- The paper's main contribution is CodeLLMLingua, a dual-stage framework that retains crucial code segments using coarse- and fine-grained compression strategies.
- It employs function-level ranking and a knapsack algorithm to select semantic blocks, achieving up to a 5.6× reduction in input size.
- The approach significantly reduces latency and computational costs while maintaining high performance in code completion, summarization, and question answering tasks.
LongCodeZip: Compress Long Context for Code LLMs
Introduction
The increasing complexity of software development has led to multiplied demands on LLMs for effective code completion, program synthesis, and question answering. LLMs designed to handle code must operate under the constraint of adequately managing long-context inputs while facing challenges such as increased latency and API costs. Traditional context pruning techniques fall short in programming tasks because they do not consider the unique structural dependencies inherent in code.
Methodology Overview
The paper introduces CodeLLMLingua, a novel framework for compressing code contexts that can be seamlessly integrated with existing LLMs. The methodology comprises a dual-stage strategy: coarse-grained compression and fine-grained compression.
- Coarse-Grained Compression: This phase identifies function-level code chunks within the long context and ranks them using conditional perplexity relative to the task instruction. Only the most relevant functions are retained, preserving essential code elements that are likely important for downstream tasks.
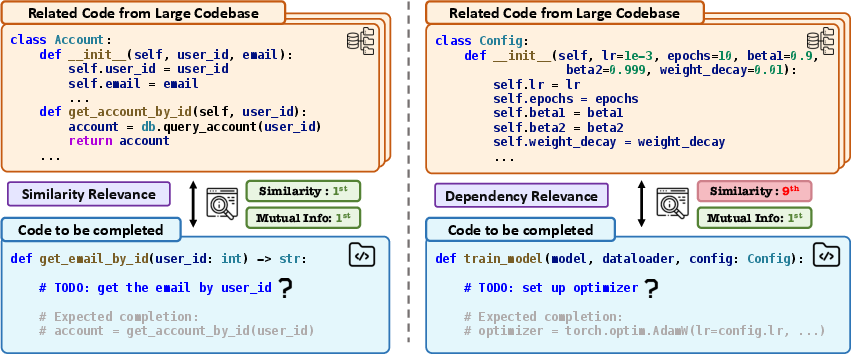
Figure 1: Challenge for RAG, a similarity-based context compression method.
- Fine-Grained Compression: Once the relevant functions are selected, they are further decomposed into semantic blocks based on perplexity scores. The framework then selects an optimal subset of these blocks using a knapsack algorithm to maximize informativeness within a given token budget.
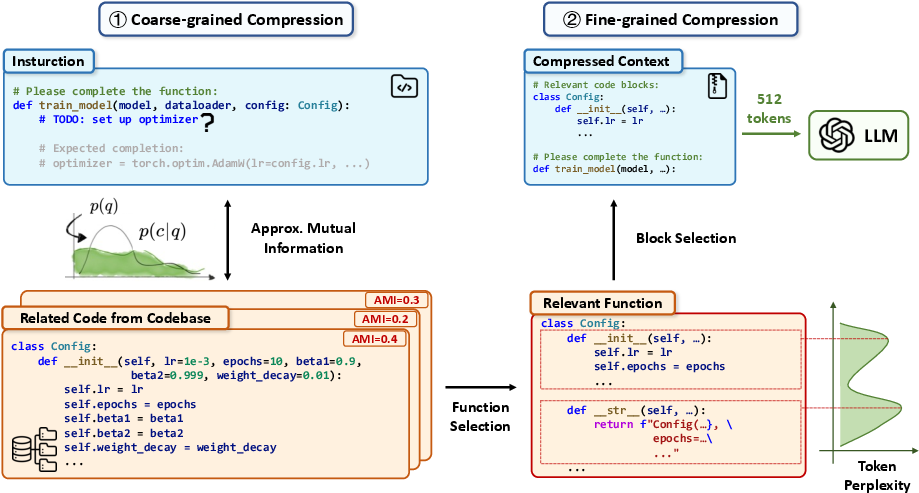
Figure 2: Overview of the CodeLLMLingua framework.
This two-phase compression strategy helps maintain task performance while achieving significant context compression, as indicated by robust empirical results.
Results and Evaluation
Evaluations conducted on tasks such as long-context code completion, module summarization, and code question answering demonstrate CodeLLMLingua's efficacy. The framework succeeds in achieving up to a 5.6× compression ratio without degrading performance outcomes. These achievements are made possible by effectively preserving semantically crucial information while reducing the overall context size for the model.
CodeLLMLingua exhibits significant improvements over baseline methods, showing a notable reduction in input size and fewer computational resources. The framework's deployment results in decreased latency and reduced cost, which are critical metrics for scalability in real-world applications.
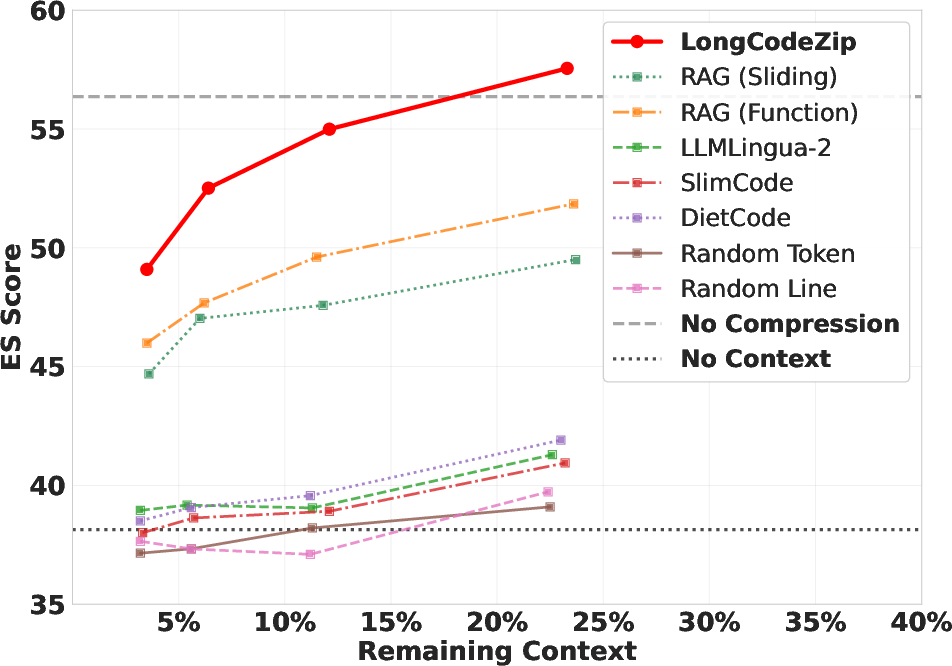
Figure 3: Performance (ES) vs remaining context (\%).
Trade-Offs and Practical Considerations
While CodeLLMLingua significantly compresses long contexts into more manageable sizes, there are some implementation considerations:
- Computational Overhead: The compression process introduces slight computational overhead. However, the trade-offs in reduced input size pay dividends in saving more considerable computational resources during model inference.
- Adaptability: The framework's dual-stage process is model-agnostic, making it adaptable across various LLM implementations without necessitating retraining.
- Complexity: Specific use-cases might demand configurations for compression ratios, which could require additional tuning across different tasks and datasets.
Conclusion
CodeLLMLingua sets a new precedent in code context compression by addressing and overcoming the inadequacies observed with prior approaches, particularly around code-specific intricacies ignored by general-purpose compression methods. By substantially reducing the context length while maintaining output accuracy and efficiency, CodeLLMLingua enhances the scalability of LLMs in processing real-world, large-scale software codebases. Future developments could extend its application to other domains requiring efficient context management in large-scale models.