- The paper introduces LLM-Hanabi, a benchmark that quantifies Theory-of-Mind and rationale inference through natural language gameplay in Hanabi.
- It demonstrates that first-order ToM, where agents interpret hints directly, is more predictive of game success than second-order reasoning.
- Experimental results indicate that large reasoning models outperform standard LLMs, suggesting that enhancing direct rationale inference is crucial for improved collaborative AI.
Motivation and Context
The paper introduces LLM-Hanabi, a benchmark designed to rigorously evaluate the Theory-of-Mind (ToM) and rationale inference capabilities of LLMs and Large Reasoning Models (LRMs) in dynamic, multi-agent collaborative environments. Unlike prior ToM benchmarks that focus on static, text-based tasks, LLM-Hanabi leverages the cooperative card game Hanabi, which is characterized by imperfect information and the necessity for agents to infer intent from sparse, ambiguous communication. This environment provides a controlled yet challenging testbed for assessing the inferential and collaborative reasoning skills of LLMs.
LLM-Hanabi Benchmark Design
LLM-Hanabi operationalizes the Hanabi game by translating all game states and actions into natural language, enabling LLM-driven agents to interact with the environment and each other through structured prompts. The benchmark is fully automated, supporting scalable evaluation across a wide range of models.
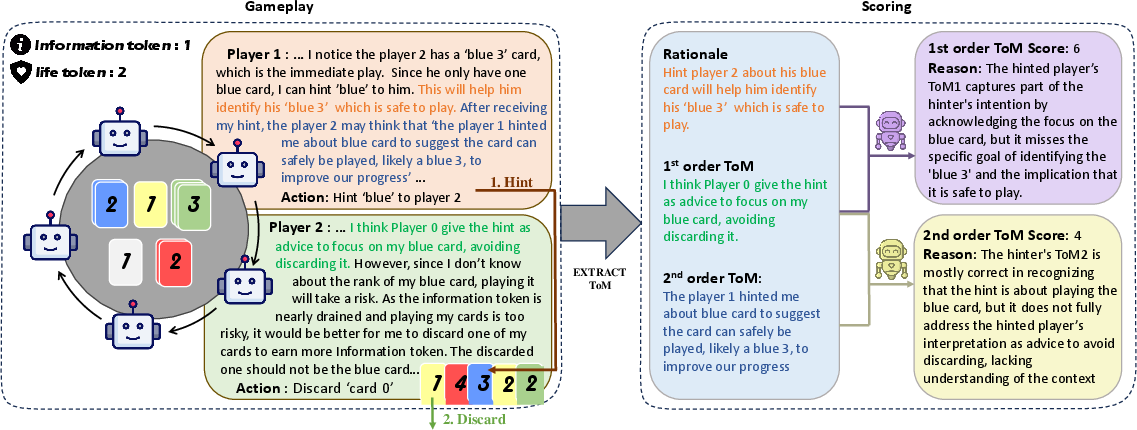
Figure 1: Overview of the gameplay and evaluation process of LLM-Hanabi.
The evaluation framework is centered on two axes:
- Game Performance: Quantified by the final Hanabi score, reflecting the agents' ability to achieve the cooperative objective under imperfect information.
- ToM Performance: Assessed via structured extraction of rationale and ToM statements during gameplay, followed by post-hoc scoring using an LLM-as-a-judge.
Theory-of-Mind Evaluation Protocol
For each hint action, the following are extracted:
- Rationale: The hinter's explicit justification for the hint.
- First-Order ToM: The recipient's interpretation of the hinter's intent.
- Second-Order ToM: The hinter's prediction of how the recipient will interpret the hint.
After each game, the LLM-as-a-judge computes:
- First-Order ToM Score: Alignment between rationale and recipient's interpretation.
- Second-Order ToM Score: Alignment between recipient's interpretation and hinter's prediction.
This protocol enables quantitative, scalable assessment of both direct and higher-order inferential reasoning.
Experimental Evaluation
Model Selection and Setup
The benchmark evaluates a diverse set of LLMs and LRMs, including open-source and proprietary models spanning a range of parameter counts and architectures (e.g., Llama-3.1, Llama-4, Deepseek-R1, QwQ-32B, Qwen3, GPT-4.1, Gemini-2.5). All models are prompted using Chain-of-Thought (CoT) reasoning and are evaluated in a 5-player Hanabi configuration to maximize interaction complexity.
Metrics
- Game Score: Aggregate of the highest card ranks played across all color stacks (max 25).
- ToM Score: Mean of first- and second-order ToM scores across all hint interactions.
Results
LRMs consistently outperform standard LLMs in both game and ToM metrics. Deepseek-R1 achieves the highest average game score (30.00), with QwQ-32B and GPT-4.1 also demonstrating strong performance. In ToM evaluation, GPT-4.1 and Deepseek-R1 are the top performers in their respective categories.
A salient finding is the persistent gap between first-order and second-order ToM scores across all models: first-order ToM (recipient's inference of intent) is significantly higher than second-order ToM (hinter's prediction of recipient's inference). This suggests that while models are adept at direct rationale inference, they struggle with recursive mental state modeling.
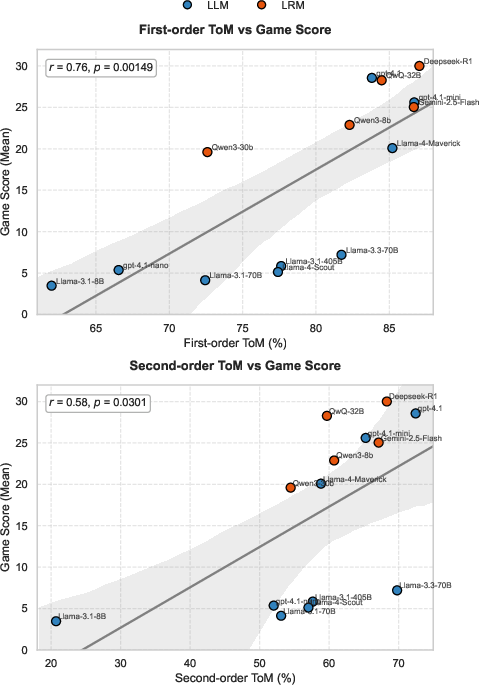
Figure 2: Correlation analysis between game score and theory-of-mind performance.
Correlation analysis reveals a strong positive relationship between ToM proficiency and game performance. Notably, first-order ToM exhibits a higher correlation with game success (r=0.76) than second-order ToM (r=0.58), indicating that the ability to accurately interpret a partner's rationale is more critical for effective collaboration than higher-order belief modeling.
Implications and Future Directions
The results have several implications for the development of collaborative AI systems:
- First-Order ToM as a Priority: The empirical evidence that first-order ToM is a stronger predictor of collaborative success than second-order ToM suggests that future model development and alignment efforts should prioritize direct rationale inference capabilities.
- Benchmark Utility: LLM-Hanabi provides a scalable, automated, and ecologically valid framework for evaluating multi-agent reasoning, filling a gap left by static or adversarial benchmarks.
- Model Architecture: The superior performance of LRMs, particularly those trained with explicit reasoning objectives or reinforcement learning, indicates that architectural and training innovations targeting inferential reasoning yield tangible benefits in collaborative settings.
- Generalization: While Hanabi is an idealized environment, the methodology can be extended to other imperfect information games and real-world multi-agent scenarios, including negotiation, coordination, and human-AI teaming.
Limitations
The benchmark is currently restricted to the Hanabi environment and language-based reasoning. It does not address multimodal or non-linguistic collaboration, and the reliance on an LLM-as-a-judge introduces potential biases. Fixed hyperparameters and prompt formats may also limit generalizability. Future work should explore broader environments, alternative evaluation modalities, and human-in-the-loop assessments.
Conclusion
LLM-Hanabi establishes a rigorous, automated benchmark for evaluating rationale inference and Theory-of-Mind in collaborative agents. The findings demonstrate that large reasoning models substantially outperform standard LLMs in both gameplay and ToM, and that first-order ToM is a more significant determinant of collaborative success than higher-order reasoning. These insights provide a concrete direction for the development of more effective, interpretable, and collaborative AI systems.

