- The paper introduces BC-MPPI, which integrates Bayesian neural network surrogates into MPPI to probabilistically handle constraints and ensure trajectory feasibility.
- It demonstrates improved safety by maintaining greater distances from obstacles and achieving closer target proximities than traditional MPPI methods in simulation experiments.
- The approach eliminates the need for hand-tuned penalty costs by adjusting the MPPI sampling distribution based on surrogate-provided uncertainty measures.
BC-MPPI: A Probabilistic Constraint Layer for Safe Model-Predictive Path-Integral Control
Introduction
The paper addresses the limitations of traditional Model Predictive Control (MPC) in highly non-linear robotic tasks and proposes Bayesian-Constraints MPPI (BC-MPPI) as an enhancement to Model Predictive Path Integral (MPPI) control. While MPC provides explicit constraints, it struggles with defining well-conditioned analytic functions for complex tasks. MPPI offers a fast, gradient-free alternative but lacks guarantees for constraint satisfaction. BC-MPPI introduces a probabilistic constraint handling mechanism into MPPI using Bayesian neural networks to ensure trajectory feasibility.
Bayesian Constraints MPPI
BC-MPPI integrates a Bayesian surrogate for each constraint, providing a mean estimate and epistemic uncertainty. At each control step, the surrogate adjusts the MPPI sampling distribution. Rollouts with higher violation probabilities are suppressed, while safe trajectories are prioritized. This approach eschews the need for hand-tuned penalty costs and sample rejection, which are typical shortcomings in MPPI.
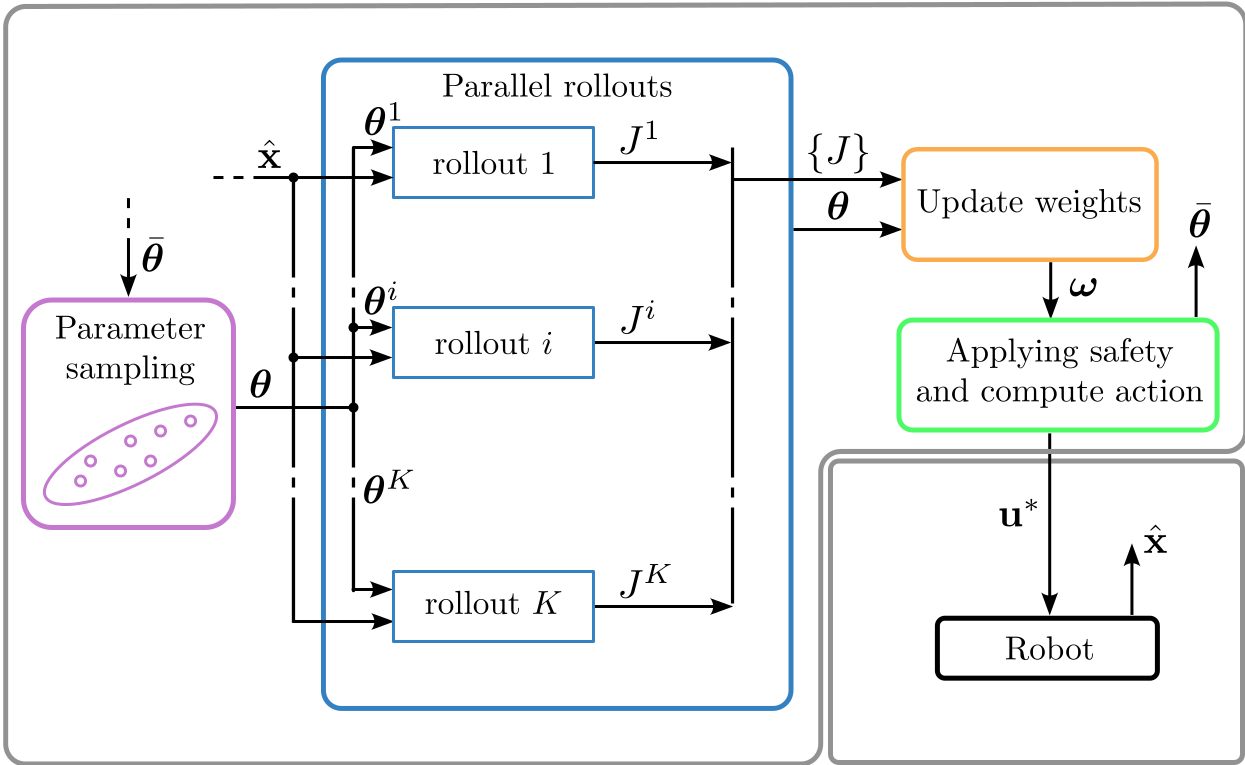
Figure 1: BC\hbox{-}MPPI workflow. A Gaussian sampler perturbs the nominal parameter vector θˉ and launches K parallel roll-outs; their costs feed the MPPI weight update, which is then scaled by the joint feasibility probability.
Simulation Experiments
Experiments conducted in the MuJoCo simulator evaluated BC-MPPI in scenarios with static and dynamic obstacles, using a quadrotor model. Compared against classic MPPI and an MPPI-penalty baseline, BC-MPPI consistently achieved superior safety margins without compromising trajectory optimality.



Figure 2: Snapshot sequence from a complex scenario involving five moving obstacles. Spheres model obstacles with inflated radii.
The experiments revealed the following metrics:
- Trajectory Quality: BC-MPPI maintained greater average distances from obstacles and consistently achieved closer proximity to the target than competitors.
- Performance Metrics: While BC-MPPI had longer simulation runtimes due to surrogate computation, the trade-off resulted in higher constraint satisfaction and fewer collisions.
- Rejection Rate: BC-MPPI demonstrated efficiency by reducing the need for sample rejections compared to the baseline.
Implications and Future Work
BC-MPPI illustrates a probabilistic approach to constraint satisfaction, integrating seamlessly with validation pipelines for autonomous systems. The method leverages surrogate models trained offline, allowing for enhanced safety in real-time applications.
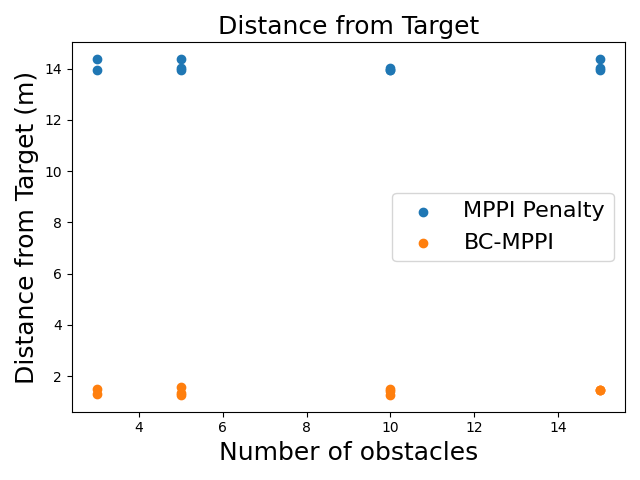
Figure 3: Distance of quadrotor from the target.
Future challenges include improving surrogate accuracy, adapting to more complex environments, and optimizing runtime for deployment on embedded systems. Exploration in scaling and online surrogate updates could further enhance applicability in diverse robotic contexts.
Conclusion
BC-MPPI successfully marries the computational agility of MPPI with a robust safety mechanism, addressing key limitations in existing literature regarding constraint satisfaction in stochastic control methods. The probabilistic nature of the approach offers a substantial advance towards certifiable autonomous systems in dynamic and unpredictable environments.
