- The paper demonstrates that MC# achieves over 6x weight reduction while maintaining performance via a hybrid static quantization and dynamic pruning approach.
- It introduces Pre-Loading Mixed-Precision Quantization (PMQ), which optimally allocates bits using integer programming to compress experts effectively.
- Online Top-any Pruning (OTP) utilizes Gumbel-Softmax sampling to dynamically select experts during inference, reducing computational overhead by 20%.
Mixture Compressor for Mixture-of-Experts Large Models
The research paper introduces MC#, a framework designed to optimize the mixture-of-experts (MoE) models, particularly focusing on LLMs and vision-LLMs (VLMs). This work presents an innovative approach to model compression, aiming to reduce computational and memory overhead associated with MoE architectures.
Introduction
MoE represents an efficient scaling method for LLMs and VLMs, expanding model capacity by utilizing multiple expert branches while ensuring sparse activation for efficiency. However, MoE models face significant challenges during deployment due to their memory and computational demands, predominantly driven by the inference process, which activates multiple experts simultaneously. The paper addresses these challenges by proposing MC#, a unified mixture compressor framework combining static quantization and dynamic expert pruning.
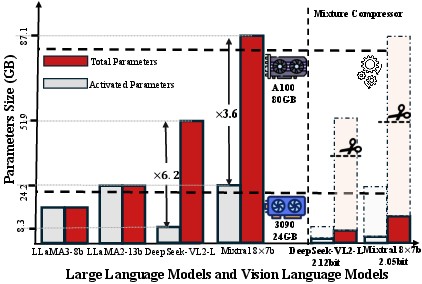
Figure 1: Comparison of total parameter size and inference activated parameter size on various large models and compressed Mixtral MoE-LLMs and DeepSeek VLMs.
Framework Overview
The MC# framework consists of two primary components:
- Pre-Loading Mixed-Precision Quantization (PMQ): PMQ aims to reduce storage and loading overhead by optimizing bit allocation using a linear programming model, considering expert significance and quantization error for achieving a Pareto-optimal trade-off between model size and performance.
- Online Top-any Pruning (OTP): OTP enhances inference efficiency by dynamically selecting a subset of experts for activation during runtime. It leverages Gumbel-Softmax sampling to model expert activation as a learnable distribution, allowing fine-grained control over which experts are activated.
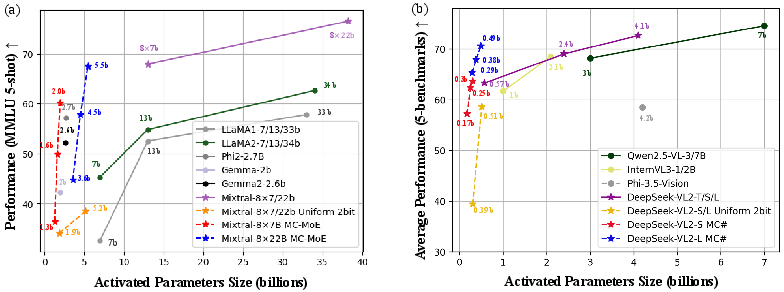
Figure 2: Performance across different LLMs and VLMs with varying activated parameters.
Implementation Details
Pre-Loading Mixed-Precision Quantization (PMQ)
PMQ employs adaptive bit allocation to statically compress experts within MoE models. This approach formulates the allocation problem as an Integer Programming problem, optimizing quantization configurations based on expert significance metrics derived from access frequency and activation-weighted importance.
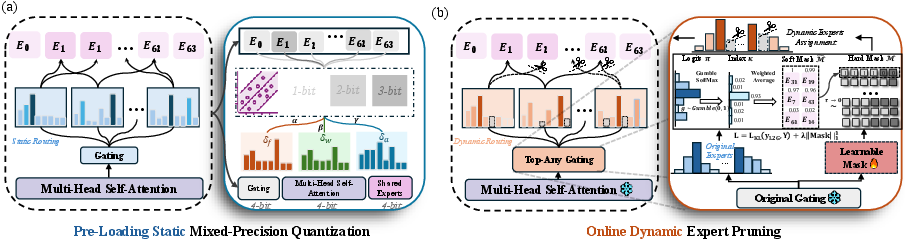
Figure 3: Overview of MC pipeline including PMQ and OTP stages for experts.
Online Top-any Pruning (OTP)
OTP offers a novel learning mechanism for dynamically adjusting expert activation at inference time. By using Gumbel-Softmax sampling, it creates a differentiable process for selecting the active experts, enabling higher inference efficiency without significant performance degradation. The framework incorporates a learnable router to apply token-wise pruning strategies effectively.


Figure 4: Workflow of OTP demonstrating selective expert activation and pruning.
Experimental Results
The paper reports evaluation results on both MoE-LLMs and MoE-VLMs across various benchmarks. The proposed MC# framework achieves significant compression, reducing model size while maintaining comparable performance to baseline full-precision models. The hybrid compression strategy results in over 6x weight reduction with minimal accuracy loss. Furthermore, the OTP stage reduces expert activation by 20% with negligible performance impact.
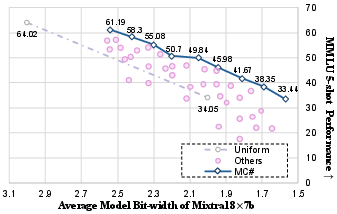
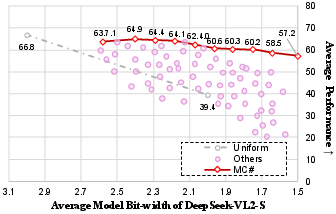
Figure 5: Quantized performance of Mixtral under different mixed-precision strategies.
Conclusion
This study effectively addresses the deployment challenges of MoE models by introducing a robust framework for model compression. The MC# framework not only reduces computational and memory overhead but also enhances efficiency through mixed-precision quantization and dynamic pruning. Future work could explore further applications in different multimodal settings and optimize these strategies for specific hardware configurations.
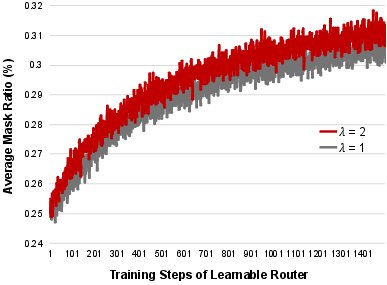
Figure 6: Ablation of mask ratio during training showcasing optimal pruning strategies.
The proposed approach significantly contributes to the practicality of deploying large MoE models in diverse computing environments, paving the way for more efficient AI applications.