Not All Bits Are Equal: Scale-Dependent Memory Optimization Strategies for Reasoning Models
Abstract: While 4-bit quantization has emerged as a memory-optimal choice for non-reasoning models and zero-shot tasks across scales, we show that this universal prescription fails for reasoning models, where the KV cache rather than model size can dominate memory. Through systematic experiments across 1,700 inference scenarios on AIME25 and GPQA-Diamond, we find a scale-dependent trade-off: models with an effective size below 8-bit 4B parameters achieve better accuracy by allocating memory to more weights rather than longer generation, while larger models achieve better accuracy by allocating memory to longer generations. This scale threshold also determines when parallel scaling becomes memory-efficient and whether KV cache eviction outperforms KV quantization. Our findings show that memory optimization for LLMs cannot be scale-agnostic, while providing principled guidelines: for small reasoning models, prioritize model capacity over test-time compute, while for larger ones, maximize test-time compute. Our results suggest that optimizing reasoning models for deployment requires fundamentally different strategies from those established for non-reasoning models.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Easy Summary of “Not All Bits Are Equal: Scale-Dependent Memory Optimization Strategies for Reasoning Models”
What this paper is about
This paper studies how to get the best performance from AI “reasoning models” (LLMs that think step-by-step) when you only have a limited amount of GPU memory. The authors show that the best way to spend your memory budget depends on how big the model is. In short: what works for small models often doesn’t work for big ones, and vice versa.
The big questions the paper asks
The researchers wanted to know, under a fixed memory limit:
- Should you spend memory on a bigger/more precise model, or on letting the model “think” longer (write more tokens)?
- Is it better to run several attempts in parallel and vote on the answer, or just let the model think longer once?
- How should we compress memory used during generation (the model’s “scratch paper”) to save space without losing too much accuracy?
How they tested their ideas (in simple terms)
Think of a reasoning AI like a student solving a hard math or science problem:
- The model’s “weights” are like the student’s brain—the built-in knowledge and skills. Bigger or more precise weights usually mean smarter “brain,” but they take more memory.
- The “KV cache” is like the student’s scratch paper—the notes the model writes down while thinking. Longer thinking means more scratch paper, which also takes memory.
- “Quantization” is like saving photos in lower quality to take up less space. You can do this to the brain (weights) or to the scratch paper (KV cache), but too much compression can hurt accuracy.
- “Eviction” is like keeping only the most important pages of your notes and throwing the rest out. This saves memory on scratch paper without lowering the quality of the kept notes.
- “Serial scaling” is letting one student think for longer. “Parallel scaling” is asking a group of students independently and voting on the best answer.
What they actually did:
- They ran over 1,700 test settings using models of different sizes (from 0.6B to 32B parameters) from the Qwen3 family.
- They tried different weight precisions (4-bit, 8-bit, 16-bit), different thinking lengths (2k to 30k tokens), and different numbers of parallel attempts (1 to 16).
- They tested on two tough benchmarks: AIME25 (hard math) and GPQA-Diamond (advanced science/knowledge).
- They also tried two ways to shrink the scratch paper:
- KV cache quantization (store notes in lower precision).
- KV cache eviction (keep only the most important notes while writing).
What they found and why it matters
Here are the key results, with a short explanation of why each matters:
- Small vs. large models need different memory strategies.
- For smaller models (roughly below the “8-bit 4B” level, about 4–5 GB of weight memory): you get better accuracy by investing memory in the model’s “brain” (more or higher-precision weights) rather than letting it think for much longer. Giving small models lots of scratch paper isn’t as helpful as making the “brain” better.
- For larger models (at or above that level): it’s better to spend memory on longer thinking (more tokens) until the gains level off. Bigger “brains” benefit a lot from more scratch paper.
- Task type matters for weight precision.
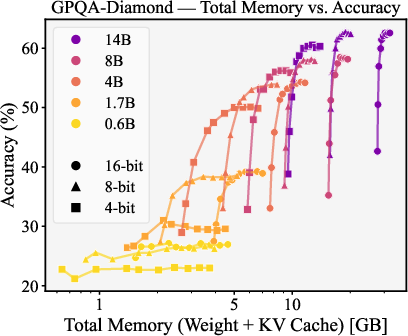
- For knowledge-heavy tasks (like GPQA-Diamond), 4-bit weights are usually most memory-efficient. That means you can compress the “brain” pretty aggressively and still do well.
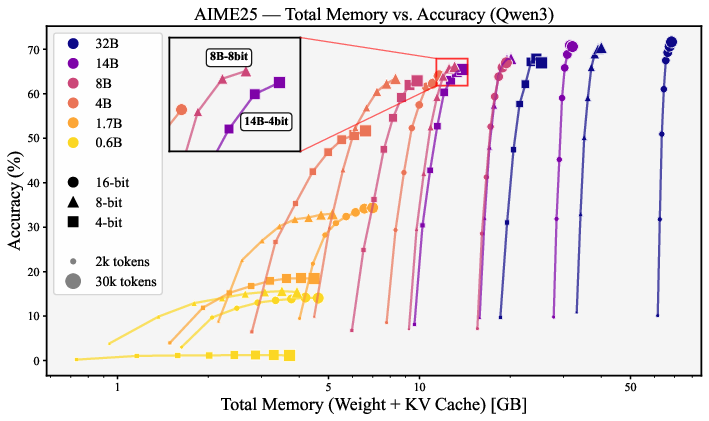
- For math reasoning (AIME25), higher precision (8- or 16-bit) wins. Math seems more sensitive to tiny errors caused by aggressive compression, so a sharper “brain” helps more.
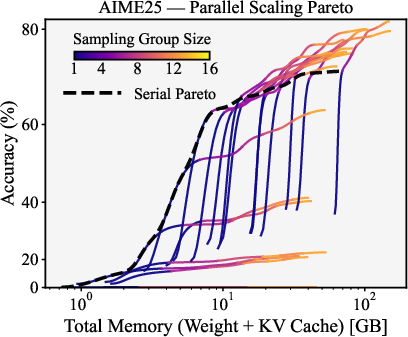
- Parallel attempts (majority voting) are only memory-efficient for bigger models.
- For small models, it’s wasteful to run many parallel tries. For large models, doing several tries in parallel and voting can improve accuracy per unit of memory, and the best group size grows as your memory budget grows.
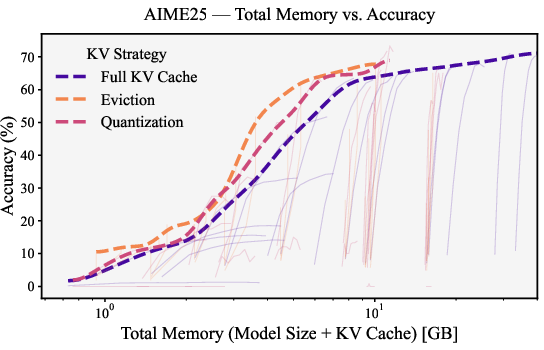
- Compressing the KV cache (scratch paper) is essential.
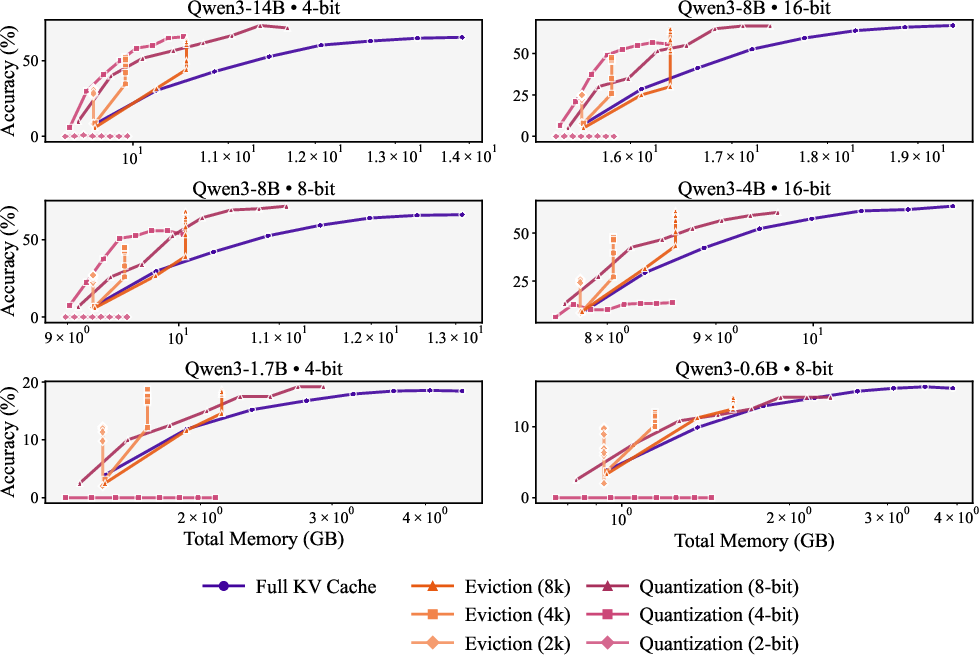
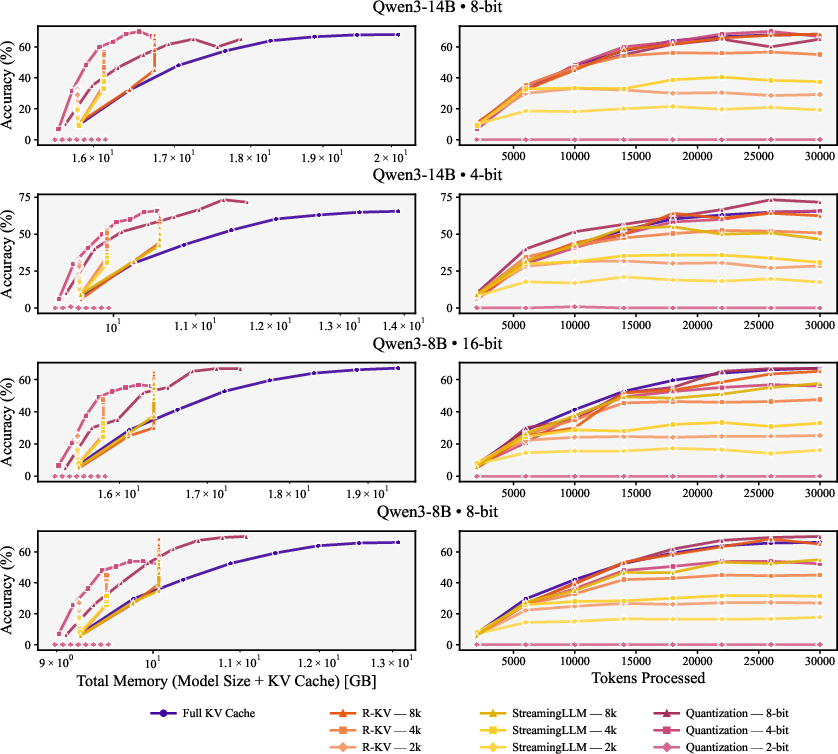
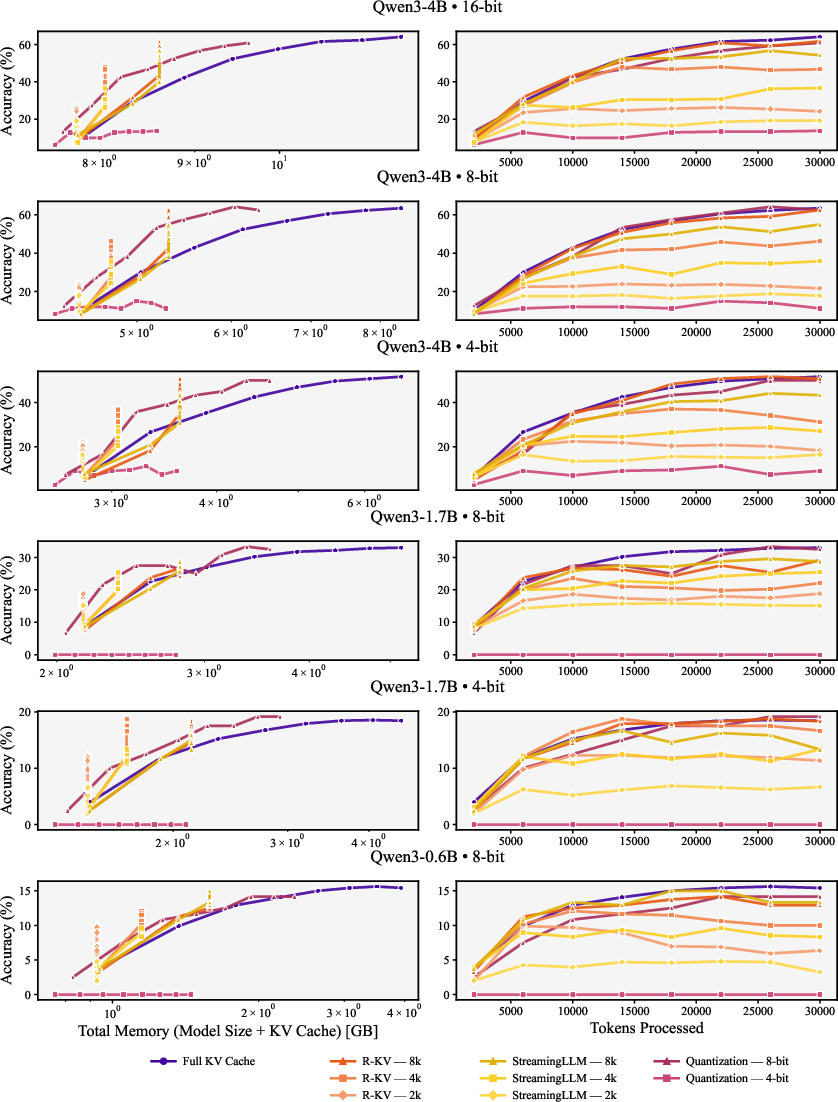
- Just compressing weights isn’t enough. Compressing the KV cache—either by quantizing it or by evicting less important parts—pushes the memory–accuracy trade-off forward. You can get the same accuracy with less memory, or better accuracy with the same memory.
- For small models, eviction is better than KV quantization; for larger models, both are competitive.
- Small models lose more from the numerical errors introduced by KV quantization. Eviction (keeping the most useful notes at full quality) works better.
- Large models can better tolerate KV quantization and it becomes competitive with eviction.
- Speed observations:
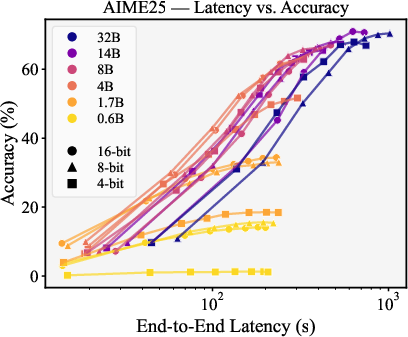
- Overall latency (how long a single answer takes) is mostly determined by how long the model is allowed to think (token count), not just its size.
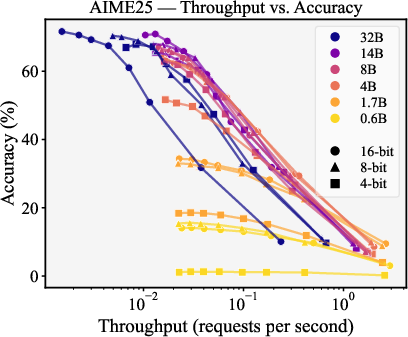
- For speed–accuracy trade-offs, 8-bit and 16-bit weights often do better than 4-bit. Surprisingly, 4-bit isn’t on the best speed–accuracy frontier in their tests.
Why this is important
These findings give practical rules for deploying reasoning AIs when memory is tight:
- For small reasoning models: improve the “brain” first (more or higher-precision weights), and use KV cache eviction instead of heavy KV quantization. Don’t overspend on long generations or many parallel tries.
- For large reasoning models: give them longer to think and consider parallel attempts. Compress the KV cache, and choose between eviction or quantization based on what works best in your setup.
- For math tasks: prefer higher-precision weights. For knowledge tasks: 4-bit often works great and saves memory.
Final takeaway: what this could change
Instead of using the same memory strategy for every model, teams should match their approach to the model’s size and the task:
- Small models: prioritize model capacity and careful scratch-paper management.
- Large models: prioritize test-time compute—longer thinking and possibly multiple attempts.
- Always consider KV cache compression; it’s a big win across the board.
This helps engineers run stronger reasoning models on limited hardware, choose sensible compression methods, and get better results without blindly following one-size-fits-all advice.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored, framed as concrete, actionable directions for future research:
- Generality across architectures: Validate whether the scale-dependent prescriptions hold for non-Qwen families (e.g., Llama, Mistral), Mixture-of-Experts, sparse attention, and RL-tuned “reasoning-first” models (e.g., R1) with differing hidden sizes and attention heads.
- Universality of the 8-bit 4B threshold: Test how the identified inflection point shifts with hardware (A100 vs. H100 vs. consumer GPUs), attention backends (FlashAttention versions), tokenizer choices, and KV layout implementations.
- Task breadth: Extend beyond AIME25 and GPQA-Diamond to code (e.g., LiveCodeBench), formal proofs, planning, multimodal reasoning, multilingual tasks, and knowledge-heavy domains with different reasoning profiles.
- Long-context regimes: Evaluate memory–accuracy trade-offs for contexts well beyond 30k tokens (e.g., 100k–1M) and for workloads dominated by prefill (RAG, document QA, streaming).
- Alternative parallel scaling strategies: Compare majority voting against best-of-n, verification-based selection, self-consistency with diverse promptings, and tree-of-thought search under identical memory budgets.
- Sample diversity and independence: Quantify how temperature, sampling strategies, and correlation between samples affect the memory efficiency of parallel scaling.
- KV compression algorithm coverage: Benchmark additional KV quantization (e.g., KIVI, KVQuant, Gear, Lexico) and eviction methods (e.g., SnapKV, Scissorhands, H2O) and explore hybrids (quantize-then-evict, layer/head-specific policies).
- Quantization design space: Study asymmetric vs. symmetric schemes, per-head/per-layer bitwidths, mixed precision for keys vs. values, and dynamic bit allocation conditioned on token importance.
- Sensitivity to quantization hyperparameters: Systematically vary GPTQ calibration set size, HQQ group size, residual buffer length, and scaling factors to map accuracy–memory sensitivities.
- Speed impacts of KV compression: Measure latency and throughput under KV quantization/eviction (not just weight-only), including memory bandwidth effects and dequantization overheads.
- Real-world serving configurations: Assess multi-GPU tensor/pipeline parallelism, CPU offloading, paged attention configurations, and scheduler behavior (preemption, fragmentation) on the memory–accuracy–throughput triad.
- Statistical robustness: Report confidence intervals, run-to-run variance, and significance tests (especially on small benchmarks like AIME) to quantify uncertainty in the observed frontiers.
- Layer-wise precision sensitivity: Identify which layers (e.g., attention vs. MLP, early vs. late) drive math sensitivity to low-bit weights and evaluate targeted mixed-precision schemes that minimize memory with minimal accuracy loss.
- Predictive model of trade-offs: Develop a quantitative scaling law linking accuracy to effective size (), token budget (), group size (), and KV strategy (), enabling memory-optimal configuration selection without exhaustive sweeps.
- Instance-adaptive policies: Explore controllers that dynamically reallocate memory between KV cache (via eviction/quantization), token budget, and parallel samples per instance/problem difficulty.
- Training-time interaction: Test whether quantization-aware training, distillation, or fine-tuning mitigates the math degradation observed at 4-bit and shifts the memory-optimal precision.
- Interpretability of eviction: Analyze how eviction alters attention patterns and reasoning chains; identify failure modes where evicting “critical” tokens causes specific classes of errors.
- Prompting artifacts from budget forcing: Evaluate whether “Wait”/“Final Answer \boxed{}” prompting induces behaviors that bias results; compare with natural stopping and alternative continuation cues across tasks/models.
- MoE-specific KV dynamics: Study how expert routing affects KV cache size, eviction efficacy, and quantization robustness when only a subset of parameters are active per token.
- Memory accounting fidelity: Incorporate framework overheads (allocators, paging metadata), activation memory, fragmentation, and host memory in the cost model to align predicted vs. realized memory footprints.
- Quality metrics beyond pass@1: Measure calibration, rationale correctness, consistency, and error types under compression to understand non-accuracy degradations important for deployment.
- Hardware heterogeneity: Benchmark on diverse GPUs (H100, A10, RTX-series) to separate bandwidth, cache, and kernel support effects from algorithmic trade-offs.
- Scaling limits of group size: Probe group sizes beyond 16, characterize diminishing returns, optimal tie-breaking, and diversity management under fixed memory budgets.
- Activation quantization: Evaluate whether quantizing activations or attention scores jointly with weights/KV changes the memory-optimal precision and latency profile.
- Cross-task KV compression effects: Replicate the KV compression analysis on knowledge-intensive tasks (e.g., GPQA-Diamond) to confirm whether eviction vs. quantization preferences differ by task type.
- Tokenization and language effects: Test multilingual settings and alternative tokenizers to quantify how token count inflation/deflation shifts KV dominance and the optimal memory allocation.
- Serving scheduler interactions: Examine vLLM (and other frameworks) scheduling policies, preemption, and paging parameters to understand how they reshape the practical Pareto frontier under load.
Practical Applications
Immediate Applications
The following applications can be deployed now by practitioners and organizations to reduce memory costs, improve accuracy, and optimize inference for reasoning LLMs under real-world constraints.
- Sector: Software/AI Infrastructure — Memory-aware serving of reasoning LLMs
- Use case: Configure LLM serving stacks to allocate memory differently for small vs. large reasoning models.
- Action:
- For small models (effective size below 8-bit 4B ≈ 4.2 GB): prioritize higher weight precision (8- or 16-bit), limit generation length, and apply KV cache eviction (e.g., R-KV, StreamingLLM).
- For large models (≥ 8-bit 4B): increase test-time token budget until accuracy saturates, enable parallel scaling (majority voting) with group sizes that grow with memory budget, and consider KV cache quantization (e.g., HQQ) over eviction.
- Tools/workflow: vLLM + FlashAttention serving with GPTQ (weights), HQQ (KV quantization), R-KV/StreamingLLM (KV eviction); implement “budget forcing” for serial scaling; integrate majority voting for parallel scaling.
- Assumptions/dependencies: Threshold is empirically established on Qwen3 and AIME25/GPQA-Diamond; behavior may vary across models/tasks; depends on GPU architecture and inference framework.
- Sector: Cloud Ops/MLOps — GPU capacity planning and cost optimization for reasoning workloads
- Use case: Plan VRAM budgets and batch sizes to avoid KV cache bottlenecks when scaling reasoning services.
- Action: Adopt per-generation memory budgeting that amortizes model weights across batches; select model size and precision using the paper’s memory cost equations; avoid parallel scaling for effectively small models.
- Tools/workflow: Memory-per-generation calculators; schedulers that factor effective size, KV cache growth with token budget and group size; dashboards for KV cache utilization.
- Assumptions/dependencies: vLLM/paged attention memory behavior; workload’s typical token budgets and accuracy requirements.
- Sector: Education — Math tutoring and STEM assistants on limited hardware
- Use case: Deliver high-quality math reasoning on consumer GPUs or on-prem servers.
- Action: Favor 8-bit (or 16-bit where possible) weights and KV eviction for small models; keep token budgets moderate; avoid parallel sampling unless memory allows.
- Tools/workflow: Lightweight tutoring services with budget forcing for serial scaling; eviction-based KV management; curated prompts to reduce unnecessary tokens.
- Assumptions/dependencies: Findings reflect math-like reasoning sensitivity to precision; require evaluation for curriculum-specific tasks.
- Sector: Healthcare and Finance — Knowledge-intensive assistants (triage, research synthesis, risk analysis)
- Use case: Deploy knowledge-heavy reasoning assistants under fixed memory budgets.
- Action: Prefer 4-bit weights for larger models to maximize parameter count; increase generation length until performance saturates; enable parallel scaling with majority voting for higher accuracy (only for large effective sizes).
- Tools/workflow: GPTQ 4-bit weight quantization; HQQ KV quantization for large models; controlled group sizes as memory grows.
- Assumptions/dependencies: Domain-specific validation; safeguard policies; the GPQA-Diamond results suggest 4-bit is memory-optimal for knowledge-heavy tasks but verify locally.
- Sector: RL and Simulation — Latency-critical reasoning loops
- Use case: Optimize speed–accuracy trade-offs for reasoning in RL rollouts or simulations.
- Action: Use 8-bit weights (4-bit not on latency/throughput Pareto frontier) and limit token budgets; apply eviction to keep KV constant when long generations are unavoidable.
- Tools/workflow: vLLM serving tuned for low-latency; streaming window eviction; throughput-aware batch sizing.
- Assumptions/dependencies: Measured on A100 80 GB; speed gains from memory movement reductions are more pronounced on larger models.
- Sector: Software Engineering — Code assistants and troubleshooting bots
- Use case: Tune memory strategies by task type: arithmetic-heavy reasoning vs. knowledge retrieval.
- Action: For arithmetic-heavy reasoning (e.g., performance-tuning, algorithm derivation), prefer higher precision weights with eviction; for knowledge retrieval and documentation, use larger 4-bit models with longer generations and (for large models) parallel samples.
- Tools/workflow: Task-aware routing; config profiles per task (math vs knowledge); majority voting enabled only where memory permits.
- Assumptions/dependencies: Task classification accuracy; stability of majority voting on coding tasks.
- Sector: Public Sector/Policy — Cost-effective LLM deployment guidelines
- Use case: Establish procurement and deployment guidance for reasoning AI under constrained budgets.
- Action: Mandate KV cache compression (eviction or quantization) and scale-aware configurations (small vs large model policies); set memory/energy targets that reflect KV dominance in reasoning workloads.
- Tools/workflow: Standardized deployment checklists; compliance tests for memory-per-request; sector-specific profiles (health, education, justice).
- Assumptions/dependencies: Local data protection and safety requirements; alignment with ethical/accuracy standards.
- Sector: Consumer/On-device AI — Local LLMs for daily life
- Use case: Run reasoning models on laptops or consumer GPUs for math help, planning, or study aids.
- Action: Choose small models with 8-bit weights; enable KV eviction to avoid memory blowups; avoid parallel sampling; tune token budgets for acceptable latency.
- Tools/workflow: OOTB setups using OLLAMA/LM Studio; plug-ins for KV eviction; “memory budget” presets.
- Assumptions/dependencies: Availability of eviction in local runtimes; limited VRAM scenarios.
Long-Term Applications
These applications require additional research, engineering development, or scaling to ensure robust, generalizable performance across models, tasks, and hardware.
- Sector: Software/AI Infrastructure — Auto-adaptive inference controllers
- Use case: Runtime agents that detect task type (math vs knowledge), model effective size, and memory pressure, then dynamically select weight precision, KV policy (evict vs quantize), token budget, and group size.
- Potential product: “Reasoning Memory Orchestrator” with closed-loop telemetry, multi-objective optimization (accuracy, latency, cost).
- Dependencies: Task classification, online re-quantization tooling, robust eviction policies; generalization of scale thresholds beyond Qwen3; safety guardrails.
- Sector: Model Training — Quantization-aware training (QAT) for reasoning
- Use case: Make 4-bit (and lower) weights viable for arithmetic/mathematical reasoning without substantial accuracy loss.
- Potential product: QAT pipelines tuned for reasoning, co-optimized with KV-aware architectures.
- Dependencies: Access to training data; model retraining; evaluation across diverse reasoning benchmarks; integration with inference-time compression.
- Sector: Architecture/Systems — KV-minimal reasoning architectures
- Use case: Reduce KV cache dominance via architectural changes (e.g., state-space models, structured memory, attention sinks).
- Potential product: Reasoning-focused architectures with bounded KV memory; specialized attention variants that preserve key reasoning tokens efficiently.
- Dependencies: Research validation; hardware support; compatibility with existing inference stacks.
- Sector: Orchestration/MLOps — Memory-aware parallel scaling with verifiers
- Use case: Pair majority voting with verifier models under memory constraints, adapt group sizes dynamically to budget and accuracy targets.
- Potential product: “Self-consistency + verification” controller with memory-aware scheduling and cost caps.
- Dependencies: Verifier availability and cost; coordination overhead; task-level gains vs. memory expansion.
- Sector: Hardware — KV-centric accelerators and memory systems
- Use case: Hardware optimized for KV cache operations (quantization/dequantization, eviction policies, streaming windows).
- Potential product: GPUs/NPUs with KV-optimized memory hierarchies, dequantization units, and eviction-friendly attention primitives.
- Dependencies: Vendor adoption; software ecosystem updates; proof of sustained energy savings.
- Sector: Policy/Standards — Energy and cost standards for reasoning AI
- Use case: Regulatory frameworks and benchmarks that factor KV memory footprints, not just FLOPs, in energy/cost assessments.
- Potential product: Sector-specific standards (health, finance, education) with “bytes spent” auditing; incentives for KV-efficient deployments.
- Dependencies: Broad benchmarking; transparency mandates; harmonization across jurisdictions.
- Sector: Safety/Compliance — Formal methods for eviction/quantization safety
- Use case: Ensure KV eviction does not remove critical context for safety-critical domains (e.g., medical advice), and that quantization does not induce unacceptable numerical errors in sensitive computations.
- Potential product: Certifiable inference policies; safety tests and proofs for memory compression.
- Dependencies: Domain-specific safety criteria; interpretable token importance estimation; robust monitoring.
- Sector: Developer Tools — Unified “Memory Budget Wizard”
- Use case: A tool that ingests task type, VRAM budget, throughput/latency targets, and outputs optimal model, precision, token budget, group size, and KV strategy.
- Potential product: CLI/UI integrated with vLLM and common runtimes; supports batch amortization planning and dynamic adjustments.
- Dependencies: Reliable cross-model thresholds; extensibility to varied architectures; continuous telemetry.
Cross-cutting assumptions and dependencies
- Generalization: Findings were derived on the Qwen3 family and two benchmarks (AIME25, GPQA-Diamond). Thresholds such as “8-bit 4B” may shift for other models (e.g., DeepSeek-R1, Gemini, o3), tasks (coding, legal, medical), and hardware.
- Frameworks and libraries: Results depend on vLLM, FlashAttention, GPTQ, HQQ, and R-KV/StreamingLLM implementations; different backends may alter memory/speed profiles.
- Workload characteristics: Token budget distribution and accuracy metrics (pass@1, self-consistency) materially affect trade-offs; budget forcing might interact with natural stopping behavior differently across tasks.
- Hardware: Observations (latency/throughput) were measured on NVIDIA A100 80 GB; performance varies across GPU generations and memory bandwidth.
- Safety and compliance: Domain-specific constraints (healthcare, finance) require additional validation to ensure that compression (especially eviction/quantization) does not degrade safety-critical reasoning.
Glossary
- 4-bit quantization: Replacing 32-bit weights with 4-bit representations to reduce memory usage, often with minimal accuracy loss. "While 4-bit quantization has emerged as a memory-optimal choice for non-reasoning models and zero-shot tasks across scales, we show that this universal prescription fails for reasoning models"
- AIME25: A competition-level math benchmark designed to test multi-step reasoning. "AIME25~\citep{aime2025problems} is a competition-level mathematical benchmark that stresses multi-step reasoning."
- attention sink: The initial tokens preserved in attention to stabilize decoding in long generations. "preserves the most recent key and value tensors, in addition to the initial sequence tokens known as the attention sink."
- batched inference: Running multiple inputs concurrently to amortize model costs across requests. "This bottleneck is magnified in batched inference: with model weights amortized, the aggregated KV cache becomes the primary memory constraint."
- best-of-n: A selection strategy that chooses the best result among multiple sampled generations. "comparing strategies such as majority voting, best-of-n, and verification-based search"
- bit-normalized studies: Analyses that compare performance while fixing the total number of parameter bits. "Bit-normalized studies examine how performance at different precisions scales with total model bits"
- budget forcing: A technique that forces a model to continue generating until a specified token count is reached. "\citet{muennighoff2025s1} introduces budget forcing to scale serial responses beyond the model's natural length for higher accuracy."
- calibration set: A small dataset used to estimate statistics for post-training quantization. "minimizes layer-wise quantization error using a small calibration set"
- calibration-free quantization: Quantization that does not require a calibration dataset. "a fast, calibration-free quantization method that is particularly well-suited for online KV cache quantization."
- chain-of-thought: Intermediate reasoning steps generated by the model to solve complex problems. "Reasoning models are typically trained to produce an extended chain-of-thought"
- chain-of-thought prompting: A prompting method to elicit step-by-step reasoning. "Chain-of-thought prompting elicits intermediate steps"
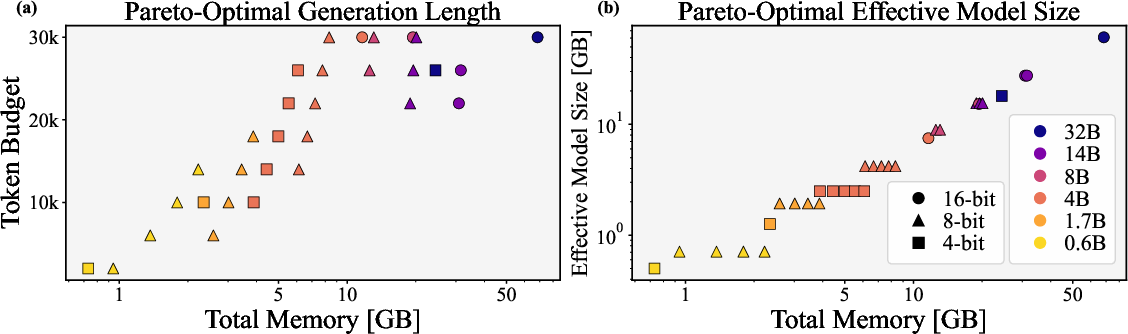
- effective size: The memory footprint of model weights (parameters multiplied by precision). "models with an effective size below 8-bit 4B parameters"
- FLOPs: Floating point operations; a measure of computational cost. "weight-only quantization, which reduces memory and latency without affecting FLOPs."
- FlashAttention: An optimized attention algorithm improving speed and memory efficiency. "using the vLLM framework~\citep{kwon2023efficient} with FlashAttention~\citep{dao2023flashattention} as the attention backend."
- GPQA-Diamond: A scientific knowledge benchmark emphasizing integrated reasoning. "GPQA-Diamond~\citep{rein2024gpqa} emphasizes scientific knowledge and integrated reasoning across domains such as chemistry, biology, and physics"
- GPTQ: A post-training weight-only quantization method minimizing layer-wise error. "Model weights are quantized to 4- and 8-bit using GPTQ."
- HQQ: A fast, calibration-free quantization backend for online KV cache quantization. "with an HQQ backend~\citep{badri2023hqq}, a fast, calibration-free quantization method that is particularly well-suited for online \gls{kv} cache quantization."
- inverse-Hessian information: Curvature information used to adjust weights during quantization. "updates weights using inverse-Hessian information."
- knowledge-intensive reasoning: Tasks that rely heavily on stored factual knowledge across domains. "For knowledge-intensive reasoning, 4-bit weight quantization is broadly memory-optimal"
- KV cache: The stored key and value tensors from attention used to speed up autoregressive decoding. "the KV cache rather than model size can dominate memory."
- KV cache eviction: Dropping less important cached keys/values to cap memory and computation. "KV cache eviction has also emerged as a critical optimization strategy"
- KV cache preemption: Runtime clearing or interruption of cached attention states due to memory pressure. "without out-of-memory errors or KV cache preemption."
- KV cache quantization: Storing the attention keys/values in lower precision to reduce memory during decoding. "KV cache quantization stores key and value tensors at reduced precision to lower the memory footprint and memory bandwidth during decoding."
- majority voting: Aggregating multiple generated answers by selecting the most frequent one. "majority voting selects the final answer as the most frequent among the independently sampled outputs"
- memory--accuracy trade-off: The balance between memory usage and model performance. "We systematically explore the memory--accuracy trade-offs"
- parallel scaling: Improving performance by sampling multiple reasoning trajectories in parallel. "Another line of work, parallel scaling, generates multiple independent reasoning trajectories"
- Pareto frontier: The set of configurations not dominated in both memory and accuracy. "Figure~\ref{fig:aime25_qwen3_accuracy_total_memory} reveals the Pareto frontier for accuracy versus total memory"
- Pareto-optimal: A configuration where improving one metric would worsen another. "Composition of Pareto-optimal configurations (AIME25, Qwen3)."
- pass@1 accuracy: The probability that the top generated answer is correct. "The plot illustrates the trade-off between pass@1 accuracy and total memory (weights + KV cache) for the Qwen3 family."
- per-channel symmetric quantization: Quantizing each tensor channel independently with symmetric ranges. "we use per-channel symmetric quantization of both keys and values"
- prefill: The initial context-processing phase before token-by-token decoding. "During prefill, the KV tensors for the entire input context are quantized and cached in low precision."
- post-training quantization: Quantizing a trained model without further retraining. "Weight-only post-training quantization replaces full-precision weights with low-bit representations without retraining"
- quantization-aware training: Training with quantization simulated in the forward pass to improve low-bit performance. "Quantization-aware training extends this idea by training models with quantized weights in the forward pass"
- quantization error: The error introduced by representing values in reduced precision. "as it is more robust to quantization error"
- R-KV: An eviction method that retains non-redundant, informative tokens during decoding. "R-KV~\citep{cai2025r} proposes redundancy-aware selection for reasoning models"
- redundancy-aware selection: Selecting tokens to keep based on their information and redundancy. "R-KV~\citep{cai2025r} proposes redundancy-aware selection for reasoning models"
- residual buffer: A small recent-token buffer stored at full precision alongside quantized cache. "a full-precision residual buffer of 128 tokens."
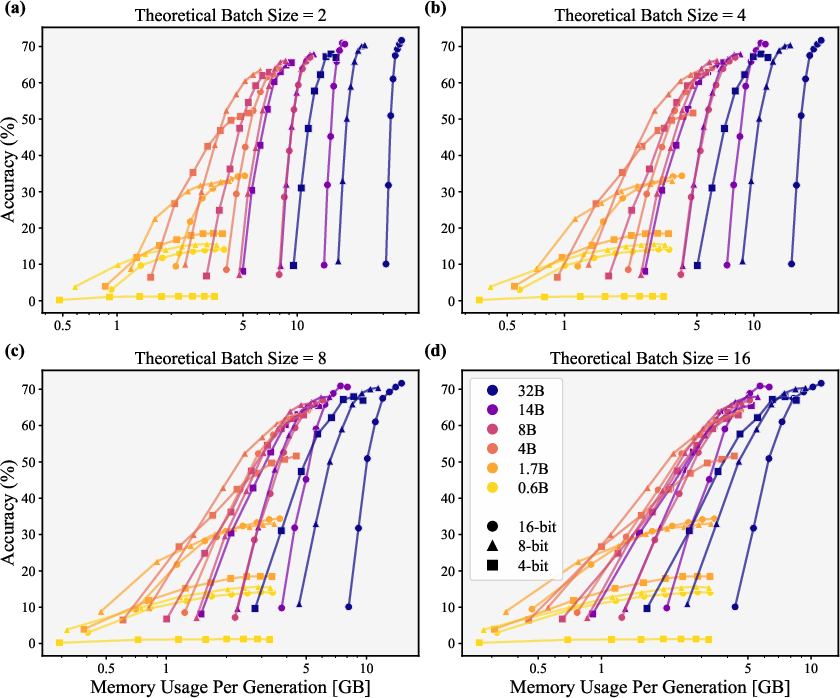
- sampling group size: The number of parallel samples generated per input for aggregation. "sampling group size (, with indicating multiple samples for majority voting)"
- self-consistency: Aggregating diverse reasoning paths to improve answer accuracy. "self-consistency improves performance by sampling diverse rationales and aggregating them via majority voting"
- serial scaling: Increasing the length of a single reasoning trajectory to improve performance. "We refer to this as serial scaling."
- sliding-window mechanism: An eviction strategy that keeps only recent tokens (and sometimes a sink) in the cache. "employs a sliding-window mechanism that preserves the most recent key and value tensors"
- StreamingLLM: A method using sliding-window cache retention (and an attention sink) for long sequences. "StreamingLLM~\citep{xiao2023efficient}, employs a sliding-window mechanism that preserves the most recent key and value tensors, in addition to the initial sequence tokens known as the attention sink."
- test-time compute: The computation spent during inference, such as longer generations or more samples. "for small reasoning models, prioritize model capacity over test-time compute, while for larger ones, maximize test-time compute."
- test-time scaling: Methods that improve performance by increasing inference-time computation. "We scope this work to test-time scaling methods that do not rely on external models such as verifiers or process reward models."
- test-time scaling laws: Empirical relationships describing how performance improves with more inference-time compute. "Test-time scaling laws study how performance changes with increased FLOPs, tokens, or the number of generations"
- throughput: The number of requests processed per second under hardware constraints. "Each point represents the maximum throughput (requests per second) vs. accuracy under 80\,GB VRAM constraints"
- token budget: A limit on the number of tokens generated or processed at inference. "We evaluate token budgets from 2k to 30k in 4k increments."
- vLLM: A high-performance inference framework for LLMs. "using the vLLM framework"
- verification-based search: Using a verifier to select or guide among candidate generations. "comparing strategies such as majority voting, best-of-n, and verification-based search"
- weight-only quantization: Quantizing only the weights (not activations), typically post-training. "Unlike weight-only quantization, KV quantization is applied online at inference."
- zero-shot: Performing a task without task-specific fine-tuning or examples. "zero-shot tasks across scales"
Collections
Sign up for free to add this paper to one or more collections.