- The paper introduces AbsTopK, a sparse autoencoder that leverages proximal gradient methods to remove non-negativity constraints and encode bidirectional features.
- The method applies an ℓ0 norm-based thresholding to preserve both positive and negative activations, achieving improved error metrics and model fidelity.
- Empirical results on models like Qwen3-4B underscore AbsTopK's superiority in handling steering tasks and enhancing semantic interpretability.
AbsTopK: Rethinking Sparse Autoencoders For Bidirectional Features
Introduction
The paper introduces a novel framework for designing Sparse Autoencoders (SAEs) by leveraging the proximal gradient method for sparse coding. Traditional SAEs like ReLU, JumpReLU, and TopK have exhibited limitations in capturing bidirectional semantic concepts due to non-negativity constraints. The proposed AbsTopK seeks to overcome these limitations by applying hard thresholding on the largest-magnitude activations, preserving both positive and negative activations. This abstraction allows richer conceptual representations and aligns more effectively with the inherent bidirectionality of many latent semantic concepts in LLMs.
Methodology
The authors propose a unified framework exploiting proximal operators to derive SAEs from the dictionary learning problem. This approach establishes a formal connection between sparsity-inducing regularizers and activation functions commonly used in SAEs.
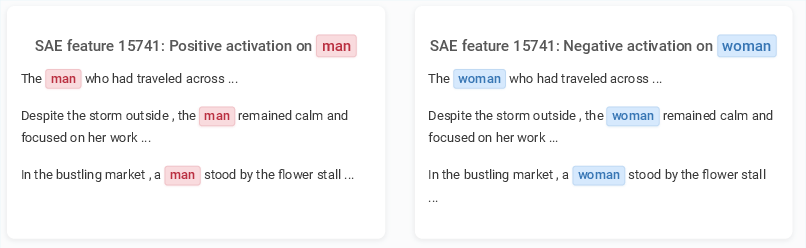
Figure 1: AbsTopK enables single latent features to encode opposing concepts by leveraging both positive and negative activations.
Proximal Gradient Method
The proximal gradient method is applied to the sparse coding problem, yielding the proximal operator: z(1)=proxλR(W⊤x+be)
where R is a sparsity-inducing regularizer. This step leads to a single-layer neural network instantiation, characteristic of SAEs. The newly proposed AbsTopK removes the non-negativity constraint inherent in other SAEs by leveraging an ℓ0 norm-based thresholding method, simplifying the integration of bidirectional semantic features.
Experiments
The empirical validation involved comprehensive testing across four LLMs, including Qwen3 4B and Gemma2-2B, using AbsTopK, TopK, and JumpReLU variants. Metrics such as MSE training loss, normalized reconstruction error, and cross-entropy loss recovery were employed to evaluate the approaches.
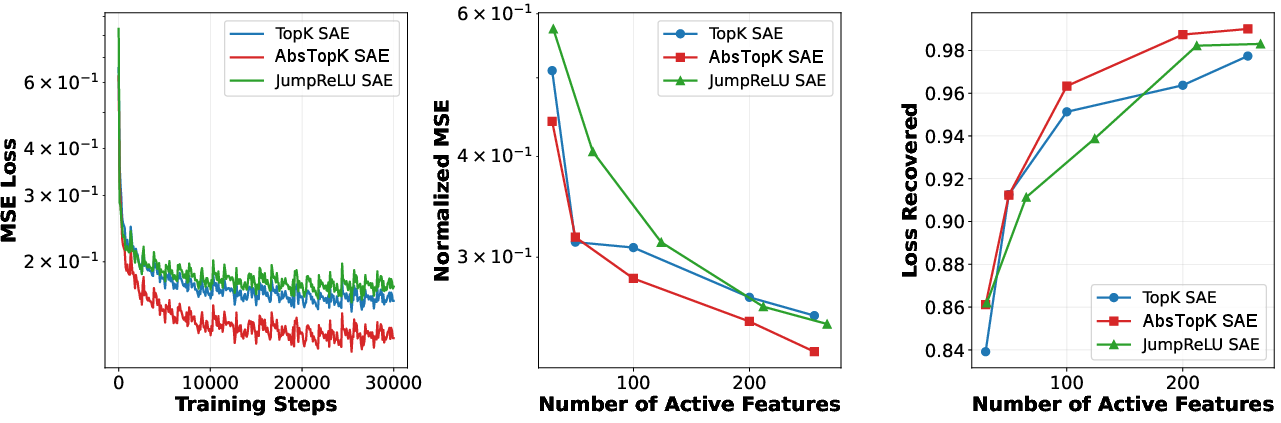
Figure 2: Performance comparison of JumpReLU, TopK, and AbsTopK SAEs on Qwen3 4B Layer 20, illustrating significant error reduction and model fidelity preservation.
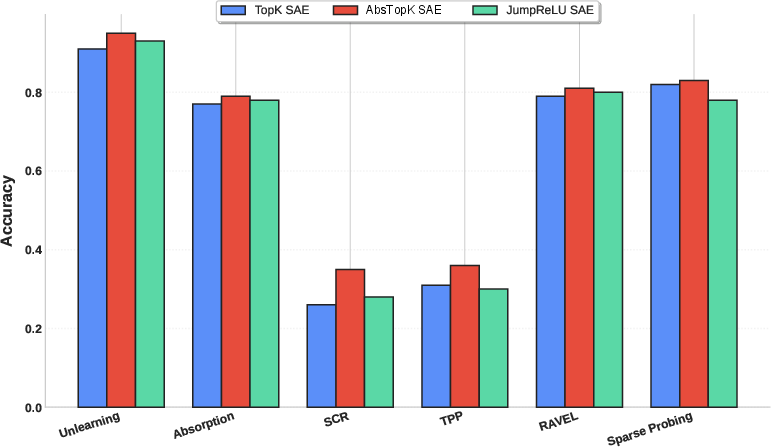
Figure 3: Performance comparison of SAE variants across tasks on Qwen3-4B Layer 18, indicating overall superior task performance by AbsTopK.
AbsTopK consistently outperformed other variants, showcasing enhanced representational capacity and interpretability by allowing a single feature to compactly encode contrasting semantic directions (e.g., male vs. female).
Results on Steering and Probing Tasks
AbsTopK was assessed on steering tasks, demonstrating its adeptness in controlled intervention within LLMs without severely compromising broader model competencies. This contrasts with simpler methods like Difference-in-Means (DiM), which typically necessitate labeled datasets and fail to capture multidimensional and bidirectional features inherent in LLMs efficiently.
Implications and Future Work
The introduction of AbsTopK advances the field of interpretable LLMs by enabling more coherent feature representations that align with the natural bidirectionality of semantic concepts. Future research could explore multi-step proximal updates to capture finer-grained semantic structures and optimize the computational efficiency of such enrichments in large-scale models.
Conclusion
AbsTopK addresses fundamental limitations in existing SAEs by eliminating the non-negativity constraint, thereby facilitating the identification and manipulation of bidirectional features within LLMs. Its efficacy across multiple models demonstrates its potential to augment the interpretability and control of contemporary AI systems, encouraging developments towards more nuanced and broader spectrum feature encodings. The research provides a groundwork for further exploration into efficient proximal algorithms and their applicability to various domains beyond natural language processing.

