- The paper introduces DexCanvas, a hybrid real-synthetic dataset that merges 70 hours of human demonstrations with 7,000 physics-validated simulation hours to advance dexterous manipulation research.
- The authors employ a reinforcement learning-based force reconstruction pipeline that achieved an average success rate of 80.15% under nominal conditions and demonstrated robustness to perturbations.
- The dataset features a comprehensive taxonomy of 21 manipulation types with multi-modal captures, offering a versatile tool for developing contact-aware and imitation learning strategies.
DexCanvas: A Large-Scale Human Demonstration Dataset with Physics-Validated Force Annotations for Dexterous Manipulation
Introduction and Motivation
Dexterous manipulation with high-DoF anthropomorphic hands remains a central challenge in robotic learning, particularly for contact-rich tasks requiring nuanced control strategies. While recent advances in reinforcement learning (RL) and generative modeling have enabled progress in simulation, the lack of large-scale, physically grounded datasets capturing authentic human manipulation strategies has limited the transferability and robustness of learned policies. DexCanvas addresses this gap by introducing a hybrid real-synthetic dataset that combines 70 hours of high-fidelity human demonstrations with 7,000 hours of physics-validated rollouts, systematically organized across 21 manipulation types derived from the Cutkosky taxonomy.
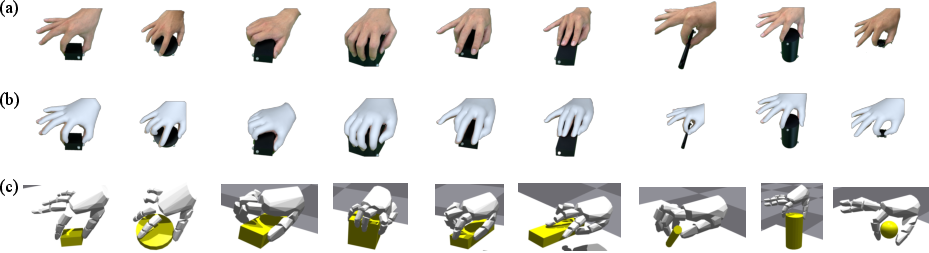
Figure 1: DexCanvas dataset overview. (a) Real human demonstrations captured through optical mocap showing diverse manipulation strategies. (b) MANO hand model fitted to mocap data preserving accurate kinematics. (c) Physics simulation with actuated MANO hand reproducing demonstrations while extracting contact forces and validating physical plausibility.
Manipulation Taxonomy and Dataset Scope
DexCanvas is structured around a comprehensive taxonomy of 21 manipulation types, hierarchically organized into four main categories: Power, Intermediate, Precision, and In-hand Manipulation. This taxonomy ensures systematic coverage of the manipulation space, moving beyond the ad-hoc or task-specific focus of prior datasets. Each manipulation type is further subdivided by thumb position and finger participation, with visual exemplars provided for each category.
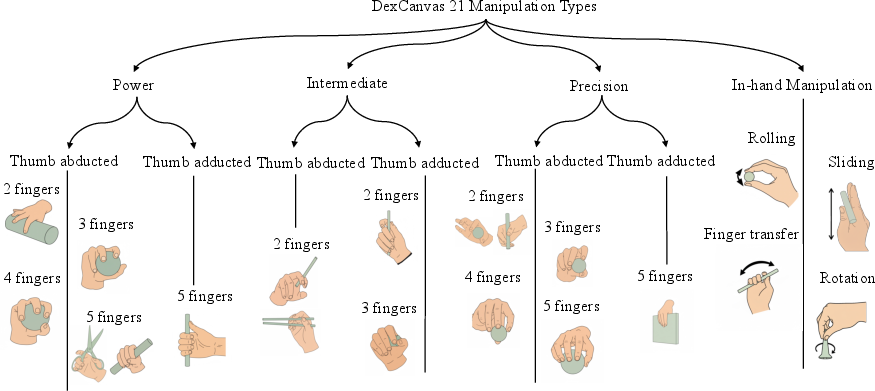
Figure 2: Complete taxonomy of 21 manipulation types in DexCanvas, hierarchically organized by manipulation strategy, thumb position, and finger participation.
The dataset includes 30 objects, ranging from geometric primitives in multiple sizes and weights to YCB objects for complex, task-specific grasps. Five operators performed 50 repetitions of each feasible manipulation-object pair, resulting in 12,000 sequences and 70 hours of real demonstrations.
Multi-Modal Capture and Processing Pipeline
The data acquisition system integrates a 22-camera optical motion capture (mocap) array with synchronized multi-view RGB-D sensors. The hand is instrumented with 14 reflective markers, and each object is 3D-printed with embedded marker mounts to ensure precise alignment between the captured pose and the simulation model.
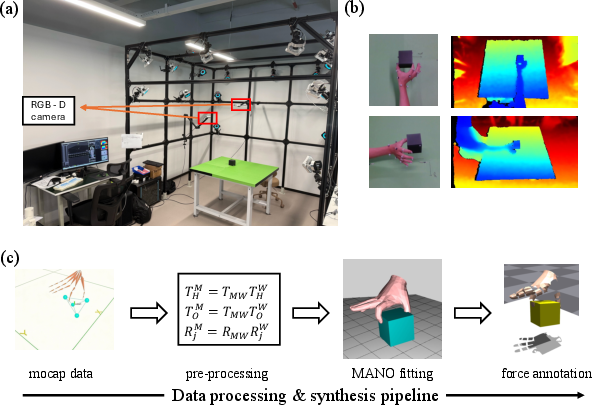
Figure 3: Overview of the capture setup and data pipeline, including the mocap system, RGB-D sensors, and the processing pipeline for MANO fitting and simulation.
Raw mocap data is processed into MANO hand model parameters, including per-participant shape coefficients and frame-wise joint angles. The resulting hand-object trajectories are time-aligned with RGB-D streams and transformed into a standardized coordinate system for downstream use.
Physics-Based Force Reconstruction via Reinforcement Learning
A central innovation of DexCanvas is the real-to-sim pipeline for extracting physically consistent force annotations from geometry-only mocap data. For each object-manipulation pair, a dedicated RL policy is trained to control an actuated MANO hand in IsaacGym, reproducing the observed object trajectory while maintaining stable contact and respecting physics constraints. The policy operates as a residual controller, outputting joint angle corrections to compensate for tracking errors and ensure physical plausibility.
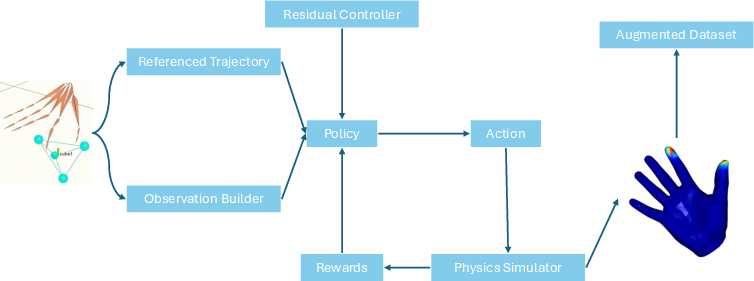
Figure 4: Overview of the RL-based force reconstruction pipeline, where policies are trained to track human demonstrations in simulation, enabling direct measurement of contact forces.
The reward function balances object trajectory tracking with minimal deviation from the original human gesture. During policy rollout, the simulator provides per-frame contact points, force vectors, and object wrenches, yielding rich, fine-grained force annotations that are otherwise unobtainable from mocap alone.
Experimental Results
Policy Reproduction and Data Synthesis
Policies trained for 32 representative object-manipulation pairs achieved an average success rate of 80.15% under nominal conditions. When initial object poses were perturbed by up to 20% of object size, the success rate decreased to 62.54%, indicating moderate degradation and demonstrating the robustness and diversity of the synthesized data.
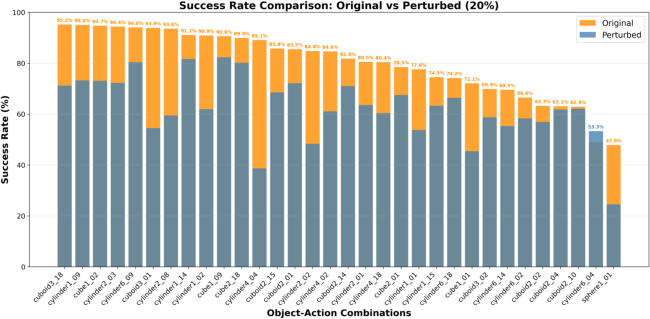
Figure 5: Success rates of policies across 32 object-manipulation pairs under nominal and perturbed conditions, illustrating robustness to initial state variation.
This synthesis pipeline enables a 100× expansion of the dataset, transforming 70 hours of real demonstrations into 7,000 hours of physics-validated rollouts.
Force Annotation Quality
The reconstructed force profiles exhibit smooth, physically consistent variations across fingers and time, with spatial renderings highlighting correspondence between force peaks and contact regions.
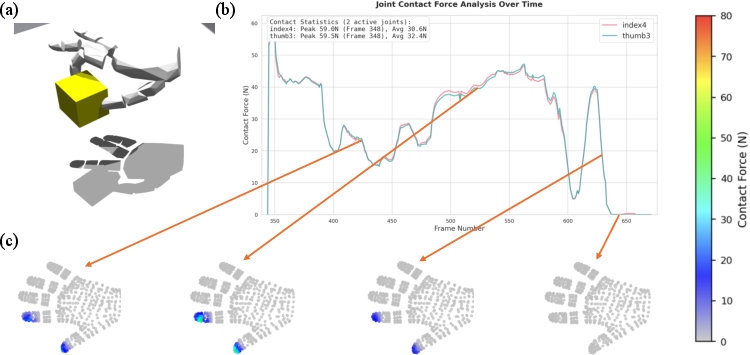
Figure 6: Evaluation of force annotation quality, including trajectory reproduction, per-finger force time series, and rendered force distributions on the hand mesh.
Manipulation-Specific Force Signatures
Distinct manipulation types produce characteristic contact force distributions, as revealed by aggregated heatmaps over 100 trials per type. Power grasps engage multiple joints, while precision manipulations concentrate forces on specific fingertips.

Figure 7: Manipulation-specific contact distributions, showing heatmaps of joint-level contact frequencies for three representative manipulation types.
These results confirm that the pipeline captures the unique physical signatures of each manipulation strategy, providing valuable supervisory signals for learning contact-aware policies.
Implementation Considerations
- Data Access: DexCanvas is available via HuggingFace Hub, supporting both full download and streaming. The data structure is compatible with PyTorch DataLoader for supervised learning and provides a stateful trajectory buffer for parallel RL training.
- Simulation and RL: The RL pipeline uses IsaacGym for high-throughput physics simulation. Policies are trained per object-manipulation pair using PPO, with privileged access to future object poses during training for improved tracking.
- Action Smoothing: Exponential filtering of action residuals ensures smooth, stable manipulation trajectories, critical for maintaining contact and preventing object slip.
- Scalability: While per-pair policy training is computationally intensive, the approach enables massive data augmentation and is amenable to future unification via multi-task or conditional policy architectures.
Implications and Future Directions
DexCanvas establishes a new standard for dexterous manipulation datasets by combining large-scale, authentic human demonstrations with physics-validated force annotations. The dataset supports research in RL, imitation learning, contact-rich control, and cross-morphology skill transfer. The inclusion of multi-modal RGB-D streams enables future work in visuomotor policy learning and multi-modal representation learning.
Key future directions include:
- Expanding Manipulation Scope: Incorporating more complex objects and free-form manipulation scenarios.
- Unified Policy Learning: Developing multi-task or conditional policies to scale beyond per-pair training.
- Cross-Morphology Retargeting: Leveraging force annotations for physics-aware transfer to diverse robot hand designs.
- Multi-Modal and Language Grounding: Exploiting RGB-D and potential language annotations for richer supervision and grounding.
Conclusion
DexCanvas provides a comprehensive, physically grounded resource for advancing dexterous manipulation research. By bridging the gap between human demonstrations and robot learning, and by providing high-fidelity force annotations at scale, it enables the development and evaluation of contact-aware, generalizable manipulation policies. The dataset, code, and processing pipelines are publicly available, facilitating reproducibility and accelerating progress toward robust, human-level robotic manipulation.

