- The paper introduces a decoupled architecture that separates multimodal reasoning from visual synthesis, enabling efficient and high-fidelity image generation and editing.
- It employs a progressive three-stage training strategy integrating a fine-tuned MLLM, connector, and scalable diffusion transformer to optimize performance across multiple tasks.
- Experimental results demonstrate competitive benchmarks with superior photorealism, faster convergence, and efficient resource usage compared to existing UMM paradigms.
Query-Kontext: Decoupling Multimodal Reasoning and Visual Synthesis for Unified Image Generation and Editing
Motivation and Context
The proliferation of Unified Multimodal Models (UMMs) has led to significant advances in text-to-image (T2I) generation and instruction-based image editing (TI2I). However, existing paradigms—assembled frameworks coupling frozen VLMs/LLMs with diffusion generators, and native UMMs with early-fusion transformers—entangle multimodal reasoning and high-fidelity synthesis, resulting in suboptimal exploitation of VLM semantic understanding and diffusion model photorealism. Query-Kontext introduces a decoupled architecture that delegates generative reasoning to a VLM and reserves the diffusion model for visual synthesis, aiming to maximize the strengths of both components.

Figure 1: Showcase of Query-Kontext model on multimodal reference-to-image tasks.
Model Architecture
Query-Kontext comprises four principal modules: a Multimodal LLM (MLLM, Qwen2.5-VL), a connector, a Multimodal Diffusion Transformer (MMDiT), and a low-level image encoder (VAE). The MLLM encodes multimodal inputs—text, images, and learnable query tokens—producing fixed-length kontext tokens Q={q1,...,qK} that encapsulate semantic and coarse image-level conditioning. These tokens, concatenated with text embeddings via the connector, condition the diffusion model, which is initialized with a scalable in-house MMDiT backbone.
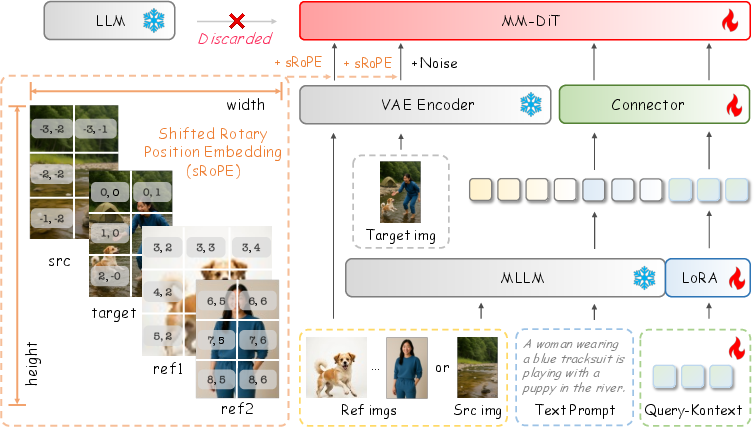
Figure 2: The overall framework of the unified multi-modal to image generation and editing model, Query-Kontext.
A shifted 2D Rotary Position Embedding (RoPE) mechanism is introduced to disambiguate positional encoding for multiple reference images, supporting both pixel-level fidelity (source images) and identity preservation (reference images). This is achieved by shifting latent coordinates into distinct quadrants depending on image type, enabling the model to generalize across editing and composition tasks.
Progressive Training Strategy
Query-Kontext employs a three-stage individualized-teaching curriculum:
- Stage 1: The MLLM is fine-tuned (LoRA) to output kontext tokens aligned with a lightweight diffusion head, optimizing for T2I, image reconstruction, and transformation tasks. This stage cultivates multimodal generative reasoning in the VLM.
- Stage 2: The lightweight head is replaced with a large-scale diffusion model (10× parameters). The MLLM is frozen, and the connector and diffusion model are fine-tuned for alignment, focusing on T2I and reconstruction objectives.
- Stage 3: A dedicated low-level image encoder is introduced for high-fidelity image referring. Only the connector and kontext tokens are optimized, with LoRA applied to the diffusion model for task generalization.
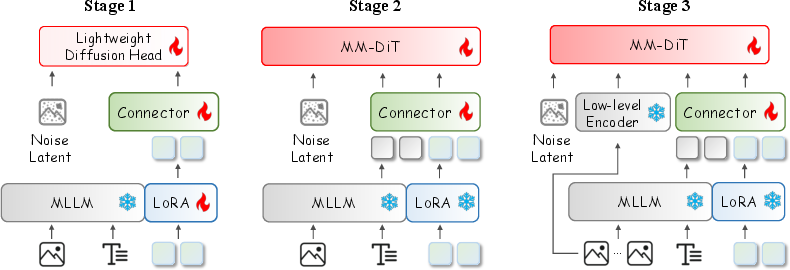
Figure 3: Three training stages of Query-Kontext.
This staged approach enables efficient alignment and scaling, with resource requirements approximately 10% of end-to-end UMM training.
Data Curation and Task Coverage
A comprehensive multimodal reference-to-image dataset is constructed, integrating real, synthetic, and open-source sources. The dataset spans five task categories: T2I generation, image transformation, instruction editing, customized generation, and multi-subject composition. Synthetic pipelines leverage segmentation, mask augmentation, and LLM-driven instruction generation to produce high-quality triplets for editing and composition.

Figure 4: Examples of the image transformation task. Each row shows a transformation instruction, the source image and the resulting target image, in order from left to right.
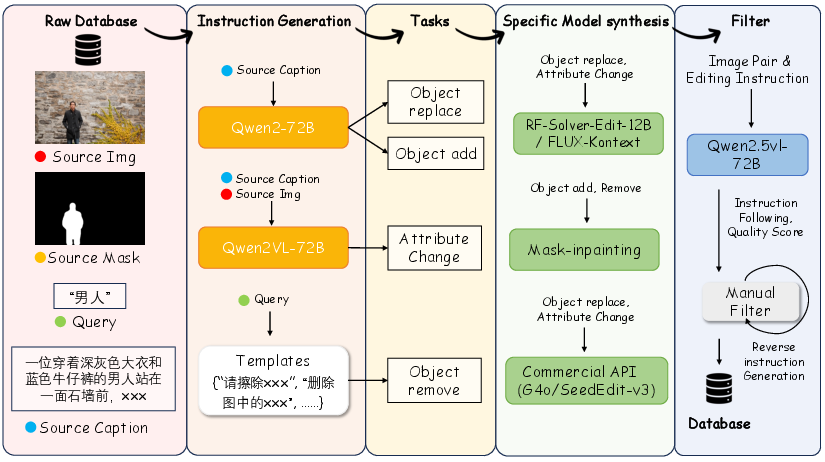
Figure 5: Examples of synthetic data pipeline for instruction Editing.

Figure 6: Examples of image inpainting with mask augmentation.

Figure 7: Examples of instruction editing data pair constructed from real video.
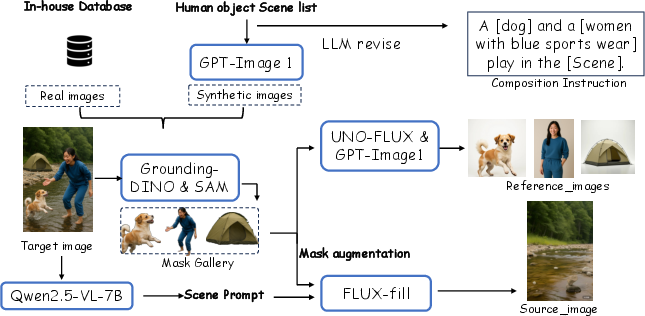
Figure 8: Examples of synthetic data pipeline for Multi-Subject Composition.
Experimental Results
Query-Kontext achieves competitive or superior results across multiple benchmarks:
- GenEval: Overall score of 0.88, matching SOTA unified UMMs (BAGEL).
- GEdit-Bench: Highest overall scores for instruction-guided editing (7.66 EN, 7.65 CN), outperforming Qwen-Image and GPT-Image.
- DreamBooth (Single-Subject): DINO 0.786, CLIP-I 0.858, CLIP-T 0.307, surpassing Metaquery and UNO-FLUX.
- DreamBench (Multi-Subject): CLIP-T 0.336, DINO 0.532, CLIP-I 0.731, leading among generalist models.
The shifted RoPE mechanism demonstrates clear task-dependent behavior: source images yield higher pixel-level fidelity, while reference images support identity-preserving generalization.
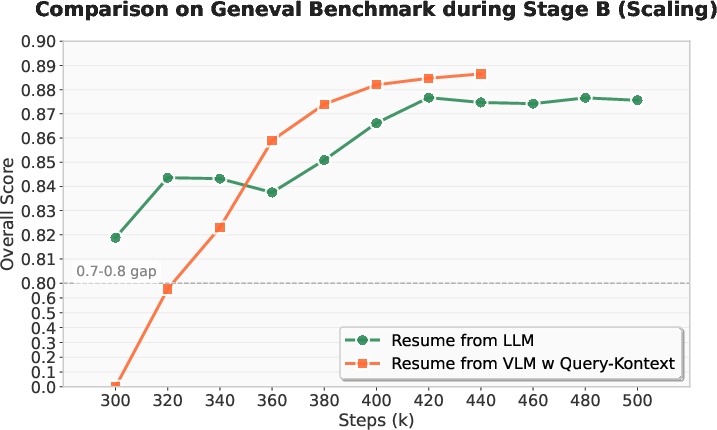
Figure 9: Convergence validation of Query-Kontext. Comparison on our in-house MMDiT between VLM re-alignment with Query-Kontext and LLM-based resumption.
Convergence analysis reveals that VLM-based conditioning via kontext tokens accelerates diffusion model alignment and improves visual quality compared to LLM-only baselines. LoRA rank ablations indicate diminishing returns beyond r=128.
Implementation and Scaling Considerations
The architecture is initialized with Qwen2.5-VL-7B, a two-layer MLP connector, and a scalable MMDiT backbone (up to 10B parameters). Training leverages tensor parallelism, ZeRO Stage-2 sharding, and BF16 mixed precision. Data bucketing by aspect ratio and reference count optimizes throughput. Resolution upscaling is performed post Stage 3, with batch sizes up to 1024 and learning rates down to 1×10−5.
The decoupled design allows independent scaling of VLM and diffusion components, mitigating capacity competition and facilitating targeted resource allocation. Alignment with large frozen diffusion models is nontrivial; unfrozen fine-tuning is required for successful connector adaptation.
Implications and Future Directions
Query-Kontext demonstrates that decoupling multimodal reasoning from visual synthesis enables efficient, scalable, and generalizable UMMs. The kontext token mechanism unleashes in-context learning and structured reasoning in VLMs, while the diffusion model specializes in photorealistic rendering. The architecture supports diverse tasks—editing, composition, customization—without sacrificing fidelity or semantic control.
Theoretical implications include the potential for further scaling laws exploration, connector optimization, and curriculum learning strategies. Practically, the framework is well-suited for deployment in resource-constrained environments and for rapid adaptation to new multimodal tasks.
Future work may address reinforcement learning or supervised fine-tuning for enhanced perceptual quality, connector scaling for larger diffusion backbones, and extension to video or 3D generative tasks.
Conclusion
Query-Kontext presents an economical, unified multimodal-to-image framework that decouples generative reasoning and visual synthesis, achieving competitive performance across generation and editing tasks. The progressive training strategy, kontext token mechanism, and comprehensive data curation collectively enable efficient scaling, generalization, and high-fidelity output. The approach sets a precedent for modular UMM design and opens avenues for further research in multimodal generative modeling.