- The paper introduces a novel Action-Guided Diffusion Policy (DP-AG) that couples perception and action through a unified representation for adaptive decision-making.
- It employs a stochastic differential equation approach with a Vector–Jacobian Product, achieving improved convergence, smoothness, and success rates.
- Empirical evaluations in simulations and real-world robotic tasks demonstrate the model’s robustness and potential for real-time adaptability.
Act to See, See to Act: Diffusion-Driven Perception-Action Interplay for Adaptive Policies
This essay discusses the paper "Act to See, See to Act: Diffusion-Driven Perception-Action Interplay for Adaptive Policies," which introduces a novel approach to imitation learning by integrating dynamic perception-action interplay. The core innovation is the Action-Guided Diffusion Policy (DP-AG), which models a bidirectional flow between perception and action, diverging from traditional methods that decouple these processes.
Dynamic Perception-Action Interplay
DP-AG employs a unified representation learning framework that explicitly models the interaction between perception and action. By adopting a stochastic differential equation (SDE) approach, where the action-guided Vector–Jacobian Product (VJP) of the diffusion policy's noise predictions drives latent updates, the model enhances the adaptability of policies in dynamic environments. This setup ensures that observation features, encoded into latent spaces, are continuously refined as actions unfold. The cycle-consistent contrastive loss further solidifies this dynamic loop, enforcing coherence in perception-action transitions.
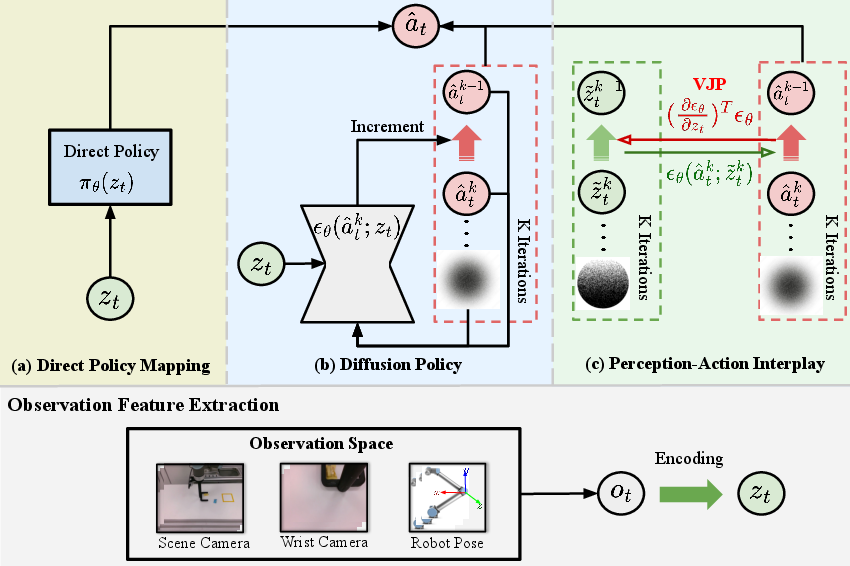
Figure 1: Use of Observation Features depicts the establishment of a mutually reinforcing cycle between perception and action through noise predictions.
Implementation Strategy
DP-AG builds on the principles of variational inference, encoding observation features into a Gaussian posterior that captures inherent uncertainties. These features subsequently evolve under the influence of the action-conditioned SDE, driven by the VJP of diffusion noise predictions.
The implementation extends the traditional diffusion model by integrating variational components, where the latent evolution under action influence is calculated as:
dz~tk=VJP(a^tk,zt)dt+σϕ(zt)dWt,
ensuring dynamic updates in alignment with action transitions.
Empirical Evaluation
Empirical results demonstrate that DP-AG outperforms state-of-the-art methods in both simulation and real-world tasks, including robotic manipulation on a UR5 robot arm. DP-AG showed significant improvements in success rate, convergence speed, and action smoothness over baselines.
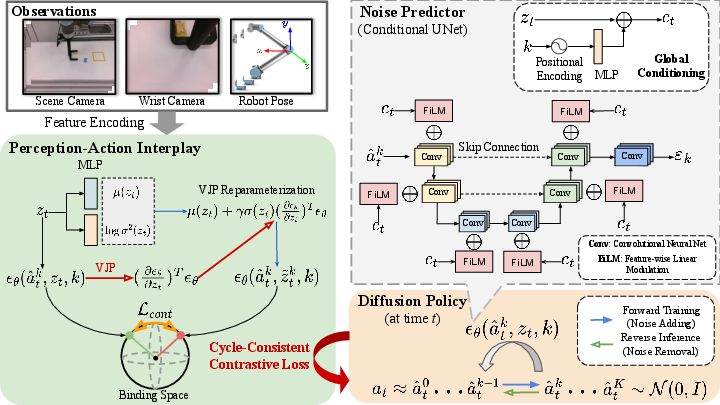
Figure 2: Method Overview highlights the integration of feedback mechanisms in guiding feature evolution via the VJP of noise.
Theoretical Contributions
The paper derives a variational lower bound for the action-guided SDE, showcasing the mathematical underpinning that connects dynamic perception-action interplay to improved policy performance. Theoretical analysis further establishes that the contrastive alignment enforces mutual smoothness in both latent and action trajectories, leading to more coherent and adaptive policies.
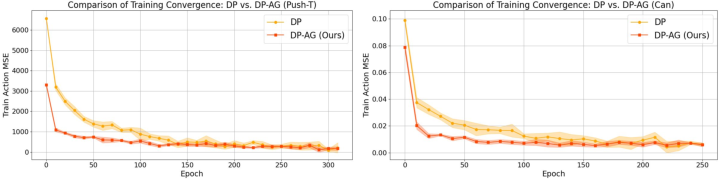
Figure 3: Convergence Plots demonstrate faster learning rates and improved training stability with DP-AG.
Practical Implications
The practical implications of DP-AG are broad, impacting fields requiring real-time adaptability in environments with changing dynamics. In tasks with varying conditions, such as autonomous driving or robotic manipulation, DP-AG's structure can provide more resilient and context-aware decision-making mechanisms.
Conclusion
DP-AG represents a significant advance in imitation learning by effectively coupling perception with action, leading to more adaptive and contextually aware policies. This integration facilitates real-time adaptation, providing a promising framework for tasks requiring dynamic decision-making in uncertain environments. Future research can extend DP-AG's applicability to other domains and explore its integration with reinforcement learning frameworks to further enhance adaptive policy performance.

