Published 2 Oct 2025 in cs.LG, math.OC, and stat.ML | (2510.02239v1)
Abstract: Conventional wisdom in deep learning optimization dictates updating all layers at every step-a principle followed by all recent state-of-the-art optimizers such as Muon. In this work, we challenge this assumption, showing that full-network updates can be fundamentally suboptimal, both in theory and in practice. We introduce a non-Euclidean Randomized Progressive Training method-Drop-Muon-a simple yet powerful framework that updates only a subset of layers per step according to a randomized schedule, combining the efficiency of progressive training with layer-specific non-Euclidean updates for top-tier performance. We provide rigorous convergence guarantees under both layer-wise smoothness and layer-wise $(L0, L1)$-smoothness, covering deterministic and stochastic gradient settings, marking the first such results for progressive training in the stochastic and non-smooth regime. Our cost analysis further reveals that full-network updates are not optimal unless a very specific relationship between layer smoothness constants holds. Through controlled CNN experiments, we empirically demonstrate that Drop-Muon consistently outperforms full-network Muon, achieving the same accuracy up to $1.4\times$ faster in wall-clock time. Together, our results suggest a shift in how large-scale models can be efficiently trained, challenging the status quo and offering a highly efficient, theoretically grounded alternative to full-network updates.
The paper proposes a randomized progressive training method that selectively updates network layers to achieve provably faster convergence.
It introduces a flexible non-Euclidean optimization framework with rigorous iteration complexity guarantees and a detailed cost model.
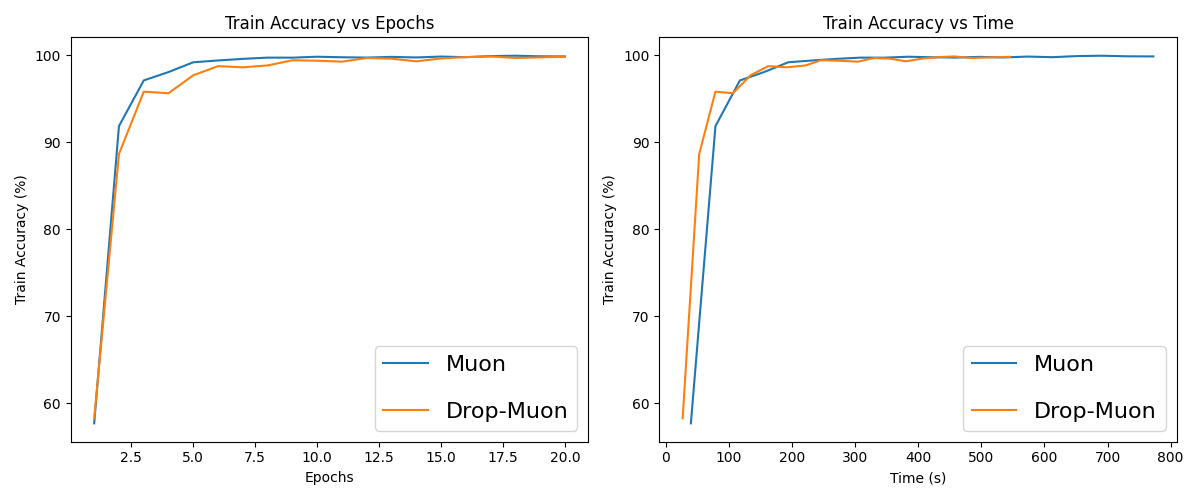
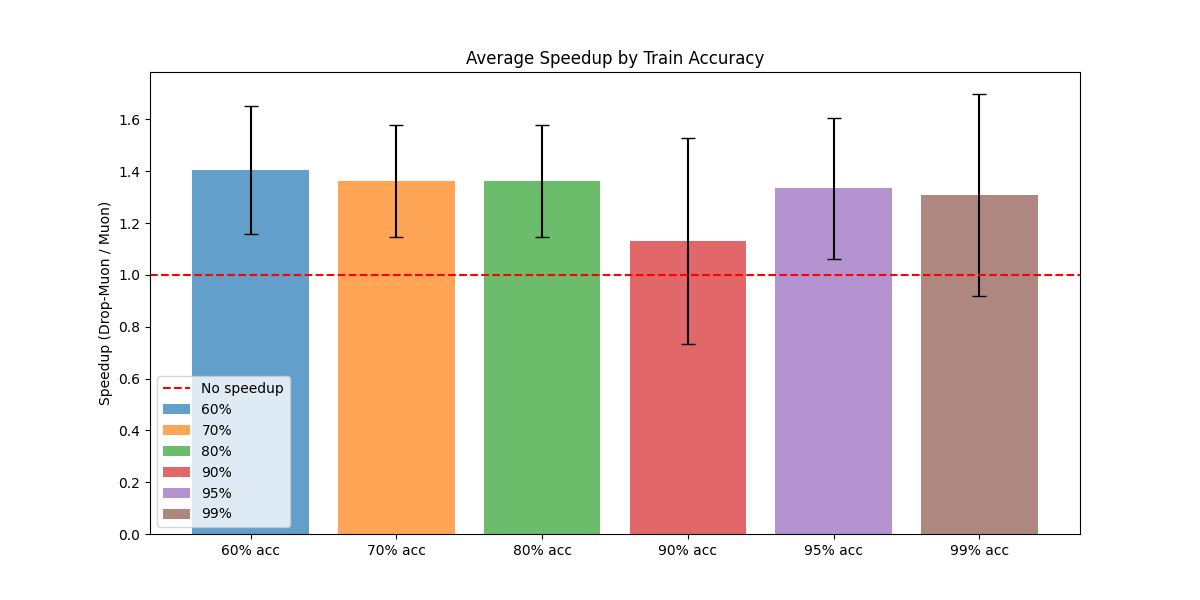
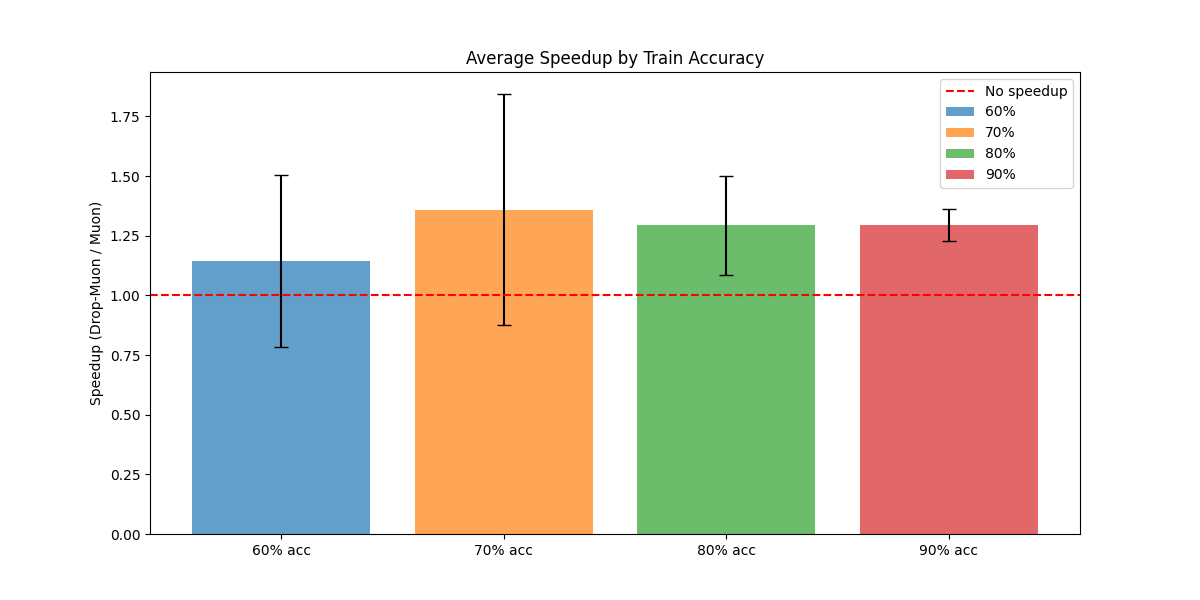
Empirical results on MNIST, Fashion-MNIST, and CIFAR-10 demonstrate up to 1.4× faster training compared to full-network update schemes.
Drop-Muon: Update Less, Converge Faster
Introduction and Motivation
The paper "Drop-Muon: Update Less, Converge Faster" (2510.02239) introduces Drop-Muon, a randomized progressive training framework for deep neural network optimization that challenges the conventional paradigm of updating all layers at every iteration. The authors provide both theoretical and empirical evidence that full-network updates are generally suboptimal, and that selective, randomized layer updates can yield superior convergence rates and computational efficiency. Drop-Muon generalizes the Muon optimizer by allowing for arbitrary layer-wise non-Euclidean updates and randomized layer subsampling, with rigorous convergence guarantees under both deterministic and stochastic regimes.
Algorithmic Framework
Drop-Muon operates by sampling a random subset of layers Sk at each iteration k according to a user-defined distribution D, and updating only those layers. The update for each active layer i∈Sk is performed via a non-Euclidean linear minimization oracle (LMO) over a norm ball, typically the spectral norm for hidden layers. The update rule is:
Xik+1=Xik−γikMi♯
where Mik is a momentum term, and Mi♯ denotes the sharp operator associated with the chosen norm. For inactive layers, parameters and momentum are simply carried forward. The sampling distribution D can be arbitrary, but the paper focuses on Randomized Progressive Training (RPT), where the minimal active layer index is sampled and all deeper layers are updated.
Theoretical Analysis
Convergence Guarantees
The authors establish tight iteration complexity bounds for Drop-Muon under two smoothness regimes:
Layer-wise L0-smoothness: Each subset of layers has its own effective smoothness constant, allowing for larger stepsizes and tighter local curvature bounds.
Layer-wise (L0,L1)-smoothness: The local curvature depends both on fixed constants and the magnitude of the layer's gradient, capturing the anisotropic geometry of deep networks.
For both deterministic and stochastic gradient settings, the paper proves O(1/K) and O(1/K) convergence rates for weighted sums of squared gradient norms and gradient norms, respectively. These results strictly generalize prior work on Muon, Scion, and Gluon, and provide the first such guarantees for progressive training in the non-smooth regime.
Cost Model and Compute-Optimality
A detailed cost model is developed, accounting for per-layer forward/backward passes, gradient transformations, and parameter updates. The expected cost to reach a target accuracy ε is shown to depend critically on the layer sampling distribution and the smoothness constants. The main theoretical result is that full-network updates are only optimal if the first layer has the largest smoothness constant—a condition rarely met in practice. Otherwise, selective layer updates are provably more efficient.
Empirical Results
Extensive experiments on MNIST, Fashion-MNIST, and CIFAR-10 with 3-layer CNNs demonstrate that Drop-Muon consistently outperforms full-network Muon in wall-clock time, achieving the same accuracy up to 1.4× faster. The advantage is robust across different layer sampling strategies, with epoch-shift distributions (which bias updates towards shallow layers early in training and deeper layers later) yielding the best results.
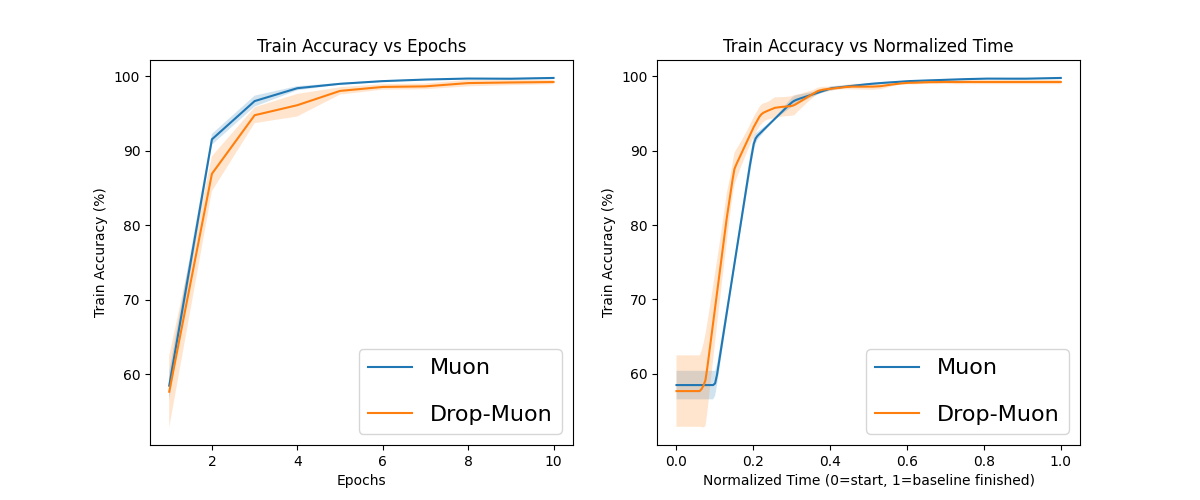
Figure 1: Evolution of the training accuracy for Muon and Drop-Muon with uniform index sampling on MNIST.
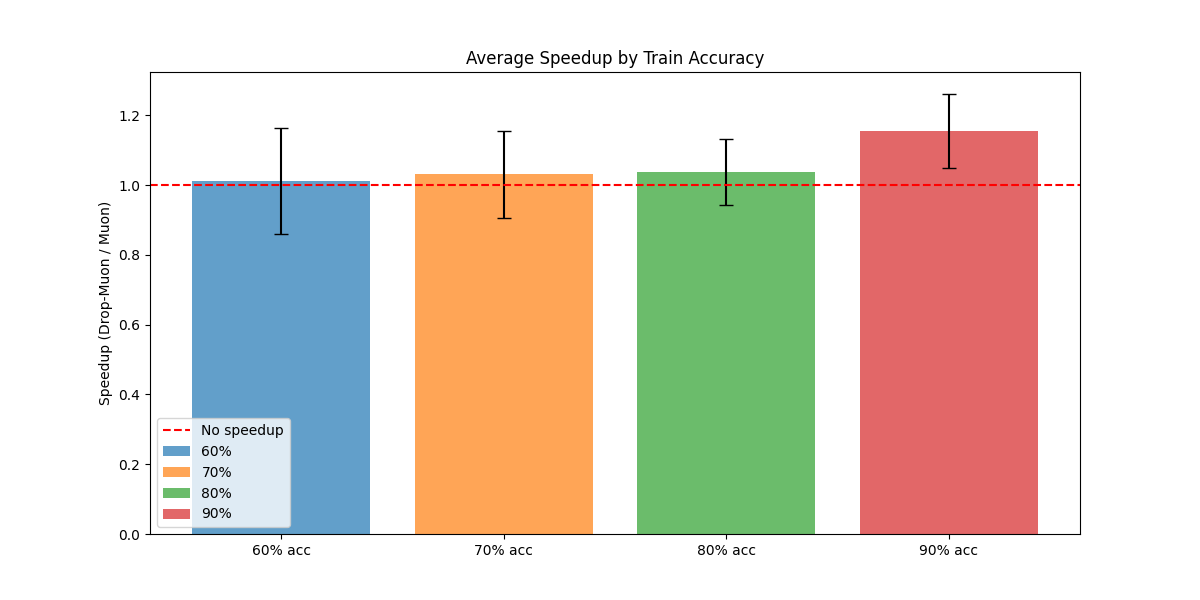
Figure 2: Averaged time-to-target speed-up over multiple runs comparing Muon and Drop-Muon with epoch-shift index sampling.
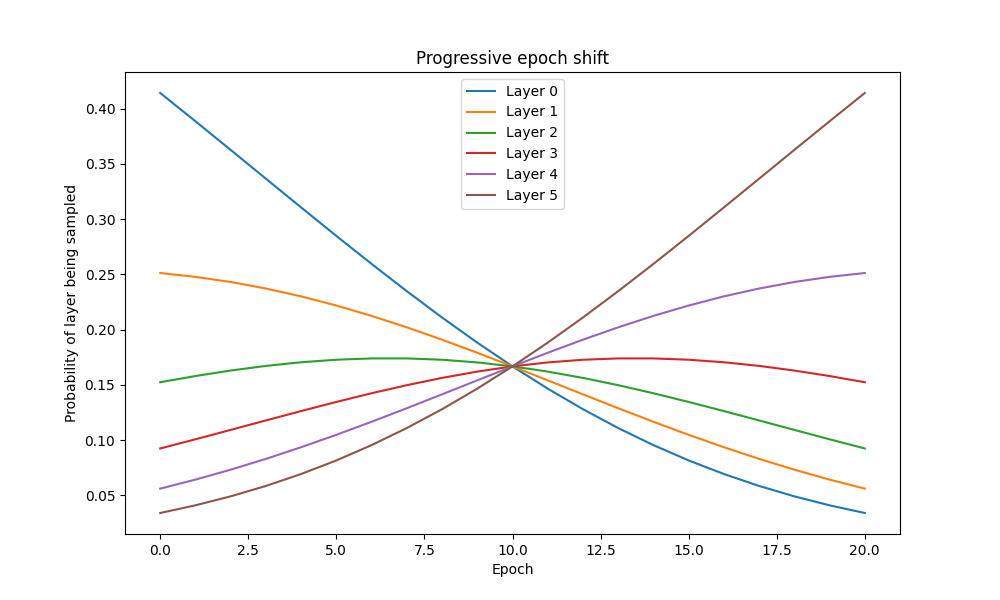
Figure 3: Evolution of the layer sampling distribution as a function of the epochs. Shallow layers are more trained in the first epochs but their probabilities of being sampled decrease with the epochs. This effect can be amplified or reduced by varying the value of α; here α=0.5.
Figure 4: Normalized curve averaging of several runs of Muon and Drop-Muon with uniform index sampling on MNIST.
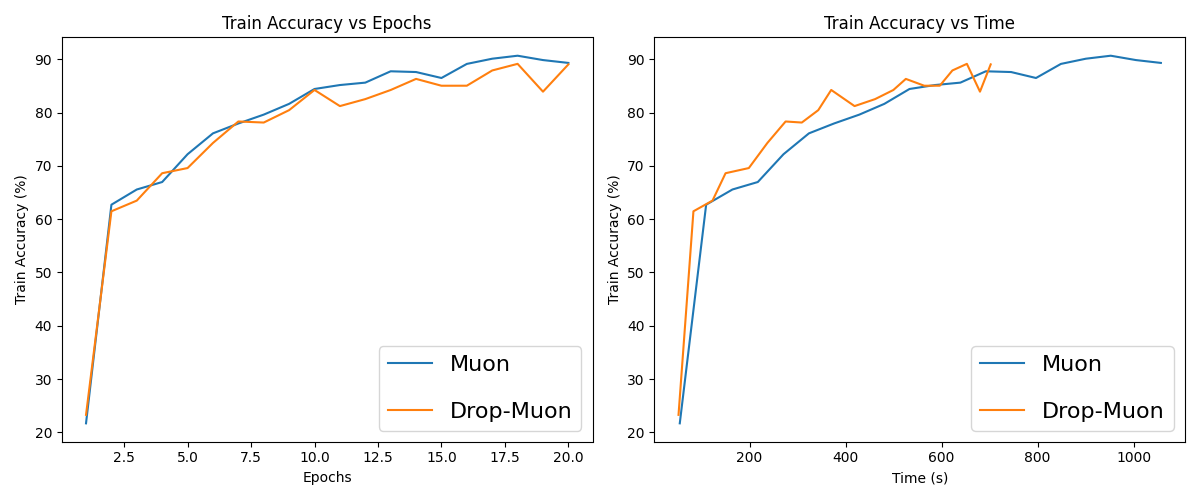
Figure 5: Evolution of the training accuracy for Muon and Drop-Muon with epoch-shift index sampling on CIFAR-10.
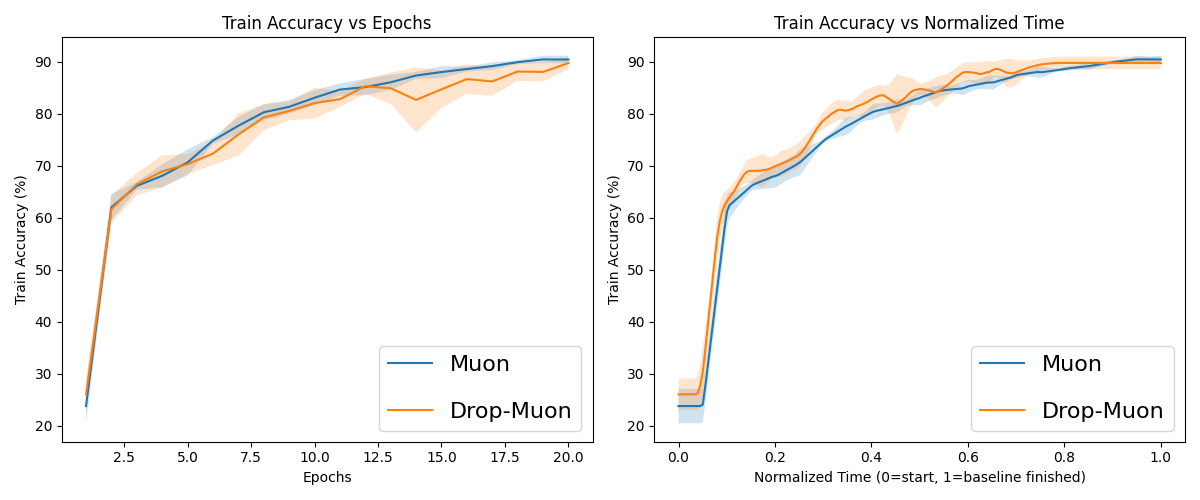
Figure 6: Normalized curve averaging of several runs of Muon and Drop-Muon with epoch-shift index sampling on Fashion-MNIST.
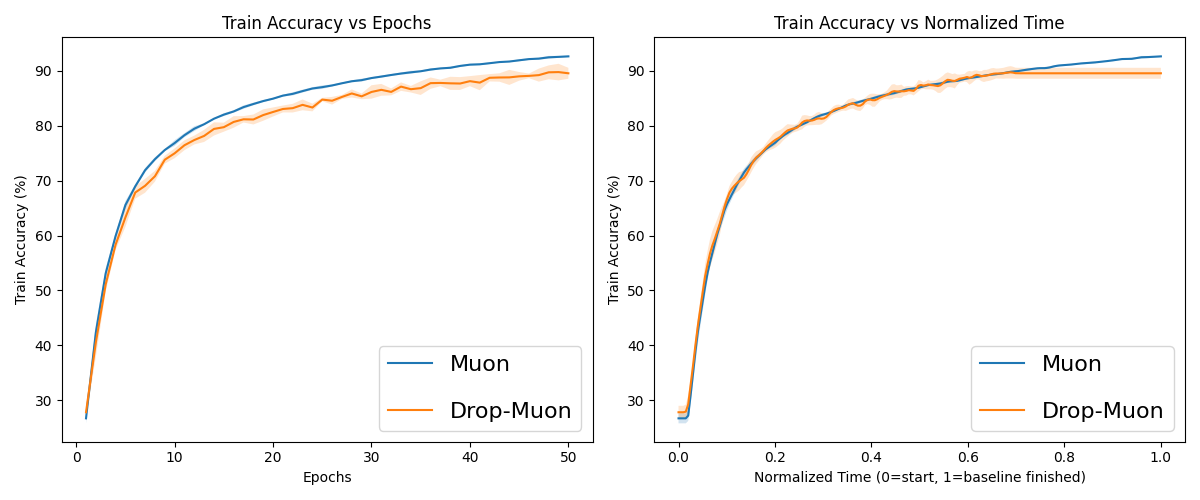
Figure 7: Normalized curve averaging of several runs of Muon and Drop-Muon with epoch-shift index sampling on CIFAR-10.
Figure 8: Averaged time-to-target speed-up over multiple runs comparing Muon and Drop-Muon with epoch-shift index sampling on CIFAR-10.
defdrop_muon_step(X, M, grad_fn, sample_layers, step_sizes, momentum_params):
S = sample_layers() # Sample active layersfor i inrange(len(X)):
if i notin S:
M[i] = M[i] # Freeze momentum
X[i] = X[i] # Freeze parameterselse:
M[i] = (1 - momentum_params[i]) * M[i] + momentum_params[i] * grad_fn(X, i)
X[i] = X[i] - step_sizes[i] * sharp_operator(M[i])
return X, M
sample_layers() implements the chosen layer sampling distribution (e.g., uniform, epoch-shift).
sharp_operator() computes the normalized steepest descent direction in the chosen norm (e.g., spectral norm via Newton-Schulz).
The cost model can be integrated to dynamically adjust sampling probabilities for compute-optimality.
Scaling and Resource Considerations
Drop-Muon is highly parallelizable and compatible with large-batch training.
The per-iteration cost is reduced due to truncated backpropagation and selective updates.
For large models, caching activations and sampling the cutoff layer less frequently can further reduce overhead.
Hyperparameter Tuning
Larger stepsizes can be safely used for layers with smaller smoothness constants, as per the theoretical analysis.
The sampling distribution can be dynamically adapted based on observed layer-wise gradients or smoothness estimates.
Practical and Theoretical Implications
Drop-Muon provides a principled framework for sub-network optimization, strictly generalizing LMO-based methods and coordinate descent. The results challenge the entrenched practice of full-network updates, suggesting that randomized, selective layer updates should be the default for large-scale deep learning. The approach is particularly well-suited for architectures with heterogeneous layer-wise smoothness, such as transformers and deep CNNs.
Theoretically, the work advances the understanding of non-Euclidean optimization in deep learning, providing new convergence guarantees under relaxed smoothness assumptions. Practically, Drop-Muon is simple to implement, requires minimal changes to existing pipelines, and yields substantial speedups in training time.
Future Directions
Adaptive Sampling:Online learning of the layer sampling distribution to further optimize convergence and resource usage.
Integration with Distributed Training: Combining Drop-Muon with communication-efficient distributed optimization schemes.
Extension to Other Architectures: Application to transformers, LLMs, and other architectures with pronounced layer-wise heterogeneity.
Automated Smoothness Estimation: Leveraging empirical layer-wise curvature estimates to guide sampling and stepsize selection.
Conclusion
Drop-Muon introduces a theoretically grounded and empirically validated alternative to full-network updates in deep learning optimization. By leveraging randomized progressive training and non-Euclidean layer-wise updates, it achieves faster convergence and reduced computational cost. The framework generalizes existing LMO-based optimizers and provides new insights into the geometry and efficiency of deep network training. The results have significant implications for both the theory and practice of large-scale neural network optimization, and open avenues for further research in adaptive and distributed training strategies.