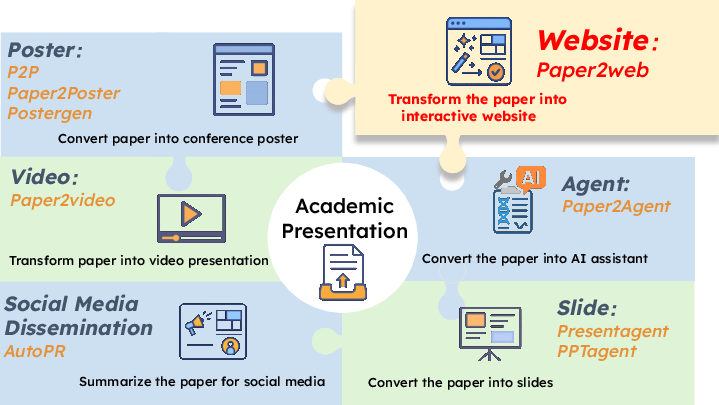
Paper2Web: Let's Make Your Paper Alive!
Abstract: Academic project websites can more effectively disseminate research when they clearly present core content and enable intuitive navigation and interaction. However, current approaches such as direct LLM generation, templates, or direct HTML conversion struggle to produce layout-aware, interactive sites, and a comprehensive evaluation suite for this task has been lacking. In this paper, we introduce Paper2Web, a benchmark dataset and multi-dimensional evaluation framework for assessing academic webpage generation. It incorporates rule-based metrics like Connectivity, Completeness and human-verified LLM-as-a-Judge (covering interactivity, aesthetics, and informativeness), and PaperQuiz, which measures paper-level knowledge retention. We further present PWAgent, an autonomous pipeline that converts scientific papers into interactive and multimedia-rich academic homepages. The agent iteratively refines both content and layout through MCP tools that enhance emphasis, balance, and presentation quality. Our experiments show that PWAgent consistently outperforms end-to-end baselines like template-based webpages and arXiv/alphaXiv versions by a large margin while maintaining low cost, achieving the Pareto-front in academic webpage generation.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about turning a regular research paper (usually a long, static PDF) into a lively, easy-to-explore website. The website keeps the important ideas from the paper but adds helpful features like good layout, links, videos, images, and interactive parts. The authors build:
- Paper2Web: a large dataset and a fair way to judge how good these websites are.
- PWAgent: an automated system that takes a paper and creates a high-quality, interactive project homepage.
Think of it like transforming a textbook page into a mini app that’s easier and more fun to explore.
What questions are the researchers trying to answer?
They focus on three simple questions:
- How can we automatically turn a full academic paper into a well-designed, interactive website?
- How do we fairly measure whether the website is good—both in how complete it is and how easy it is to use?
- Can our approach do better than common methods (like simple HTML conversion or ready-made templates) while keeping costs low?
How did they do it?
They used two main parts: a new dataset and a smart system that builds websites step by step.
Paper2Web Dataset and Evaluation
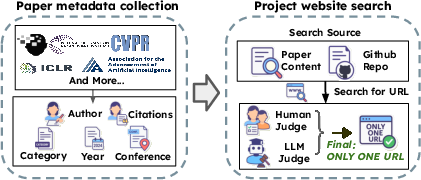
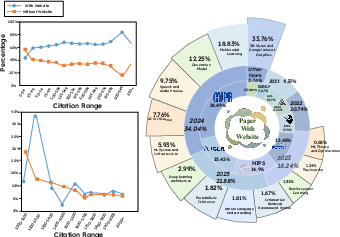
- They collected 10,716 AI papers from major conferences (like NeurIPS and ICML) and matched each to its official project website when available. This helps them understand what good research websites look like.
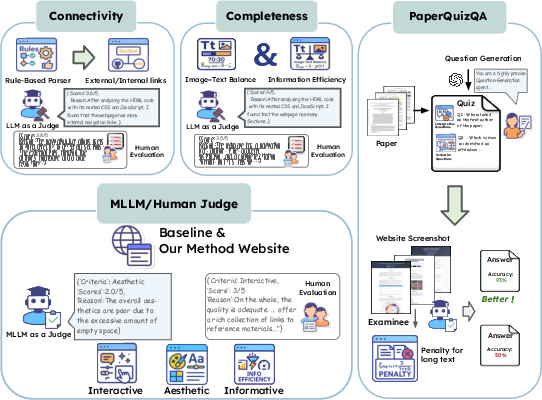
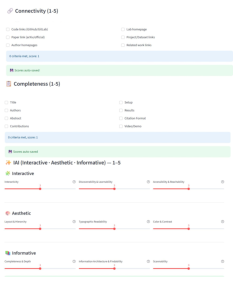
- They created a benchmark (a standardized test) to judge academic websites across three areas. The evaluation looks at three things:
- Connectivity and Completeness: Does the site have useful links and cover the core parts of the paper (like abstract, method, results)? They also check balance between images and text, and whether the site is concise instead of overly wordy.
- Holistic Quality (AI + human judging): An AI model (checked by humans) scores pages on Interactivity (do elements respond?), Aesthetics (is it pleasant and well balanced?), and Informativeness (is the content clear and logical?).
- PaperQuiz: A quiz made from the original paper tests how well the website communicates the key information. An AI reader answers questions using only screenshots of the site. There’s a penalty if the site just dumps too much text, encouraging smart, compact design.
PWAgent: The Website-Building System
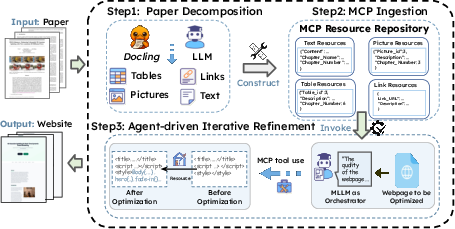
PWAgent is like a careful web designer who works in stages:
- Paper Decomposition: The paper PDF is turned into structured parts (text sections, figures, tables, and links). This is like sorting a backpack: notes, images, references—each gets its own labeled pocket.
- MCP Ingestion: MCP (Model Context Protocol) is a standardized “toolbox” that stores these parts in an organized “pantry” with labels, IDs, and cross-links. This lets the AI fetch exactly what it needs when building the site.
- Iterative Refinement: The agent drafts a website, looks at the rendered page (like taking screenshots), spots problems (messy layout, bad balance, missing connections), and fixes them. It cycles through local tweaks (small areas) and global checks (overall look and feel) until the site is balanced, readable, and interactive.
What did they find?
The main takeaways:
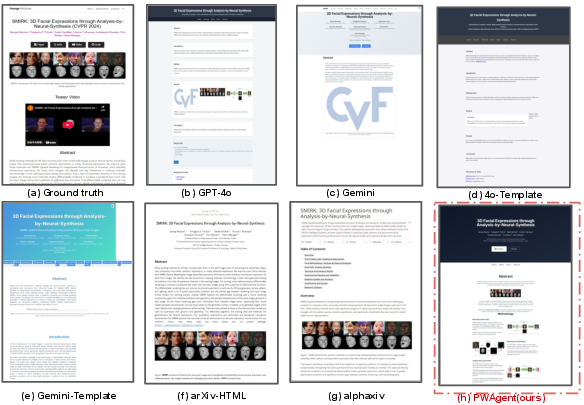
- PWAgent builds better websites than popular alternatives. Compared to arXiv HTML pages and alphaXiv, PWAgent’s sites:
- Cover more of the paper’s key content with a better balance of text and images.
- Have smarter, more useful links (not just a flood of messy citations).
- Are more interactive and nicer-looking.
- Fair scoring across different judges:
- In human-checked AI evaluations, PWAgent scores higher in interactivity, aesthetics, and informativeness than automated baselines.
- PWAgent also performs strongly on the PaperQuiz, especially after penalizing overly long, text-heavy pages. This shows it communicates information efficiently, not just by copying text.
- Cost-efficient: PWAgent achieves high quality at low cost per page (roughly $0.025), beating more expensive “end-to-end” methods (like directly asking a big AI to write the whole site) that can cost several times more without better results.
Why this matters: It shows we can automatically build engaging, accurate research websites that people actually want to read, without spending a ton of money or effort.
Why is this important?
- Better science communication: Most papers are PDFs—great for accuracy, but not for exploration. Websites can mix text with videos, animations, and interactive elements, making complex ideas easier to understand for students, developers, journalists, and the general public.
- Fair evaluation: The new benchmark helps the community judge website quality beyond just “how much text did you copy.” It rewards clarity, balance, and interactivity.
- Practical tool: PWAgent gives researchers a smart starting point for a good project homepage. Authors can then customize it further (add demos, videos, or new visuals) to make it even better.
Final thoughts
This work pushes research sharing beyond static PDFs and toward interactive, friendly websites. The dataset, fair scoring system, and PWAgent together make it easier to create pages that people can actually navigate, learn from, and enjoy. In the future, the authors plan to improve how multimedia (like videos and animations) is evaluated and to build even smarter agents, so research websites can become richer, more interactive, and more helpful for everyone.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, framed to be actionable for future research.
- Dataset scope bias: the corpus is restricted to AI papers (2020–2025) and English-language project pages, leaving generalization to other disciplines, languages, and time ranges untested.
- Canonical homepage mapping: the pipeline enforces “at most one” canonical site per paper; no analysis of multi-site ecosystems (e.g., multiple mirrors, GitHub Pages + lab website) or how this impacts evaluation and generation.
- Temporal drift: webpages evolve; there is no protocol for versioning, snapshotting, or handling content changes over time, which can invalidate labels and metrics.
- Interactive/multimedia labeling: only 2,000 samples were audited; the criteria for “interactive” and “multimedia” are not operationalized with instrumentation logs, leaving reproducibility and coverage uncertain.
- Accessibility metrics: no evaluation of accessibility compliance (e.g., WCAG/ARIA, alt-text, keyboard navigation, color contrast), screen-reader performance, or cognitive load.
- Responsiveness and device diversity: cross-device layout fidelity, mobile usability, and performance (e.g., viewport breakpoints, CPU/GPU load, network latency) are not measured.
- Security and safety: generated pages are not assessed for security (e.g., XSS, unsafe inline scripts) or privacy (e.g., tracking, third-party embeds).
- Link quality semantics: “Connectivity” counts and validates URLs but does not score link relevance, trustworthiness, freshness (dead links), or target diversity (code, data, demo).
- Completeness definition: coverage of paper sections is not evaluated against a canonical schema (e.g., methods, ablations, limitations, ethics); the metric could be gamed by superficial inclusion of headings.
- Image–text balance prior: the ideal 1:1 ratio and the scaling parameter
γare heuristic and unvalidated across disciplines; no empirical calibration or sensitivity analysis. - Verbosity penalty calibration: the penalty term
ζand parameterization are not tied to human comprehension outcomes, risking over-penalization of legitimately detailed, high-information pages. - Math fidelity: conversion accuracy of equations (LaTeX → MathJax/HTML), proofs, and cross-references is not evaluated; risk of semantic errors in math-heavy papers remains unquantified.
- Table and figure reconstruction: reliability of table parsing, figure–caption alignment, and in-text references is claimed but not rigorously benchmarked against a ground-truth annotation set.
- DOM-level interactivity correctness: no metric verifies whether widgets (tabs, accordions, filters) function as intended under user manipulations or degraded conditions (e.g., no JS).
- Holistic scoring validity: MLLM-as-a-Judge scores are “human-verified” but lack detail on sample size, inter-rater reliability, model calibration, and robustness across models and styles.
- Circularity risk in PaperQuiz: LLMs generate questions and other LLMs answer them; no human-grounded validation of question quality, ambiguity, or answer correctness.
- Screenshot-only QA: PaperQuiz uses single webpage screenshots, which may omit content below the fold or in interactive regions; no multi-screenshot or DOM-aware QA variant is explored.
- Multi-page sites: many academic project websites are multi-page; the benchmark and generation pipeline appear single-page-centric, leaving navigation and information architecture largely unevaluated.
- SEO and discoverability: effects of generated site structure on search indexing, schema.org metadata, and citation discoverability are not measured.
- Cost and runtime reporting: token cost is reported, but there is no thorough analysis of wall-clock time, compute hardware, concurrency, throughput, or energy consumption.
- Statistical significance: reported improvements lack confidence intervals, statistical tests, or per-category breakdowns (e.g., CV vs NLP vs theory) to establish robustness.
- PWAgent ablations: the contribution of each pipeline component (MCP ingestion, layout budget heuristic, tile-merging refinement) is not isolated via ablation studies.
- Failure mode taxonomy: qualitative failure patterns (e.g., broken anchors, image overflow, misaligned captions, hallucinated content) are mentioned but not systematically categorized or measured.
- Author-in-the-loop workflows: no evaluation of editing tools, revision loops, or how PWAgent accommodates author preferences and custom design languages.
- Multimedia integration: the paper acknowledges open challenges but does not propose concrete metrics for the effectiveness of videos/animations (e.g., engagement, comprehension gains).
- Ethics and licensing: dataset scraping, webpage redistribution, intellectual property, and licensing for derived artifacts (HTML snapshots, images) are not addressed.
- Generalization to long contexts: beyond tiling, there is no empirical stress test on extremely long documents (e.g., theses, surveys) or highly modular appendices.
- Domain transfer: applicability to non-AI scholarly formats (e.g., clinical studies, humanities papers, law articles) is unassessed, especially for domain-specific conventions.
- Style diversity: aesthetic scoring does not consider different design paradigms (minimalist vs illustrative); how style diversity affects MLLM judgments and user preferences is unknown.
- Robustness to layout complexity: the “content-aware spatial allocation heuristic” is under-specified; no formal objective or guarantees for avoiding overflow, occlusion, or drift across complex layouts.
- Link landing-page verification: links are “valid” syntactically, but no automated check verifies that targets correspond to claimed resources (e.g., code repo truly related, dataset accessible).
- Human-centered outcomes: no user studies measure comprehension, task completion time, retention, or trust compared to PDFs and oracle sites.
- Cross-browser compatibility: functionality and rendering differences across browsers (Chrome, Firefox, Safari, Edge) are not tested.
- Non-text modalities: audio, interactive notebooks, code sandboxes, and live demos are not evaluated for usability, reproducibility, or security.
- Reproducibility of metrics: parameters for
γ,β, prompt templates, and tool configurations are not fully specified, which may hinder reproducibility and comparability. - Release artifacts: it is unclear whether the dataset includes frozen HTML, assets, and interaction traces to enable consistent benchmarking over time.
Practical Applications
Practical Applications of Paper2Web and PWAgent
Below are actionable, real-world use cases derived from the paper’s dataset, evaluation suite, and PWAgent pipeline. They are grouped into Immediate Applications (deployable now) and Long-Term Applications (requiring more research, scaling, or ecosystem adoption). Each item highlights relevant sectors, potential tools/products/workflows, and key assumptions or dependencies.
Immediate Applications
These can be piloted or deployed with today’s tooling (e.g., the Paper2All repository, PWAgent pipeline, MCP-compatible LLMs, standard web stacks).
Academia and Scholarly Communication
- Automated project webpages for new papers
- Sectors: Education, Software, Research
- What: Use PWAgent to convert PDFs (e.g., from arXiv, OpenReview, Overleaf exports) into interactive, multimedia-rich lab or project websites with balanced image–text layout and curated links.
- Tools/Workflows: Paper2All repo + PWAgent; PDF→Markdown via MARKER/DOCLING; MCP server; deploy via GitHub Pages/Netlify; optional template fallback.
- Assumptions/Dependencies: Access to an MLLM and LLM (e.g., Qwen2.5-VL-32B + Qwen3-30B); stable PDF parsing; hosting permissions for figures/videos; institutional branding guidelines.
- Conference/journal submission add-ons
- Sectors: Education, Publishing
- What: Offer “Generate project page” during submission; use Connectivity/Completeness + MLLM-as-a-Judge as pre-publication quality checks; attach a shareable microsite link for reviewers and attendees.
- Tools/Workflows: Submission portal integration; batch PWAgent runs; PaperQuiz to ensure knowledge retention; scoring dashboards for editors.
- Assumptions/Dependencies: API integration with submission systems; cost/capacity planning for batch generation; reviewer anonymity/privacy controls.
- Repository augmentation (arXiv/alphaXiv, institutional repositories)
- Sectors: Education, Software
- What: Provide an alternate “interactive view” that improves layout, link hygiene, and interactivity over direct TeX→HTML; display PaperQuiz scores to signal information density without verbosity.
- Tools/Workflows: Nightly pipelines; MCP-backed asset store per paper; site embeds; A/B tests vs existing HTML views.
- Assumptions/Dependencies: Licensing and TOS alignment; stable access to metadata and assets; willingness to run LLMs at scale.
- Lab/departmental dissemination standards
- Sectors: Education
- What: Department-wide GitHub Action that auto-generates a project page for each accepted paper; uses Paper2Web metrics as quality gates; simplifies onboarding for early-career researchers.
- Tools/Workflows: CI/CD with PWAgent; link validation; auto-publishing on merge; badge showing Connectivity/Completeness scores.
- Assumptions/Dependencies: Centralized CI secrets for LLM APIs; storage quotas; accessibility review processes.
Industry (Publishing, Developer Tools, Marketing)
- “Doc-to-site” SaaS for technical whitepapers
- Sectors: Software, Finance, Energy, Healthcare
- What: Convert technical whitepapers and reports into interactive microsites that emphasize method diagrams, KPIs, and compliance links; use MLLM-as-a-Judge for preflight checks on aesthetics/interactivity.
- Tools/Workflows: Hosted PWAgent service; client upload portal; brand theming; CMS export (Headless CMS, Markdown/MDX).
- Assumptions/Dependencies: Client content rights; brand token integration; data residency and privacy compliance.
- Developer documentation enrichment
- Sectors: Software, Robotics
- What: Turn RFCs/specs into navigable sites that cross-link repos, issues, demos, and API docs; connect link assets to internal tools (Jira/GitHub).
- Tools/Workflows: MCP repository shared with dev portals; link typing (dataset/code/demo/benchmark) to drive navigation; CI-based regeneration.
- Assumptions/Dependencies: Stable internal URLs; SSO/security; PDF parsing robustness for complex tables/diagrams.
- Automated landing pages for product marketing
- Sectors: Software, Consumer Tech
- What: Generate landing pages from solution briefs with illustrative visuals, interactive FAQs, and distilled highlights; A/B test layouts guided by Paper2Web metrics.
- Tools/Workflows: PWAgent + analytics; PaperQuiz as a proxy for “comprehension lift”; experiment orchestration in marketing stacks.
- Assumptions/Dependencies: Visual asset availability; consent for LLM use on proprietary text; analytics instrumentation.
Policy, Public Sector, and Nonprofits
- Public-facing pages for funded research projects
- Sectors: Government, Healthcare, Energy, Climate
- What: Convert grant reports into accessible pages with clear findings, datasets, and impact summaries; provide PaperQuiz-derived “understandability” indicators for accountability.
- Tools/Workflows: Batch conversion on report submission; required link typing (data/code/ethics); standardized navigation.
- Assumptions/Dependencies: Open-access mandates; hosting for datasets; multilingual needs (see long-term for localization).
- Web accessibility audits of research pages
- Sectors: Government, Education
- What: Use Connectivity/Completeness plus image–text balance and verbosity penalties to flag inaccessible or overloaded pages; triage fixes.
- Tools/Workflows: Automated HTML parsing + metric computation; remediation suggestions from PWAgent; integration with accessibility scanners.
- Assumptions/Dependencies: Policy alignment with metrics; human verification of edge cases; document diversity (scanned PDFs).
Daily Life and Learning
- Study-note websites from papers
- Sectors: Education
- What: Students convert readings into structured microsites with diagrams and glossaries; use PaperQuiz as self-tests; share within reading groups.
- Tools/Workflows: Local PWAgent runs; static site hosting; quiz export to LMS or flashcard systems.
- Assumptions/Dependencies: Fair-use of figures; LLM availability and cost; device compatibility.
- NGO/think-tank report dissemination
- Sectors: Public Policy, Nonprofits
- What: Turn long PDF reports into clear, interactive summaries for broad audiences; highlight policy recommendations, evidence sources, and datasets.
- Tools/Workflows: Report upload + PWAgent; link curation; social-ready highlights.
- Assumptions/Dependencies: Permission to reuse graphics; multilingual target audiences (future localization).
Long-Term Applications
These require broader adoption, stronger multimodal capabilities, standards alignment, or further R&D (e.g., robust execution of multimedia and interactive components across devices and domains).
Next-Generation Scholarly Publishing
- “Living papers” with executable artifacts
- Sectors: Education, Software
- What: Extend PWAgent to embed code cells, model demos, and dataset explorers; unify paper, code, and results into reproducible, interactive documents.
- Tools/Workflows: Notebook-as-UI (e.g., Jupyter-in-the-browser), containerized demos, MCP tools for safe code execution, provenance tracking.
- Assumptions/Dependencies: Sandbox security; compute budgets; publisher workflows; standardized artifact packaging.
- Review-time interactive views and clarity checks
- Sectors: Education, Publishing
- What: Default reviewer interfaces are interactive pages; PaperQuiz used to quantify clarity and retention; MLLM-as-a-Judge flags layout issues before acceptance.
- Tools/Workflows: Overleaf/OpenReview integration; reviewer dashboards; auto-suggested edits to source LaTeX/Markdown.
- Assumptions/Dependencies: Community buy-in; fairness and bias audits for MLLM judging; blind review constraints.
Education at Scale
- Auto-generated course and textbook websites
- Sectors: Education
- What: Convert textbooks, lecture notes, and syllabi into interactive course portals with hierarchical navigation, embedded exercises, and PaperQuiz-based formative assessment.
- Tools/Workflows: Batch PDF→site pipelines; LMS integration; adaptive quizzes sourced from PaperQuiz question banks.
- Assumptions/Dependencies: Licensing for textbook content; robust figure/table extraction; accessibility and mobile-first design.
- Learning analytics and “comprehension-first” search
- Sectors: Education, Software
- What: Rank resources by Connectivity/Completeness and PaperQuiz scores; route learners to pages with higher comprehension payoff.
- Tools/Workflows: Search re-ranking; metadata ingest; analytics dashboards for instructors.
- Assumptions/Dependencies: Validity across disciplines; bias checks; student privacy.
Cross-Domain Document Transformation
- Enterprise knowledge portals from technical PDFs
- Sectors: Healthcare, Finance, Energy, Robotics
- What: Convert SOPs, compliance docs, clinical guidelines, or R&D reports into navigable, cross-linked portals for frontline staff; enforce versioning and audit trails.
- Tools/Workflows: PWAgent + enterprise CMS; role-based access; MCP as a content API for chatbots and copilots.
- Assumptions/Dependencies: Data governance; PII/PHI handling; change management; multilingual content.
- Legal/patent/grant documents to interactive briefs
- Sectors: Legal, Government, IP
- What: Turn long legal or IP documents into browsable, evidence-linked summaries with claim trees and prior-art cross-links.
- Tools/Workflows: Domain-tuned decomposition schemas; court/patent office portal integrations.
- Assumptions/Dependencies: High-accuracy parsing; legal risk mitigation; human-in-the-loop verification.
Discovery, Ranking, and Policy
- “Scholarly SEO” and discovery rankings
- Sectors: Education, Software
- What: Rank search results with Paper2Web metrics (Connectivity/Completeness/PaperQuiz) to surface clearer, more informative resources.
- Tools/Workflows: Indexers using site screenshots + HTML; re-ranking models.
- Assumptions/Dependencies: Metric robustness across formats; gaming-resistance; ethical ranking policies.
- Standards for accessibility and open-science compliance
- Sectors: Policy, Government, Education
- What: Adopt Paper2Web metrics in policy checklists (link hygiene, content balance, knowledge-transfer scores); require interactive dissemination for funded projects.
- Tools/Workflows: Compliance audits; certification badges; public registries.
- Assumptions/Dependencies: Community consensus; legal mandates; maintenance of benchmarks.
Tooling and Ecosystem Extensions
- Overleaf/arXiv/Publisher plug-ins
- Sectors: Education, Publishing
- What: One-click “Publish as interactive site” button; background PWAgent runs; live previews with MCP-driven feedback on layout and emphasis.
- Tools/Workflows: Plugin APIs; preview servers; interactive diff of HTML fragments linked to rendered tiles.
- Assumptions/Dependencies: Stable APIs; cost controls; uptime SLAs.
- Browser extension for on-demand preview
- Sectors: Software, Education
- What: “View as interactive page” on any PDF link; local or cloud-based generation; quick comprehension previews.
- Tools/Workflows: Extension + cloud service; caching; user controls for privacy.
- Assumptions/Dependencies: PDF CORS and content rights; performance on large docs; fair-use.
- Multilingual and accessibility-first generation
- Sectors: Education, Government, Healthcare
- What: Automatic localization of generated sites (text, captions, labels); accessibility annotations (alt text, ARIA roles); testing across devices.
- Tools/Workflows: Translation-aware MCP repository; accessibility validators; region-specific typography/layout.
- Assumptions/Dependencies: High-quality multilingual LLMs; domain terminology glossaries; accessibility standards (WCAG) adherence.
- Provenance, integrity, and trust signals
- Sectors: Education, Policy, Finance, Healthcare
- What: Content provenance (watermarks, signed assets), link integrity checks, and citation verification embedded into generated sites.
- Tools/Workflows: Cryptographic signatures; link monitoring; citation resolvers.
- Assumptions/Dependencies: Standardized provenance formats; cooperation from publishers; long-term link stability.
Notes on Feasibility and Risk
- LLM Dependencies: PWAgent performance depends on reliable PDF→Markdown extraction and MLLM reasoning (layout, visual alignment). Weak extraction or model drift can degrade results.
- Cost and Scale: While PWAgent shows favorable cost curves, large-scale deployments (repositories, publishers) require budgeting, batching strategies, and caching.
- Quality Assurance: MLLM-as-a-Judge and PaperQuiz correlate with human preference but still need human spot checks, especially for high-stakes content (healthcare, legal).
- Licensing and Rights: Reuse of figures, videos, and third-party content must respect copyright; institutions may need rights clearance workflows.
- Accessibility and Devices: Responsive design and assistive tech compatibility may require additional checks beyond the current metrics.
- Generalization: The dataset focuses on AI papers; cross-disciplinary robustness (e.g., math-heavy proofs, biomedical tables) may need schema extensions or domain-tuned models.
In summary, Paper2Web’s dataset, metrics, and PWAgent pipeline enable immediate, cost-effective improvements in how scholarly and technical content is disseminated, while laying the groundwork for a future of living, interactive, and more accessible scientific communication across sectors.
Glossary
- Agent-Driven Iterative Refinement: An iterative agent loop that assesses rendered pages and applies targeted edits to improve layout, coherence, and alignment. "Finally, we propose an agent-driven iterative refinement mechanism to progressively enhance the layout, visual coherence, and semantic alignment of generated webpages."
- AlphaXiv: A system that uses LLMs to condense content and optimize layout for paper webpages. "AlphaXiv leverages LLMs for content condensation and layout optimization, yet it still limits author control over multimedia placement and visual design"
- arXiv HTML initiative: A project converting arXiv papers to HTML to improve accessibility, often with layout issues. "The arXiv HTML initiative~\citep{frankston2024html} is one representative example"
- Connectivity: A metric assessing how well a webpage links internal and external resources for navigation and access. "It incorporates rule-based metrics like Connectivity, Completeness and human-verified LLM-as-a-Judge"
- Connectivity-aware placement: Positioning elements based on link structure to improve navigation and coherence. "typed references for connectivity-aware placement"
- Content-aware allocation heuristic: A heuristic estimating each asset’s spatial footprint to guide balanced layout. "A content-aware allocation heuristic estimates each assetâs spatial footprint and assigns provisional layout budgets to guide rendering and navigation."
- Content condensation: Reducing and restructuring text to preserve key ideas while making pages concise. "AlphaXiv leverages LLMs for content condensation and layout optimization"
- Context compression: Presenting essential information compactly to enable efficient knowledge transfer. "highlighting the value of concise, engineered sites and supporting website generation as effective context compression."
- Cross-modal semantics: Aligning information across text, images, and links to maintain context and meaning. "We enrich the parsed outputs with cross-modal semantics:"
- DOCLING: A tool for converting PDFs to structured formats for downstream parsing. "tools such as MARKER\footnote{https://github.com/datalab-to/marker} or DOCLING\footnote{https://github.com/docling-project/docling}"
- Grounding: Attaching content to stable references for accurate retrieval and navigation. "each resource is stored with a unique rid and fields for grounding and navigation."
- Hallucinations: Fabricated or incorrect content produced by models during reasoning. "To reduce hallucinations during long-range reasoning, the agent segments the rendered page into independent visual tiles"
- Holistic Evaluation with Human-Verified MLLM-as-a-Judge: A comprehensive scoring approach using an MLLM’s judgments validated by humans. "\subsection{Holistic Evaluation with Human-Verified MLLM-as-a-Judge}"
- Image–Text Balance Prior: A prior that penalizes deviations from an ideal ratio of images to text. "{#1{ImageâText Balance Prior.}"
- Image-to-text ratio: The proportion of visuals to text, affecting readability and understanding. "it suffers from an unbalanced image-to-text ratio with very few visuals"
- Information Efficiency Prior: A prior encouraging concise, information-dense text relative to human-designed baselines. "{#1{Information Efficiency Prior.}"
- LLM-as-a-Judge: Using a LLM to evaluate artifacts along defined dimensions. "human-verified LLM-as-a-Judge (covering interactivity, aesthetics, and informativeness)"
- Long-range reasoning: Reasoning over extended contexts or large documents where errors can accumulate. "To reduce hallucinations during long-range reasoning"
- MCP (Model Context Protocol): A protocol exposing standardized tools and resources that agents can query and edit. "Model Context Protocol (MCP) ingestion to construct a semantically aligned resource repository"
- MCP Ingestion: The process of loading parsed paper assets into an MCP-managed resource store. "\subsection{MCP Ingestion}"
- MCP Resource Repository: The structured store of text, visuals, and links within an MCP server. "These enriched records are then committed to MCP server as MCP Resource Repository"
- MCP server: The service that hosts resources and tools under MCP for retrieval and editing. "We first instantiate a fully instrumented MCP server"
- MLLM (Multimodal LLM): A model that processes and reasons over multiple modalities like text and images. "we employ a MLLM as an automated judge"
- Orchestrator Agent: The coordinating agent that performs global–local assessments and issues tool calls for fixes. "an MLLM acting as the Orchestrator Agent"
- Oracle Method: Using the original, author-created website as the gold-standard baseline. "(1) Oracle Method, original websites created by authors."
- PaperQuiz: A quiz-based evaluation measuring knowledge transfer from webpage screenshots through verbatim and interpretive questions. "we propose PaperQuiz to evaluate knowledge transfer from webpage screenshots through both verbatim and interpretive questions"
- Pareto-front: The set of solutions that are not dominated in a trade-off between quality and cost. "achieving the Pareto-front in academic webpage generation."
- Provisional layout budgets: Preliminary size allocations for elements to balance density and guide rendering. "assigns provisional layout budgets to guide rendering and navigation."
- Resource repository: A centralized store of organized assets (text, visuals, links) for synthesis and editing. "organizing them into a centralized resource repository."
- Responsiveness: The ability of a webpage layout to adapt across devices and screen sizes. "missing responsiveness"
- Semantic alignment: Ensuring that visual and textual elements correspond meaningfully to each other. "construct a semantically aligned resource repository"
- TeX–HTML pipelines: Conversion pipelines that attempt to replicate LaTeX layouts in HTML, often imperfectly. "these issues stem from TeXâHTML pipelines that emulate LaTeX behavior without executing a full TeX engine"
- Tool calls: Programmatic invocations of tools exposed by MCP for retrieval, editing, or layout operations. "issues targeted edits via tool calls"
- Verbosity penalty: A penalty term reducing scores for overly text-heavy pages to encourage conciseness. "incorporating a verbosity penalty to discourage overly text-heavy pages."
- Visual tiles: Segmented regions of a rendered page linked to corresponding HTML fragments for precise edits. "the agent segments the rendered page into independent visual tiles"
Collections
Sign up for free to add this paper to one or more collections.