- The paper introduces a modular framework that uses minimal cross-attention adapters to align frozen T2A models with video, achieving competitive temporal and semantic fidelity.
- It leverages pretrained video encoders with token pooling and RoPE to efficiently capture spatial context and optimize audio-video alignment.
- Evaluation on curated benchmarks shows that Foley Control delivers strong synchronization using significantly less paired data and fewer trainable parameters compared to existing systems.
Foley Control: A Lightweight Bridge for Video-Guided Text-to-Audio Generation
Introduction
Foley Control presents a modular framework for video-guided Foley synthesis that leverages frozen, high-fidelity text-to-audio (T2A) models and pretrained video encoders. The method introduces a minimal cross-attention bridge, enabling temporal and semantic alignment between video and generated audio without retraining large generative backbones. This approach is motivated by the practical constraints of production environments, where retraining or fine-tuning foundation models is often infeasible due to data, compute, and modularity requirements. Foley Control demonstrates competitive performance on curated benchmarks, achieving strong synchronization and semantic fidelity with a fraction of the trainable parameters and paired data required by fully multimodal systems.
Architectural Overview
Foley Control integrates V-JEPA2 video embeddings with a frozen Stable Audio Open DiT backbone via compact video cross-attention modules. The architecture is designed to preserve the strengths of the pretrained T2A model—audio fidelity and prompt-driven controllability—while introducing just enough trainable capacity to align audio with video timing and dynamics.
The forward flow is as follows: video frames are encoded by V-JEPA2, pooled into compact tokens, and injected into the DiT blocks via cross-attention after text conditioning. This ordering ensures that text prompts establish global semantics, while video refines local timing and dynamics.
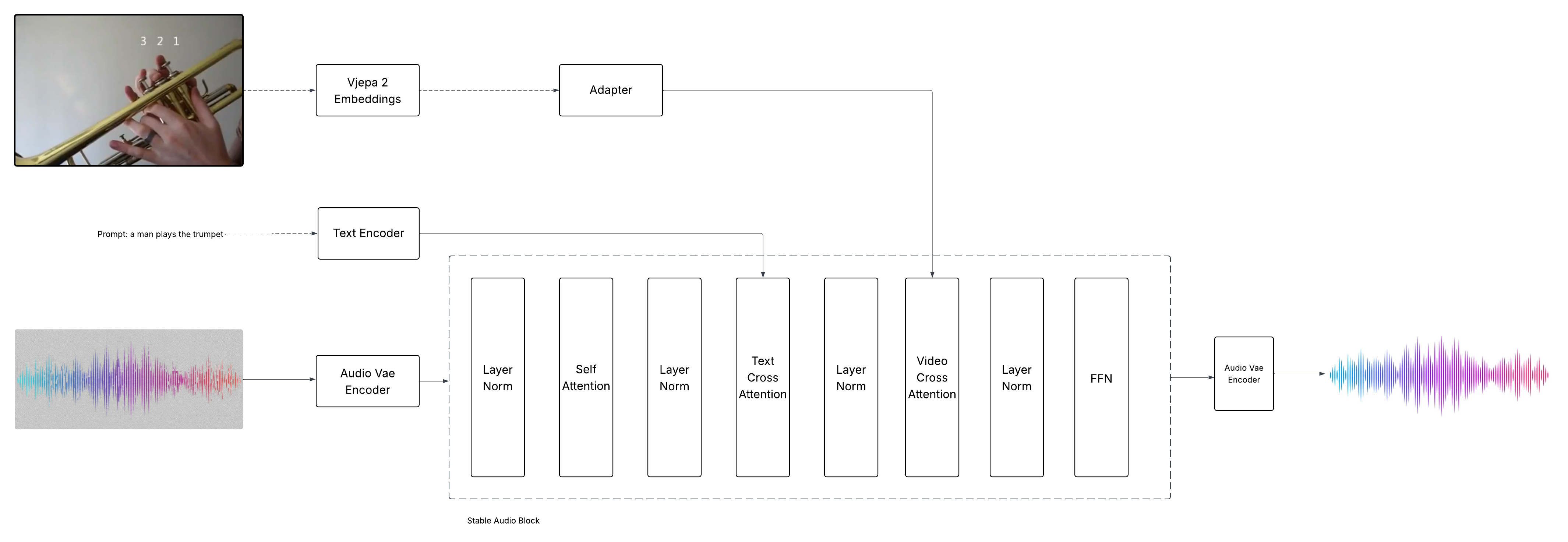
Figure 1: Forward flow: frames → V\textendash JEPA2 → adapter (video vCA), prompt → text encoder (Tx\textendash CA), and noise (latent init) entering the DiT at the same level.
Key architectural choices include:
- Frozen Backbone: All parameters of the Stable Audio Open DiT, VAE, and text encoder remain frozen.
- Video Cross-Attention: Inserted after text cross-attention in each DiT block, with audio latents as queries and video tokens as keys/values.
- MLP Adapter: A lightweight two-layer MLP processes video features before cross-attention.
- Rotary Position Embeddings (RoPE): Applied independently to audio and video sequences, providing temporal ordering cues without specialized synchronization modules.
- Token Pooling: V-JEPA2 outputs are pooled to one token per effective frame, balancing spatial context and computational efficiency.
This design enables modularity: encoders or the T2A backbone can be swapped or upgraded without end-to-end retraining, supporting evolving production pipelines.
Dataset Curation and Training Protocol
The training corpus is derived from Kinetics-700, filtered for high-quality, semantically consistent audio–video pairs using ImageBind and Meta Audiobox Aesthetics scores. Silent or low-quality samples are excluded, resulting in a dataset that is orders of magnitude smaller than those used by fully multimodal systems (e.g., HunyuanVideo-Foley).
Training is performed with a batch size of 12, updating only the collaboration layers. The backbone remains frozen, and token-drop regularization is applied. Evaluation is conducted on the MovieGenBench test set, emphasizing long-form cinematic scenes and ambient soundscapes.
Ablation Studies: Pooling Strategies
Ablations compare frame pooling (one token per two frames) versus grid-based pooling (8×8 tokens per frame) for V-JEPA2 embeddings. The KL-PANNs metric is used to assess alignment quality.
Results indicate that single pooled embeddings match or slightly outperform grid-based embeddings, with negligible differences in temporal alignment and perceptual fidelity. This supports aggressive pooling as a means to reduce compute and memory without sacrificing performance.
(Figure 2)
Figure 2: Ablation trends across training steps for different pooling strategies, evaluated with the KL-PANNs metric (lower is better) on the Kinetics-700 validation subset.
Comparative Evaluation
Foley Control is benchmarked against state-of-the-art systems including MMAudio, HunyuanVideo-Foley, ThinkSound, FRIEREN, and FoleyCrafter. All models are evaluated on MovieGenBench using consistent protocols and metrics:
- ImageBind Score (IB): Audio–visual semantic consistency.
- KL Divergence (KL-PANNs, KL-PaSST): Distributional consistency.
- Fréchet Distance (FD-VGG, FD-PANNs, FD-PaSST): Embedding alignment.
- DeSync Score: Temporal misalignment.
Foley Control achieves competitive scores, particularly in semantic and temporal alignment, despite training on significantly less paired data and with far fewer trainable parameters. For example, it operates with ∼43× less paired data than HunyuanVideo-Foley, yet delivers comparable synchronization and semantic fidelity.
Implementation Considerations
- Computational Efficiency: The framework is highly efficient, requiring only the training of lightweight cross-attention adapters. This enables rapid iteration and deployment in resource-constrained environments.
- Modularity: The frozen backbone and adapter design allow for easy swapping of video encoders or T2A models, facilitating upgrades and integration with evolving production systems.
- Scalability: The approach scales to longer contexts and diverse scenes, with token pooling and RoPE ensuring stable optimization and alignment.
- Limitations: The current setup caps video duration and may miss fine-grained spatial cues. It does not explicitly model spatial acoustics or streaming alignment.
Implications and Future Directions
Foley Control demonstrates that strong video–audio alignment can be achieved by bridging pretrained single-modality models with minimal trainable capacity. This has practical implications for production workflows, where modularity, controllability, and efficiency are paramount. The approach suggests that future multimodal systems may benefit from similar adapter-based strategies, leveraging foundation models while minimizing retraining.
Potential future developments include:
- Adaptive Tokenization: Learned pooling or budget-aware routing for finer spatial and temporal control.
- Longer-Context Conditioning: Extending the framework to handle longer video segments and more complex scenes.
- Spatial Audio Generation: Incorporating binaural or ambisonic modeling for immersive soundscapes.
- Robustness: Enhancing performance on in-the-wild edits, background music, and noisy inputs.
- Extension to Other Modalities: Applying the bridge design to speech, dialogue, or other audio modalities.
Conclusion
Foley Control introduces a practical, efficient framework for video-guided Foley synthesis by aligning a frozen T2A model to video via lightweight cross-attention adapters. The method achieves competitive alignment and fidelity with minimal data and compute, supporting modularity and prompt-driven control. Ablations confirm that aggressive pooling of video tokens preserves performance, and comparative evaluations validate the approach against state-of-the-art systems. Future work may address longer contexts, spatial audio, and broader modality coverage, further enhancing the utility of adapter-based multimodal generation.

