. human labels), nor their implications for downstream alignment.
Practical Applications
Immediate Applications
Below are concrete, deployable uses of the paper’s branch-and-rethink reward modeling (BR-RM) in current workflows, organized by sector. Each bullet ends with brief assumptions/dependencies that affect feasibility.
- Industry (LLM providers, SaaS, MLOps)
- RLHF/RLAIF pipeline upgrade: Replace scalar or single-pass GenRM judges with BR-RM for preference modeling to reduce judgment diffusion and catch subtle errors; drop-in with GRPO/PPO infrastructure and binary outcome rewards. Tools/products: NeMo-RL integration, trlx/OpenRLHF adapters, “BR-RM-as-a-service” API. (Dependencies: labeled preference data by domain; extra test-time compute and latency; strict format parsing; KL/reference policy setup.)
- Production guardrails for generative apps: Deploy BR-RM as a two-pass gate over model outputs to enforce safety, factuality, and instruction adherence with instance-adaptive rubrics. Sectors: healthcare (PHI redaction), finance (regulatory statements), enterprise chat. (Dependencies: tuned dimension sets and task hierarchies; latency budgets; high-recall safety data; audit logging.)
- A/B response selection and routing: Use BR-RM to select the best of multiple candidate completions and route borderline cases to human reviewers (HITL). Workflows: experimentation platforms, prompt CI. (Dependencies: traffic load vs cost; calibrated confidence; reviewer bandwidth.)
- Evaluation and regression testing: Make BR-RM the “CI judge” for prompt suites (RewardBench-like checks) to prevent quality regressions in releases. (Dependencies: domain generalization; stable prompts/criteria; versioned eval seeds.)
- Human labeling acceleration: Pre-screen preference pairs with BR-RM and surface concise issue sketches (from Turn 1) to focus annotators, cutting cost/time. (Dependencies: annotation UI integration; reliable parsing; labeler trust/training.)
- Content moderation and trust & safety: Instance-adaptive checks for disallowed content, hallucinated medical/legal claims, or hidden prompts, with escalation on flagged dimensions. (Dependencies: safety rule coverage; bias/fairness audits; transparency to moderators.)
- Software engineering
- Code generation QA: Two-pass checking for logic and safety in code suggestions; optionally trigger unit tests only when “Computation/Correctness” is branched. Tools: CI plugin that fails builds on low reward. (Dependencies: sandboxed runners; language/toolchain coverage; latency.)
- PR review assistant: Prioritize critical issues (security, undefined behavior) via adaptive branching; present concise rationales to reviewers. (Dependencies: repo/CI permissions; secret handling.)
- Knowledge management and documentation QA: Enforce factual accuracy and policy adherence in internal reports or customer-facing artifacts with adaptive checks. (Dependencies: retrieval access to ground truth; domain ontologies; PII controls.)
- Academia and Education
- Research evaluator for LLM benchmarking: Use BR-RM as a robust judge for papers/benchmarks requiring sensitive reasoning checks across criteria. (Dependencies: public model availability; seed/control of stochasticity; reproducibility.)
- Autograding and tutoring: Grade math/logic/short-answer tasks with focused, two-pass rubrics; return issue sketches as formative feedback. LMS plugin/products: “Think-Twice Grader.” (Dependencies: rubric-to-criteria mapping; cheating detection; alignment with institutional policies.)
- Dataset curation: Filter noisy preference pairs and mine “hard cases” from BR-RM’s branch-conditioned uncertainty or disagreements. (Dependencies: uncertainty calibration; de-duplication; privacy compliance.)
- Policy and Governance
- Internal AI safety audits: Run BR-RM as an evaluator that produces audit-ready, structured traces on high-risk prompts (e.g., biosafety, financial advice) to support internal risk reviews. (Dependencies: trace retention and access controls; red-teaming coverage; legal oversight.)
- Procurement and model validation checklists: Require vendors to demonstrate two-pass evaluator performance on standard/risk-specific suites (RewardBench, RM-Bench) before deployment. (Dependencies: standardized tasks; regulatory alignment; accepted test batteries.)
- Daily Life and Productivity
- Personal writing and fact-checking assistant: Second-pass verifier that flags likely factual slips or logical inconsistencies in drafts and emails, focusing only on critical dimensions. (Dependencies: latency tolerance; source citations; user privacy.)
- Personal finance helpers: Verify arithmetic and categorization in budgets/summaries via “Computation/Correctness” branching; escalate uncertain items to the user. (Dependencies: bank data permissions; explainability; on-device vs cloud.)
- Safer parental controls: Adaptive checks on generated content for minors, with two-pass scrutiny of safety and appropriateness. (Dependencies: age-tiered policies; false-positive rates; localization.)
Long-Term Applications
These use cases need further research, domain data, scaling, tool integration, or regulatory clearance before broad deployment.
- Healthcare
- Clinical assistant gating: Two-pass evaluator for clinical notes, patient education, and order sets, prioritizing factual correctness and contraindications before content is shown to clinicians/patients. (Dependencies: FDA/EMA regulatory pathways; high-quality clinical preference data; PHI-safe infrastructure; domain-specific criteria and task hierarchies.)
- Structured verification pipelines: Integrate BR-RM with retrieval (guidelines, EHR facts) and medical calculators during Turn 2 to verify claims. (Dependencies: tool reliability; audit trails; coverage of specialties.)
- Finance and Legal
- Compliance-first document generation: Branch on “Regulation/Policy Adherence” and “Factual Accuracy” for filings, research notes, or contracts; produce traceable justifications for compliance teams. (Dependencies: statutory corpora; liability frameworks; human sign-off; robust change tracking.)
- Real-time advisory gating: Evaluate trading/risk explanations before execution in agentic systems; escalate when subtle reasoning flaws are detected. (Dependencies: ultra-low-latency constraints; market data feeds; guardrails against Goodharting.)
- Robotics and Autonomy
- Plan/skill evaluation: Use BR-RM to score task plans or natural-language policies for safety, constraint satisfaction, and environment fit, with conditioned rethinking tied to sensor evidence. (Dependencies: sim-to-real reliability; real-time budgets; multi-modal inputs; failure recovery.)
- Reward shaping for language-driven controllers: Provide structured, two-pass rewards during training to curb shallow heuristics in long-horizon tasks. (Dependencies: non-stationary rewards; stability with policy learning; compute.)
- Education at Scale
- Nationwide formative assessment: Two-pass, rubric-aligned grading and feedback for open-ended responses, with content validity checks that adapt to question type. (Dependencies: psychometric validation; fairness across demographics; alignment with standards/curricula.)
- Public Policy and Safety
- External model certification: Require two-pass evaluators with transparent traces for high-stakes domains (health, law, critical infrastructure) as part of certification regimes. (Dependencies: accepted standards; test-of-time reproducibility; third-party audit ecosystems.)
- Continuous post-deployment monitoring: BR-RM-backed watchdogs that sample production traffic, run branch-conditioned checks on drifted prompts, and trigger targeted mitigations. (Dependencies: privacy-preserving logging; incident response; drift detection.)
- Tool-Augmented Reasoning Systems
- Adaptive verification toolchains: Turn 2 automatically calls retrieval, calculators, code runners, or theorem provers only for the selected dimensions—minimizing unnecessary tool use. Products: “Selective Tool Orchestrator.” (Dependencies: tool reliability; sandboxing; provenance tracking.)
- Active learning orchestrators: Use branching patterns and rethinking disagreements as acquisition functions to select training data that maximally reduces failure modes. (Dependencies: uncertainty calibration; cost-effective relabeling; diverse pool sampling.)
- Consumer and Edge
- On-device two-pass judges: Distilled BR-RMs for mobile/edge to perform privacy-preserving second-look checks on drafts or summaries without cloud calls. (Dependencies: compression/quantization; energy constraints; acceptable latency.)
- Multimodal extensions: Apply branch-and-rethink to image/text/video outputs (e.g., misinformation detection in media). (Dependencies: multimodal criteria design; dataset breadth; safety policy coverage.)
Cross-cutting assumptions and risks
- Data availability and licensing: High-quality, domain-specific preference pairs (e.g., safety, medical, legal) are essential for reliable focus and rethinking.
- Cost and latency: Two turns add compute; batching, token budgets, and early stopping heuristics may be needed for production SLAs.
- Robust parsing and format enforcement: Strict format checks and resilient parsers are required to avoid brittleness.
- Generalization and bias: Criteria selection and hierarchies must be tested for fairness and domain transfer; periodic audits are needed.
- Goodhart’s law and overfitting: When used as a training reward, agents may exploit the judge; randomized spot-checks and adversarial audits mitigate this.
- Governance: In high-stakes settings, human oversight, audit trails, and regulatory alignment remain mandatory.
Glossary
- Ablation study: A controlled analysis where components are removed to measure their contribution to performance. "including the ablation study of our training recipes"
- Adaptive allocation: Dynamically distributing computation or attention based on instance difficulty or uncertainty. "deliberate, multi-step inference and adaptive allocation"
- Adaptive Branching: A first-turn procedure that selects a small set of critical evaluation criteria to focus analysis. "Turn~1 performs adaptive branching, selecting a small set of instance-critical dimensions (such as factuality and safety) and sketching concise, evidence-seeking hypotheses."
- Alignment pipelines: End-to-end processes (e.g., RLHF) that align model behavior with human preferences using reward models. "Reward models (RMs) are central to alignment pipelines such as RLHF, converting human or AI preference signals into scalar rewards for optimization"
- All-at-once scoring: A single-pass grading approach that aggregates all quality dimensions into one decision. "By converting all-at-once scoring into focused, second-look reasoning"
- Binary outcome reward: A reward signal that assigns success/failure based solely on the correctness of the final decision. "using a simple binary outcome reward with strict format checks"
- Branch-Conditioned Rethinking: A second-turn targeted reread conditioned on the issues identified during branching. "Turn~2 executes branch-conditioned rethinking, a targeted reread that tests those hypotheses and scrutinizes only what matters most."
- Branch-and-Rethink (BR-RM): A two-turn reward modeling framework that enforces focused evaluation followed by a conditioned second pass. "We introduce branch-and-rethink (BR-RM), a two-turn RM that transfers the think-twice principle to reward modeling."
- Chain-of-thought: Explicit intermediate reasoning steps produced by a model to improve multi-step problem-solving. "chain-of-thought, scratchpads, and reflect-revise traces"
- Clipped surrogate objective: A PPO-style objective that clips the probability ratio to stabilize training. "via a clipped surrogate objective and a KL-divergence penalty against a reference policy"
- Critic-free advantage: An advantage estimate computed without a learned value function, often normalized per group. "Here is a group-relative, critic-free advantage"
- Deliberation trace: The generated, structured reasoning sequence (possibly multi-turn) that culminates in a decision. "to generate a two-turn deliberation trace"
- Direct Preference Optimization (DPO): A training method that directly optimizes a model to match preference labels without explicit reward modeling. "iterative Direct Preference Optimization"
- Generative Reward Models (GenRMs): Reward models that produce a critique or rationale before emitting a score. "Generative Reward Models (GenRMs) ask the judge to explain before scoring: the RM first produces a short critique or rationale and then outputs a number"
- Generalized Reward Policy Optimization (GRPO): A PPO variant used to optimize policies under reward signals, balancing stability and efficiency. "We employ Generalized Reward Policy Optimization (GRPO, \citealt{shao2024deepseekmath}), a variant of PPO, chosen for its training stability and sample efficiency."
- Holistic score: An overall score that implicitly aggregates multiple evaluation dimensions in one number. "Scalar RMs typically output a single holistic score per response"
- Inductive bias: Built-in structural assumptions that guide model evaluation or learning. "provide a structured inductive bias."
- Instance-adaptive focus: Adjusting evaluation attention to the dimensions most relevant for the specific instance. "do not enforce instance-adaptive focus or a second pass conditioned on discovered issues."
- Instance-critical dimensions: The most salient criteria (e.g., factuality, safety) for judging a particular instance. "selecting a small set of instance-critical dimensions"
- Judgment diffusion: Attention spreading across many criteria, leading to diluted focus and shallow analysis. "a design that induces judgment diffusion: attention spreads across evaluation criteria, yielding diluted focus and shallow analysis."
- KL-divergence penalty: A regularization term that penalizes deviation from a reference policy to stabilize training. "a KL-divergence penalty against a reference policy"
- Length bias: A spurious tendency for evaluators to prefer longer outputs regardless of quality. "including length and position biases"
- Policy (πθ): The generative model viewed as a decision-making policy that outputs the evaluation trace. "We instead train a policy to generate a two-turn deliberation trace"
- Preference accuracy: The metric measuring how often a model selects the human-preferred response. "model performance was measured by preference accuracy"
- Preference function: A learned function that determines which of two responses is preferred for a given prompt. "The standard reward modeling task is to learn a preference function"
- Probability ratio: The ratio between current-policy and reference-policy probabilities used in PPO-style objectives. "where $\rho(\tau) = \frac{\pi_\theta(\tau)}{\pi_{\text{ref}(\tau)}$ is the probability ratio."
- Proximal Policy Optimization (PPO): A reinforcement learning algorithm that improves policies via clipped updates. "a variant of PPO"
- Reference policy: A fixed or prior policy used to compute KL penalties during training. "against a reference policy $\pi_{\text{ref}$"
- Reinforcement Learning from Human Feedback (RLHF): Training that uses human preference signals to shape model behavior via rewards. "RLHF- and RLAIF-style pipelines"
- RLAIF: Reinforcement Learning from AI Feedback, using AI-generated preferences instead of human labels. "RLHF- and RLAIF-style pipelines"
- Reward Model (RM): A model that converts preference signals into scalar rewards for training or evaluation. "Enter Reward Models (RMs), the workhorse that turns preference signals into scalar rewards in RLHF- and RLAIF-style pipelines"
- Scalar RMs: Reward models that output a single numerical score without generating a rationale. "Scalar RMs typically output a single holistic score per response"
- Scratchpads: Intermediate working notes or computations produced by a model to support reasoning. "chain-of-thought, scratchpads, and reflect-revise traces"
- Self-consistency: A reasoning technique that samples multiple reasoning paths and aggregates the final answers. "self-consistency demonstrate that explicitly externalizing intermediate steps improves accuracy and interpretability in multi-step tasks"
- Strict format checks: Enforcement mechanisms ensuring the model outputs adhere to a prescribed structure. "strict format checks"
- Structured two-turn traces: Deliberation outputs separated into two stages, each with specific roles. "over structured two-turn traces"
- Task-specific evaluation hierarchies: Ordered criteria that prioritize what to check first for different task types. "we incorporate task-specific evaluation hierarchies, $\mathcal{H}_{\text{task}$"
- Test-time compute: The amount of computation allocated during inference rather than training. "allocate extra test-time compute"
- Think-twice strategies: Methods that deliberately perform a second pass to improve reasoning quality. "with think-twice strategies showing that a deliberate second pass can elicit stronger reasoning"
- Token budget: The number of tokens the model is allowed to generate or analyze for a task. "allocates its generative token budget across different evaluation dimensions."
- Two-turn RM: A reward model that evaluates in two sequential turns (branching then rethinking). "a two-turn RM that transfers the think-twice principle to reward modeling"
- Whitened advantage: An advantage value standardized by subtracting mean and dividing by standard deviation. "use this centered (whitened) value as "
Collections
Sign up for free to add this paper to one or more collections.