- The paper demonstrates that current LLMs achieve only 52.56% pass@1 on the MCPMark benchmark, highlighting the challenge of agentic workflows.
- The paper introduces a human–AI curated pipeline with 127 tasks simulating realistic, multi-step procedures across five diverse MCP environments.
- The paper identifies significant environmental gaps and model instabilities, emphasizing the need for improved reasoning, tool use efficiency, and robust execution.
MCPMark: Stress-Testing Realistic and Comprehensive MCP Use
Introduction and Motivation
The Model Context Protocol (MCP) has emerged as a standardized interface for connecting LLMs to external systems, enabling agentic capabilities such as tool use, API interaction, and contextual resource integration. However, prior MCP benchmarks have been limited in scope, typically focusing on read-heavy or shallow tasks that do not reflect the complexity of real-world workflows. MCPMark addresses this gap by introducing a benchmark with 127 high-quality tasks, each beginning from a curated initial state and accompanied by a programmatic verification script. The benchmark is designed to stress-test LLMs in realistic, multi-step, and CRUD-diverse scenarios across five representative MCP environments: Notion, GitHub, Filesystem, PostgreSQL, and Playwright.
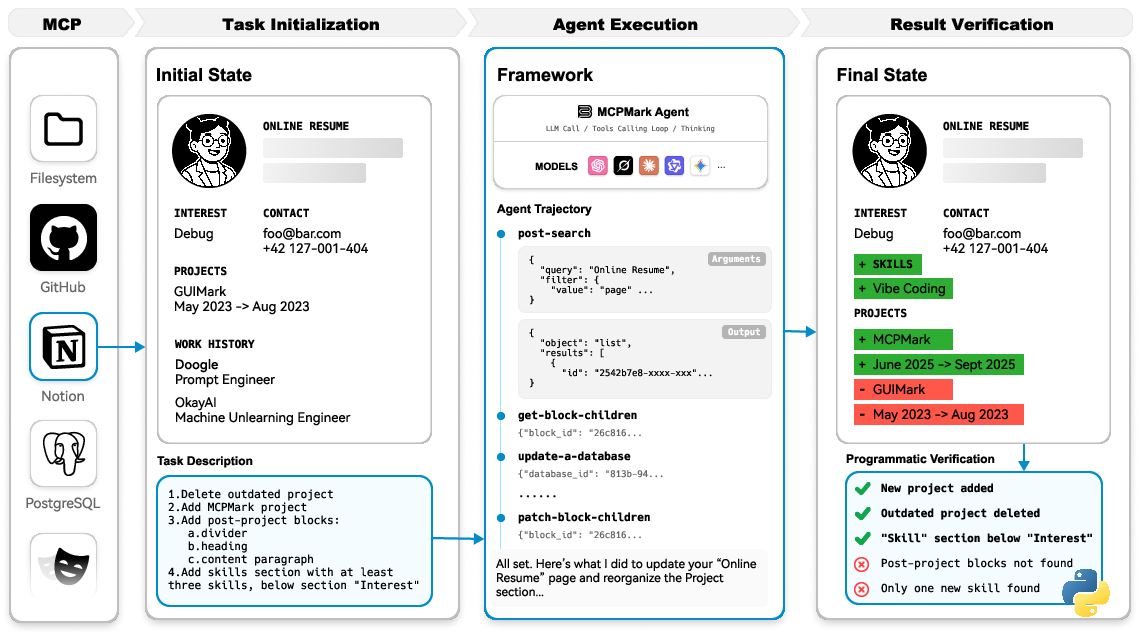
Figure 1: MCPMark evaluation pipeline with full state tracking, from initial state and instruction to agent execution and programmatic verification.
Benchmark Design and Task Construction
MCPMark's construction process involves a human–AI collaborative pipeline, pairing domain experts with agentic task creation and execution agents. Each task is grounded in a realistic initial state, such as a populated Notion template, a GitHub repository with development history, or a web application requiring authentication. The pipeline iteratively refines task instructions and verification scripts to ensure both challenge and verifiability. Tasks are validated through cross-review and community-level checks, with additional verification for unsolved tasks to ensure correctness and clarity.

Figure 2: Representative task instances illustrating initial states and instructions for complex, multi-step workflows in each MCP environment.
The benchmark covers a broad spectrum of CRUD operations and authentic workflows, including database schema design, CI/CD setup, browser automation, and document management. MCPMark's 127 tasks are distributed across 38 unique initial states, with 20–30 tasks per MCP environment.
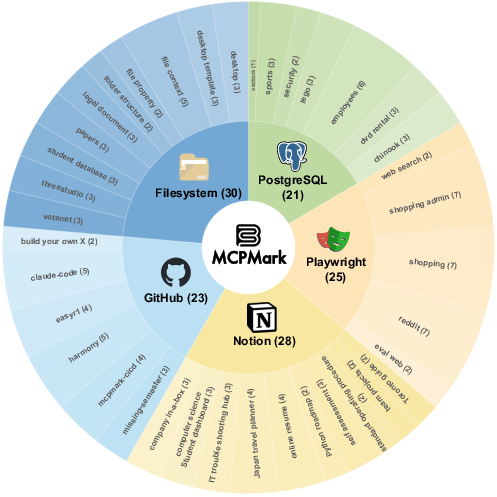

Figure 3: Task distribution and tool set overview, showing coverage across 5 MCP servers and the full CRUD toolset per environment.
Evaluation Framework and Agent Design
MCPMark employs a minimal agent framework, MCPMark-Agent, which executes models in a standardized tool-calling loop. The agent interacts with MCP servers via the Model Context Protocol Python SDK and LiteLLM, converting tools to the OpenAI function-call format and routing requests to model APIs. The evaluation pipeline enforces explicit state tracking in sandboxed environments, ensuring reproducibility and safety. Each run is limited to 100 turns and a 3600-second timeout, with automatic environment reset after verification.
Experimental Results and Analysis
Empirical results demonstrate the benchmark's difficulty. The best-performing model, gpt-5-medium, achieves only 52.56% pass@1 and 33.86% pass4, while other strong models such as claude-sonnet-4 and o3 fall below 30% pass@1 and 15% pass4. Open-source models lag further behind, with qwen3-coder-plus reaching 24.80% pass@1. On average, LLMs require 16.2 execution turns and 17.4 tool calls per task, far exceeding previous MCP benchmarks.
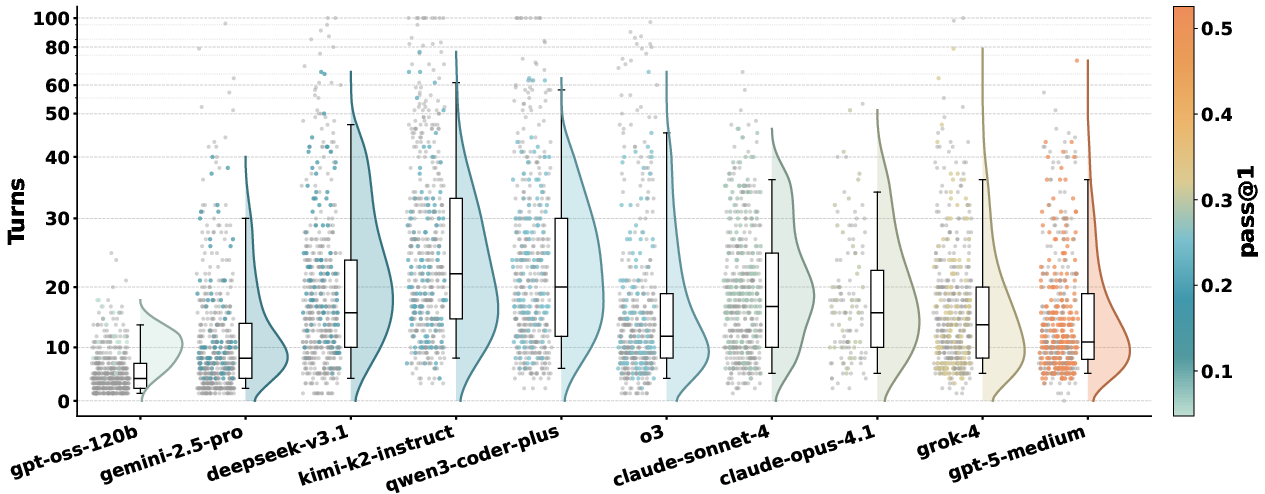
Figure 4: Turns distribution per run, with successful runs requiring fewer, more targeted tool calls.
Environment Gap
Performance varies substantially across MCP environments. Local services (PostgreSQL, Filesystem, Playwright) yield higher success rates, with gpt-5-medium reaching 76.19% pass@1 on PostgreSQL. Remote services (Notion, GitHub) remain challenging, with most models below 25% pass@1. This environment gap is attributed to differences in data availability and simulation fidelity; local services are easier to emulate and more prevalent in training data, while remote APIs require authentic traces that are costly to curate.
Robustness and Consistency
Repeated attempts (pass@4) improve success rates, but robustness remains low. For example, gpt-5-medium's pass@4 is 68.50%, but pass4 drops to 33.86%, indicating instability across runs. This inconsistency poses risks for real-world deployment, where reliability is critical.
Stronger models succeed through efficient, targeted tool use rather than exhaustive exploration. Models such as kimi-k2-instruct exhibit overcalling behavior, exceeding 30 turns with diminishing returns. Cost analysis reveals that higher cost does not correlate with higher accuracy; some expensive runs perform worse than lower-cost runs.
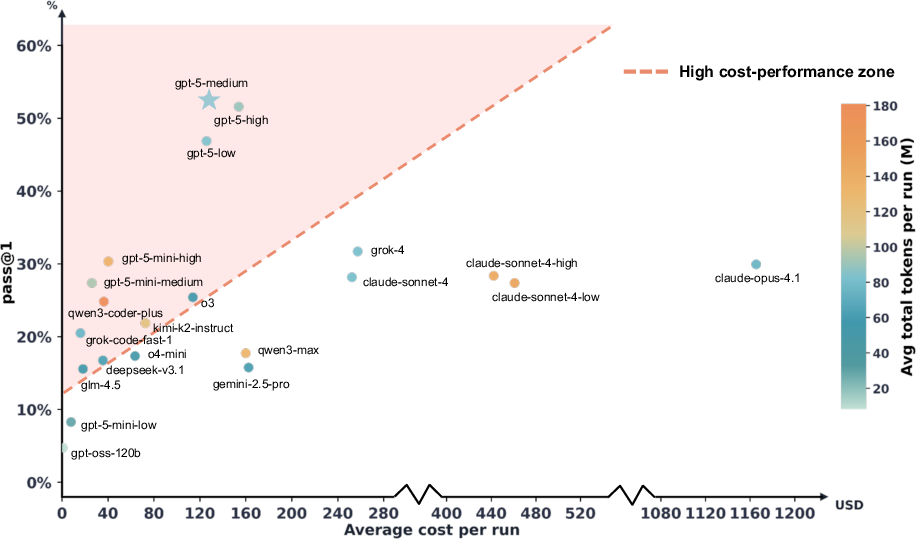
Figure 5: Cost-performance map per run, highlighting that higher cost does not guarantee better performance.
Reasoning Effort and Failure Modes
Reasoning Effort
Increasing reasoning effort (i.e., more thinking tokens before tool calls) benefits larger models, especially on remote services. For gpt-5-medium, medium effort raises pass@1 from 46.85% to 52.56%. Smaller models do not benefit, indicating that reasoning improvements require sufficient model capacity.
Failure Breakdown
Failures are categorized as implicit (task completes but fails verification) or explicit (context window overflow, turn limit exceeded, abandoned, premature stop, malformed tool calls). Implicit failures dominate, often exceeding 50% of errors, and are driven by reasoning, planning, and context management deficiencies. Explicit failures are model-specific, with gemini-2.5-flash and gpt-4.1 experiencing more abandoned or malformed tool calls.
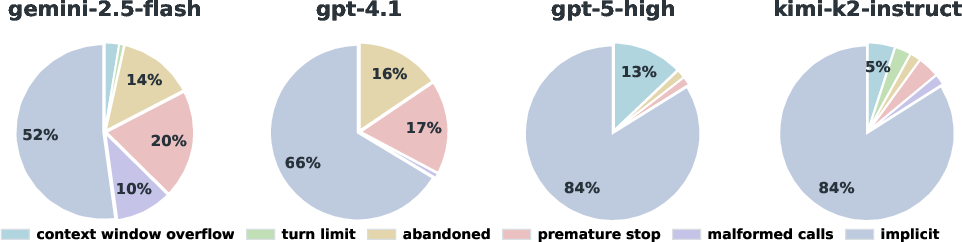
Figure 6: Failure breakdown across models, distinguishing implicit and explicit failure types.
Case Studies
Case studies across MCP environments illustrate typical success and failure modes. For example, in the Filesystem case, claude-sonnet-4 successfully extracts contacts and writes CSV files, passing verification, while gemini-2.5-pro creates files but fails on content correctness.
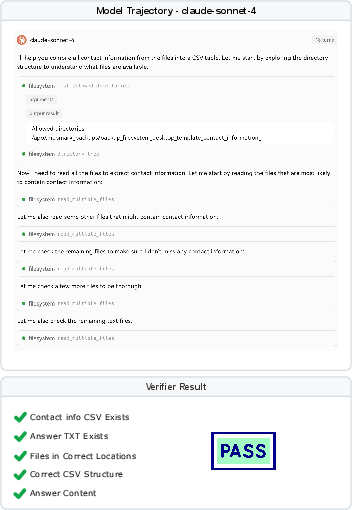
Figure 7: Successful run by claude-sonnet-4 in the Filesystem case, passing all verification checks.

Figure 8: Failed run by gemini-2.5-pro, with incorrect CSV/answer content.
Similar patterns are observed in GitHub, Notion, Playwright, and PostgreSQL cases, with successful runs characterized by complete, consistent execution and failed runs exhibiting partial progress or verification failures.
Implications and Future Directions
MCPMark exposes critical limitations in current LLM agentic capabilities, including poor robustness, inefficient tool use, and environment-specific generalization gaps. The benchmark's stress-testing nature highlights the need for advances in agent reasoning, long-context management, and execution stability. Scaling the task creation pipeline and introducing finer-grained difficulty gradients are necessary for broader applicability and training data generation. Expanding MCPMark to include ambiguous user intent and additional MCP servers would further challenge agentic systems and drive progress in general agent research.
Conclusion
MCPMark establishes a rigorous benchmark for evaluating LLMs in realistic, multi-step, and CRUD-diverse agentic workflows. The consistently low success rates, high interaction demands, and environment-specific performance gaps underscore the substantial challenges that remain for agentic AI. MCPMark provides a concrete testbed for measuring progress in reasoning, planning, and tool use, and will be instrumental in guiding future research on robust, general-purpose AI agents.

