SEEC: Stable End-Effector Control with Model-Enhanced Residual Learning for Humanoid Loco-Manipulation
Abstract: Arm end-effector stabilization is essential for humanoid loco-manipulation tasks, yet it remains challenging due to the high degrees of freedom and inherent dynamic instability of bipedal robot structures. Previous model-based controllers achieve precise end-effector control but rely on precise dynamics modeling and estimation, which often struggle to capture real-world factors (e.g., friction and backlash) and thus degrade in practice. On the other hand, learning-based methods can better mitigate these factors via exploration and domain randomization, and have shown potential in real-world use. However, they often overfit to training conditions, requiring retraining with the entire body, and still struggle to adapt to unseen scenarios. To address these challenges, we propose a novel stable end-effector control (SEEC) framework with model-enhanced residual learning that learns to achieve precise and robust end-effector compensation for lower-body induced disturbances through model-guided reinforcement learning (RL) with a perturbation generator. This design allows the upper-body policy to achieve accurate end-effector stabilization as well as adapt to unseen locomotion controllers with no additional training. We validate our framework in different simulators and transfer trained policies to the Booster T1 humanoid robot. Experiments demonstrate that our method consistently outperforms baselines and robustly handles diverse and demanding loco-manipulation tasks.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about helping a humanoid robot walk and use its hands at the same time without dropping or spilling things. When a robot walks, its body shakes and moves, which makes its hands wobble too. The authors introduce a new method called SEEC (Stable End-Effector Control) that keeps the robot’s “end-effector” — think of the hand or tool at the end of the arm — steady even while the robot is moving. They show it working on a real robot that can carry a plate of snacks, hold a chain without letting it swing wildly, and wipe a whiteboard while walking.
Key Objectives
The paper focuses on simple but important questions:
- How can a humanoid robot keep its hand steady while walking, turning, or stepping?
- Can we design an arm controller that works well even when the walking style changes?
- Can we train this controller in simulation and use it on a real robot without retraining?
How the Method Works (Everyday Explanation)
Imagine you’re walking while holding a tray of water. Your body moves up and down and side to side, but you try to keep your hands steady so the water doesn’t spill. The robot needs to do the same thing: move its legs and body while keeping its hands steady.
Here’s the approach, with simple analogies:
- Two-part control: The robot has two “teams.”
- The lower body team (legs) handles walking.
- The upper body team (arms) handles the task, like carrying a plate.
- A “teacher plus student” idea:
- The “teacher” is a physics-based model that calculates how much extra “twisting force” (torque) the arm needs to cancel out the shakes caused by walking. Think of it like physics advice: “Push a little more here, pull a bit there,” so the hand stays steady.
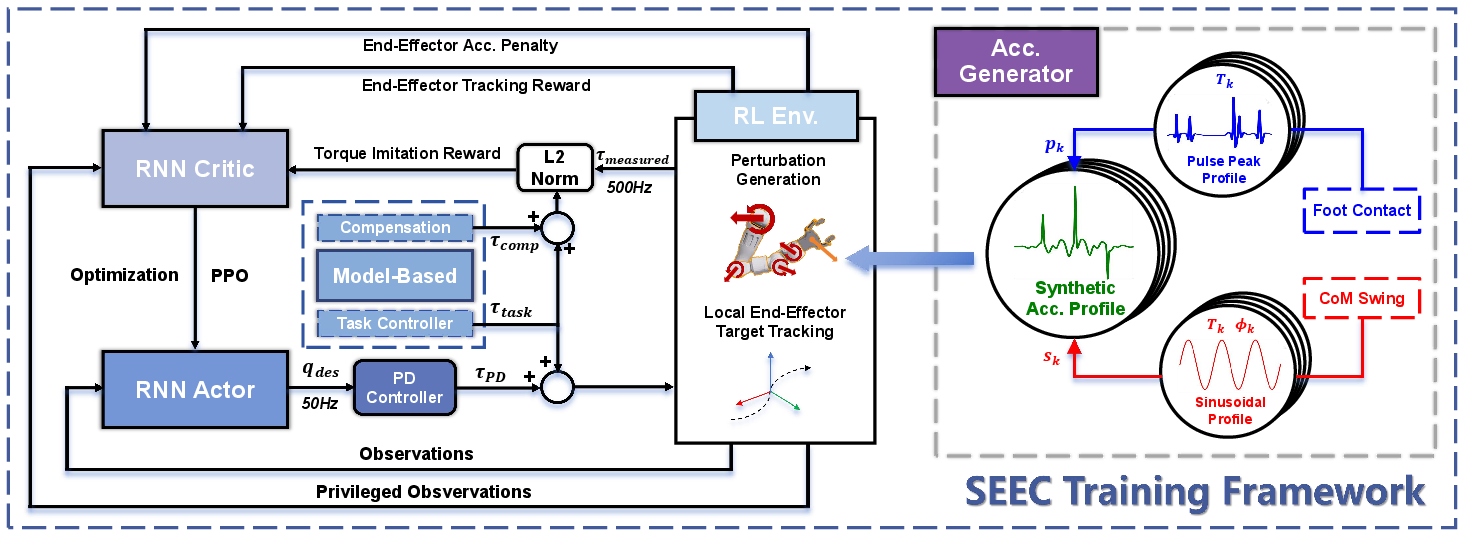
- The “student” is a learning-based controller (a reinforcement learning policy) that practices matching this advice and learns how to make good corrections on its own. This is called “model-enhanced residual learning” — the model gives a strong hint, and the learned policy adds smart adjustments on top.
- Training with pretend walking shakes:
- In simulation, they don’t just have the robot stand still. They add fake but realistic body movements — bumps like foot impacts and gentle side-to-side sways — to mimic different walking styles. This “perturbation generator” is like practicing on a moving bus or a boat deck, so the arm learns to react and keep steady under many kinds of motion.
- Why not just use a simple arm control?
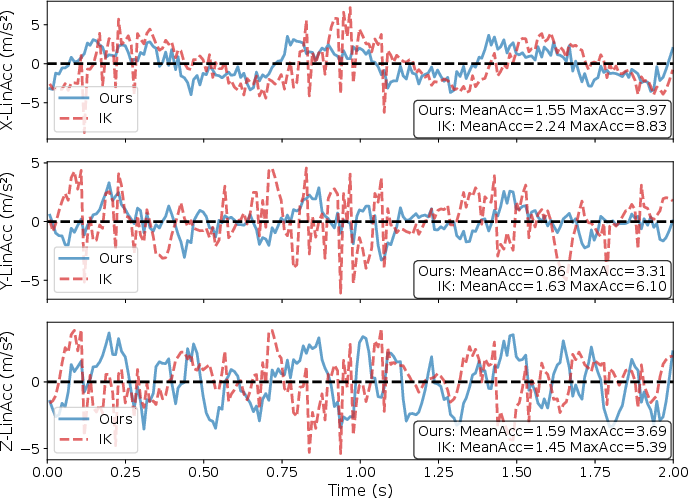
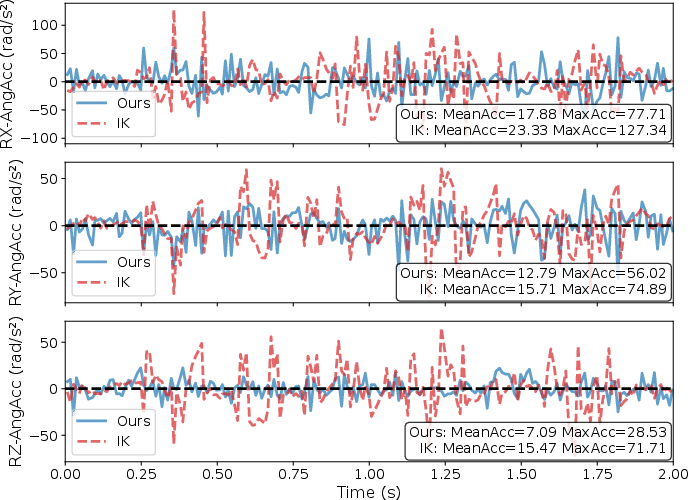
- A basic method called IK (Inverse Kinematics) figures out joint angles to put the hand in the right place. But IK doesn’t handle the sudden shakes from walking very well, so the hand can wobble a lot and things can spill.
- SEEC combines physics know-how with learning, so the arm anticipates and cancels shakes more effectively.
- Safe, practical control:
- On the real robot, they don’t directly apply the teacher’s perfect torques because sensors can be noisy and motors don’t behave exactly like in simulation. Instead, the learning policy outputs target joint positions to a standard PD controller (a common smooth control loop). This makes the system more robust in the real world.
Main Findings and Why They Matter
In both simulation and on a real humanoid robot (Booster T1), SEEC consistently kept the robot’s hand more stable than other methods. Here are the key takeaways:
- Lower hand acceleration: SEEC reduced sudden movements (both linear and angular accelerations) of the hand compared to IK and regular learning methods. This means less wobbling and more precise control while walking.
- Works across different walking styles: Because it was trained with lots of different “fake shakes,” SEEC handled walking patterns it had never seen before. This shows good generalization — it doesn’t need retraining when the legs change how they walk.
- Real-world tasks:
- Holding a flexible chain while walking without letting it swing and fall.
- Wiping a whiteboard smoothly while stepping.
- Carrying a plate of snacks without dropping them.
- Holding a bottle of liquid while minimizing sloshing.
In each case, SEEC kept the hand steady and performed better than the IK baseline.
These results matter because robots in the real world will often need to move and use their hands at the same time — for example, carrying items, assisting people, or doing chores in dynamic environments.
Implications and Potential Impact
This work shows a practical path to more capable humanoid robots:
- Modular design: Since the arm controller is trained to handle a wide range of body motions, you can swap in different walking controllers without retraining everything. That makes building complex robot skills faster and easier.
- Better safety and reliability: A steadier hand means fewer spills, drops, or unstable contacts. That’s important for interacting with people and handling fragile or liquid items.
- Future improvements:
- Adding more precise whole-body state estimation could help the robot not just react to shakes but predict and avoid them.
- Including advanced model-based controllers that handle constraints (like avoiding collisions or joint limits) could improve safety and performance.
- Richer sensors and smarter training could enable even more complex tasks, like carrying objects with teammates or navigating cluttered spaces while manipulating tools.
In short, SEEC helps humanoid robots become more stable and trustworthy at multitasking — walking and using their hands — which is a key step toward everyday practical use.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper. Each item is framed to be directly actionable for future research.
- Formal guarantees: No Lyapunov/passivity-based stability proof or safety guarantees for the closed-loop residual-PD controller under worst-case base disturbances and actuator saturation.
- Assumption validity: The method assumes negligible arm-to-base back-coupling and a robust locomotion controller; the paper does not quantify when these assumptions break (e.g., heavy payloads, large arm accelerations) or provide mechanisms to handle coupling when it is non-negligible.
- Real-time state estimation: The approach avoids using angular acceleration (not available on IMU) and does not deploy model-based compensation on hardware; there is no evaluation of observer/sensor-fusion methods (e.g., EKF/UKF) to estimate base angular acceleration and improve compensation accuracy.
- Global frame tracking: Targets are set in the local frame; implementing and evaluating world-frame targets is left for future work due to missing accurate real-time global pose estimation (VIO/SLAM/leg odometry).
- Disturbance modeling realism: Base acceleration perturbations are synthetic (impulses + sinusoidal sway) with fixed distributions; the paper does not calibrate these profiles to real locomotion logs across gaits, speeds, terrains, or external pushes, nor assess coverage of realistic disturbance statistics.
- Generalization to unseen locomotion controllers: Although degradation is smaller than baselines, the controller still loses stability when swapping in a new locomotion policy; there is no mechanism for online adaptation, conditioning on locomotion policy signatures, or meta-learning to reduce this gap.
- Constraint-aware control: The model-based term and training do not enforce joint/torque limits, self-collision avoidance, contact constraints, or actuator saturation; safe operation under aggressive maneuvers and tight hardware limits is unaddressed.
- Energy and wear: The paper does not quantify the energy/torque overhead and actuator heating/wear introduced by compensation, nor explore cost functions that trade off stability vs. energy.
- Metrics breadth and statistical rigor: Evaluation focuses on end-effector acceleration (mean/max) with small roll-out counts; tracking errors, contact force stability, payload disturbance metrics, success rates, and significance testing over larger trials are missing.
- Multi-contact and force-sensitive manipulation: Tasks primarily involve holding/wiping; there is no evaluation on force-controlled contact tasks (e.g., pushing, drilling), admittance/impedance at the wrist, or compliant contact with varying surface properties.
- Terrain and motion diversity: Experiments are limited to flat ground and moderate speeds; performance under stairs, slopes, uneven terrain, faster gaits (running), abrupt turns, slips, and external perturbations is not studied.
- Cross-robot portability: The approach is only validated on Booster T1; how policy and compensation generalize across humanoids with different kinematics, inertias, and actuation (including heavier arms) is unknown.
- Upper–lower body co-design: The decoupled architecture does not explore feedback from upper-body disturbances to locomotion to minimize base acceleration (e.g., gait shaping), nor joint optimization/co-design of controllers.
- Trade-off management: Stabilization and tracking objectives can conflict; beyond fixed tolerances, adaptive weighting/tolerance scheduling that responds to disturbance magnitude is not investigated.
- Low-level control choice: The system relies on PD with zero velocity targets; the impact of impedance/torque control, nonzero velocity targets, and adaptive gain scheduling on stability and contact quality is unexplored.
- Cross-simulator fidelity: Training (IsaacLab) and evaluation (MuJoCo) use different simulators; the paper does not analyze simulator discrepancies, parameter mismatches, or domain randomization needed to bridge them.
- Sensing delays/noise: Sensitivity to IMU drift, latency, motor delays, and measurement noise is not quantified; delay compensation and robust observer design are not evaluated.
- Disturbance parameter ranges: Impulse/oscillation amplitude and period ranges are not justified by measured base accelerations on the real robot; curriculum designs or ablations that tie distribution choices to performance are missing.
- Online estimation of operational-space quantities: Computing , , and accurately on hardware under model errors is not addressed; learning-based estimators or online system identification could be explored.
- Fail-safe and arbitration: There is no mechanism to detect and mitigate excessive arm accelerations that destabilize locomotion, nor an arbitration layer to temporarily reduce upper-body authority or trigger recovery behaviors.
- Real-time compute budget: The paper does not profile inference and control latency on embedded hardware, nor optimize architectures for tight real-time constraints.
- Benchmark standardization and reproducibility: A standardized loco-manipulation benchmark suite (tasks, metrics, payloads, terrains) with open protocols is not provided, limiting cross-lab comparability and replication.
Practical Applications
Immediate Applications
The following applications can be deployed now by leveraging SEEC’s model‑enhanced residual learning, perturbation generation, and modular upper/lower-body decoupling. Each item includes sector, potential tools/products/workflows, and assumptions/dependencies.
Industry
- Stable tray/liquid transport by humanoid robots while walking in hospitality and retail
- Sector: hospitality, retail
- Tools/products/workflows: integrate SEEC upper‑body controller as a ROS2/Isaac plugin; calibrate PD gains; use onboard IMU for base angular velocity; adopt SEEC’s torque‑guided reward shaping to refine behavior for specific payloads (cups, bowls, trays)
- Assumptions/dependencies: robust locomotion controller; negligible arm‑to‑base coupling for typical payloads; available IMU and joint sensing; compliance with food safety policies
- Mobile wiping/polishing while stepping (cleaning tasks on walls, boards, panels)
- Sector: facilities services, manufacturing
- Tools/products/workflows: teleoperation (VR) or autonomous wiping with operational‑space tracking; SEEC’s stabilization to maintain steady contact pressure; deploy in routine cleaning of whiteboards, panels, or smooth surfaces
- Assumptions/dependencies: sufficient end‑effector force control via PD and operational‑space terms; safe contact constraints; reliable IMU and kinematics
- Carrying delicate goods or instruments in hospitals and labs (e.g., samples, IV bags, sensitive devices)
- Sector: healthcare, biotech
- Tools/products/workflows: use SEEC to damp hand accelerations; configure task tolerances (pose/orientation) to avoid spillage or damage; mocap or vision systems for validation using LinAcc/AngAcc metrics
- Assumptions/dependencies: pathogen control and staff safety protocols; robust gait; payloads within the negligible back‑coupling regime; regulatory approvals for clinical environments
- Sensor stabilization during mobile inspection and mapping (e.g., camera/LiDAR borne by a humanoid)
- Sector: industrial inspection, infrastructure monitoring
- Tools/products/workflows: mount sensors on end‑effectors; apply SEEC to suppress motion‑induced jitter; incorporate perturbation generator during training to match expected locomotion patterns
- Assumptions/dependencies: synchronized sensor and IMU data; locomotion generalization to site terrain; acceptable power and compute budgets
- Cable/chain/hoseline management while walking (reducing oscillations and entanglement)
- Sector: manufacturing, utilities, construction
- Tools/products/workflows: train with SEEC’s disturbance profiles to minimize oscillations; operational‑space tracking for path following of hoses/cables; adopt task tolerances to balance tracking and stabilization
- Assumptions/dependencies: realistic disturbance sampling matching site dynamics; safe handling protocols; adequate gripper performance
Academia
- Drop‑in upper‑body residual policy for loco‑manipulation benchmarks
- Sector: robotics research
- Tools/products/workflows: adopt SEEC’s PPO recurrent actor‑critic with torque‑guided rewards; use IsaacLab/MuJoCo; replicate LinAcc/AngAcc metrics; perform zero‑shot tests on unseen locomotion controllers
- Assumptions/dependencies: access to sim platforms (IsaacLab/MuJoCo); recurrent network training expertise; accurate robot URDF/inertia
- Training robustness via base‑acceleration perturbation generator
- Sector: robotics methods research
- Tools/products/workflows: reuse the Gaussian impulse + periodic sway disturbance model to cover step reactions and CoM sways; log‑uniform gait period sampling; incorporate observation noise, friction, and domain randomization
- Assumptions/dependencies: simulator support for fictitious wrenches; appropriate ranges for training parameters; compute resources for RL
Policy and Standards
- Safety and acceptance test protocols for humanoid loco‑manipulation
- Sector: regulatory, safety certification
- Tools/products/workflows: adopt LinAcc/AngAcc mean/max thresholds for end‑effector stability; define permissible acceleration envelopes for tasks (food handling, cleaning, patient‑proximate operations)
- Assumptions/dependencies: standardized measurement setups (e.g., mocap at ≥120 Hz or equivalent vision/IMU systems); stakeholder consensus on thresholds
Daily Life
- Home service robots carrying drinks/snacks and performing light cleaning while moving
- Sector: consumer robotics
- Tools/products/workflows: integrate SEEC into consumer humanoids; calibrate task tolerances (e.g., ±5 cm, ±0.1 rad) to balance tracking and stability; provide user teleoperation modes for initial deployment
- Assumptions/dependencies: robust, safe locomotion in cluttered homes; compatible hardware; cost and reliability constraints
Long‑Term Applications
These applications require further research, scaling, or development (e.g., richer state estimation, constraint‑aware control, handling strong coupling, or broader regulatory approvals).
Industry
- Precision mobile assembly and finishing (painting, sanding, sealant application while walking)
- Sector: manufacturing, construction
- Tools/products/workflows: integrate constraint‑aware operational‑space MPC with SEEC residual RL; add tactile/force sensing; world‑frame target tracking
- Assumptions/dependencies: accurate whole‑body state estimation; constraint solvers; higher compute; safety certification for contact tasks
- Dual‑arm coordinated transport of heavier or flexible payloads (boards, boxes, fabric)
- Sector: logistics, manufacturing
- Tools/products/workflows: extend SEEC beyond negligible arm‑to‑base coupling; learn compensation under significant payload inertia; include coupled upper‑lower body dynamics during training
- Assumptions/dependencies: revised modeling (non‑negligible back‑coupling); strengthened locomotion; advanced state estimation and control allocation
- Disaster response and field operations on uneven terrain carrying fragile equipment
- Sector: public safety, defense, energy (nuclear/oil/gas)
- Tools/products/workflows: robust sim‑to‑real with terrain/domain randomization; teleoperation fallback; tight integration with communications and safety protocols
- Assumptions/dependencies: locomotion on rough environments; radiation/EMI resilience; remote supervision; regulatory approvals
Academia
- World‑frame end‑effector tracking with proactive compensation
- Sector: robotics methods research
- Tools/products/workflows: add accurate real‑time global pose estimation (VIO, SLAM, mocap‑free) and whole‑body state estimation; convert world commands to local frames dynamically
- Assumptions/dependencies: low‑latency and drift‑resistant state estimation; robust sensor fusion
- Constraint‑aware hybrid controllers (MPC + residual RL) with formal safety guarantees
- Sector: control and learning theory
- Tools/products/workflows: combine operational‑space MPC for hard constraints with residual RL for adaptation; formal verification of stability and constraint satisfaction
- Assumptions/dependencies: real‑time optimization; certified software; standardized benchmarks
- Standardized loco‑manipulation benchmarking suites and datasets
- Sector: research community infrastructure
- Tools/products/workflows: open benchmarks for end‑effector stability under locomotion (tasks, metrics, disturbance profiles, payloads); community evaluation protocols
- Assumptions/dependencies: multi‑robot compatibility; shared data formats; broad adoption by labs and industry
Policy and Standards
- Task‑specific stability requirements and certification for humanoids in public spaces
- Sector: regulatory, public safety
- Tools/products/workflows: define application‑specific acceleration caps (e.g., food service vs. patient care); compliance audits; operator training standards
- Assumptions/dependencies: empirical data across platforms; stakeholder alignment; liability frameworks
- Human–robot collaboration protocols for mobile hand‑overs while walking
- Sector: occupational safety, ergonomics
- Tools/products/workflows: guidelines for safe approach speeds, end‑effector acceleration limits during hand‑over; visual/auditory cues and fail‑safes
- Assumptions/dependencies: reliable perception; cultural/organizational acceptance; iterative trials
Daily Life
- Consumer‑grade “SEEC‑enabled” humanoid butlers performing mobile manipulation robustly
- Sector: consumer robotics
- Tools/products/workflows: integrated whole‑body state estimation; advanced compliance and safety stacks; long‑term autonomy in dynamic homes
- Assumptions/dependencies: affordability, reliability, regulatory approvals; strong privacy/safety guarantees
Cross‑cutting assumptions and dependencies (affecting feasibility across applications)
- Robust locomotion and balance policies able to tolerate upper‑body actuation without failure
- Negligible arm‑to‑base coupling (current design); lifting heavier loads will require extended modeling and training
- Accurate kinematics, inertia models, and IMU/joint sensing; low‑latency control loops (PD gains tuned per robot)
- Reliable state estimation (future world‑frame tracking), including global pose and contact forces
- Real‑time compute for hybrid MPC+RL extensions and constraint handling
- Simulator support (IsaacLab/MuJoCo) for perturbation generation and domain randomization to achieve robust sim‑to‑real transfer
- Safety, regulatory, and ethical considerations for deployment in public/clinical environments
Glossary
- Actor–critic networks: A reinforcement learning architecture that pairs a policy (actor) with a value estimator (critic), often with recurrence for temporal memory. "using recurrent actorâcritic networks with hidden sizes "
- Base twist: A 6D velocity (linear and angular) of the robot’s base represented as a Lie-algebra element. "base twist "
- Center of mass (CoM): The point representing the average distribution of mass; its motion affects robot dynamics and disturbances. "a rhythmic sway from the body's center of mass (CoM) shifting with each step \cite{westervelt2003hybrid}."
- Centrifugal forces: Inertial forces in rotating frames proportional to that act outward from the axis of rotation. "The terms correspond respectively to linear, Euler, centrifugal, and Coriolis forces"
- Coriolis forces: Inertial forces in rotating frames proportional to that arise due to the rotation. "The terms correspond respectively to linear, Euler, centrifugal, and Coriolis forces"
- Domain randomization: A training technique that randomizes simulation parameters to improve robustness to real-world variability. "via exploration and domain randomization"
- End-effector: The robot arm’s tip or tool, whose pose and stability are controlled during manipulation. "Arm end-effector stabilization is essential for humanoid loco-manipulation tasks"
- Fictitious wrench: An equivalent force/torque applied to a fixed-base model to emulate non-inertial effects of base motion. "injecting the equivalent fictitious wrench that would be induced by a generic base twist"
- Gaussian impulse: A short-duration acceleration modeled with a Gaussian profile to simulate impact-like disturbances. "where is a Gaussian impulse with standard deviation $\SI{0.01}{\s}$ and unit peak amplitude"
- Gyroscopic torque: Torque arising from angular momentum effects in rotating bodies, tied to . "plus angular-acceleration and gyroscopic torques."
- IMU (Inertial Measurement Unit): A sensor measuring angular velocity and linear acceleration for state estimation. "missing angular acceleration signals on the hardware IMU"
- Inverse kinematics (IK): The computation of joint configurations that achieve a desired end-effector pose. "IK baseline"
- IsaacLab: A robotics simulation and training environment used to develop and evaluate policies. "Both policies are trained in IsaacLab \cite{mittal2023orbit}"
- Jacobian: A matrix mapping joint velocities/accelerations to end-effector velocities/accelerations. "where is the end-effector Jacobian"
- Joint-space inertia matrix: The mass matrix describing the robot’s dynamics in joint coordinates. "where is the jointâspace inertia matrix"
- Log-uniform distribution: A probability distribution where the logarithm of the variable is uniformly distributed, used for sampling periods. "drawn from a log-uniform distribution in the range $[\SI{0.64}{\s},\SI{1.28}{\s}]$"
- Markov Decision Process (MDP): A formalism for sequential decision-making with states, actions, and rewards. "modeled as Markov Decision Processes (MDPs)."
- Minimum-norm torque: The torque solution that minimizes the Euclidean norm while achieving desired task-space accelerations. "the minimumânorm torque"
- Model Predictive Control (MPC): An optimization-based control method that plans over a horizon to satisfy constraints and objectives. "combine MPC and RL controllers"
- Operational-space centrifugal/Coriolis term: Nonlinear dynamic terms in task space capturing rotation-related effects. " is the operational-space centrifugal/Coriolis term,"
- Operational-space formulation: A control framework that regulates motion/force in task space using quantities like and . "Using the operationalâspace formulation,"
- Operational-space inertia matrix: The matrix representing effective mass/inertia at the end-effector in task space. "where is the operationalâspace inertia matrix."
- Operational-space tracking: Task-space control to follow desired end-effector position/velocity. "operational space tracking \cite{khatib2003unified} of $x_{\text{des}$ and $\dot x_{\text{des}$"
- PD controller: A proportional-derivative controller used for low-level joint position/velocity tracking. "lowâlevel PD controller"
- Proprioception: Internal sensing of the robot’s own joint states and base motion used as observations. "proprioception (base angular velocity, joint states, previous actions)"
- Proximal Policy Optimization (PPO): A reinforcement learning algorithm that uses a clipped objective for stable policy updates. "The policy is trained with PPO~\cite{schulman2017proximal}"
- Quaternion subtraction: An operator used to compute orientation error between quaternions. "(: quaternion subtraction)"
- Residual policy learning: Learning an additive correction on top of a nominal controller to improve performance. "a residual policy learning approach \cite{silver2018residual, cheng2025rambo}"
- Reward reshaping: Modifying the reward function to include guidance signals that steer learning toward desired behaviors. "distill these signals into policy via reward reshaping, guiding it to output a joint command that stabilizes the arm end-effector."
- se(3): The Lie algebra of the special Euclidean group, representing 6D twists (velocity). ""
- Sim-to-real gap: The mismatch between simulation and hardware that can degrade real-world performance. "sim-to-real gap, such as motor delays and friction."
- Spatial acceleration: A 6D acceleration combining linear and angular components for rigid-body motion. "Directly applying spatial accelerations to a floating base in simulation is numerically unstable"
- Zero-shot transfer: Deploying a trained policy on new hardware or tasks without additional training. "validating it both in simulation and on the real hardware via zero-shot transfer."
Collections
Sign up for free to add this paper to one or more collections.

