Mask2IV: Interaction-Centric Video Generation via Mask Trajectories
Abstract: Generating interaction-centric videos, such as those depicting humans or robots interacting with objects, is crucial for embodied intelligence, as they provide rich and diverse visual priors for robot learning, manipulation policy training, and affordance reasoning. However, existing methods often struggle to model such complex and dynamic interactions. While recent studies show that masks can serve as effective control signals and enhance generation quality, obtaining dense and precise mask annotations remains a major challenge for real-world use. To overcome this limitation, we introduce Mask2IV, a novel framework specifically designed for interaction-centric video generation. It adopts a decoupled two-stage pipeline that first predicts plausible motion trajectories for both actor and object, then generates a video conditioned on these trajectories. This design eliminates the need for dense mask inputs from users while preserving the flexibility to manipulate the interaction process. Furthermore, Mask2IV supports versatile and intuitive control, allowing users to specify the target object of interaction and guide the motion trajectory through action descriptions or spatial position cues. To support systematic training and evaluation, we curate two benchmarks covering diverse action and object categories across both human-object interaction and robotic manipulation scenarios. Extensive experiments demonstrate that our method achieves superior visual realism and controllability compared to existing baselines.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “Mask2IV: Interaction-Centric Video Generation via Mask Trajectories”
Overview
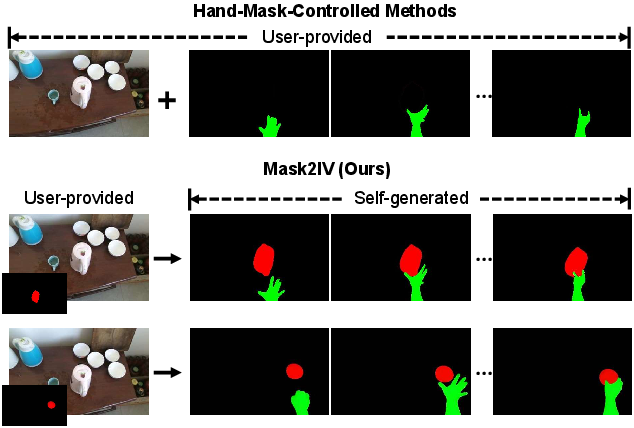
This paper introduces Mask2IV, a system that can create short videos showing a person’s hands or a robot arm interacting with a specific object. Instead of asking the user to provide detailed, frame-by-frame instructions, the system first imagines a sensible path for how the hands and the object should move, and then turns that plan into a realistic video. This helps researchers and robot builders get high-quality, controllable videos of interactions without doing lots of manual labeling.
What are the paper’s main goals?
The authors want video generation that’s not only realistic but also easy to control. In simple terms, they aim to:
- Let you choose which object to interact with.
- Let you tell the system what action should happen (for example, “pick up the mug”).
- Let you place where the object should end up (for example, “move the toy car to this spot”).
How does Mask2IV work?
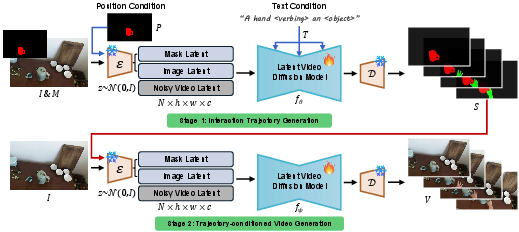
Mask2IV uses a two-stage approach, like planning a trip and then taking it:
- Interaction Trajectory Generation Think of a “mask” as a colored sticker that shows where something is in an image (e.g., the red sticker marks “the object,” and the green sticker marks “the hand or robot”). A “trajectory” is the path those stickers take over time.
- Input: an initial image, a mask that highlights the target object, and either a short action description (“a hand closing a laptop”) or a simple “target position mask” showing where you want the object to end up.
- Output: a sequence of colored masks over time that shows how the hand/robot and object move and interact—like a comic strip of outlines before the final artwork is filled in.
- Two ways to guide the trajectory:
- Text guidance (TT-Gen): You describe the action in words, and the model predicts how the hand/object should move to do that action.
- Position guidance (PT-Gen): You mark the final location of the object, and the model figures out a smooth path from start to finish.
Analogy: Stage 1 is like sketching the motion using colored outlines so the system focuses on “where things go” without worrying yet about textures, lighting, and fine details.
- Trajectory-Conditioned Video Generation Once the motion path is ready, the model turns those outlines into a realistic, full-color video.
- The video generator takes the initial image and the mask trajectory and “paints” each frame so hands, objects, and backgrounds look natural.
- To make this more robust and realistic, the authors add two smart tricks:
- Random “inflate/deflate” of masks: Slightly enlarging or shrinking masks makes the model less sensitive to exact mask shapes, so it generalizes better.
- Contact-focused training: The model pays extra attention to areas where hands/robots touch the object, improving those tricky boundary regions.
Under the hood: The paper uses modern “diffusion models,” which you can imagine as starting with noisy, blurry frames and gradually cleaning them up to reveal the final video. A “VAE” is used to compress images into a form the model can process efficiently, and “cross-attention” is a mechanism that helps the model “listen” to the text prompt or the position cue while generating motion and visuals.
What did they test, and what did they find?
The authors built two benchmarks to fairly train and test their method:
- Human–Object Interaction: HOI4D (videos of hands interacting with many different objects).
- Robotic Manipulation: BridgeDataV2 (videos of robot arms moving and placing objects).
They compared Mask2IV to other methods:
- DynamiCrafter (a strong image-to-video baseline that doesn’t offer fine control).
- CosHand and InterDyn (methods that use masks but typically require dense mask sequences provided by the user).
Key findings:
- Mask2IV produced videos that were more realistic and better controlled than the baselines. In simpler terms: fewer visual glitches, smoother and more believable motions, and better alignment with the requested action or target position.
- It handled different objects and actions well—just changing the input object mask or text prompt led to different, sensible interactions.
- It paid special attention to the “contact” area where the hand or robot touches the object, leading to cleaner, more convincing interactions.
Why these results matter: In metrics that measure video quality and how well the video matches the intended action, Mask2IV consistently scored better. More importantly for practical use, it doesn’t force users to provide dense mask sequences for every frame; it predicts those automatically and still stays controllable.
Why is this important?
This research can have a big impact on areas like:
- Robot learning: Robots can learn from many realistic, controllable videos showing how to manipulate objects, without humans needing to manually label every frame.
- VR/AR and animation: Creators can quickly produce clear, believable interaction scenes by telling the system what to do and which object to use.
- Planning and simulation: Engineers can test how an action plays out before doing it in the real world.
Overall, Mask2IV makes interaction-focused video generation more practical, flexible, and precise by splitting the problem into “plan the motion” and “render the video,” and by letting users control interactions with simple inputs like text or a target position.
Final takeaway
Mask2IV shows that a two-stage approach—first predicting mask-based motion trajectories, then generating the final video—can produce realistic, controllable videos of hands or robots interacting with objects. It avoids the need for heavy manual inputs, works with both text and position cues, and focuses on the key moment where contact happens. This is a step forward for building smarter, more useful video generation tools that can help robots learn, creators design, and researchers study interactions more effectively.
Knowledge Gaps
Unresolved Gaps, Limitations, and Open Questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper that future work could address:
- Error propagation across stages: Stage 2 is trained on ground-truth trajectories but tested on Stage-1 predictions, creating exposure bias. No scheduled sampling, self-training, or uncertainty-aware conditioning is explored to mitigate this distribution shift.
- Trajectory uncertainty and multimodality: The system does not estimate or express uncertainty over multiple plausible interaction trajectories; there is no mechanism to sample or rank diverse valid outcomes for the same prompt.
- Limited control axes: Control is restricted to object selection, action text, and end-position masks. There is no fine-grained control over speed, timing, intermediate waypoints, grasp timing, force, or velocity profiles.
- 3D and physics grounding: Trajectories are 2D masks without physical constraints; there is no modeling of 3D pose, contact forces, collision avoidance, or dynamics consistency (e.g., gravity, friction, object inertia).
- Camera motion handling: The method does not explicitly estimate or control camera trajectory; robustness to large or rapid viewpoint changes and rolling shutter artifacts is not studied.
- Long-horizon interactions: Videos are limited to 16 frames at 320×512; multi-step or long-duration tasks (e.g., pick–place–open–pour) are not addressed, and temporal stability over longer sequences is untested.
- Multi-object and multi-contact scenarios: Beyond selecting a single target object, the approach does not handle simultaneous interactions with multiple objects, sequential object manipulation, or avoidance of non-target objects.
- Articulated and deformable objects: Although articulated parts are color-coded, there is no explicit articulation modeling or deformable object handling (cloth, cables, fluids); generalization to such cases is unknown.
- Robot/human kinematic feasibility: Generated motions are not checked against hand/robot kinematic limits or joint constraints; grasp pose feasibility and reachability are not enforced or evaluated.
- Orientation and 6-DoF control: Position-conditioned trajectories specify 2D placement; there is no explicit handle on object orientation (full 6-DoF), in-hand reorientation, or tool-use poses.
- Occlusion and clutter robustness: Robustness to heavy occlusions, cluttered scenes, similar-looking distractors, small or transparent objects, and specular surfaces is not quantified.
- Noisy mask supervision: For BridgeData V2, masks derive from GroundingDINO+SAM2 and a temporal mIoU heuristic; the accuracy/consistency of these pseudo-labels and their impact on performance are not evaluated.
- Language grounding limits: HOI prompts are template-based, limiting linguistic diversity. The model’s handling of synonyms, compositional commands, ambiguous language, or negation (e.g., “not pick up”) is untested.
- Text–object binding: There is no mechanism to resolve conflicts when text refers to one object while the mask indicates another, nor to disambiguate among visually similar instances using language cues.
- Control success metrics: Evaluation lacks task-specific measures such as end-position error w.r.t. the target mask, contact accuracy over time, grasp/contact duration, or trajectory adherence scores.
- Physical plausibility metrics: There is no metric for physics realism (e.g., interpenetration, slipping, object stability) or learned physics priors; perceptual quality metrics (FVD/LPIPS/SSIM) may not reflect interaction correctness.
- Downstream utility validation: The paper does not test whether generated videos improve policy learning, imitation, or affordance models (e.g., via data augmentation or pretraining) relative to baselines.
- Real-time feasibility: Inference uses 50 DDIM steps on A100s; latency, throughput, and memory footprints for on-robot or interactive applications are not reported or optimized.
- Stage coupling design: It is unclear whether joint training, iterative refinement, or teacher–student distillation across the two stages would reduce compounding errors—this design space remains unexplored.
- Alternative controls and signals: The framework does not study integrating additional weak controls (optical flow, depth, 2D/3D keypoints, bounding boxes) or how they trade off user burden vs. control fidelity.
- Robustness via mask perturbation: Random dilation/erosion is beneficial, but no analysis quantifies how trajectory noise (shape, timing, sparsity) affects output; other robustness strategies are not explored.
- Contact loss dependence: The contact loss assumes reliable hand/object masks during training; its sensitivity to noisy masks and its effect on non-contact regions are not ablated in detail (e.g., λ sensitivity).
- Fairness of baseline adaptations: Baselines are adapted to use predicted masks rather than their native inputs; the degree to which these modifications handicap or benefit them is not rigorously audited.
- Cross-domain generalization: Although a single framework targets humans and robots, cross-domain transfer (train-on-human, test-on-robot and vice versa) and embodiment generalization (new grippers/hands) are not evaluated.
- Generalization to unseen objects/tasks: Performance on out-of-distribution objects, novel affordances, and unseen task verbs is not systematically characterized.
- Failure mode analysis: The paper lacks a systematic taxonomy of failure cases (e.g., hallucinated contacts, missed grasps, object drift) and does not quantify their frequencies or causes.
- Human studies: There are no human evaluations focused on interaction correctness, realism of contacts, or preference tests, which could complement automatic metrics.
- Scalability and resolution: The impact of scaling model size, video resolution, and frame count on controllability and realism is unreported; training efficiency and compute–quality trade-offs are unclear.
- Safety constraints: The framework does not include safety-aware controls (e.g., keep-out zones, force limits) or evaluate unsafe behaviors in generated sequences.
- Reproducibility of data curation: The heuristic for identifying manipulated objects (low temporal mIoU) and the segmentation pipeline are not benchmarked against ground-truth; reproducibility across scenes/datasets is uncertain.
Practical Applications
Context and Summary
Mask2IV introduces a two-stage, interaction-centric video generation framework that predicts mask-based motion trajectories for both actors (human hands, robot arms) and objects, then synthesizes videos conditioned on these trajectories. It supports explicit control over:
- Object specification via an input object mask,
- Action control via text prompts (TT-Gen),
- Target localization via a position mask (PT-Gen).
Key innovations include decoupling trajectory prediction from video synthesis, joint actor–object trajectories, robust training via random dilation/erosion of masks, and a contact loss to improve fidelity in interaction regions. Benchmarks across human–object interaction (HOI4D) and robotic manipulation (BridgeData V2) demonstrate superior realism and controllability versus mask-controlled baselines.
Below are practical applications enabled by the framework, organized by immediacy, linked to sectors, with tools/workflows and feasibility assumptions.
Immediate Applications
These applications can be deployed now with available tooling and standard GPU resources.
- Synthetic robot manipulation dataset augmentation
- Sectors: robotics, software, manufacturing
- What: Generate diverse, controllable pick-and-place or push/pull sequences using PT-Gen (position masks) to expand training sets for visuomotor policies, imitation learning, and affordance learning.
- Tool/workflow: “Robot Data Augmentor” plugin that takes a workspace image + object mask + target mask, outputs 16-frame sequences; integrate into existing pipelines (e.g., BridgeData V2–style workflows).
- Assumptions/dependencies: Reliable object segmentation (e.g., GroundingDINO/SAM2); cloud GPUs; awareness of synthetic-to-real domain gap.
- Controllable product demo and instructional videos
- Sectors: e-commerce, marketing, media
- What: Produce object-specific demos (e.g., opening, closing, placing) using TT-Gen text prompts to showcase product affordances and handling.
- Tool/workflow: “Trajectory-Guided Video Generator” for creative suites; input product image + object mask + action text; export for web/social.
- Assumptions/dependencies: Rights to product imagery; editorial validation for plausibility; compute budget.
- AR/VR interaction prototyping
- Sectors: AR/VR, gaming, UX design
- What: Rapidly storyboard hand–object interactions to validate gameplay or UI concepts without full 3D rigging.
- Tool/workflow: “AR Interaction Storyboard” module; specify object mask and action text; generate video blocks for design review.
- Assumptions/dependencies: 2D-to-3D conversion not covered; used for concepting and visual reference.
- Affordance learning and contact-region supervision
- Sectors: academia, robotics R&D
- What: Create training data with clear contact regions (via Mask2IV’s contact loss emphasis) to train affordance and grasp models.
- Tool/workflow: Generate sequences with actor/object masks; extract contact maps to weight loss or provide labels for affordance networks.
- Assumptions/dependencies: Transferability of synthetic contact cues to real scenes; require mask consistency.
- Human-in-the-loop robotic planning visualization
- Sectors: industrial automation, operations
- What: Visual previews of planned object placements using position masks to aid operators in validating pick-and-place intents.
- Tool/workflow: “Planning Visualizer” front-end; upload scene photo + object mask + desired placement mask; obtain video preview.
- Assumptions/dependencies: Visualization only; actual motion planning and 3D control require separate systems.
- Gesture–object interaction prototyping for HCI
- Sectors: software, HCI, mobile UX
- What: Validate gesture-driven interactions (e.g., pinch-to-grab, swipe-to-push) in app prototypes using TT-Gen.
- Tool/workflow: Prototype tool; feed UI mock + object masks + action prompts; generate demos for stakeholder review.
- Assumptions/dependencies: 2D video suffices for UX validation; not a runtime feature.
- Benchmarking and model evaluation in academia
- Sectors: academia, research labs
- What: Use curated HOI4D/BridgeData V2-based benchmarks to evaluate controllable video generation models and metrics (FVD, LPIPS, SSIM, T2V/V2V similarity).
- Tool/workflow: Adopt Mask2IV training/eval scripts; compare with adapted baselines (DynamiCrafter-ft, CosHand, InterDyn).
- Assumptions/dependencies: Dataset access; reproducibility; GPU resources.
- Semi-automatic trajectory mask annotation for data labeling
- Sectors: data labeling, ML ops
- What: Replace labor-intensive frame-by-frame hand-mask annotation with Mask2IV’s trajectory prediction from a single image + object mask.
- Tool/workflow: “Auto-Trajectory Annotator” that seeds segmentations (GroundedSAM) and generates actor/object mask sequences.
- Assumptions/dependencies: QC loop for correcting errors; performance varies with clutter and egocentric motion.
- Synthetic data governance pilot for robot learning pipelines
- Sectors: policy, compliance, enterprise ML
- What: Establish labeling conventions and audit trails for synthetic sequences used in product ML workflows.
- Tool/workflow: “Synthetic Tagger” to watermark and label Mask2IV-generated videos; integrate with data registries.
- Assumptions/dependencies: Organizational buy-in; clear metadata standards; alignment with internal governance.
- Consumer “how-to” content personalization
- Sectors: education, consumer apps
- What: Create simple, object-specific guidance videos (“open this jar,” “place this utensil”) by drawing a mask and specifying an action.
- Tool/workflow: Mobile app: take photo, tap/trace object mask, choose action/target; cloud generation, return short video.
- Assumptions/dependencies: Cloud compute; reliable on-device segmentation; disclaimers for safety-critical tasks.
Long-Term Applications
These applications require further research, scaling, 3D integration, or regulatory alignment.
- Closed-loop robot learning with generative priors
- Sectors: robotics, AI
- What: Use Mask2IV as a prior for policy learning (imitation/RL), sampling trajectories that shape action distributions and provide visual targets.
- Tool/workflow: Integrate TT-Gen/PT-Gen into training loops; perform sim-to-real adaptation and counterfactual generation.
- Assumptions/dependencies: Physics-consistent 3D dynamics, domain randomization, policy transfer; safety validation.
- Interactive digital twins for smart homes and factories
- Sectors: manufacturing, smart homes, digital twins
- What: Author interaction scenarios (pick/place, open/close) in digital twins with object-specific control; couple with physics engines (e.g., Genesis).
- Tool/workflow: Multi-view capture → 3D reconstruction → Mask2IV trajectory → physics-consistent execution.
- Assumptions/dependencies: 3D scene understanding; multi-camera calibration; realistic physical simulation.
- Real-time assistive robotics previews in healthcare
- Sectors: healthcare, assistive tech
- What: Generate short previews of planned assistive actions (e.g., grasp a cup) for clinicians/patients to verify intent before execution.
- Tool/workflow: On-device or edge inference; human confirmation loop; safe execution pipeline.
- Assumptions/dependencies: Low-latency hardware; safety and regulatory compliance (IEC/ISO medical robotics standards).
- AR step-by-step overlays for maintenance and training
- Sectors: education, field service, aerospace/automotive maintenance
- What: Use mask trajectories as overlays guiding hand–object interactions in AR headsets for complex procedures.
- Tool/workflow: Overlay generation aligned to scene geometry; TT-Gen for action types; PT-Gen for precise placement.
- Assumptions/dependencies: Robust real-time segmentation, spatial anchoring, occlusion handling in AR.
- Curriculum learning and dataset distillation
- Sectors: academia, AI research
- What: Auto-generate progressively complex interaction sequences to train robust policies and representations.
- Tool/workflow: “Curriculum Generator” varying object types, motions, occlusions; feedback loop via performance metrics.
- Assumptions/dependencies: Reliable realism scoring; avoiding overfitting to synthetic biases.
- Safety and standards testing via synthetic edge cases
- Sectors: policy, certification, safety engineering
- What: Synthesize near-miss and hazardous human–robot interactions to stress-test perception and control systems.
- Tool/workflow: “Hazard Case Library” with controlled mask trajectories; evaluation harness integrated with safety KPIs.
- Assumptions/dependencies: Acceptance by regulators; mapping 2D sequences to actionable tests; ethics review.
- Trajectory-aware video editing for professional media
- Sectors: media production, broadcasting
- What: Edit object interactions by re-authoring mask trajectories (swap target object, change action intent, reposition).
- Tool/workflow: NLE plugin allowing mask-trajectory keyframing with TT/PT controls; export consistent sequences.
- Assumptions/dependencies: IP and authenticity policies; watermarking of synthetic edits.
- Multi-agent and articulated interaction generation
- Sectors: robotics, gaming, simulation
- What: Extend to multiple hands/robots, multi-object scenes, and articulated mechanisms (doors, tools).
- Tool/workflow: Multi-channel mask trajectories; hierarchical contact loss; scene-level constraints.
- Assumptions/dependencies: Model scaling; reliable segmentation for multiple entities; larger datasets.
- Embodied AI standards and benchmarking
- Sectors: academia, policy, standards bodies
- What: Define metrics and protocols for interaction-centric generation (e.g., contact fidelity, object-placement accuracy).
- Tool/workflow: Community benchmarks and leaderboards; reference implementations and evaluation suites.
- Assumptions/dependencies: Community adoption; funding; governance frameworks for synthetic data use.
- Consumer home robotics guidance and personalization
- Sectors: consumer robotics, smart home
- What: Household robots preview tasks on specific user objects, adapting guidance to clutter and object variability.
- Tool/workflow: Photo capture → object mask → planned placement → preview video → execution; human approval loop.
- Assumptions/dependencies: Robust clutter segmentation; generalization across home environments; on-device acceleration.
Cross-Cutting Assumptions and Dependencies
- Data quality: Accurate object masks and initial images are pivotal; automatic segmentation may need manual correction in cluttered or egocentric scenes.
- Compute: Training and inference currently require GPUs; mobile/edge deployment will need model compression or distillation.
- Physical realism: 2D video plausibility does not guarantee 3D physical feasibility; coupling with physics engines is needed for control/execution use cases.
- Domain gap: Synthetic-to-real transfer must be managed (domain randomization, fine-tuning); careful evaluation to avoid bias and overfitting.
- Ethics and policy: Synthetic content requires transparent labeling/watermarking; safety-critical applications need rigorous validation and compliance.
- IP and authenticity: Commercial use must respect content rights; synthetic edits should be disclosed to avoid misinformation.
- Tooling integration: Practical adoption benefits from plugins for creative suites, robotics pipelines, and data ops platforms; standardized metadata and APIs will ease deployment.
Glossary
- AdamW: An optimization algorithm that decouples weight decay from gradient-based updates to improve training stability. "We employ AdamW~\cite{adamw} optimizer with a learning rate of and a batch size of 8."
- Ablation study: A systematic evaluation where components of a model are removed or modified to assess their impact on performance. "An ablation study is performed in~\cref{tab:ablation} to evaluate the contribution of each component."
- Affordance reasoning: Inferring how objects can be interacted with or used based on their properties and context. "Generating interaction-centric videos... provide rich and diverse visual priors for robot learning, manipulation policy training, and affordance reasoning."
- CLIP: A vision-LLM that encodes text and images into a shared embedding space for cross-modal tasks. "The text prompt is encoded using CLIP~\cite{clip} and injected into the model via cross-attention."
- Color encoding: Assigning specific colors to segmentation masks to distinguish different classes or roles. "we adopt a unified color encoding scheme for all segmentation masks: actors (hands or robot arms) are encoded in green (0, 255, 0), interacted objects in red (255, 0, 0), and articulated parts (present only in HOI4D) in blue (0, 0, 255)."
- Contact loss: A loss function that prioritizes regions where the actor and object are in contact to improve synthesis fidelity. "we introduce a contact loss to emphasize content in the interaction-rich regions."
- Contact map: A binary map indicating the boundary and overlap regions between actor and object masks. "Specifically, based on the hand mask and object mask , a contact map is defined as:"
- ControlNet: A neural network module that conditions generative models on external control signals like masks or edges. "find that directly concatenating mask latent features with the noise input yields stronger performance than training an auxiliary ControlNet, leading to improved training stability and faster convergence in early stages."
- CosHand: A mask-conditioned generation method originally for images, adapted here to video by concatenating temporal mask latents. "Specifically, CosHand was originally proposed for image generation by concatenating the future mask latent with the noise latent."
- Cross-attention: An attention mechanism that injects conditioning information (e.g., text) into a generative model. "and injected into the model via cross-attention."
- DDIM sampler: A deterministic sampling procedure for diffusion models that accelerates inference. "At inference, the DDIM sampler~\cite{ddim} is used with 50 timesteps to progressively denoise the latent representation and produce the output video."
- Denoising network: The neural component of a diffusion model that predicts noise to reconstruct clean data from noisy inputs. "where is a weighting factor denoting the importance of contact regions in the loss, represents the denoising network, and is the timestep in the forward process."
- Diffusion models: Generative models that learn to reverse a gradual noising process to synthesize data. "Recent advances in diffusion models have substantially improved the generation of realistic and coherent visual content."
- Diffusion objective: The training loss used in diffusion models, often a weighted noise-prediction objective. "The contact map is then used to reweight the diffusion objective, prioritizing contact regions:"
- Dilation and erosion: Morphological operations that expand or shrink mask regions to improve robustness. "we apply random dilation and erosion to the trajectory to enhance the robustness of the generation process."
- DynamiCrafter: A state-of-the-art image-to-video diffusion baseline used as the foundation for the proposed method. "We build our method on DynamiCrafter~\cite{xing2024dynamicrafter}, one of the state-of-the-art image-to-video generation methods, and incorporate extra convolution channels to support encoding of the mask latent."
- EgoVLP: A pretrained video-LLM for evaluating text-video alignment in egocentric data. "To measure text-video alignment, we use pretrained video-LLMs tailored to each dataset: EgoVLP~\cite{egovlp} for the HOI4D and ViCLIP~\cite{internvid} for the BridgeData V2."
- Egocentric views: First-person camera perspectives commonly used to study human-object interactions. "Much of the existing work~\cite{lai2024lego,handi,egovid} targets egocentric views, where diverse human-object interaction behaviors are prevalent."
- Embodied intelligence: Intelligence that arises from agents interacting with the physical world, often via bodies or manipulators. "Generating interaction-centric videos... is crucial for embodied intelligence, as they provide rich and diverse visual priors for robot learning, manipulation policy training, and affordance reasoning."
- GroundedSAM: A segmentation tool that combines grounding and SAM for open-world visual tasks. "If the initial frame contains an actor, we use GroundedSAM~\cite{groundedsam} to perform segmentation and assign the actor a distinct color from that of the object, enabling the model to better differentiate their roles."
- GroundingDINO: An object detection model used to localize targets for video segmentation. "We thus utilize GroundingDINO~\cite{liu2024grounding} for object detection and SAM2~\cite{sam2} for video segmentation, targeting both the robot arm and the interacting object."
- Hand masks: Pixel-wise segmentations of hands used as explicit control signals for generation. "recent studies~\cite{coshand,interdyn} have proposed using hand masks as an explicit control signal for interaction modeling."
- HOI4D: A dataset of human-object interactions with segmentation and temporal annotations. "For HOI, we select the HOI4D~\cite{liu2022hoi4d} dataset."
- Image-to-video diffusion model: A generative model that synthesizes a video conditioned on a single image input. "To preserve the motion priors, we freeze the temporal attention layer and fine-tune the remaining parameters of a pre-trained image-to-video diffusion model."
- InterDyn: A controllable generation framework using hand mask sequences for interaction modeling. "InterDyn~\cite{interdyn} proposes a controllable generation framework using hand mask sequences, but requires dense annotations and is limited to close-up scenes."
- Intersection-over-Union (mIoU): A metric measuring overlap between predicted and ground-truth masks across frames. "we compute the mean Intersection-over-Union (mIoU) of object masks across temporally spaced frames."
- LPIPS: A perceptual similarity metric based on deep features to assess visual fidelity. "and Learned Perceptual Image Patch Similarity (LPIPS)~\cite{lpips} to measure the frame-level visual fidelity."
- Mask-based interaction trajectory: A sequence of masks that encodes the motion of actors and objects over time. "It first predicts a mask-based interaction trajectory (visualized in the top-left corner of each frame), and then generates the video guided by this trajectory."
- Mask latent: The encoded representation of a mask used to condition a diffusion model. "find that directly concatenating mask latent features with the noise input yields stronger performance than training an auxiliary ControlNet"
- Object mask: A binary mask specifying the pixels belonging to a target object. "Given an RGB image and a mask that specifies the object of interest,"
- Object-specific control: Conditioning generation to interact with a designated target object. "In addition, Mask2IV supports object-specific control by generating interaction trajectories conditioned on arbitrary target objects."
- Optical flow: A pixel-wise motion field used as a control signal in video generation. "A variety of control signals have been explored, including bounding-boxes~\cite{wang2024boximator,luo2024ctrl}, masks~\cite{dai2023animateanything,yariv2025through,interdyn}, depth maps~\cite{chen2023control,liang2024movideo}, and optical flow~\cite{shi2024motion,liang2024movideo}."
- Position-conditioned Trajectory Generation (PT-Gen): A variant that conditions trajectories on target position masks for precise placement. "PT-Gen focuses on precise spatial control of the objectâs final position."
- PSNR: A distortion-based metric evaluating reconstruction quality in images or frames. "and use Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index Measure (SSIM)~\cite{ssim}, and Learned Perceptual Image Patch Similarity (LPIPS)~\cite{lpips} to measure the frame-level visual fidelity."
- SAM2: A video segmentation model used to obtain masks for robotic manipulation data. "We thus utilize GroundingDINO~\cite{liu2024grounding} for object detection and SAM2~\cite{sam2} for video segmentation, targeting both the robot arm and the interacting object."
- Segmentation masks: Pixel-level labels identifying regions belonging to specific entities. "However, it does not provide segmentation masks."
- SSIM: A structural similarity measure for image quality assessment. "and use Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index Measure (SSIM)~\cite{ssim}, and Learned Perceptual Image Patch Similarity (LPIPS)~\cite{lpips} to measure the frame-level visual fidelity."
- Temporal attention layer: A module in video diffusion models that attends across time for coherent motion. "To preserve the motion priors, we freeze the temporal attention layer and fine-tune the remaining parameters of a pre-trained image-to-video diffusion model."
- Text-to-Video Similarity (T2V-Sim): An embedding-based metric measuring how well a generated video matches a text prompt. "We utilize the Text-to-Video Similarity (T2V-Sim) score to measure how closely the generated video matches the text prompt, computed as the cosine similarity between text and video embeddings."
- Trajectory-conditioned Video Generation: The stage that synthesizes videos guided by predicted interaction trajectories. "It consists of two stages: Interaction Trajectory Generation and Trajectory-conditioned Video Generation."
- TT-Gen: A text-conditioned trajectory generation variant that leverages language to shape motion. "TT-Gen leverages language guidance to shape the trajectory."
- VAE decoder: The decoding component of a variational autoencoder that reconstructs data from latents. "which, in conjunction with the VAE decoder , generates the interaction trajectory over time."
- VAE encoder: The encoding component of a variational autoencoder that maps inputs to latent representations. "the input frame and object mask are encoded by the VAE encoder into latent features and "
- Video-LLMs: Models pretrained to align video and text representations for retrieval or evaluation. "To measure text-video alignment, we use pretrained video-LLMs tailored to each dataset:"
- Video-to-Video Similarity (V2V-Sim): An embedding-based metric comparing generated videos with real videos. "Additionally, we compute the Video-to-Video Similarity (V2V-Sim) score, which is used to evaluate the alignment between generated and real videos in the embedding space."
- ViCLIP: A video-LLM used for evaluating text-video alignment on the robotic dataset. "To measure text-video alignment, we use pretrained video-LLMs tailored to each dataset: EgoVLP~\cite{egovlp} for the HOI4D and ViCLIP~\cite{internvid} for the BridgeData V2."
- Visuomotor policies: Control policies that map visual inputs to motor actions in robotic systems. "These methods often target downstream applications such as training visuomotor policies or generating synthetic demonstrations."
Collections
Sign up for free to add this paper to one or more collections.