- The paper demonstrates a hierarchical multi-agent framework (AutoPage) that automates project webpage creation by decomposing the task into planning, multimodal content generation, and interactive rendering.
- It introduces PageBench, a comprehensive benchmark that evaluates content quality, visual aesthetics, and semantic fidelity using metrics like cosine similarity and aesthetic scores.
- The system achieves significant improvements over end-to-end LLMs, offering low-cost generation (under $0.1) and flexible human-in-the-loop interventions for precise output.
Human-Agent Collaborative Paper-to-Page Crafting for Under \$0.1: An Expert Analysis
The paper addresses the automation of project webpage generation from academic papers, a task that, despite its importance for research dissemination, has remained largely manual and labor-intensive. Existing automation efforts have focused on static formats (slides, posters, videos), but these approaches are ill-suited for the dynamic, interactive, and visually demanding nature of modern project webpages. The authors argue that a monolithic, end-to-end LLM approach is insufficient due to the complexity and multimodality of the task, as well as the need for factual accuracy and authorial alignment.
AutoPage: Hierarchical Multi-Agent System
The core contribution is AutoPage, a multi-agent system that decomposes the paper-to-page task into a hierarchical, coarse-to-fine pipeline, integrating both automated verification and optional human-in-the-loop feedback. The system is structured into three main phases:
- Narrative Planning and Structuring: The system parses the source PDF into a structured asset library (text, figures, tables) using tools like MinerU and Docling, then generates a web-optimized narrative outline via LLM-based planning agents.
- Multimodal Content Generation: Textual content is generated first for each section, followed by the selection and placement of visual elements, ensuring semantic alignment. Automated checkers verify the consistency between text and visuals, and human feedback can be incorporated for further refinement.
- Interactive Page Rendering: Content modules are integrated into user-selected or automatically matched templates, with final HTML/CSS/JS generation. Automated layout checkers and optional human feedback ensure visual and structural quality.
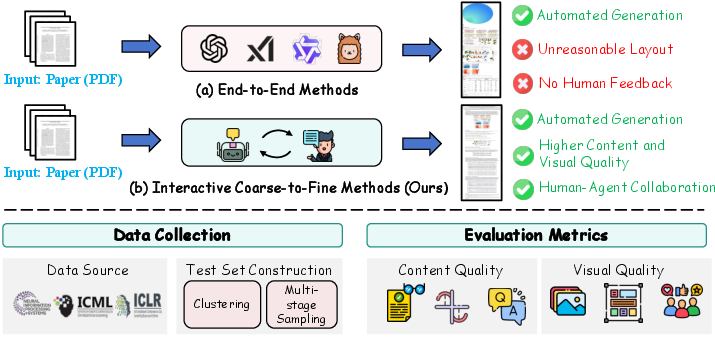
Figure 1: Overview of the AutoPage system, contrasting end-to-end LLM approaches with the proposed human-agent collaborative pipeline and illustrating the PageBench benchmark construction.
This architecture enables both fully autonomous operation and flexible human intervention, supporting a spectrum of use cases from rapid batch generation to author-guided customization.
PageBench: Benchmark and Evaluation Protocol
To enable rigorous evaluation, the authors introduce PageBench, a benchmark dataset comprising over 1,500 academic papers and their corresponding human-authored project pages, sampled from major AI conferences. The evaluation protocol is designed to prevent information leakage by decoupling content and layout, requiring models to generate content for a given paper using a template from a different paper.
The evaluation suite includes:
- Content Quality: Readability (Perplexity), Semantic Fidelity (embedding-based cosine similarity), and Compression-Aware Information Accuracy (QA-based factual correctness modulated by compression ratio).
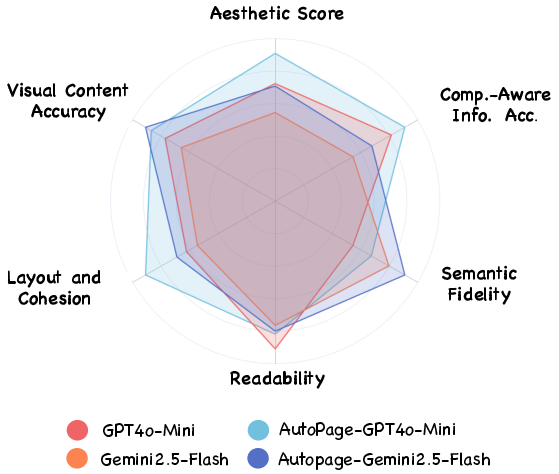
- Visual Quality: Visual Content Accuracy (formula/image rendering and relevance), Layout and Cohesion (structural integrity, white space, balance), and Aesthetic Score (overall visual impression), all assessed via VLM-as-Judge protocols.
Experimental Results
AutoPage consistently outperforms end-to-end LLM baselines across all metrics and backbone models. Notably, it achieves:
Ablation studies confirm that the verifier modules (content and HTML checkers) are critical for maintaining high visual and semantic quality, with their removal leading to significant performance degradation.
Model-Agnostic Enhancement and Equalization
AutoPage demonstrates model-agnostic adaptability, providing substantial gains even for weaker open-source backbones (e.g., Qwen3-235B). The system narrows the performance gap between strong and weak models, with larger relative improvements observed for the latter, effectively "equalizing" baseline disparities.
Human Preference and Qualitative Analysis
A user study with 20 expert participants, employing a forced-choice ranking protocol, shows that AutoPage-generated pages are most preferred (mean score 7.16/10), outperforming both proprietary and open-source baselines.
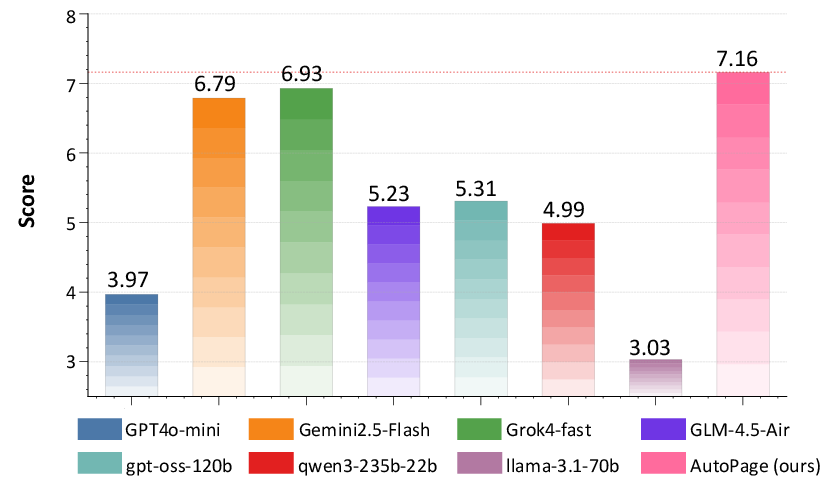
Figure 3: Human preference study, with AutoPage achieving the highest user preference score among all baselines.
Qualitative comparisons highlight AutoPage's superiority in formula rendering, image layout, table presentation, and content planning. Baseline methods frequently fail in these areas, producing visually broken or semantically incoherent pages.

Figure 4: Qualitative comparison illustrating AutoPage’s superior generation quality in formula presentation, image layout, table presentation, and content planning.
Additional visualizations further demonstrate AutoPage's robustness in handling complex layouts, image scaling, and content integrity.
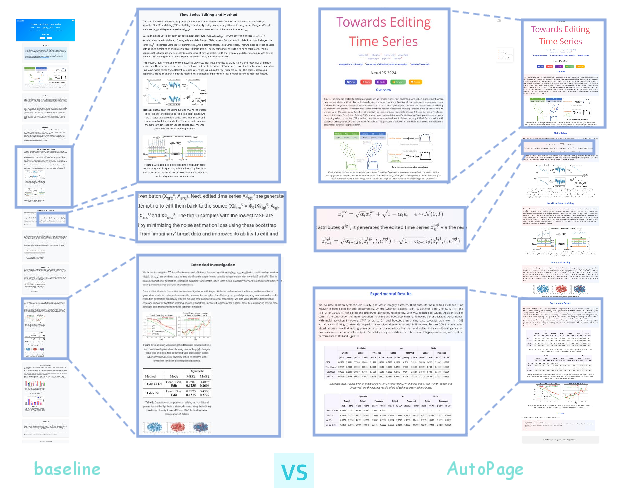
Figure 5: AutoPage (right) correctly renders formulas and preserves intended layout, while the baseline (left) fails in both aspects.

Figure 6: AutoPage (right) adapts table styles and image sizes for visual coherence, unlike the baseline (left).

Figure 7: AutoPage (right) ensures all content is displayed in correct layout, whereas the baseline (left) omits entire sections.
Human-in-the-Loop Feedback: Precision and Flexibility
The system's optional human-in-the-loop checkpoints enable fine-grained corrections, such as adjusting image sizes, vertical spacing, and removing erroneous assets. These interventions are shown to significantly enhance the final output quality, as evidenced by before-and-after visual comparisons.
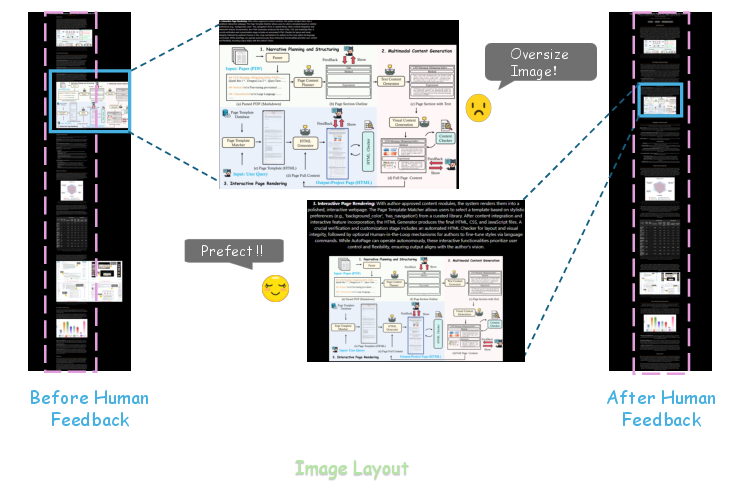
Figure 8: Human feedback corrects oversized images, resulting in a balanced layout.
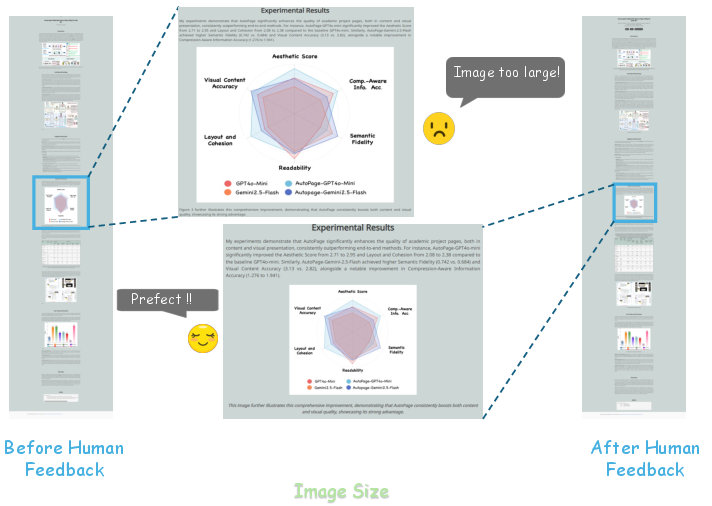
Figure 9: Human feedback resolves flawed layouts, ensuring appropriate image sizing.
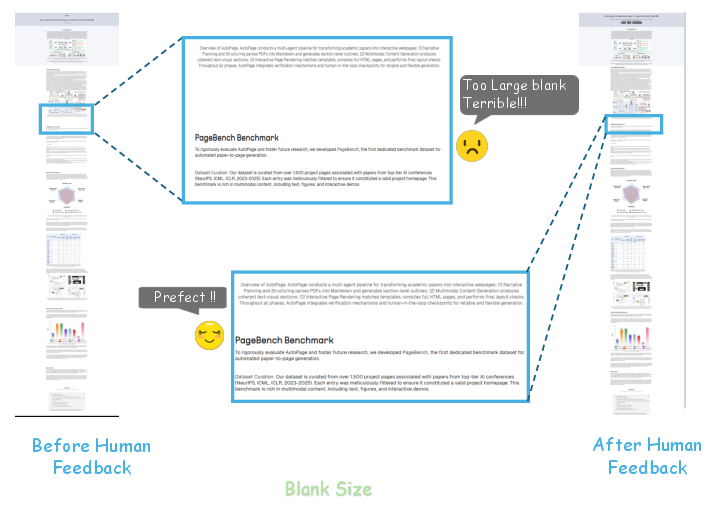
Figure 10: Human feedback eliminates excessive vertical whitespace, improving layout compactness.
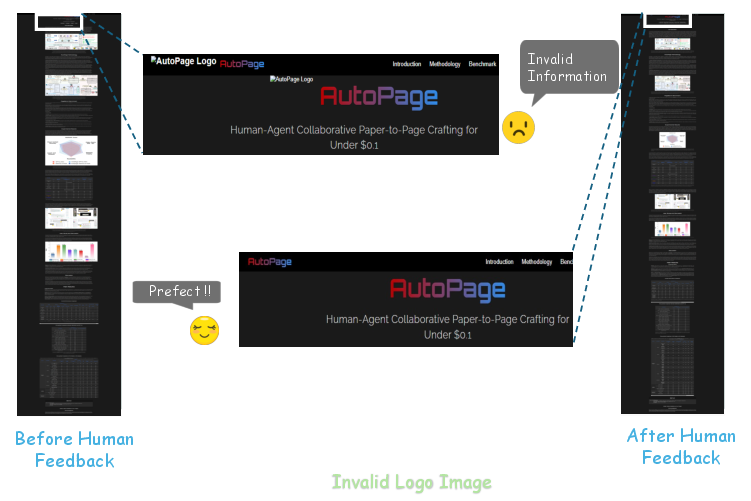
Figure 11: Human feedback removes incorrect UI assets, refining the final page.
Efficiency, Cost, and Practical Considerations
AutoPage achieves high efficiency, generating a complete project page in 4–20 minutes at a cost of \$0.06–\$0.20, depending on the backbone model. This cost-effectiveness, combined with the system's modularity and support for both autonomous and interactive workflows, makes it suitable for large-scale deployment and individual customization.
The authors note that readability metrics (e.g., Perplexity) can be misleading if not considered alongside semantic fidelity and factual accuracy, as some models achieve low PPL by sacrificing content correctness.
Implications and Future Directions
AutoPage establishes a new paradigm for automated research communication, demonstrating that hierarchical, agent-based systems with integrated verification and human collaboration can outperform monolithic LLM approaches in complex, multimodal generation tasks. The introduction of PageBench provides a foundation for principled benchmarking and further research in this area.
Potential future developments include:
- Extending the framework to other scientific communication formats (e.g., interactive demos, code documentation).
- Incorporating more advanced VLMs for richer visual reasoning and layout optimization.
- Exploring adaptive human-in-the-loop strategies for active learning and continuous improvement.
- Investigating domain adaptation for non-AI disciplines and multilingual support.
Conclusion
AutoPage represents a significant advance in automated, high-quality project webpage generation from academic papers, leveraging a hierarchical multi-agent architecture, rigorous verification, and flexible human collaboration. The system achieves strong empirical results across content and visual quality metrics, narrows the gap between model backbones, and is validated by human preference studies. The release of PageBench further catalyzes research in this domain, setting a new standard for automated scientific communication.