- The paper shows that RL's use of on-policy data dramatically reduces catastrophic forgetting compared to SFT during language model adaptation.
- It employs comparative analysis of forward KL (mode-covering) versus reverse KL (mode-seeking) to explain how data selection impacts forgetting dynamics.
- The study highlights practical strategies, including Iterative-SFT, to approximate on-policy conditions, suggesting avenues for continuous learning frameworks.
Retaining by Doing: The Role of On-Policy Data in Mitigating Forgetting
Introduction
The paper "Retaining by Doing: The Role of On-Policy Data in Mitigating Forgetting" (2510.18874) addresses the issue of catastrophic forgetting in LMs during post-training. Catastrophic forgetting refers to the degradation of previously acquired capabilities when a model is adapted to new tasks. This phenomenon is prevalent in techniques like supervised fine-tuning (SFT) and reinforcement learning (RL), which are frequently used for task adaptation. The paper compares these two methods, highlighting a consistent trend where RL results in less forgetting than SFT. Through empirical studies and theoretical analysis, the authors identify that the mode-seeking nature of RL, due to its use of on-policy data, plays a critical role in maintaining prior knowledge.
Forgetting in LM Post-Training
Preliminaries
In the context of LM post-training, catastrophic forgetting is measured using metrics like target task gain (the improvement in task performance) and non-target tasks drop (the decline in performance on other tasks). The LLM's policy is evaluated before and after the training to quantify these metrics.
Comparison Between SFT and RL
Empirical results demonstrate that RL consistently achieves higher target task performance with minimal forgetting compared to SFT. RL's robustness to forgetting is attributed mainly to its use of on-policy data, which allows the model to preserve its existing knowledge while adapting to new tasks. Conversely, SFT, which relies on off-policy data, suffers from significant forgetting.
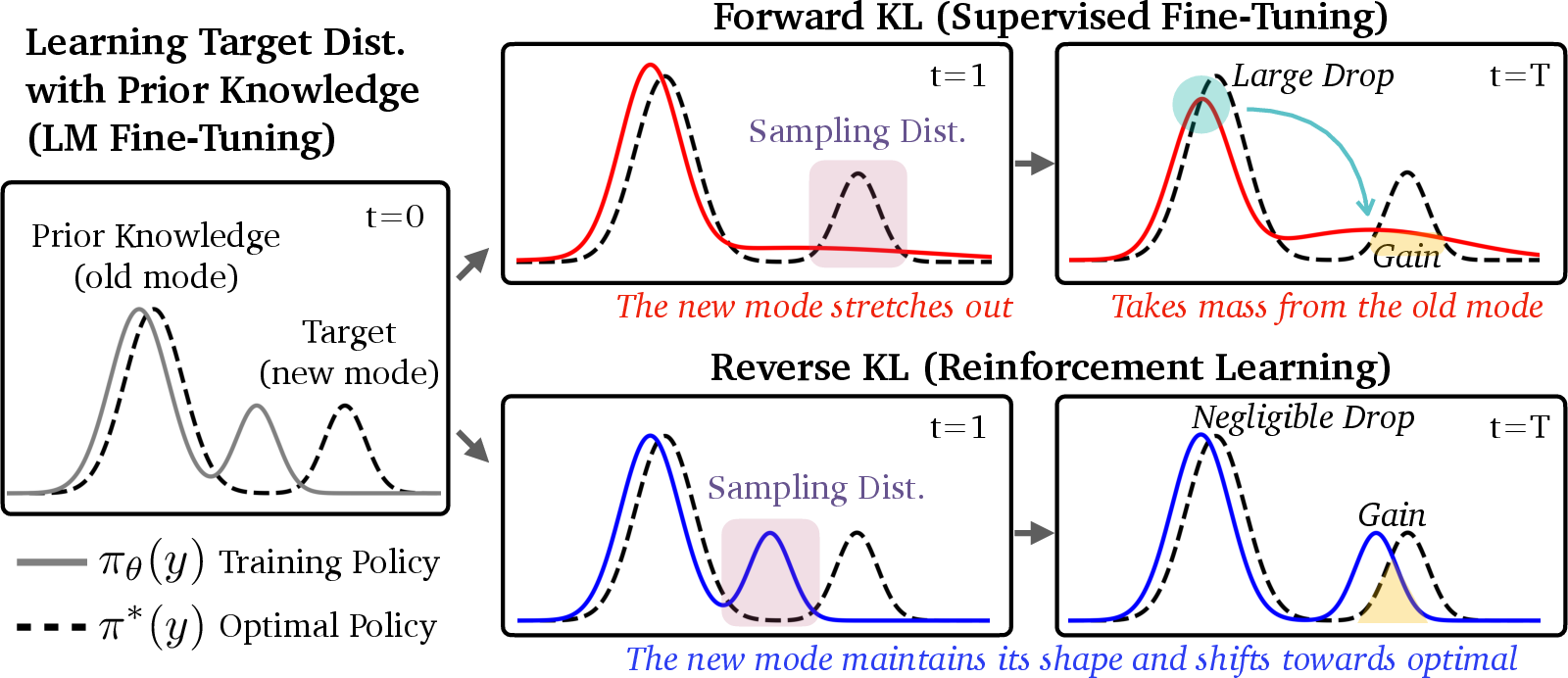
Figure 1: Illustration of the forgetting dynamics for the forward KL objective, corresponding to SFT, and the reverse KL objective, corresponding to RL.
Understanding Forgetting Dynamics Through KL Divergence
Forward KL vs. Reverse KL
SFT can be viewed as minimizing the forward KL divergence, which is mode-covering, while RL minimizes the reverse KL divergence, which is mode-seeking. Initially, intuition suggests that reverse KL should lead to more forgetting due to its fast probability mass movement. However, results indicate the opposite in practical LM scenarios, primarily when the policy is multi-modal. In uni-modal settings, forward KL indeed exhibits less forgetting. This discrepancy is reconciled by considering the behavior of reverse KL in multi-modal settings where it maintains prior modes better.
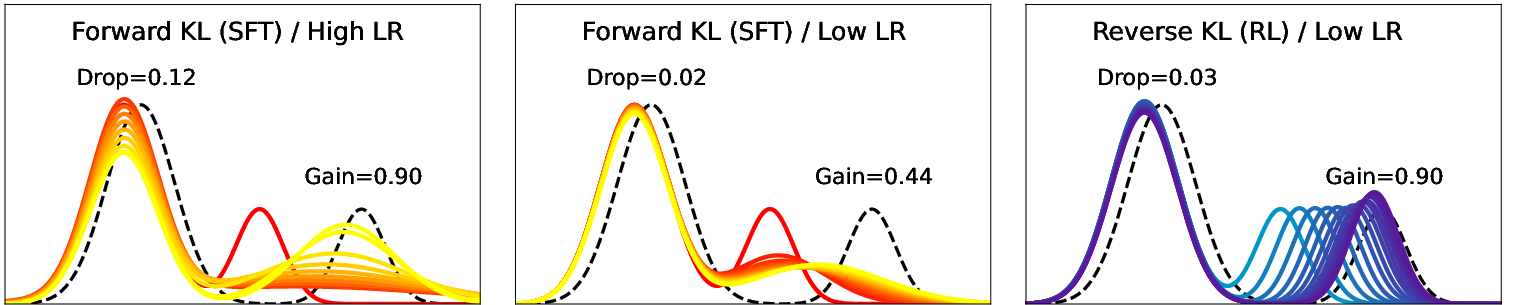
Figure 2: Reverse KL (RL) with multi-modal training policy forgets less than forward KL (SFT).
The Role of On-Policy Data
On-Policy Data Mitigates Forgetting
Through systematic ablations, the paper demonstrates that the robustness of RL to forgetting primarily stems from its use of on-policy data, rather than other algorithmic components such as KL regularization or advantage estimation. Experiments with variations like non-regularized GRPO and classical REINFORCE reaffirm the central role of on-policy data.
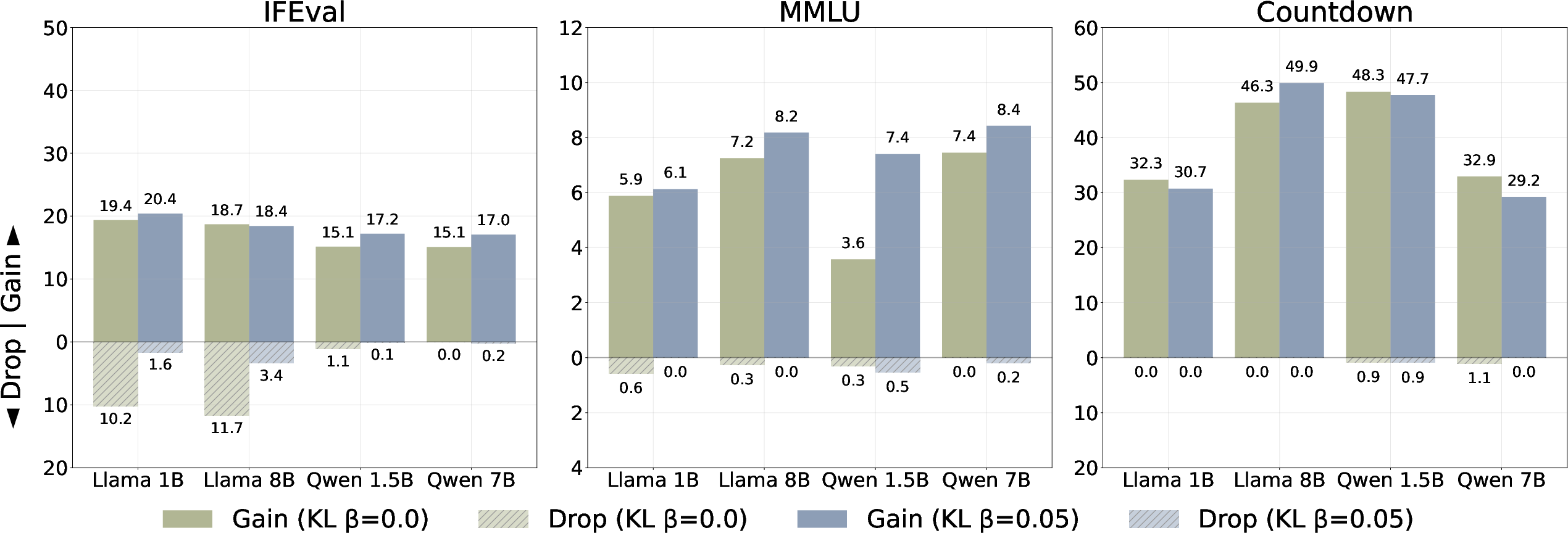
Figure 3: KL regularization is not a major contributor to RL's lesser degree of forgetting.
Approximately On-Policy Data
The study further explores whether partial on-policy setups can mitigate forgetting, finding success with methods like Iterative-SFT, which use approximately on-policy data generated at epochs' start. This approach significantly reduces forgetting while maintaining task performance, suggesting a practical and efficient alternative to fully on-policy RL.
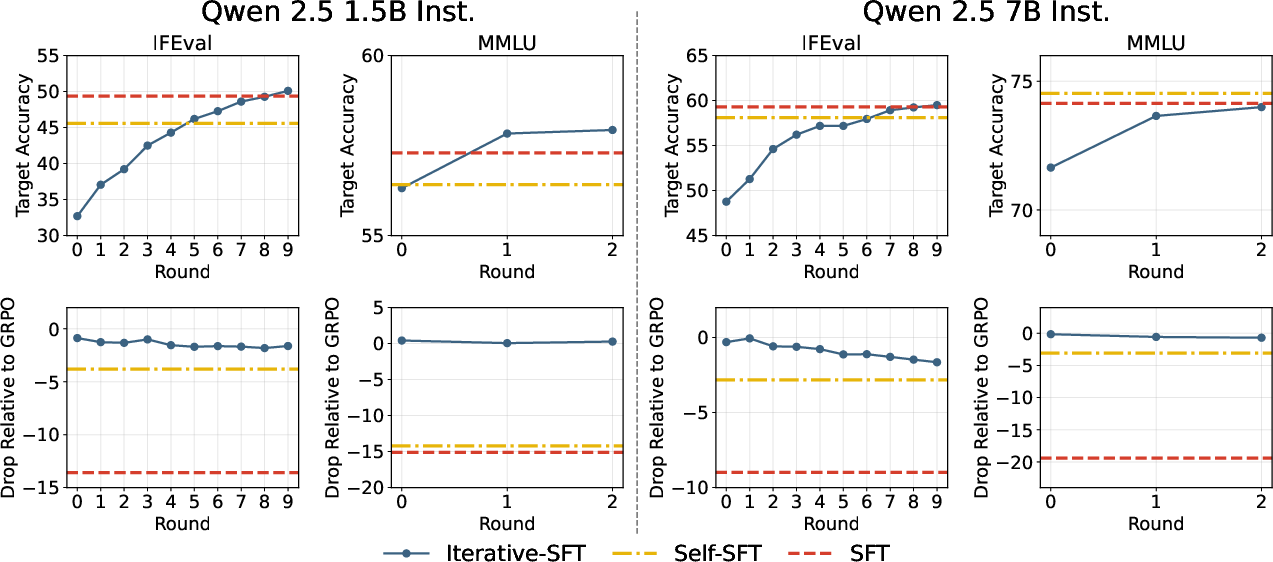
Figure 4: Approximately on-policy data can suffice for mitigating forgetting in SFT.
Implications and Future Directions
The findings underscore the importance of on-policy data in post-training scenarios, advocating for strategies that incorporate such data to reduce forgetting efficiently. The research opens avenues for further exploration on the theoretical underpinnings of on-policy data's role in adaptive learning and suggests directions for developing continuous learning frameworks without catastrophic forgetting.
Conclusion
The paper provides a comprehensive exploration of forgetting mechanisms in LMs, highlighting RL's resilience due to on-policy data usage. These insights are integral for advancing LM adaptation techniques, emphasizing efficient data strategies to maintain model capabilities over time.
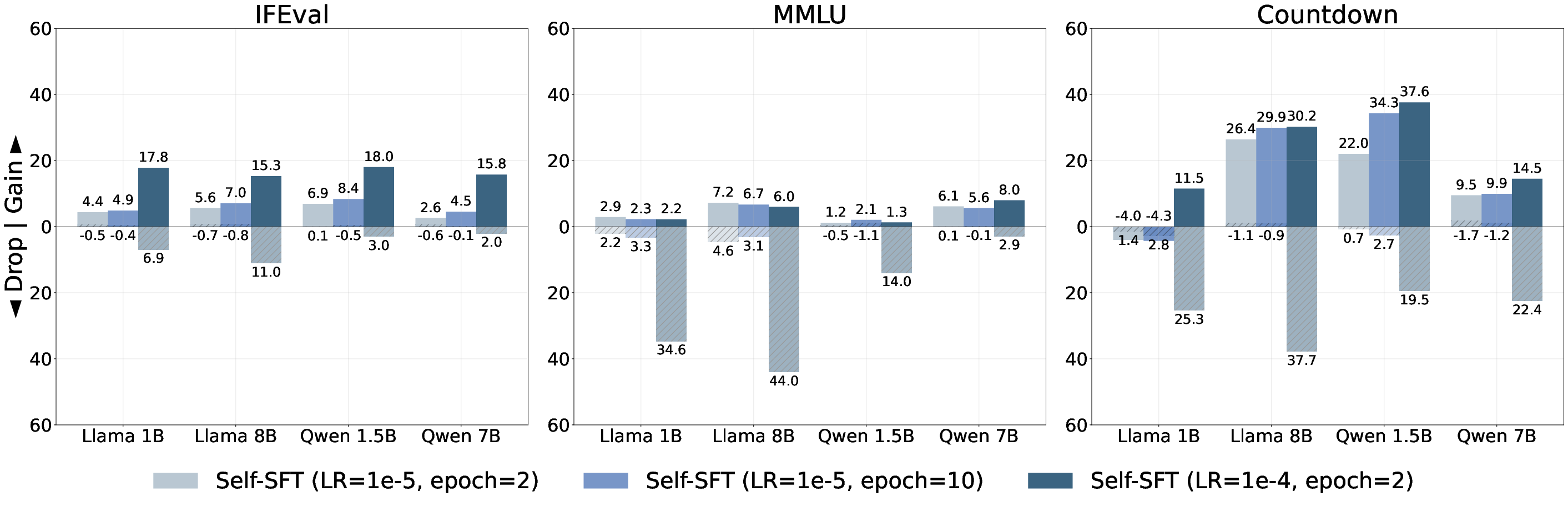
Figure 5: SFT exhibits a tradeoff between target task performance and forgetting.
