- The paper introduces a unified framework that leverages flexible 3D point trajectory control to enhance both dense and unaligned image-to-video synthesis.
- It employs an efficient condition injection strategy through VAE token fusion and LoRA adaptations, significantly reducing trajectory errors and improving motion alignment.
- Experimental results demonstrate improved FVD scores, trajectory consistency, and visual fidelity across dense, spatially sparse, temporally sparse, and unaligned control scenarios.
Introduction and Motivation
FlexTraj introduces a unified framework for image-to-video generation with flexible point trajectory control, addressing the limitations of prior video diffusion models in controllability and granularity. Existing approaches typically rely on task-specific conditioning signals (e.g., depth maps, edges, masks, bounding boxes) that restrict control to a single granularity and assume strict alignment between input conditions and source frames. FlexTraj overcomes these constraints by representing motion as annotated 3D point trajectories, each with segmentation ID (SegID), temporally consistent trajectory ID (TrajID), and optional color cues, enabling both dense and sparse control, as well as robust handling of unaligned conditions.
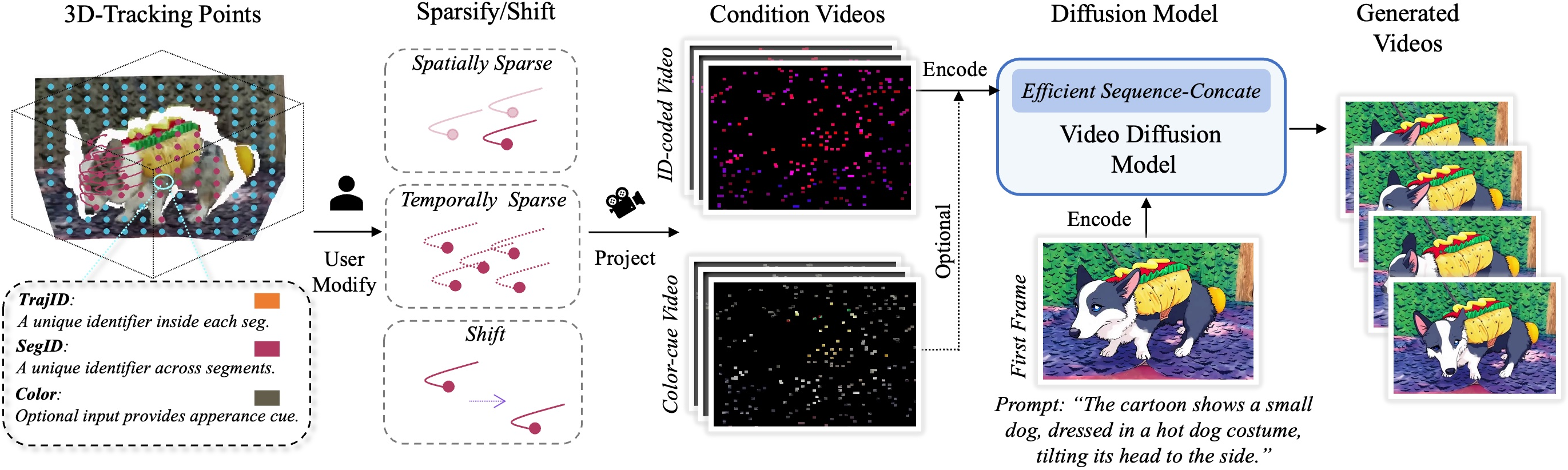
Figure 1: Overview of the FlexTraj framework, illustrating multi-granularity and alignment-agnostic trajectory control via annotated 3D points projected into condition videos and injected into a video diffusion model.
Trajectory Representation
FlexTraj's trajectory representation is defined as a set of 3D points pit=(xit,yit,zit,si,ui,ai), where (xit,yit,zit) is the spatial location at frame t, si is the segmentation ID, ui is the trajectory ID, and ai is an optional color vector. This representation supports:
- Dense control: High sampling density for fine-grained motion cloning and mesh-to-video tasks.
- Spatially sparse control: Selective sampling for drag-to-video and partial mesh-to-video.
- Temporally sparse control: Motion interpolation with anchor frames.
- Unaligned control: Trajectories shifted or misaligned with respect to the source frame.
The annotated points are projected into two condition videos: an ID-coded video (encoding SegID and TrajID) and a color-cue video (encoding appearance cues). These are processed by a pretrained video VAE to produce compact condition tokens.
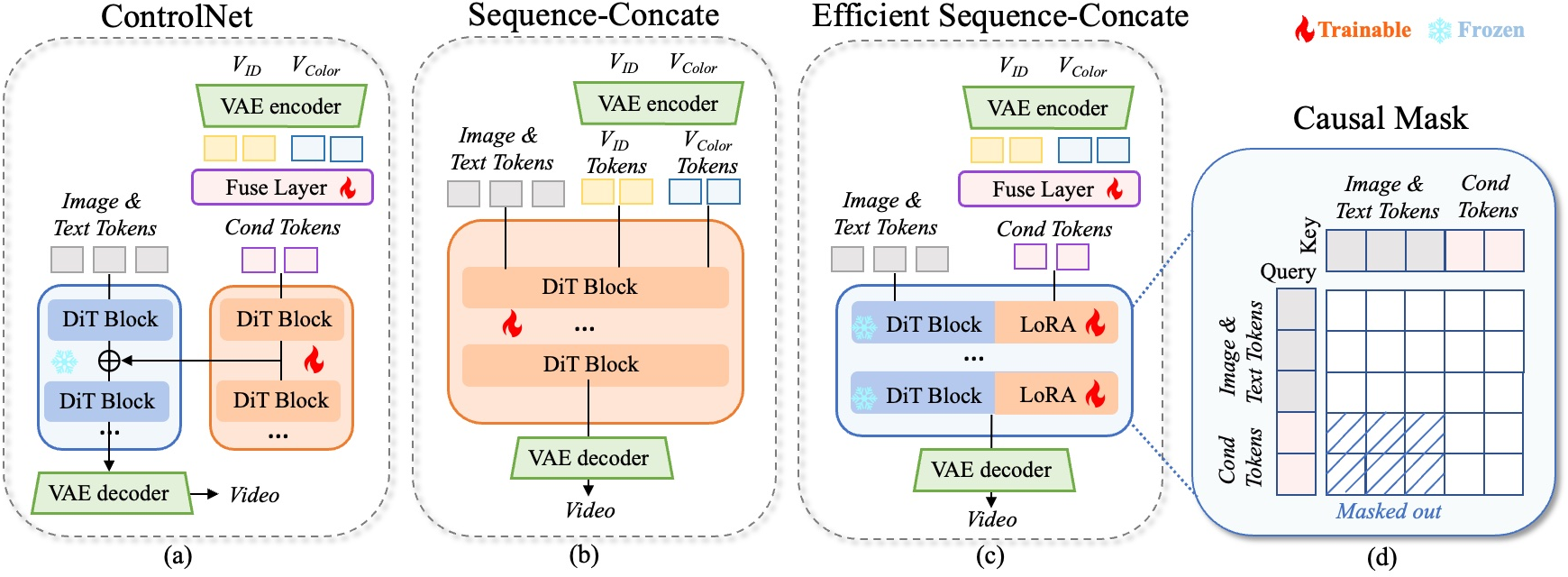
Efficient Condition Injection
Traditional ControlNet-style condition injection is suboptimal for DiT-based video diffusion models, enforcing strict alignment and limiting flexibility. FlexTraj introduces an efficient sequence-concatenation strategy:
Annealing Training Curriculum
Training a unified model for multi-granularity and unaligned control is non-trivial due to the expanded parameter search space. FlexTraj employs a four-stage annealing curriculum:
- Dense, aligned supervision: Rapid convergence with complete condition videos.
- Dense, partial supervision: Random omission of color-cue video.
- Sparse supervision: Gradual introduction of spatial and temporal sparsity.
- Unaligned supervision: Training with shifted trajectories and reduced learning rate to prevent catastrophic forgetting.
This curriculum enables the model to generalize across varying levels of sparsity and alignment, supporting flexible trajectory control in diverse scenarios.
Experimental Results
Qualitative Comparisons
FlexTraj is evaluated on four tasks: dense, spatially sparse, temporally sparse, and unaligned control, using DAVIS and FlexBench datasets. Baselines include DAS, ToRA, LeviTor, Go-with-the-Flow, MagicMotion, and SparseCtrl.
- Dense control: FlexTraj achieves superior alignment with source motion, outperforming 2D-based and U-Net-based baselines in fine-grained detail and handling newly emerging points.

Figure 3: Qualitative comparison on dense control, demonstrating FlexTraj's precise motion following and handling of new points.
- Spatially sparse control: FlexTraj accurately captures occlusion and maintains high visual fidelity, whereas 2D-based methods fail in occlusion scenarios and U-Net-based methods introduce artifacts.

Figure 4: Qualitative comparison on spatially sparse control, showing robust occlusion handling by FlexTraj.
- Temporally sparse control: FlexTraj generates coherent in-between frames aligned with anchor-frame motion, outperforming baselines in motion interpolation.

Figure 5: Qualitative comparison on temporally sparse control, highlighting FlexTraj's superior interpolation and alignment.
- Unaligned control: FlexTraj flexibly follows input motion without relying on strict spatial alignment, avoiding artifacts and implausible results seen in baselines.
Figure 6: Qualitative comparison on unaligned control, demonstrating FlexTraj's robustness to misaligned conditions.
Quantitative Comparisons
FlexTraj consistently achieves the lowest trajectory error (TrajErr) and highest trajectory similarity (TrajSIM) across all tasks, while maintaining competitive or superior video quality (FVD, Frame Consistency).
| Task |
Method |
FVD↓ |
Consistency↑ |
TrajErr↓ |
TrajSIM↑ |
| Dense |
Ours |
532.4 |
0.979 |
0.017 |
- |
| Spatially Sparse |
Ours |
710.4 |
0.980 |
0.025 |
- |
| Temporally Sparse |
Ours |
837.0 |
0.983 |
0.031 |
- |
| Unaligned |
Ours |
622.3 |
0.976 |
- |
0.908 |
Ablation Studies
Ablation experiments confirm the necessity of each design component:
- Trajectory representation: Removing SegID or TrajID degrades instance separation and correspondence, respectively.
- Condition injection: ControlNet-style injection yields limited control; FlexTraj's sequence-concatenation achieves accurate motion.
- Training strategy: Random mixing or reversed schedules reduce motion control performance; annealing preserves alignment and generalization.

Figure 7: Ablation study examples, illustrating the impact of trajectory representation, condition injection, and training strategy.
Limitations
FlexTraj's performance is constrained by tracking quality and the base video generator's capabilities. Tracking failures result in misaligned regions, and large rotations or long-term scene memory remain challenging. Future work should explore explicit memory mechanisms and improved tracking for enhanced consistency.

Figure 8: Limitations of FlexTraj, including tracking failures and scene degradation after large camera movements.
Additional Results
FlexTraj demonstrates broad applicability across creative and professional CG tasks, including motion transfer, camera redirection, mesh animation, and drag-based image-to-video synthesis.

Figure 9: Additional results showcasing FlexTraj's versatility across diverse applications.
Conclusion
FlexTraj establishes a unified paradigm for controllable image-to-video generation, supporting multi-granularity and alignment-agnostic trajectory control. Its compact trajectory representation, efficient condition injection, and annealing training curriculum collectively enable robust, precise, and flexible video synthesis. The framework advances the state of controllable video diffusion, with strong empirical results and broad practical implications. Future research should address tracking robustness and long-term scene consistency to further expand FlexTraj's capabilities.