- The paper presents a novel framework that integrates code-aligned dataset creation with chain-of-thought reasoning for structured visual generation and editing.
- It employs a three-stage training pipeline and introduces StructScore, a metric that achieves high correlation with human ratings and outperforms traditional metrics.
- Results highlight that explicit multimodal reasoning is critical for improving factual accuracy and semantic correctness in structured image editing tasks.
Factuality in Structured Visual Generation and Editing: A Comprehensive Framework
Motivation and Problem Statement
The paper addresses a critical gap in current visual generative models: the inability to reliably generate or edit structured visuals—such as charts, diagrams, and mathematical figures—with high factual fidelity. While state-of-the-art models excel at producing aesthetically pleasing natural images, they consistently underperform on tasks requiring precise composition planning, text rendering, and multimodal reasoning. This deficiency is particularly acute in domains where semantic correctness and strict adherence to instructions are paramount, as opposed to mere visual plausibility.
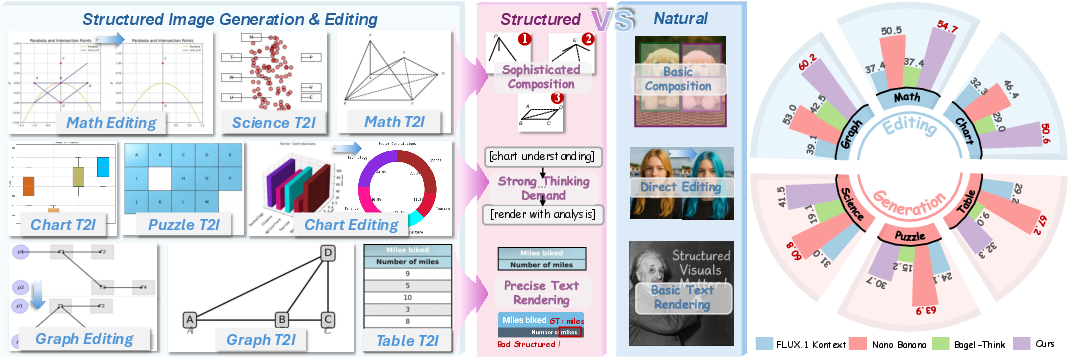
Figure 1: Overview of the proposed framework, highlighting the unique challenges of structured visual generation and the model's competitive performance on both generation and editing benchmarks.
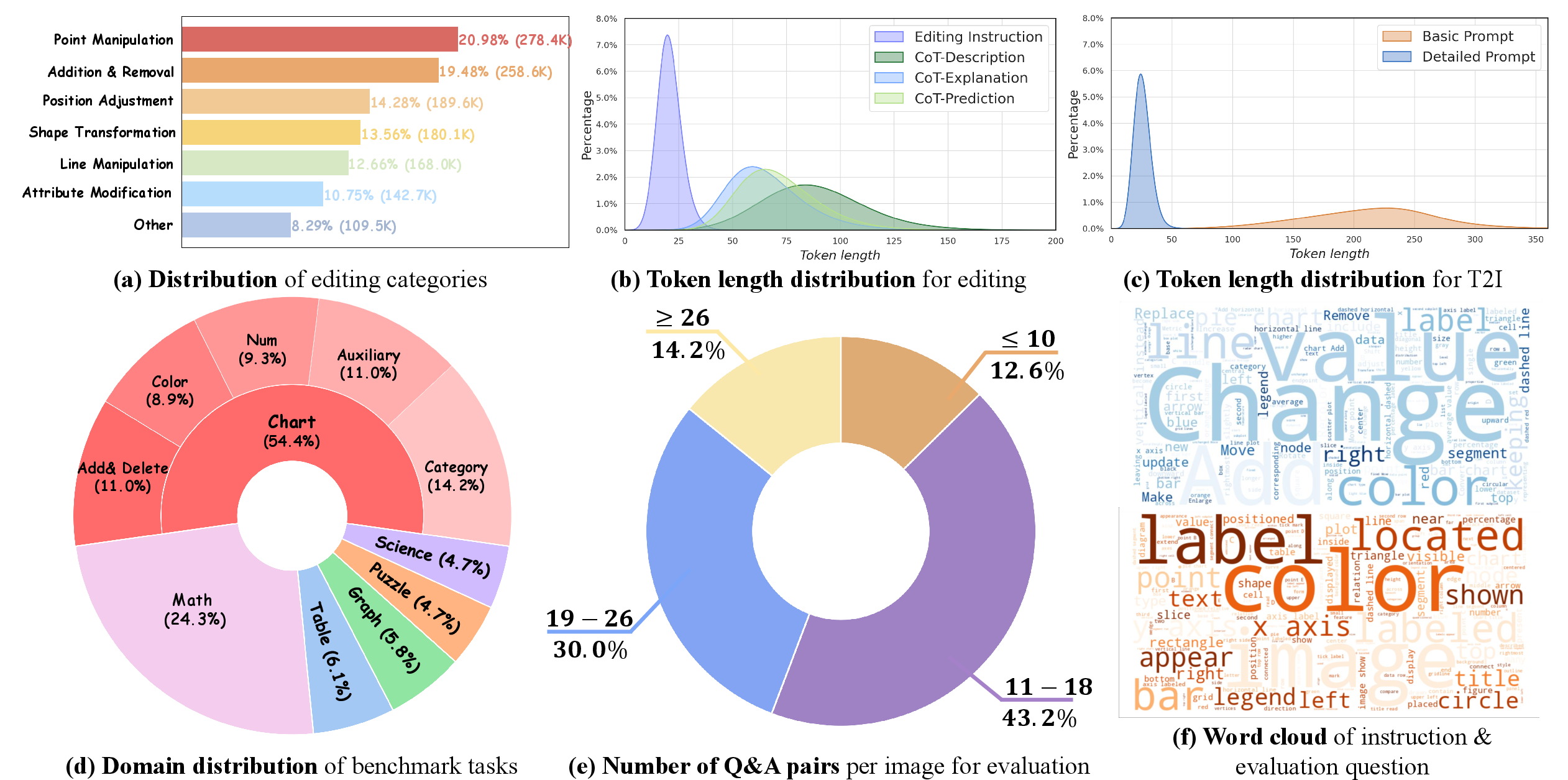
Dataset Construction: Code-Aligned, Reasoning-Augmented Pairs
A central contribution is the construction of a large-scale, high-quality dataset comprising 1.3 million structured image pairs. The dataset is derived from executable drawing programs (primarily Python and LaTeX), ensuring strict code-image alignment and verifiable state transitions. The data curation pipeline leverages GPT-5 to extract salient visual features, generate paired editing instructions, and synthesize chain-of-thought (CoT) reasoning annotations for each example.
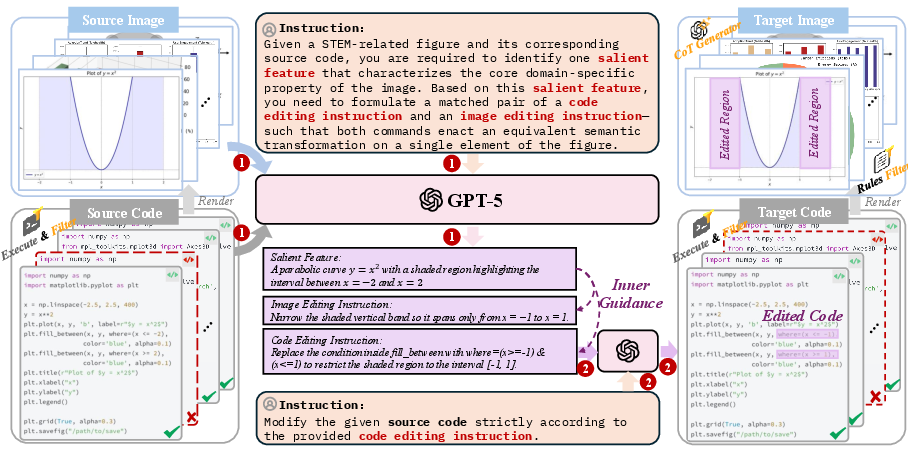
Figure 2: Data construction pipeline, illustrating the use of GPT-5 for feature extraction, instruction generation, and rigorous filtering to ensure dataset quality.
This approach yields several advantages over prior datasets:
- Precise Supervision: Each image is directly linked to its source code, enabling unambiguous mapping between instructions and visual changes.
- Rich Annotations: CoT reasoning traces provide explicit semantic and analytical signals, supporting complex generation and editing tasks.
- Diversity and Coverage: The dataset spans multiple structured domains, including mathematics, charts, puzzles, scientific figures, graphs, and tables.
Benchmarking and Evaluation: StructBench and StructScore
To rigorously evaluate model performance on structured visual tasks, the authors introduce StructBench, a benchmark comprising 1,714 carefully curated samples across six domains. The evaluation protocol is built around StructScore, a novel metric that decomposes each instance into a set of atomic question-answer (QA) pairs, probing fine-grained visual attributes and relations.
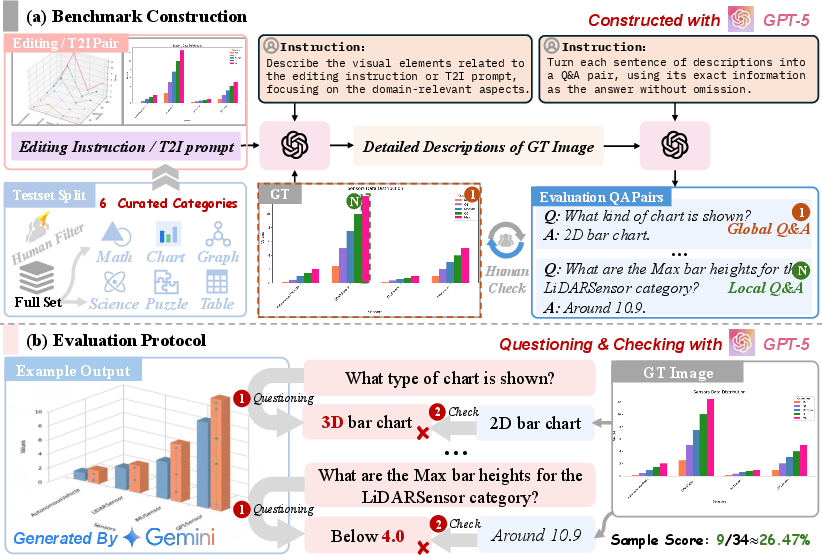
Figure 3: Benchmark construction and evaluation workflow, detailing the clustering of data, QA pair generation, and multi-turn evaluation protocol.

Figure 4: Comparison of initial and revised atomic QA pairs, demonstrating the impact of atomicity on metric reliability.
Key aspects of the evaluation framework include:
Model Architecture and Progressive Training
The unified model is based on FLUX.1 Kontext, a diffusion transformer architecture, augmented with a lightweight MLP connector to align Qwen-VL multimodal features with the generative backbone. The training pipeline is organized into three progressive stages:
- Unified Alignment: Freezes the backbone and aligns Qwen-VL features using simple data, ensuring robust multimodal feature integration.
- Hybrid Visual Learning: Jointly fine-tunes on both structured and natural image data, employing mask-based loss weighting to handle the unique pixel statistics of structured visuals.
- Thinking Enhancement: Incorporates CoT reasoning traces as long-context inputs, enabling explicit multimodal reasoning and improved semantic fidelity.
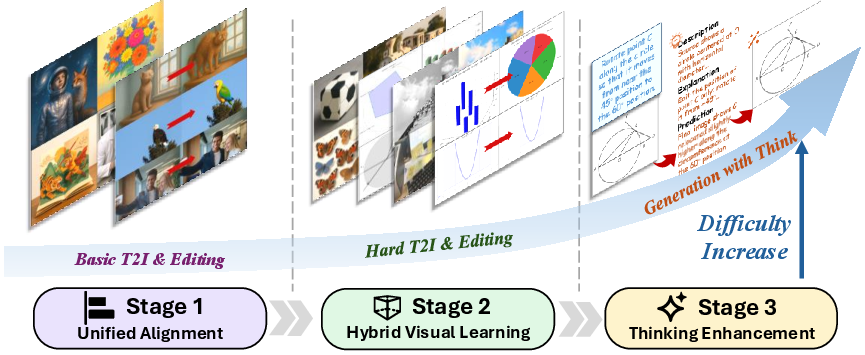
Figure 6: Three-stage progressive training pipeline, illustrating the increasing complexity and reasoning integration across stages.
Experimental Results and Analysis
The evaluation covers 15 models, including leading closed- and open-source systems. The main findings are:
- Closed-Source Superiority, but Suboptimal Performance: Closed-source models (e.g., GPT-Image, Nano Banana) outperform open-source baselines, but even the best models achieve only ~50% accuracy on structured tasks, indicating substantial headroom for improvement.
- Data Quality as the Primary Driver: Models trained on the proposed dataset exhibit significant gains over those trained on natural-image corpora, regardless of architectural differences.
- Reasoning Integration is Critical: Explicit reasoning, both during training and at inference time, yields consistent improvements across architectures. The use of an external reasoner (GPT-5) at inference time enables the generator to focus on synthesis, while the reasoner handles complex analysis and planning.
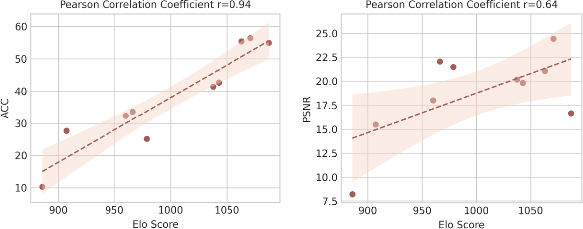
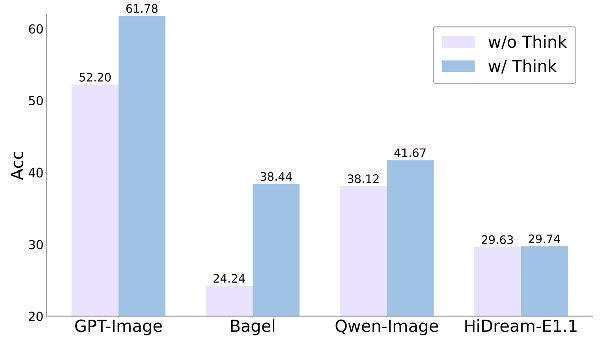
Figure 7: Pearson correlation analysis among Accuracy, PSNR, and human Elo score, demonstrating the superior alignment of StructScore with human judgments.

Figure 8: Case study showing that explicit reasoning improves output fidelity, especially for complex editing tasks.
Implications and Future Directions
The results underscore the inadequacy of current generative models for structured visual domains, where factual accuracy and compositional reasoning are essential. The findings suggest several implications:
- Unified Multimodal Models Require Enhanced Reasoning: Scaling model parameters alone is insufficient; explicit integration of multimodal reasoning, both in training and inference, is necessary for high-fidelity structured visual generation.
- Evaluation Must Move Beyond Aesthetics: Fine-grained, attribute-level evaluation is essential for progress in domains where semantic correctness is non-negotiable.
- Data Curation Pipelines Should Leverage Programmatic Supervision: Code-aligned datasets provide a scalable and verifiable foundation for structured visual tasks.
The authors propose extending the framework to additional structured domains, such as molecular diagrams, musical notation, and structured video, further broadening the applicability of unified multimodal models.
Conclusion
This work presents a comprehensive framework for structured image generation and editing, addressing the unique challenges of factuality, compositionality, and multimodal reasoning. Through the construction of a large-scale, code-aligned dataset, a progressive training pipeline, and a rigorous evaluation benchmark, the study establishes new baselines and highlights the critical role of explicit reasoning in structured visual tasks. The results indicate that substantial progress remains to be made, particularly in bridging the gap between visual plausibility and semantic correctness. The release of the dataset, model, and benchmark is poised to catalyze further research in unified multimodal foundation models for structured visuals.